재귀함수로 DFS 풀기의 늪에 빠져 있다가 정리하는 글. 지금까지 재귀함수는 대충 이렇게 작동한다~ 하는 정도로만 이해하고 있었는데, 코드스쿼드 메모리 구조 관련 미션 하다가 stack에 대해서 조금 더 공부하면서 정리해 본다.
프로그램(프로세스)과 메모리
프로그램이 실행되기 위해서는 먼저 프로그램이 메모리에 올라가야 한다.(load). OS가 프로세스에 제공하는 메모리 공간은
- code 영역: 실행할 프로그램의 코드가 저장된다. 읽기 전용이므로 프로그램(프로세스)은 코드 영역을 침범해 쓰기를 시도할 수 없다.
- data 영역: 프로그램의 전역변수나 정적 변수를 저장/할당하는 공간이다.
- heap 영역: 사용자가 동적으로 메모리를 할당하는 영역. C에서는 malloc.()/new 연산자를 통해 할당하고, free()/delete 연산자를 통해 메모리를 동적 메모리를 해제할 수 있다. 런타임(컴파일 완료 후 사용자의 실행) 시에 크기가 결정된다.
- stack 영역: 함수 호출과 관련된 영역. 함수 내 지역변수, 호출한 함수의 반환 주소, 반환값, 매개변수 등에 사용된다. 이렇게 스택에 저장되는 함수의 호출 정보를 stack frame이라고 한다. 함수를 호출할수록 커지고, 함수가 return되면 줄어든다. 컴파일 시 크기가 결정된다.
