2.0 What is Web Scrapping
Web Scrapping
- Web상의 데이터를 추출하는 것
2.1 Navigating with Python
requests
-
requests : HTTP 요청을 보내는 모듈
-
request 우분투에서 설치
pip3 install requests
requests.get(url)
- get
- HTTP 메소드(함수)
- 요청받은 url의 정보를 검색하여 응답
예시) 네이버에 get 요청 보내기
import requests
r=requests.get('https://www.naver.com')
print(r)
// <Response [200]> # 응답코드 200 : OK 위와 같이 requests.get('url') 로 요청
응답 코드 200 : OK (요청이 성공적으로 수행되었음)
응답코드 ref) https://javaplant.tistory.com/18
정보 출력
- print(var.text)를 이용하여 출력
- .text을 통하여 변환을 시켜주고 출력해야함
- .text 하지않고 출력시 위와 같이 응답코드 출력
- 해당 url의 html을 가져와서 출력하는 것
예시)
import requests
r=requests.get('https://www.naver.com')
print(r.text)아래와 같이 html을 가져와서 출력
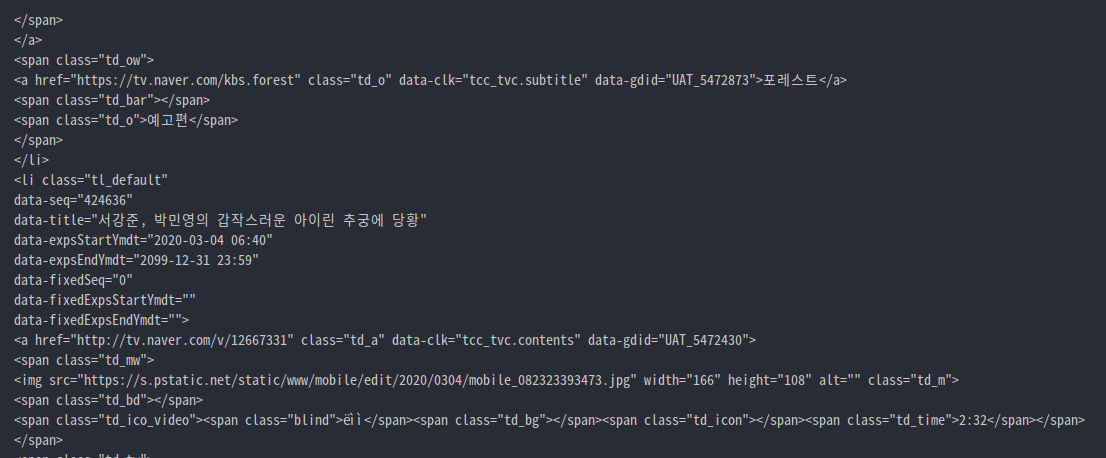
ref) https://rednooby.tistory.com/97
2.2 Extracting Indeed Pages
BeautifulSoup
-
BeautifulSoup : html에서 정보를 추출할 때 사용하는 모듈(패키지)
-
BeautifulSoup 우분투에 설치
pip3 install BeautifulSoup4
BeautifulSoup 사용
from bs4 import BeautifulSoup # package import
soup = BeautifulSoup(html_doc,'html.parser') # html 파일 열기- BeautifulSoup를 이용해서 HTML을 파싱/추출 할 때
- soup(변수) = Beautifulsoup(파싱/추출할 문서,'파서')를 이용하여 문서개체(soup) 생성
- 관습적으로 BeautifulSoup 사용시 문서 개체 변수는 soup로 지정
예시)
import requests
from bs4 import BeautifulSoup
r=requests.get("https://www.naver.com")
soup=BeautifulSoup(r.text,'html.parser')
print(soup)html_doc에 r.text
파서는 html.parser(파이썬 내장)를 사용
위 예시는 아래와 같이 출력
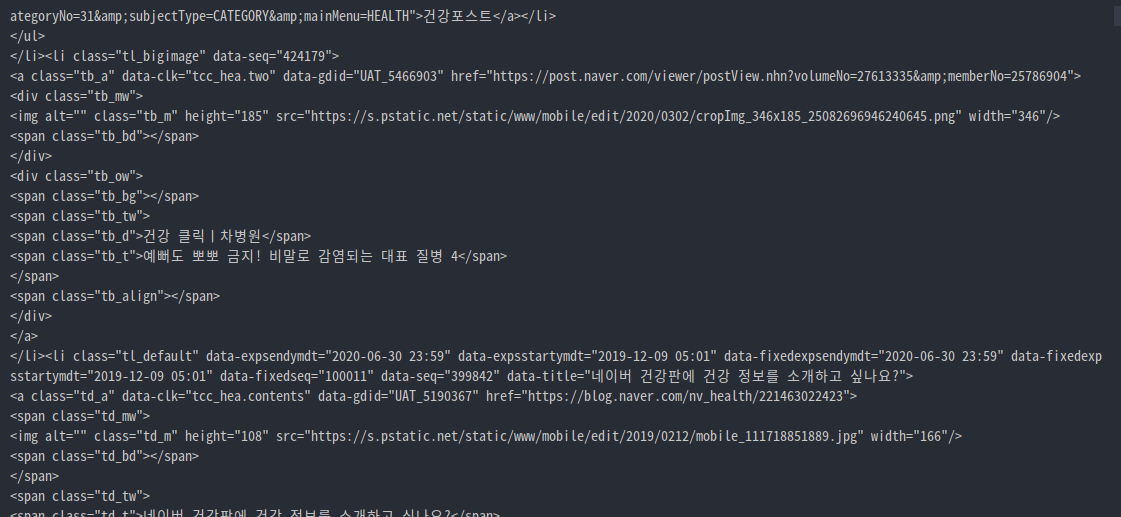
