알고리즘과 초콜릿 케이크 레시피/ 반에서 가장 키 큰 사람 찾기 : 선형알고리즘
알고리즘이란,
파인만의 알고리즘
1. 문제를 적는다
2. 골똘히 생각한다
3. 답을 생각한다
4. 잠을 잔다
5. 다시 깊게 생각한다
6. 답을 쓴다
5에서 막히면 4로 다시 가서 반복
어떤 어려운 문제도 해결할 수 있게 해주는 기적의 알고리즘.
요리 레시피는 소프트웨어와 비유하지만
알고리즘은 세심하고 명료하게 작성되어야 하며, 모호함이 있으면 안 된다.
'알고리즘은 지능이나 상상력이 없는 개체가 수행하더라도 연산의 의미와 수행 방법에 의심의 여지가 없을 정도로 상세하고 정확하게 명시 되어야 한다.'
그렇기에 레시피는 프로그램 알고리즘에 비해 필요한 수준이 '모호해서' 알고리즘에 비유하는 것은 적합하지 않다.
알고리즘의 표현법
자연어 알고리즘
⦁ 양치질하는 알고리즘
① 칫솔에 치약을 바른다.
② 입속에 칫솔을 넣는다.
③ 양치질을 한다.
④ 입을 헹군다.
일상 속에서 사용하는 언어를 사용해 표기하는 언어로 문제 해결과정을 순서대로 나열하는 것
순서도 알고리즘
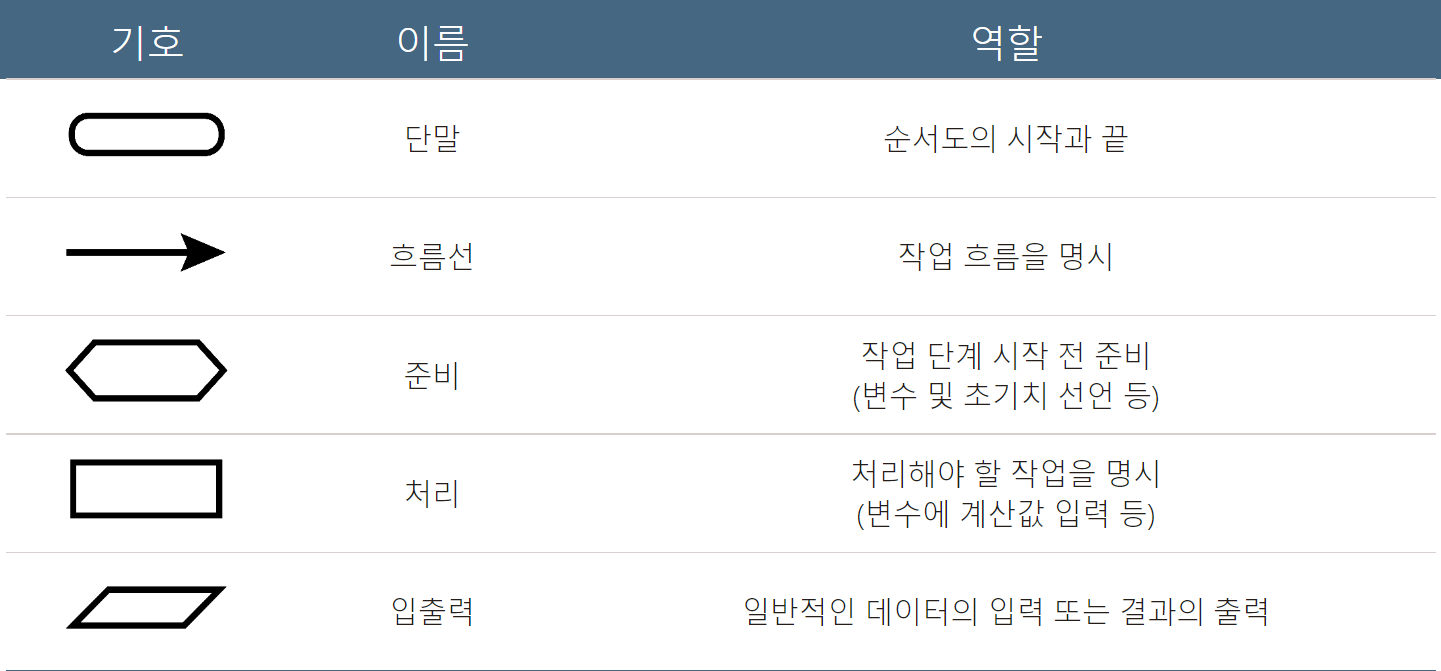

약속된 기호를 사용해서 알고리즘을 표현하는 방식
쉽게 알아볼 수 있지만, 복잡한 알고리즘과 *블록형 언어를 표현하기 어렵다.