으로 나뉜다. 그 가운데 stack 영역에는 '함수의 호출'과 관계되는 데이터들이 저장된다. stack에 저장되는 데이터는 다음과 같다.
- ESP(Extended Stack Pointer): 현재 스택의 최상단 데이터를 가리키는 포인터. 인텔 CPU는 리틀 엔디언을 채택하고 있기 때문에 데이터가 push될 때마다 ESP의 주소는 아래로 감소한다.
- return address: 함수 실행이 끝난 후 돌아갈 주소
- 함수의 인자(매개변수)
- 함수의 local 변수(있는 경우)
즉 함수를 호출하면 메모리의 stack에 이런 정보들이 저장되는데, 재귀함수는 함수 내에서 함수를 또 호출하는 방식이다. 그렇기 때문에 stack에 이런 데이터들이 함수를 호출할 때마다 쌓이게 된다.
즉 함수를 호출하면 메모리의 stack에 이런 정보들이 저장되는데, 재귀함수는 함수 내에서 함수를 또 호출하는 방식이다. 그렇기 때문에 stack에 이런 데이터들이 함수를 호출할 때마다 쌓이게 된다.
void A(int n)
{
if (n > 1) {
A(n - 1);
}
}
void main()
{
int x = 3;
A(3);
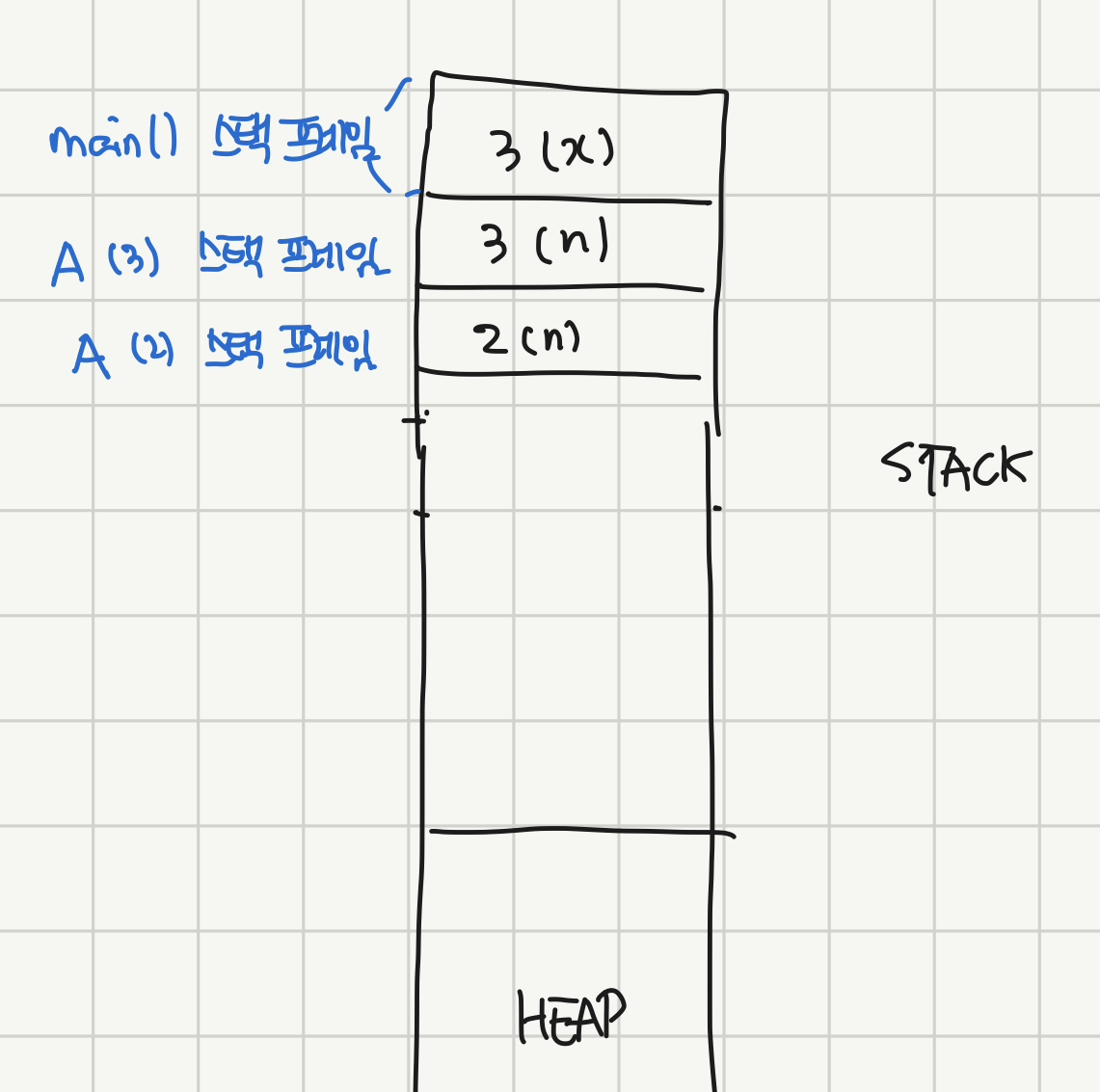
}이런 코드가 있다고 하면 STACK에는 가장 먼저 main 함수의 스택 프레임이 만들어지고, 그 안에는 지역 변수인 x가 들어가게 된다.
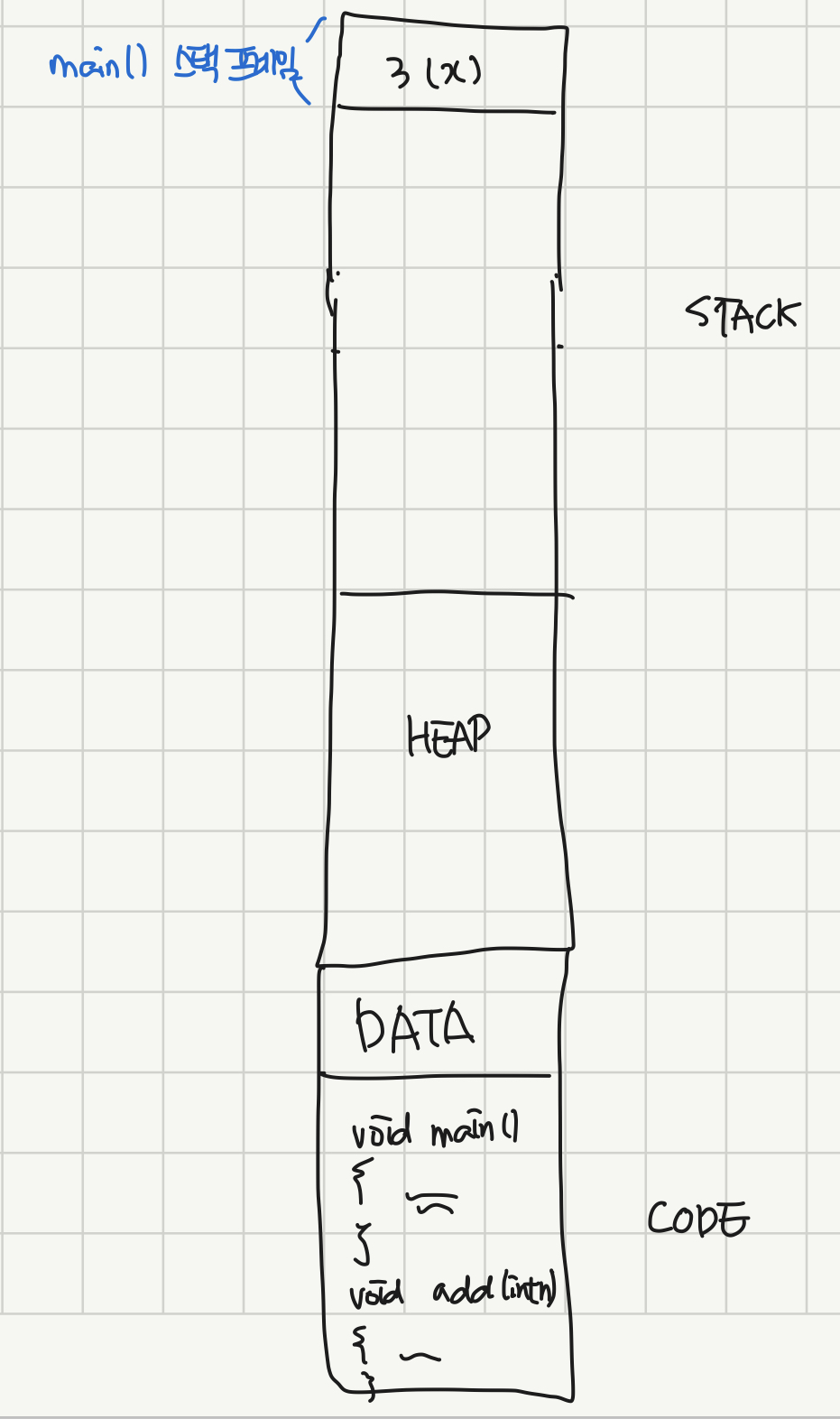
이런 모습. main() 내의 지역 변수인 x=3이 스택 프레임 안에 들어가 있다.
컴파일러 종류에 따라 해당 함수 내에서 호출되는 함수의 매개변수(main이라면 A(3)에 들어가는 3)까지 그 함수의 스택프레임에 들어가는 경우도 있는 것 같다. 하지만 편의를 위해서 그냥 하나만 넣기로 한다.
그러면 A 함수가 호출되면서 A(3)의 스택 프레임이 생기게 된다. 여기서 중요한 점은 main() 함수가 아직 끝나지 않았다는 것이다. main은 A(3) 호출이 완전히 끝나야 끝난다. 그래서 A(3)의 스택프레임이 생성될 때, A(3)이 return되면 돌아갈 위치 역시 스택에 적히게 된다. 하지만 그림에서는 복잡하니까 패스!
void A(int n)
{
if (n > 1) {
A(n - 1);
}
}
void main()
{
int x = 3;
A(3);
// A(3)의 호출이 끝나면 여기로 돌아와야 한다. 그 다음에야 main()이 종료된다.
