아래 동영상 내용의 내용을 따라가며 speech synthesis 에 관해 정리하였으며 생략, 추가한 내용이 있습니다.
1. speech synthesis 의 역사
-
1779년 독일 모음 발성 기계 (a, e, i, o, u)
-
1950년대 컴퓨터를 이용한 speech sythesis 시스템 개발
-
1961년 벨 연구소에서 IBM 7090을 이용하여 "Daisy Bell" 을 불렀다.
영상을 들어 보면 단순히 멜로디뿐만 아니라 영어 발음이 구현된 것을 알 수 있다.
아서 C.클라크는 이 장치의 시연을 보고 <2001: 스페이스 오디세이> 의 시나리오에 음악 연주 장면을 포함시켰다. HAL 9000이 부르는 노래로 등장한다.
-
1970년대 포먼트 합성이 등장
- 포먼트란 인간의 음성에서 나타나는 공명되는 주파수. 포먼트에 따라 인간이 인식하는 모음vowel 이 달라진다.
- 포먼트 기반 음성의 유명한 예시는 스티븐 호킹의 목소리가 있다. 그의 목소리는 컴퓨터 과학자 데니스 클라트가 녹음한 모델 'Perfect Paul'이다. 호킹은 이후에 더 자연스러운 음원이 등장했지만 이 모델을 계속 사용했다고 한다.
-
1990년대 연결합성 (Concatenative Synthesis) 의 등장
- 음소 단위로 분리된 음성을 모아서 DB를 구축하고 input 된 텍스트에 따라 그 음성 유닛들을 이어 붙이는 방식이다.
- 이때 인간의 음성은 동시조음coarticulation 이라는 특성이 있는데, 특정 음소가 딱 그렇게 나오는 게 아니고 같이 나오는 앞뒤 소리에 영향을 받는다는 특성이다. 그래서 퀄리티를 높이기 위해서는 음성 유닛들이 많이 필요하다.
- Vocaloid, UTAU, VOICEROID 의 초기 버전.
-
2000년대 이후 통계 기반 파라미터 음성합성 - HMM 음성 합성이 등장한다.
- 음성 신호의 스펙트럼, 피치, 지속시간 등의 정보를 HMM 모델로 훈련하여 음성을 합성한다.
- 기존 연결 합성 방식은 음성 신호 자체를 대량으로 DB 로 가지고 있었는데, 그것보다 효율적이다. 음성의 주요 파라미터를 저장하기 때문.
HMM 방식으로 합성한 음원의 예시
- CeVIO Creative Studio - 나고야공대에서 개발한 HTS (HMM-based Speech Synthesis System)
-
2010년대 후반부터 DNN 음성합성이 주류가 되고 있다.
- 딥러닝 기반 음성 합성은 이미 인간이 분간하기 어려운 수준까지 도달했으며 획기적인 성능을 보여준다. 근데 이 포스팅에서 다루는 주제는 아니라 생략
- Ai 프레디 머큐리 이런 식으로 유튜브의 주류 컨텐츠가 되기도 했고... 이것을 일상적으로 듣는 사람도 많아졌다고 느낀다. (기존 음성 합성 소프트웨어-캐릭터의 팬이 아니라도 말이지)
2. 사인파를 이용한 speech synthesis (Composite Sinusoidal Modeling)
인간의 목소리를 사인파로 표현할 수 있을까? 물론 푸리에 변환을 통해 <주기 신호, 아니 비주기 신호까지> 임의의 signal 을 sine wave의 합으로 표현할 수 있다는 것은 당연하다.
근데 흉내낼 원본이 없는 상태에서 만든다고 생각하면 어떻게 해야 만들어볼 수 있을까...
인간의 목소리는 기본주파수로만 이루어져 있는 게 아니고 하모닉스를 갖는다. (인간의 목소리 뿐만 아니라 자연 상태의 소리는 다 그렇다.)
