개요
이전 글에서 노래 가사들을 크롤링해 왔으니 크롤링한 가사를 감정 분석하기 위한 모델이 필요합니다. 모델은 SKT Brain에서 개발한 KoBERT 모델을 활용하였고 모델 학습에는 AI Hub의 감성 대화 말뭉치 데이터를 활용하였습니다.
KoBERT란
KoBERT란 SKT Brain에서 구글의 NLP 모델 BERT를 한국어 자연어처리에 사용할 수 있도록 만든 모델로 우수한 성능을 보여주는 자연어 처리 모델입니다.
데이터 전처리하기
- AI Hub에서 감성 대화 말뭉치를 다운로드 받습니다.
- 파이썬에서 KoBERT를 설치해줍니다. 설치는 KoBERT 깃허브에 들어가서 설치 방법을 따라 하면 됩니다.
- 감성 대화 말뭉치 파일을 바로 학습에 사용할 수 있으므로 전처리를 진행해주어야 합니다.
- 감성 대화 말뭉치 파일에는 레이블이 기쁨, 분노, 상처, 슬픔, 불안, 당황의 6가지 감성이 있는데 학습에 사용하기 위해 이 레이블들을 숫자로 바꿔줍니다.

- 감성 대화 말뭉치는 사람과 챗봇의 대화로 이루어져 있는데 감정은 사람이 친 채팅에서 나오므로 사람이 친 채팅만 학습에 사용합니다. 그리고 사람이 친 채팅 중 2문장만 학습에 사용하기 위해서 통합하여 데이터에 추가해주고 레이블과 통합 채팅 두 가지를 제외한 모든 데이터를 삭제합니다.
- 전처리가 완료되면 tsv형태로 출력합니다.
소스코드
import pandas as pd
def combine(col1, col2):
result = col1.replace("\n", " ")+" "+col2.replace("\n", " ")
return result
def cutBlank(em):
result = em.replace(" ", "")
return result
train = pd.read_csv('C:/projects/NLP/KoBERT/감성대화/감성대화말뭉치(최종데이터)_Training.csv')
valid = pd.read_csv('C:/projects/NLP/KoBERT/감성대화/감성대화말뭉치(최종데이터)_Validation.csv')
train['emotion'] = train.apply(lambda x: cutBlank(x['emotion']), axis=1)
mapping = {'기쁨': 0, '분노': 1, '상처': 2, '슬픔': 3, '불안': 4, '당황': 5}
labeld_tr = train
labeld_tr['emotion'] = train.emotion.map(mapping)
labeld_va = valid
labeld_va['emotion'] = valid.emotion.map(mapping)
labeld_tr['sentences'] = labeld_tr.apply(lambda x: combine(x['sentence 1'], x['sentence 2']), axis=1)
labeld_va['sentences'] = labeld_va.apply(lambda x: combine(x['sentence 1'], x['sentence 2']), axis=1)
labeld_tr.drop(['sentence 1', 'sentence 2', 'sentence 3', 'sentence 4'], axis=1, inplace=True)
labeld_va.drop(['sentence 1', 'sentence 2', 'sentence 3', 'sentence 4'], axis=1, inplace=True)
labeld_tr.to_csv('C:/projects/NLP/KoBERT/감성대화/labeld_train.tsv', sep='\t')
labeld_va.to_csv('C:/projects/NLP/KoBERT/감성대화/labeld_valid.tsv', sep='\t')모델 학습하기
데이터 전처리가 완료되면 모델 학습을 진행하는데 일단 모델 생성과 학습을 해야 합니다. 아래 코드를 통해서 모델을 생성하고 학습을 할 수 있습니다.
import torch
from torch import nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import gluonnlp as nlp
import numpy as np
from tqdm import tqdm, tqdm_notebook
from kobert.utils import get_tokenizer
from kobert.pytorch_kobert import get_pytorch_kobert_model
from transformers import AdamW
from transformers.optimization import get_cosine_schedule_with_warmup
from tensorboardX import SummaryWriter
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
bertmodel, vocab = get_pytorch_kobert_model()
dataset_train = nlp.data.TSVDataset('//labeld_train.tsv', field_indices=[2, 1], num_discard_samples=1)
dataset_test = nlp.data.TSVDataset('//labeld_valid.tsv', field_indices=[2, 1], num_discard_samples=1)
summary = SummaryWriter()
class BERTDataset(Dataset):
def __init__(self, dataset, sent_idx, label_idx, bert_tokenizer, max_len,
pad, pair):
transform = nlp.data.BERTSentenceTransform(
bert_tokenizer, max_seq_length=max_len, pad=pad, pair=pair)
self.sentences = [transform([i[sent_idx]]) for i in dataset]
self.labels = [np.int32(i[label_idx]) for i in dataset]
def __getitem__(self, i):
return (self.sentences[i] + (self.labels[i], ))
def __len__(self):
return (len(self.labels))
##파라미터 필요에 따라 변경가능
max_len = 128
batch_size = 32
warmup_ratio = 0.1
num_epochs = 10
max_grad_norm = 1
log_interval = 200
learning_rate = 5e-5
tokenizer = get_tokenizer()
tok = nlp.data.BERTSPTokenizer(tokenizer, vocab, lower=False)
data_train = BERTDataset(dataset_train, 0, 1, tok, max_len, True, False)
data_valid = BERTDataset(dataset_test, 0, 1, tok, max_len, True, False)
