2.7 Extracting Locations and Finishing up
function - A
- indeed_pages( )
- 페이지 목록의 마지막 숫자를 return하는 함수
import requests
from bs4 import BeautifulSoup
indeed_url = "https://kr.indeed.com/jobs?q=python&l="
def indeed_pages():
r=requests.get(indeed_url) # 해당 url의 html 가져옴
soup=BeautifulSoup(r.text,"html.parser") # html 파일 열기
pagination = soup.find('div',{'class':'pagination'}) # 찾고자하는 내용을 찾음
page_a = pagination.find_all('a') # 찾고자하는 내용을 찾음
list=[] # 빈 list 생성
for page_i in page_a[:-1] : # 맨 마지막에 있는 '다음'이라는 글씨 빼고 가져옴
list.append(int(page_i.string)) # list에 페이지 숫자 추가
max_page=list[-1] # 마지막 페이지의 숫자 가져옴
return max_page
function - B
- start( )
- 각 페이지들의 url 만드는 함수
import requests
from bs4 import BeautifulSoup
indeed_url = "https://kr.indeed.com/jobs?q=python&l="
limit=10
def start(last_page): # 변수를 받은 후 함수 시작
for n in range(last_page):
result=requests.get(f'{indeed_url}&start={n*limit}') # url 만들기
print(result.status_code) # 작동되는지 확인print(result.status_code)이용하여 작동되는지 확인 한 후
직업 목록을 추가할 list 만들기
list 만들고 추가하기
- 각 페이지에서 url 만드는 함수
- 직업 목록 가져올 빈 list 만들고 추가하기
import requests
from bs4 import BeautifulSoup
indeed_url = "https://kr.indeed.com/jobs?q=python&l="
limit=10
def start(last_page):
jobs = [] # 빈 list - jobs 만들기
for n in range(last_page):
result=requests.get(f'{indeed_url}&start={n*limit}')
return jobs # list(jobs) 반환title과 company 추출
- title과 company를 추출하는 코드
- title 문서에서 title_과 company 추출
- title 문서 : html에서 div class='jobsearch-SerpJobCard' 부분 찾은 것
import requests
from bs4 import BeautifulSoup
soup=BeautifulSoup(r.text,"html.parser")
title=soup.find_all('div',{'class':'jobsearch-SerpJobCard'})
for result in title :
title_ = result.find("div",{"class":"title"}).find("a")['title']
# title 추출 후 title_로 변수 설정
company = result.find("span",{"class":"company"})
# company 추출 후 company로 변수 설정
if company.string is not None:
print(company.string.strip())
else :
print(company.find("a").string.strip())function - C
- extract_job( )
- 위의 title_ / company 추출 코드를 이용하여 새로운 함수 extract_job( ) 정의
- 함수에 argument 주고 해당 변수 페이지의 내용 찾게하기
def extract_job(html) :
title_ = html.find("div",{"class":"title"}).find("a")['title']
company = html.find("span",{"class":"company"})
if company.string is not None:
company = company.string.strip()
else :
company = company.find("a").string.strip()
return {'title':title_, 'company':company}
# title과 company를 dictionary로 리턴
html이라는 문서에서 find title / find company 하는 함수
function 정리
function - B 와 C 결합
function - B 가 jobs를 return하므로 job(title/ company)을 추출하는 함수인 function - C 를 결합
- function - B
def start(last_page):
jobs = []
for n in range(last_page):
result=requests.get(f'{indeed_url}&start={n*limit}')
return jobs- function - C / 나머지 부분
soup=BeautifulSoup(r.text,"html.parser") # 나머지 부분
title=soup.find_all('div',{'class':'jobsearch-SerpJobCard'})
def extract_job(html) : # function - C
title_ = html.find("div",{"class":"title"}).find("a")['title']
company = html.find("span",{"class":"company"})
if company.string is not None:
company = company.string.strip()
else :
company = company.find("a").string.strip()
return {'title':title_, 'company':company}
for result in title : # 나머지 부분-
function - C 외의 나머지 부분을 function - B에 추가
- function - B 에는 r 문서가 없으므로
soup = BeautifulSoup(r.text, "html.parser")에서 r.text를 function - B 에 있는 문서인 result.text로 바꿔주기
- function - B 에는 r 문서가 없으므로