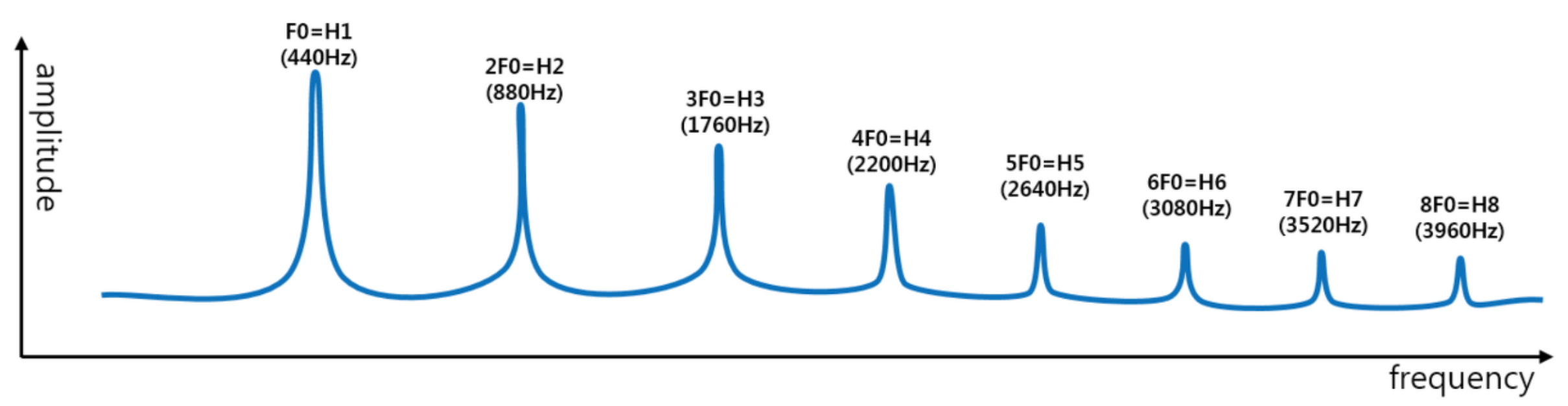
이게 무슨 뜻이냐면 4옥타브 라 (A4) 에 해당하는 주파수가 440Hz 인데. 우리가 막상 이것을 듣고자 하면 주파수 성분이 440Hz 뿐만 아니고 공기가 진동하기 때문에 440 * n 에 해당하는 주파수의 소리까지 같이 듣게 된다.
사람이 발성해도 그렇고 기타로 A4음을 쳐도 저렇게 배음 구조가 생긴다.
단순히 440Hz 단일 주파수 성분만 갖는 소리는 삐- 음처럼 전자음으로 들린다.
아다치 레이의 케이스에서는 사인파 5개를 동시에 재생하여 기본 목소리 원음을 만든다.
그러면 a 와 약간 비슷하면서 a 로는 안들리는 그런 사운드가 나옴.
여기에서부터 a i u e o 모음은 어떻게 만들면 좋을까?
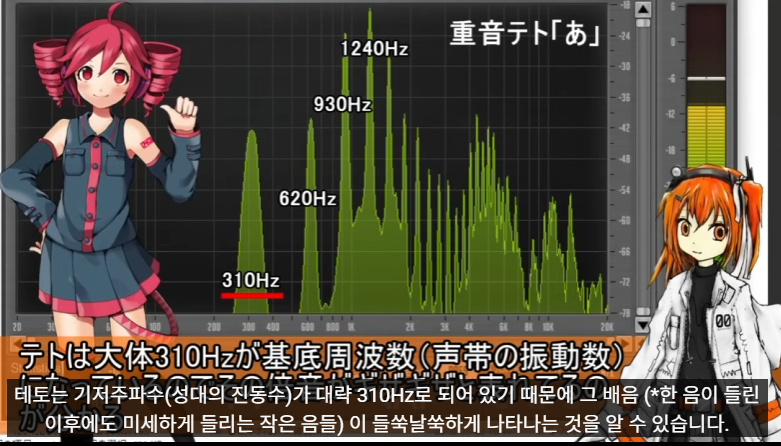
위의 예시를 보면 310Hz 와 그 배수에만 그래프가 일정하게 나타나는게 아니고 310Hz는 조금 작고 620Hz 는 더 크고 하는 식으로, harmonics (배음) 간의 볼륨 차이가 존재함.
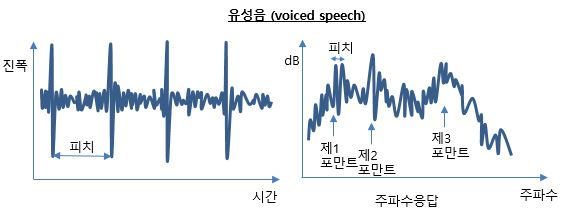
왼쪽처럼 harmonics 에 해당하는 주파수가 일정하게 나오는 게 아니고, 오른쪽처럼 포먼트라는 공명 주파수를 가짐.
이때 낮은 주파수부터 F1, F2, F3 의 포먼트 3개가 모음의 발음을 결정하는 주요 포먼트 주파수이다. (특히 F1, F2) 이후에도 포먼트가 있는데 이것은 사람에 따라, 악기에 따라 배열이 다르다.
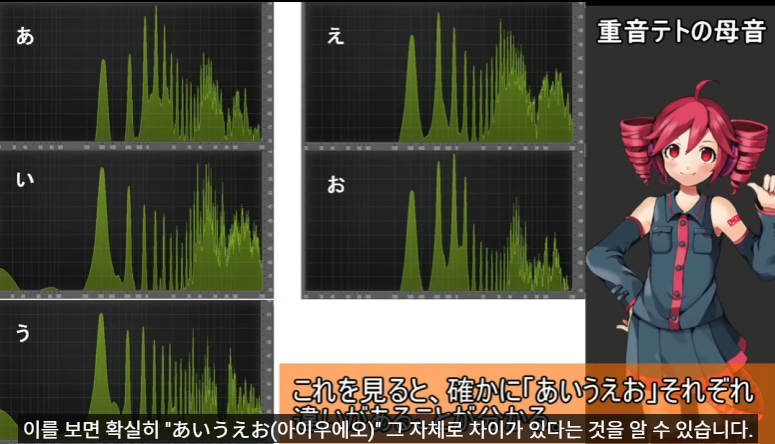
위의 예시를 보면, 음높이는 같은데 (그래프에서 가로축이 frequency 인데, 시작하는 frequency 가 모두 같다.) 파형이 전부 다른 것을 볼 수 있다.