}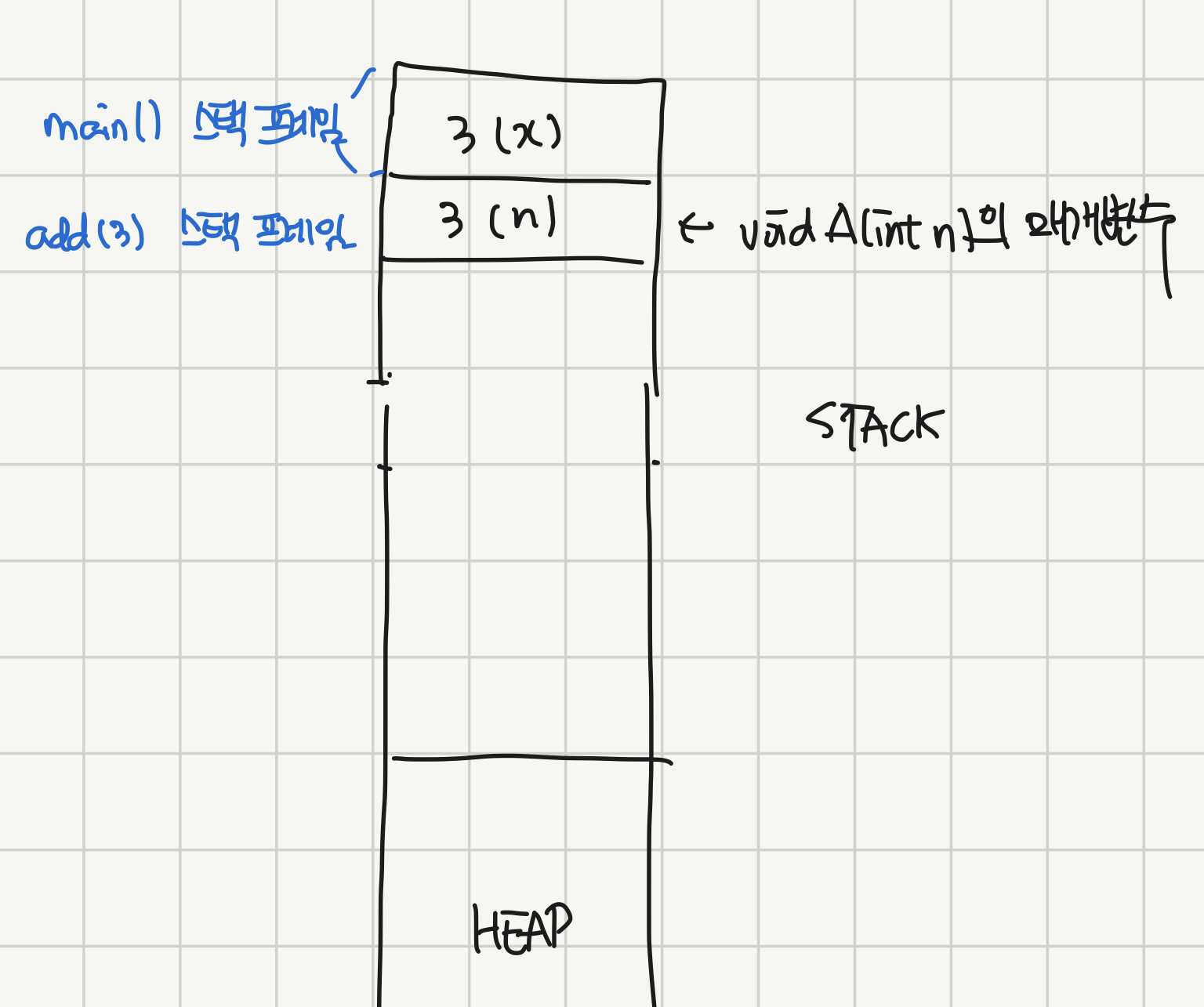
그 뒤에는 A 함수가 실행되면서, n(=3)이 1보다 크므로 A(2)가 또 호출된다. main()과 마찬가지로 A(3)가 호출됐다고 A(3)가 끝난 게 아니다. A(2)가 return하고 돌아와서 함수 끝까지 가야 끝난 것이다. 그렇기 때문에 return 주소를 또 스택에 남겨 놓고 A(3) 스택 프레임 위에 A(2) 스택 프레임이 쌓이게 된다.
