2.5 Extracting Titles
Inspect
해당 페이지 - 검사 이용하여 찾고 싶은 내용의 태그 찾기
가지고 오고 싶은 내용은 아래의 WANT에 위치
<div class="jobsearch-SerpJobCard">
<div class="title">
<a ~ title="WANT">
</a>
</div>
</div>데이터 추출 1
먼저 'div',{'class':'jobsearch-SerpJobCard'} 의 데이터 추출
데이터는 BeautifulSoup를 이용하여 추출
import requests
from bs4 import BeautifulSoup
indeed_url = "https://kr.indeed.com/jobs?q=python&l="
r=requests.get(indeed_url)
soup=BeautifulSoup(r.text,"html.parser")
title=soup.find_all('div',{'class':'jobsearch-SerpJobCard'})위의 과정을 거치면 여러개의 div class="jobsearch-SerpJobCard" 태그가 추출됨
데이터 추출 2
추출한 div class="jobsearch-SerpJobCard" 안에 있는 한개의 div class="title"를 찾아야함
여러개의 div class="jobsearch-SerpJobCard" 에서 반복적으로 찾아야하기 때문에
for문 이용
import requests
from bs4 import BeautifulSoup
indeed_url = "https://kr.indeed.com/jobs?q=python&l="
r=requests.get(indeed_url)
soup=BeautifulSoup(r.text,"html.parser")
title=soup.find_all('div',{'class':'jobsearch-SerpJobCard'})
for result in title:
result.find('div',{'class':'title'})태그 안의 속성 찾기
찾고 싶은 내용 WANT는 a 태그에 속성값으로 존재
-
태그 안에 있는 속성 찾기
-
태그,{속성:값}
태그+ 속성을 함께 찾기예시)
div id = "name" --> find("div",{"id":"name"}
의미 : find a 'div' with a id="name"
-
데이터[속성]
속성 자체의 내용을 가져올 때 추출 데이터[속성]을 이용예시)
div id="name" href="url" title="name"에서 url 또는 name을 추출하고 싶을 때find("a")["href"] / find("a")["title"] 과 같이 사용
의미 : find a "a" and get the title="" attribute여기서는 a태그까지 추출한 데이터에서 title 속성을 찾는 것 이기 때문에 데이터 자리에 find("a")라고 쓰이는 것
-
import requests
from bs4 import BeautifulSoup
indeed_url = "https://kr.indeed.com/jobs?q=python&l="
r=requests.get(indeed_url)
soup=BeautifulSoup(r.text,"html.parser")
title=soup.find_all('div',{'class':'jobsearch-SerpJobCard'})
for result in title:
result2=result.find('div',{'class':'title'})
print(result2.find("a")["title"])위의 속성 찾기를
아래와 같이 바로 연결해서 한 줄로 이어서 표현 가능
for result in title :
title_ = result.find("div",{"class":"title"}).find("a")['title']
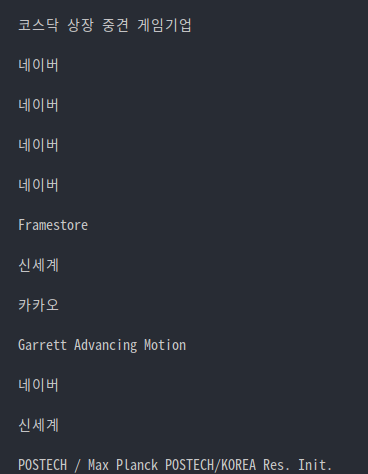
print(title_)2.6 Extracting Companies
위와 같은 과정으로 회사 이름 추출
태그를 확인해본 결과
회사 이름은 아래의 두 경우로 존재
1. <span class="company"> company </span>2. <span class="company"> <a> company </a> </span>company = result.find("span",{"class":"company"}).string
print(company) 찾으면
1의 경우 : 결과 출력
2의 경우 : none
따라서 if문을 사용하여 출력해야함
import requests
from bs4 import BeautifulSoup
indeed_url = "https://kr.indeed.com/jobs?q=python&l="
limit = 10
r=requests.get(indeed_url)
soup=BeautifulSoup(r.text,"html.parser")
title=soup.find_all('div',{'class':'jobsearch-SerpJobCard'})
for result in title :
title_ = result.find("div",{"class":"title"}).find("a")['title']
company = result.find("span",{"class":"company"})
if company.string is not None:
print(company.string)
else :
print(company.find("a").string) 
다음처럼 출력
strip()
위의 출력 사이의 공백을 없애고 싶을 때 사용하는 함수
- strip(양쪽에서 삭제할 문자)
- lstrip(왼쪽에서 삭제할 문자)
- rstrip(오른쪽에서 삭제할 문자)
삭제할 문자에 공백을 쓰면 공백을 삭제
예시)
a = " python "
print(a)
print(a.strip())
//
python # print(a)의 결과
python # print(a.strip())의 결과strip을 이용하여 위의 company 결과의 여백 지우기
import requests
from bs4 import BeautifulSoup
indeed_url = "https://kr.indeed.com/jobs?q=python&l="
limit = 10
r=requests.get(indeed_url)
soup=BeautifulSoup(r.text,"html.parser")
title=soup.find_all('div',{'class':'jobsearch-SerpJobCard'})
for result in title :
title_ = result.find("div",{"class":"title"}).find("a")['title']
company = result.find("span",{"class":"company"})
if company.string is not None:
print(company.string.strip()) # strip 이용
else :
print(company.find("a").string.strip()) # strip 이용위와 같이 strip()을 사용하면

위와 같이 여백이 없게 print됨