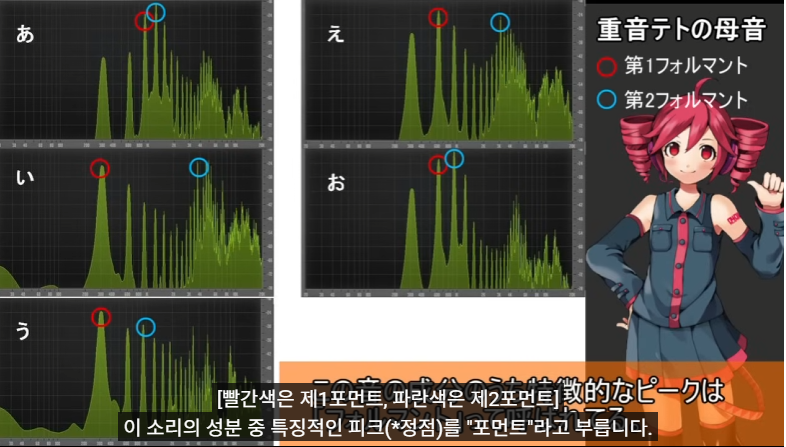
일본어 아이우에오에 해당하는 포먼트 표시된 그림.
동영상에서는 왜 이런 포먼트 위치가 나타나는지도 설명해준다... (인간의 신체적인 구조와 함께)
이 포먼트의 위치를 모방하여 모음의 발음을 조성한다.
그리고 AQUEST 에서 만든 이펙터인 Vocalizer. (포먼트 filter 랑 비슷한 자체 알고리즘을 사용) 걸고. 자체적으로 EQ를 적용해서 파형을 좀 깎는 등의 세부 조정을 한다.
아다치 레이는 미소녀 느낌의 로봇이 컨셉이기 때문에 너무 사람같지는 않고 로봇같은 느낌을 추구하는데...
(여기서부터 영상 재밌음)
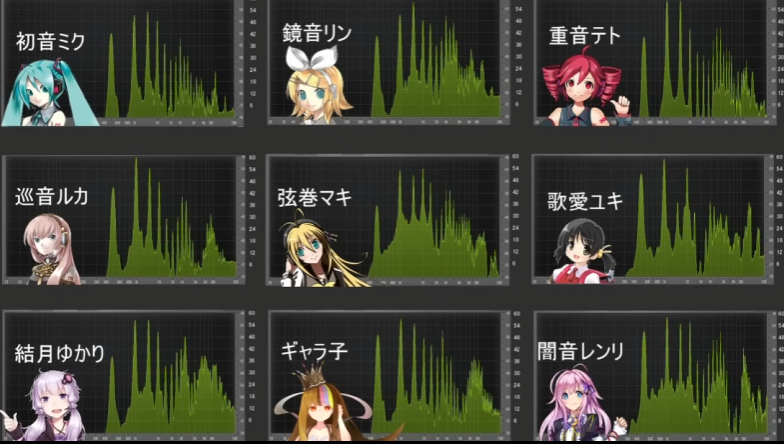
다양한 음원을 비교했을 때 (일본어 a, 500Hz) 특징적인 모양은 비슷하지만 세부적으로는 조금씩 다른 걸 알 수 있음.
특히 첫번째로 높은 F0 과 두번째로 높은 F1에 주목. 이 사이가 비어있는 음원도 있고, 꽉차있는 음원도 있습니다.
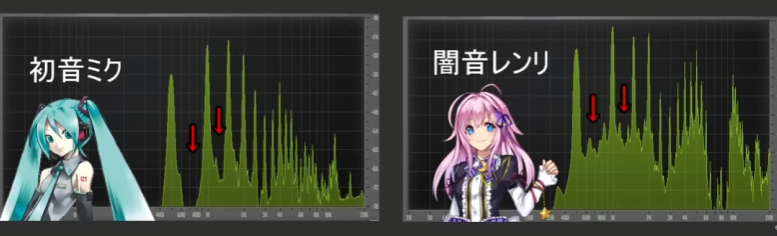
미쿠가 굉장히 특징적인데 여기가 아예 비어 있음. -> 이것이 미쿠의 기계틱함을 보여주는 게 아닌가.
렌리 같은 경우에는 UTAU니까 (Concatenative Synthesis 방식) '아' 발음의 경우에는 사람이 녹음한 그대로네요. F0와 F1 사이가 많이 채워져 있다.
여기서부터는 인간다운 voice, 로봇다운 voice 에 대해서 탐구하기 시작하는데 길어져서 다음시간에
(이제 영상 1/2 정도임)