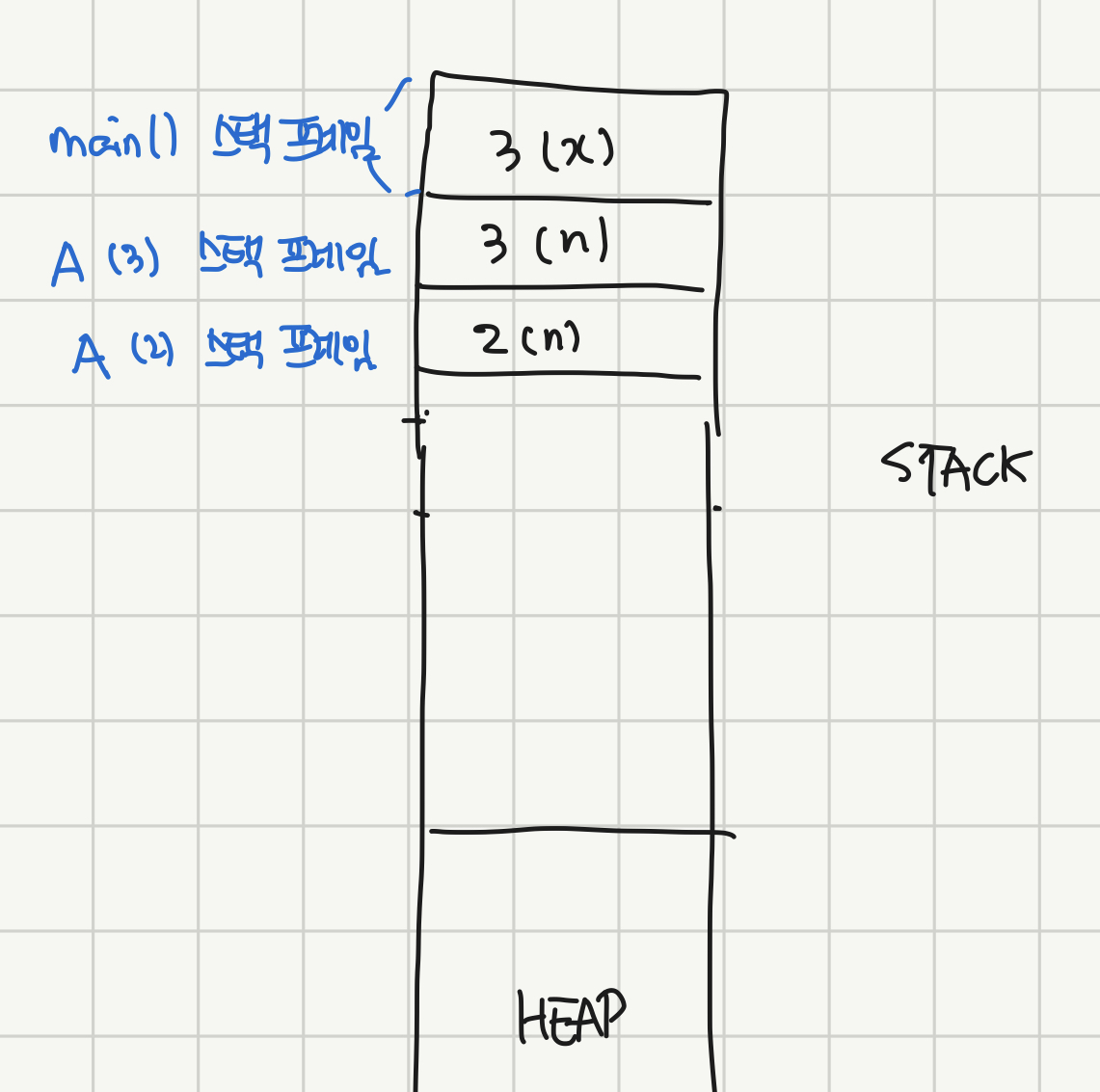
그 다음 n(=2)는 1보다 크니까 똑같은 방식으로 A(1)이 호출되면서 스택 프레임이 만들어져서 쌓인다.