*블록형 언어

선형 알고리즘
알고리즘은 바보 같은 컴퓨터도 이해할 수 있을 정도로 실행 단계를 명학하고 상세하게 설명해야한다.
가장 기본적인 확인 방법으로 책에서 예시로 가장 키가 큰 사람을 찾을 때에는 "00, 은 키가 누구니?" 라는 질문을 한 명 한 명을 붙잡아 한 뒤에 키를 비교하고 '키가 가장 큰' 이라는 조건과 대조해 찾아 오는 방식으로
for(int i = 0; i <a.length; i ++) {
a = i
result = a[i]
System.out.println(result)
}라는 for문이 있으면, 가장 키가 큰 사람(i)이라는 정보를 찾기 위해서 정해진 사람들(a배열)의 데이터를 하나하나 비교해서 가장 키가 큰 사람을 찾을 때까지 반복을 하는 것이 선형 알고리즘 이라고 한다.
하지만 선형 알고리즘은 추가 조건이 붙으면 복잡해지는데, 중복 값이나 정보를 입력 받은 순으로 기록을 해야하는지 나중에 들어온 기록부터 쌓아야 하는지 같은 값을 갖고 있는 것들은 어떻게 처리해야 하는 지 등등 해결해야 할 문제들이 추가가 되기 때문이다.
이를 해결하기 위해서 필요한 것이 자료구조(Date Structure)이다.
자료구조 데이터 스트럭쳐란
데이터를 쉽게 찾기 위해서 데이터를 수납하고 정리한 것을 말한다.
나중에 꺼내 쓰기 쉽게 잘 정리해야 하며, 언어의 배열의 대부분은 스트럭쳐이다.
알고리즘 변수 제거
만약 반평균의 키를 구할 때, 컴퓨터는 알고리즘을 사람들이 정해주지 않은 부분까지 고려해서 처리를 하게 되는데.
사람이라면 하지 않을 0으로 나누기 같은 정의되지 않은 연산을 실행할 수도 있기에 처리 곤란한 문제를 명시적으로 검사해 잠재적인 변수 문제를 해결해야한다.
알고리즘의 효율성
알고리즘의 중요한 특성은 얼마나 '효율적으로 일을 처리'하는 가이다.
여기서 말하는 '효율적'이란 '알고리즘이 얼마나 빠른가', '주어진 양의 데이터를 처리하는 데 시간이 얼마나 걸리나' 와 같은 것으로 이 작업 시간은 처리해야 하는 데이터 양에 정비례한다.
선형
만약 키 큰 사람 찾기에서 사람 수가 두 배라면 키를 물어봐야 하는 사람도 두 배가 늘어기에 두 배의 시간이 걸릴 것이고
사람의 수가 10배라면 10배의 시간이 걸리는데, 이렇게 정비례 하거나 선형적으로 비례할 떄 알고리즘은 선형시간(linear-time) 또는 선형(linear)이라고 한다.
일상에서 쓰는 알고리즘은 대부분 선형이며, 이런 알고리즘은 동일한 기본 형태를 같는다.
-
초기화 하기
합계 평균 구하기나 키 큰 사람 구하기 등등 의 문제에서 평균 합계를 0으로 하거나 키가 큰 사람을 낮은 값으로 설정해 놓는다. -
각 항목 검사하기
항목에 대해 간단한 반복적 작업(간단한 계산 : 수를 세거나 이전 값과 비교를 하거나 등등)을 실행한다. -
작업 끝내기
계산한 평균값 출력하기, 가장 키가 큰 사람 출력하기 등등