ref) http://discreteglissando.com/2014/12/03/python-bs4/
Soup 메서드
-
find_all()
-
함수 인자로는 찾고자 하는 태그의 이름, 속성 등이 들어감
soup.find_all(name,attrs,string ...) -
해당 조건에 맞는 태그들을 가져옴
예시) a태그 다 가져오기
soup.find_all('a')
-
-
find()
-
함수 인자로는 찾고자 하는 태그의 이름, 속성 등이 들어감
soup.find(name,attrs,string ...) -
함수 인자로는 찾고자 하는 태그의 이름, 속성 등이 들어감해당 조건에 맞는 하나의 태그를 가져옴 (중복이면 첫번째 태그 가져옴)
예시) 첫번째 div 태그 가져오기
soup.find('div')
-
-
태그와 속성을 이용해 가져오기
-
태그와 속성을 이용할 때 함수의 인자 설정 방법
원하는 태그를 함수의 첫번째 인자로 지정
그 다음 속성:값의 dictionary 형태로 만들어서 지정해주기함수의 인자 설정
'태그명', {'속성':'값'}예시)
soup.find_all('div',{'id':'name'})soup.find('a',{'class':'name'})
-
ref) https://twpower.github.io/84-how-to-use-beautiful-soup
page에서 정보 가져오기
1. requests를 이용하여 파이썬에 url 가져오기
import requests
r=requests.get("https://kr.indeed.com/jobs?q=python&l=")2. BeautifulSoup 이용하여 정보 가져오기
import requests
from bs4 import BeautifulSoup
r=requests.get("https://kr.indeed.com/jobs?q=python&l=")
soup= BeautifulSoup(r.text,'html.paser')3. 정보 가지고 오고 싶은 페이지의 내용 확인
페이지 --> 검사를 통해 원하는 정보가 있는 태그 등을 확인 --> 그 태그만 print
위의 홈페이지에

이런식으로 페이지가 얼마나 있는지 확인하고 싶음
페이지 - 검사를 통해 태그 확인 결과
아래와 같이 div, class로 묶여있고 그 안에 a태그로
또 그 안에 span, class로 묶여있음
<div class="pagination"> <a> <span class="pn"> n </span> </a> </div>import requests
from bs4 import BeautifulSoup
r=requests.get("https://kr.indeed.com/jobs?q=python&l=")
soup= BeautifulSoup(r.text,'html.paser')
pagination = soup.find_('div',{'class':'pagination'})