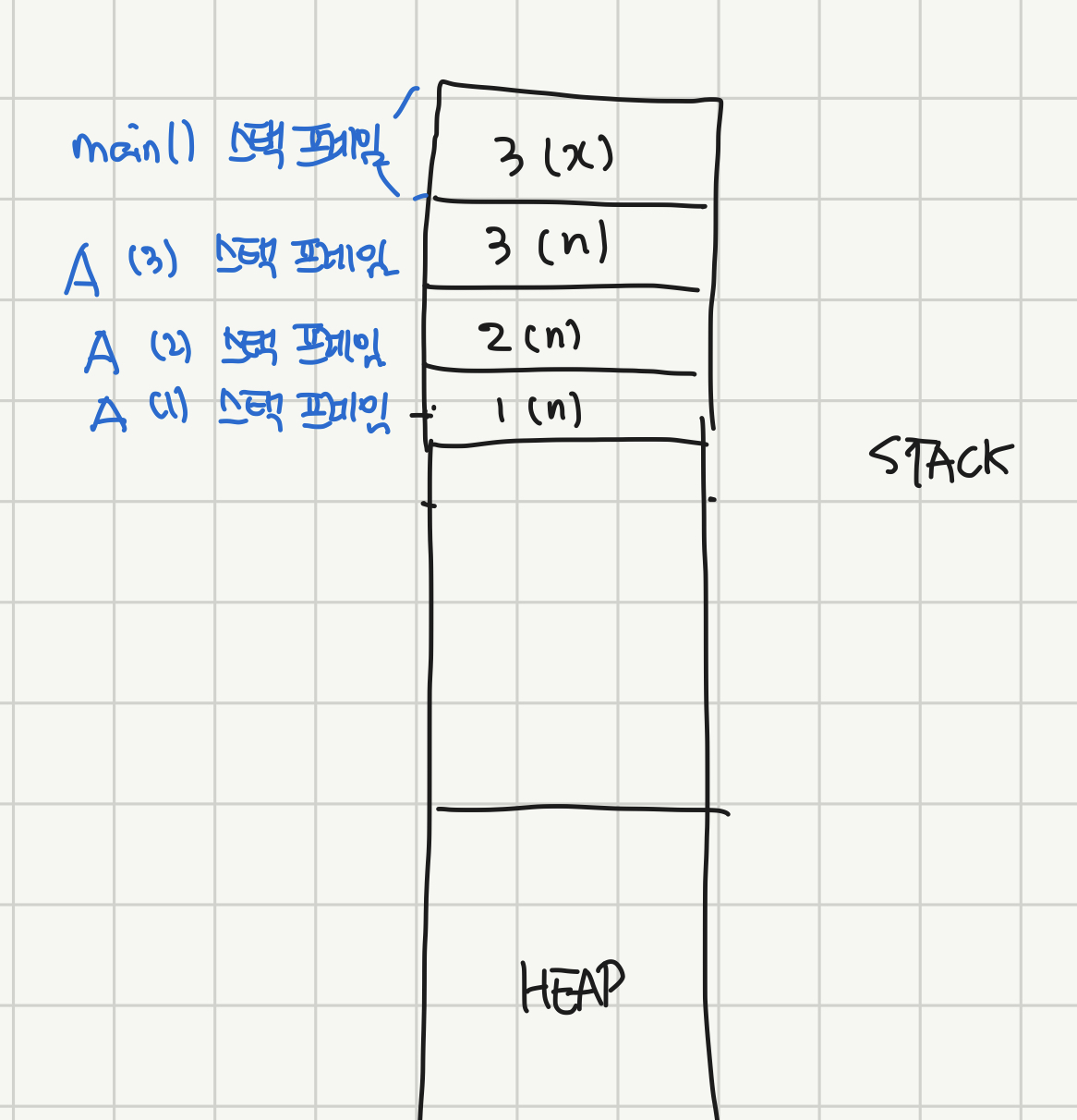
근데 A(1)을 실행하면 1은 1보다 크지 않으므로 더 이상 재귀 호출이 일어나지 않고 A(1)이 종료된다. 그럼 A(1)의 스택 프레임도 소멸한다. 만약 이런 식으로 종료 조건이 제대로 설정되지 못해서 재귀가 무한히 호출되는 경우가 있는데, STACK의 크기는 한정되어 있으므로 결국 어느 순간에는 더 이상 스택 프레임이 쌓이지 못하고 뻗어버리는 경우가 생긴다. 이게 바로 Stack Overflow다. 그래서 재귀함수를 설계할 때는 항상 종료 조건을 확인해야 한다.