-
job = extract_job(result) 구문을 이용하여 두 함수 결합
변경된 function - B
def start(last_page):
jobs = [] # 빈 list - jobs 만들기
for n in range(last_page):
result=requests.get(f'{indeed_url}&start={n*limit}')
soup=BeautifulSoup(result.text,"html.parser")
title=soup.find_all('div',{'class':'jobsearch-SerpJobCard'})
for result in title :
job = extract_job(result) # function - B와 C 결합
jobs.append(job) # list(jobs)에 추가
return jobs # list(jobs) 반환indeed.py
indeed.py
import requests
from bs4 import BeautifulSoup
indeed_url = "https://kr.indeed.com/jobs?q=python&l="
limit = 10
def indeed_pages(): # function - A
r=requests.get(indeed_url)
soup=BeautifulSoup(r.text,"html.parser")
pagination = soup.find('div',{'class':'pagination'})
page_a = pagination.find_all('a')
list=[]
for page_i in page_a[:-1] :
list.append(int(page_i.string))
max_page=list[-1]
return max_page
def extract_job(html) : # function - C
title_ = html.find("div",{"class":"title"}).find("a")['title']
company = html.find("span",{"class":"company"})
if company.string is not None:
company= company.string.strip()
else :
company=company.find("a").string.strip()
return {'title':title_,'company':company}
def start(last_page): # function - B
jobs = []
for n in range(last_page):
result=requests.get(f'{indeed_url}&start={n*limit}')
soup=BeautifulSoup(result.text,"html.parser")
title=soup.find_all('div',{'class':'jobsearch-SerpJobCard'})
for result in title :
job = extract_job(result) # function - C
jobs.append(job)
return jobs 적용
indeed.py 실행
from indeed import indeed_pages, start, extract_job
max_pages=indeed_pages()
# url에서 마지막 페이지 추출한 내용을 max_pages 변수로 지정
jobs = start(max_pages)
# start(arg) 변수 받아서 url 생성 --> return 되지는 않음
# start(arg) 안의 extract_job(arg2)
# extract_job(arg2) : arg2의 페이지에서 title/company 추출
# 추출한 값을 job으로
print(jobs)
location 추출
function - C에 location을 추출하는 코드를 추가
- 검사를 이용하여 location 위치 찾기
- span class="location"인 경우와
div class="location"인 경우가 있음
--> if문 사용
- span class="location"인 경우와
def extract_job(html) :
title_ = html.find("div",{"class":"title"}).find("a")['title']
location = html.find("span",{"class":"location"})
if location is not None:
location=location.string
else :
location = html.find("div",{"class":"location"}).string
company = html.find("span",{"class":"company"})
if company.string is not None:
company= company.string.strip()
else :
company=company.find("a").string.strip()
return {'title':title_,'company':company,'location':location} apply link 추출
function - C에 apply link를 추출하는 코드를 추가
- 검사를 이용하여 apply link 위치 찾기
- url 확인
이를 이용하여 코드를 만들면
def extract_job(html) :
title_ = html.find("div",{"class":"title"}).find("a")['title']
location = html.find("span",{"class":"location"})
link = html.get('data-jk') #data-jk의 값을 가져옴
if location is not None:
location=location.string
else :
location = html.find("div",{"class":"location"}).string
company = html.find("span",{"class":"company"})
if company.string is not None:
company= company.string.strip()
else :
company=company.find("a").string.strip()
return {'title':title_,
'company':company,
'location':location,
'link':f'https://kr.indeed.com/%EC%B1%84%EC%9A%A9%EB%B3%B4%EA%B8%B0?jk={link}'} 위의 link = html.get('data-jk') 는 link = html['data-jk'] 로 변환가능
의미 --> html의 속성값('data-jk')를 가져옴
이를 실행하면
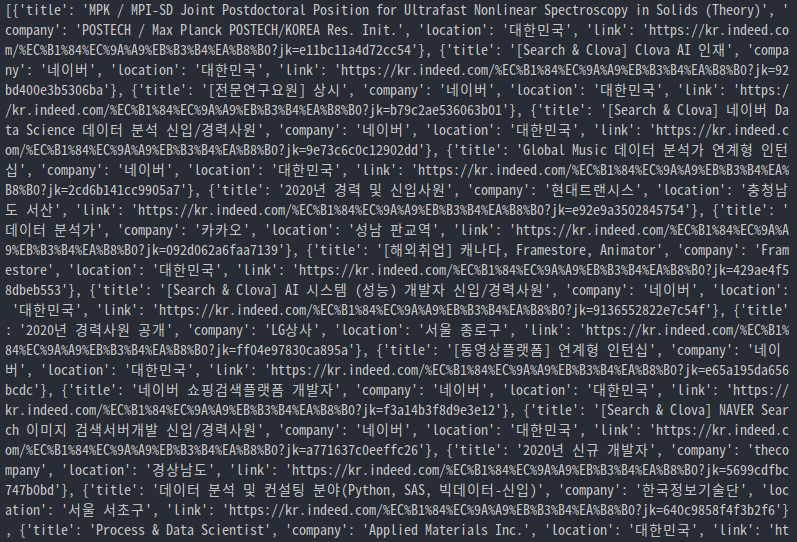
위 사진과 같이 모든 페이지의 내역이 출력