# 전체 문서(soup)에서 class = pagination인 div 태그 하나 찾음
page = pagination.find_all('span',{'class':'pn'}
# pagination class에서 class = pn 인 span 태그 모두 찾음위의 찾은 내용을 print(page)로 확인하면 다음과 같다.
[<span class="pn">2</span>, <span class="pn">3</span>, <span class="pn">4</span>, <span class="pn">5</span>, <span class="pn"><span class="np">다음 »</span></span>]4. 위의 내용에서 마지막에 있는 있는 다음 >> 을 없애기
import requests
from bs4 import BeautifulSoup
r=requests.get("https://kr.indeed.com/jobs?q=python&l=")
soup= BeautifulSoup(r.text,'html.paser')
pagination = soup.find_('div',{'class':'pagination'})
page = pagination.find_all('span',{'class':'pn'}
list=[] # 비어있는 리스트 하나 생성
for page_num in page:
list.append(page_num)
# 빈 리스트에 추출한 내용 추가
print(list[:-1]) # 마지막 데이터(-1) 전까지의 리스트 출력
// [<span class="pn">2</span>, <span class="pn">3</span>, <span class="pn">4</span>, <span class="pn">5</span>]다른 방법 )
- 정보 위치
페이지 - 검사를 통해 태그 확인 결과
아래와 같이 div, class로 묶여있고 그 안에 a태그로
또 그 안에 span, class로 묶여있음
<div class="pagination"> <a> <span class="pn"> n </span> </a> </div>위 방법은 'span',{'class':'pn'}을 이용하여 한번에 찾았으나 아래의 방법은 a 태그로 추출 후 span 태그로 한번 더 추출하는 방식
import requests
from bs4 import BeautifulSoup
r=requests.get("https://kr.indeed.com/jobs?q=python&l=")
soup=BeautifulSoup(r.text,"html.parser")
pagination = soup.find('div',{'class':'pagination'})
page_a = pagination.find_all('a')
print(page_a)
//
[<a data-pp="gQAKAAAAAAAAAAAAAAABfGSykQAdAQABQX7Q1PPnHmo5JeaLKYvegrt2qm5oDO4_fbIAAwIAAQ" href="/jobs?q=python&start=10" onmousedown="addPPUrlParam && addPPUrlParam(this);"><span class="pn">2</span></a>,
<a data-pp="gQAUAAAAAAAAAAAAAAABfGSykQApAQEBBwLfE81wIEDIfEtB_JATn4xnXfUSgFPGL0ZLhN82AAr8v5v2Lb0AAwIAAQ" href="/jobs?q=python&start=20" onmousedown="addPPUrlParam && addPPUrlParam(this);"><span class="pn">3</span></a>,
<a data-pp="gQAeAAAAAAAAAAAAAAABfGSykQA3AQEBBwCHw7YmXN_Wkz6MoFz-J1A91s5r6lz6jHTRxbSxOrWDB8OgQaXzioNvwJfk2Dcfh81l-QADAgAB" href="/jobs?q=python&start=30" onmousedown="addPPUrlParam && addPPUrlParam(this);"><span class="pn">4</span></a>,
<a data-pp="gQAoAAAAAAAAAAAAAAABfGSykQBDAQEBEAH8AnPvymBf3_NWGNo9C7_noEgBjr2WX6taQLi2M61jbcANrL_595G_LwnZOSJg-FXsWJRJCQkFgmgdUvFhgAADAgAB" href="/jobs?q=python&start=40" onmousedown="addPPUrlParam && addPPUrlParam(this);"><span class="pn">5</span></a>,
<a data-pp="gQAKAAAAAAAAAAAAAAABfGSykQAdAQABQX7Q1PPnHmo5JeaLKYvegrt2qm5oDO4_fbIAAwIAAQ" href="/jobs?q=python&start=10" onmousedown="addPPUrlParam && addPPUrlParam(this);"><span class="pn"><span class="np">다음 »</span></span></a>]위와 같이 page_a 출력
page_a : pagination 문서에서 a태그로 묶여있는 것들
pagination : 전체 문서에서 div class=pagination만 추출한 문서
위의 a태그에서 span 태그로 묶인것을 찾고 싶으면 아래와 같이
import requests
from bs4 import BeautifulSoup
r=requests.get("https://kr.indeed.com/jobs?q=python&l=")
soup=BeautifulSoup(r.text,"html.parser")
pagination = soup.find('div',{'class':'pagination'})
page_a = pagination.find_all('a')
list=[]
for page_i in page_a:
list.append(page_i.find('span'))
# page_i에 있는 span 리스트에 포함
print(list[:-1])
// [<span class="pn">2</span>, <span class="pn">3</span>, <span class="pn">4</span>, <span class="pn">5</span>]page_a에서 a태그로 묶인 것 한개가 page_i (따라서 page_i안의 span태그는 한개 존재)
이 page_i에서 span태그 하나를 찾는 것이므로 page_i. find('span') 을 이용
for문을 이용하여 여러개의 a 태그 묶임(여러개의 page_i에서) span태그 하나씩 찾아내서 리스트에 추가
리스트[:-1] 이용해서 마지막에 있는 '다음' 이라는 문자 빼고 출력