train_dataloader = torch.utils.data.DataLoader(data_train, batch_size=batch_size, num_workers=0)
test_dataloader = torch.utils.data.DataLoader(data_valid, batch_size=batch_size, num_workers=0)
class BERTClassifier(nn.Module):
def __init__(self,
bert,
hidden_size=768,
num_classes=6,#분류할 클래스의 개수
dr_rate=None,
params=None):
super(BERTClassifier, self).__init__()
self.bert = bert
self.dr_rate = dr_rate
self.classifier = nn.Linear(hidden_size, num_classes)
if dr_rate:
self.dropout = nn.Dropout(p=dr_rate)
def gen_attention_mask(self, token_ids, valid_length):
attention_mask = torch.zeros_like(token_ids)
for i, v in enumerate(valid_length):
attention_mask[i][:v] = 1
return attention_mask.float()
def forward(self, token_ids, valid_length, segment_ids):
attention_mask = self.gen_attention_mask(token_ids, valid_length)
_, pooler = self.bert(input_ids=token_ids, token_type_ids=segment_ids.long(),
attention_mask=attention_mask.float().to(token_ids.device))
if self.dr_rate:
out = self.dropout(pooler)
return self.classifier(out)
model = BERTClassifier(bertmodel, dr_rate=0.5).to(device)
no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=learning_rate)
loss_fn = nn.CrossEntropyLoss()
t_total = len(train_dataloader) * num_epochs
warmup_step = int(t_total * warmup_ratio)
scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=warmup_step, num_training_steps=t_total)
def calc_accuracy(X,Y):
max_vals, max_indices = torch.max(X, 1)
train_acc = (max_indices == Y).sum().data.cpu().numpy()/max_indices.size()[0]
return train_acc
for e in range(num_epochs):
train_acc = 0.0
test_acc = 0.0
model.train()
lossF = 0
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(tqdm_notebook(train_dataloader)):
optimizer.zero_grad()
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length = valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
loss = loss_fn(out, label)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)
optimizer.step()
scheduler.step() # Update learning rate schedule
train_acc += calc_accuracy(out, label)
lossF = loss.data.cpu().numpy()
if batch_id % log_interval == 0:
print("epoch {} batch id {} loss {} train acc {}".format(e+1, batch_id+1, loss.data.cpu().numpy(), train_acc / (batch_id+1)))
print("epoch {} train acc {}".format(e+1, train_acc / (batch_id+1)))
model.eval()
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(tqdm_notebook(test_dataloader)):
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length = valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
test_acc += calc_accuracy(out, label)
print("epoch {} validation acc {}".format(e+1, test_acc / (batch_id+1)))
summary.add_scalar('train_acc', train_acc / (batch_id+1), e+1)
summary.add_scalar('test_acc', test_acc / (batch_id+1), e+1)
summary.add_scalar('loss', lossF, e+1)
torch.save(model, 'C:/projects/NLP/KoBERT/Model/model.pt') # 전체 모델 저장
torch.save(model.state_dict(), 'C:/projects/NLP/KoBERT/Model/model_state_dict.pt') # 모델 객체의 state_dict 저장
torch.save({
'model': model.state_dict(),
'optimizer': optimizer.state_dict()
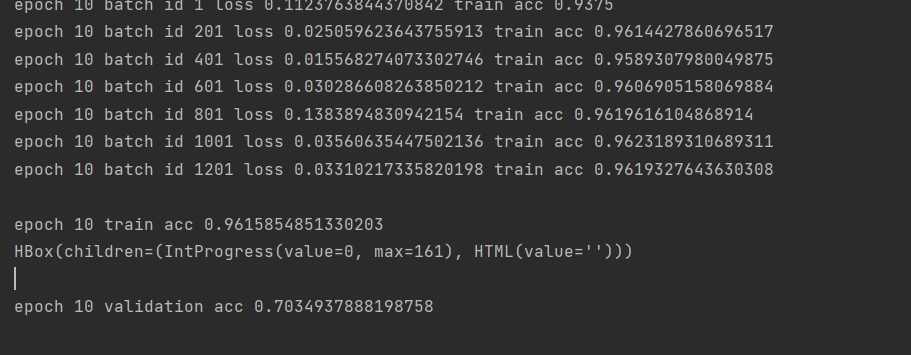
}, 'C:/projects/NLP/KoBERT/Model/model_all.tar')위에서부터 KoBERT 모델을 받아오는 과정, 데이터를 불러오는 과정, 불러온 데이터를 토큰화하고 학습에 이용가능하도록 가공하는 과정, 학습을 진행하는 과정, 학습이 완료된 모델을 저장하는 과정입니다. 저는 학습을 10번 수행하였고 학습 결과 약 70%의 validation accuracy를 보여주었습니다. 이제 모델 학습까지 수행하였으니 노래 가사의 감정 분석을 해보는 일만 남았습니다!
ps. KoBERT를 활용하여서 진행해보았지만, 아직 KoBERT에 대해서 자세하게 알지는 못하겠네요. 이런 모델들을 사용할 때 좀 더 공부를 해서 어떻게 하면 좋은 성능을 낼 수 있을지 생각해보며 프로젝트를 진행해보면 더 좋은 결과가 나올 것 같습니다.

INTP 개발자 지망생