다시 A(2)로 돌아오면, 사실 이제 더 이상 A(2)에서 할 일은 없다. 그냥 A(2)도 종료되어 스택 프레임에서 사라진다. 그렇게 A(1)도 똑같이 return되어서 사라진다. A(1)이 리턴되면 결국 main()이 끝나기 직전 부분으로 돌아오게 된다.
void main()
{
int x = 3;
A(3);
// 길고 긴 여정을 끝내고 여기로 왔다. 사실 이제 main()도 할 일은 더 없다. 끗!
}그럼 이제 main()도 종료되고, 스택 프레임은 사라지고, 프로그램은 종료된다.
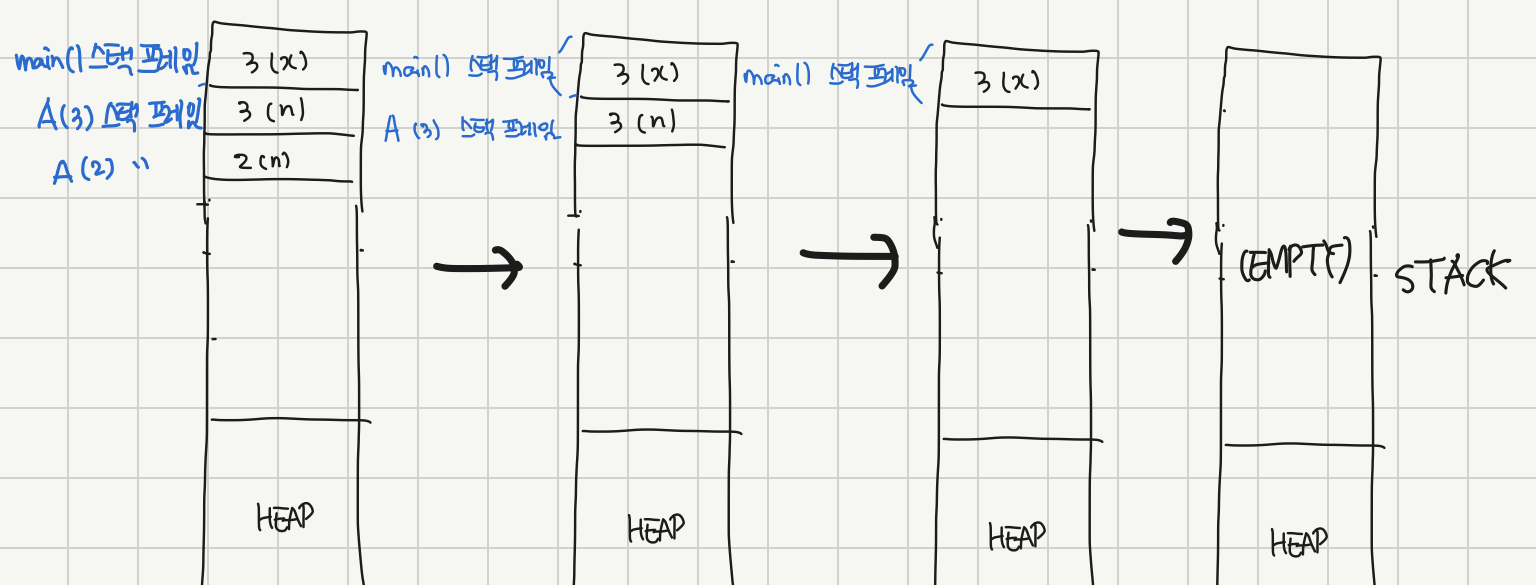
재귀함수가 도는 것을 그냥 코드로만 이해하면 굉장히 복잡하고 추상적으로 느껴지는 부분들이 많은데, 이렇게 실제로 하드웨어에서 도는 원리를 이해하면 조금 더 명확하게 이해하면서 재귀함수를 사용할 수 있다.
참고 자료
