이번 챕터는 드디어 오토인코더이다. 본격적인 내용의 시작!
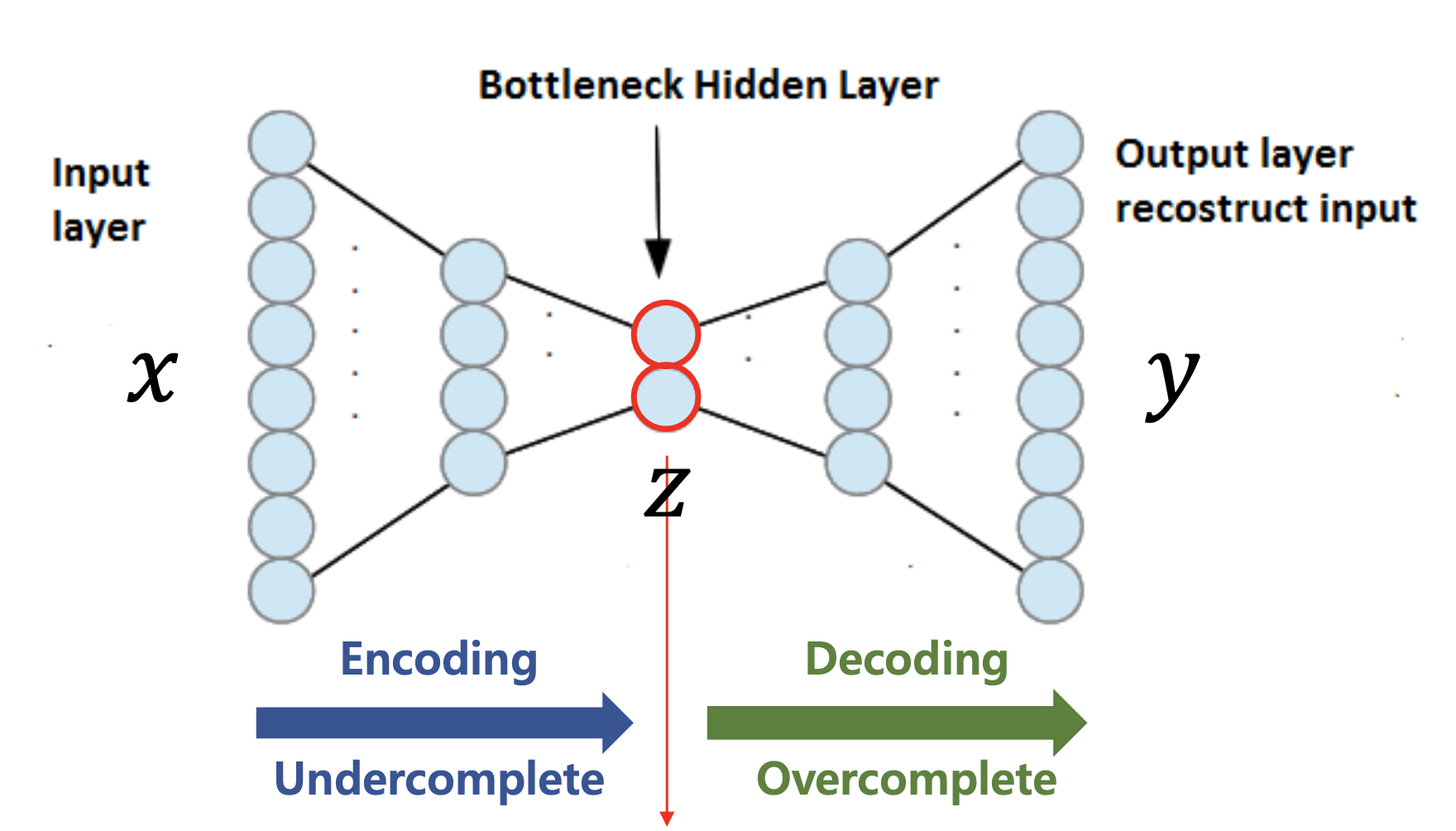
Autoencoder 모델의 구조를 보면 input 차원과 output 차원이 같다. UNet을 떠올리면 편할 것 같은데, 차원이 줄어들었다 늘어나는 것을 볼 수 있다. Encoding과 Decoding의 과정이다.!
여기서 빨간색으로 칠해진 부분을 잘 보면, 차원이 작아지는 부분을 가르키고 있다. 이는 code, latent variable, feature, hidden representation 등으로 불린다. 아무것도 모른 채 논문에서 latent라는 단어를 마주친 적이 꽤 있었는데 이해를 제대로 하지 못하고 넘어가는 경우가 종종 있었다. 이 설명을 듣고 드디어 알게 되었다!
그리고 오토인코더가 세상에 처음 공개되었을 때 주목을 받았던 이유는 unsupervised를 supervised로 바꿀 수 있었기 때문이다. 그 이유는 앞서 말했듯이 입력과 출력이 같기 때문이다.
그리고 생성 분야를 들어 말해보자면, 데이터를 decode하는 과정에서 학습 데이터에서 보았던 것들은 잘 복원한다. 학습 데이터에 대한 복원 성능이 좋은 건 당연한 일이 아니다. GAN은 autoencoder와는 다르게 그렇지 않기 때문이다. 다시 말해서 autoencoder는 최소 성능이 보장된다고 할 수 있다.
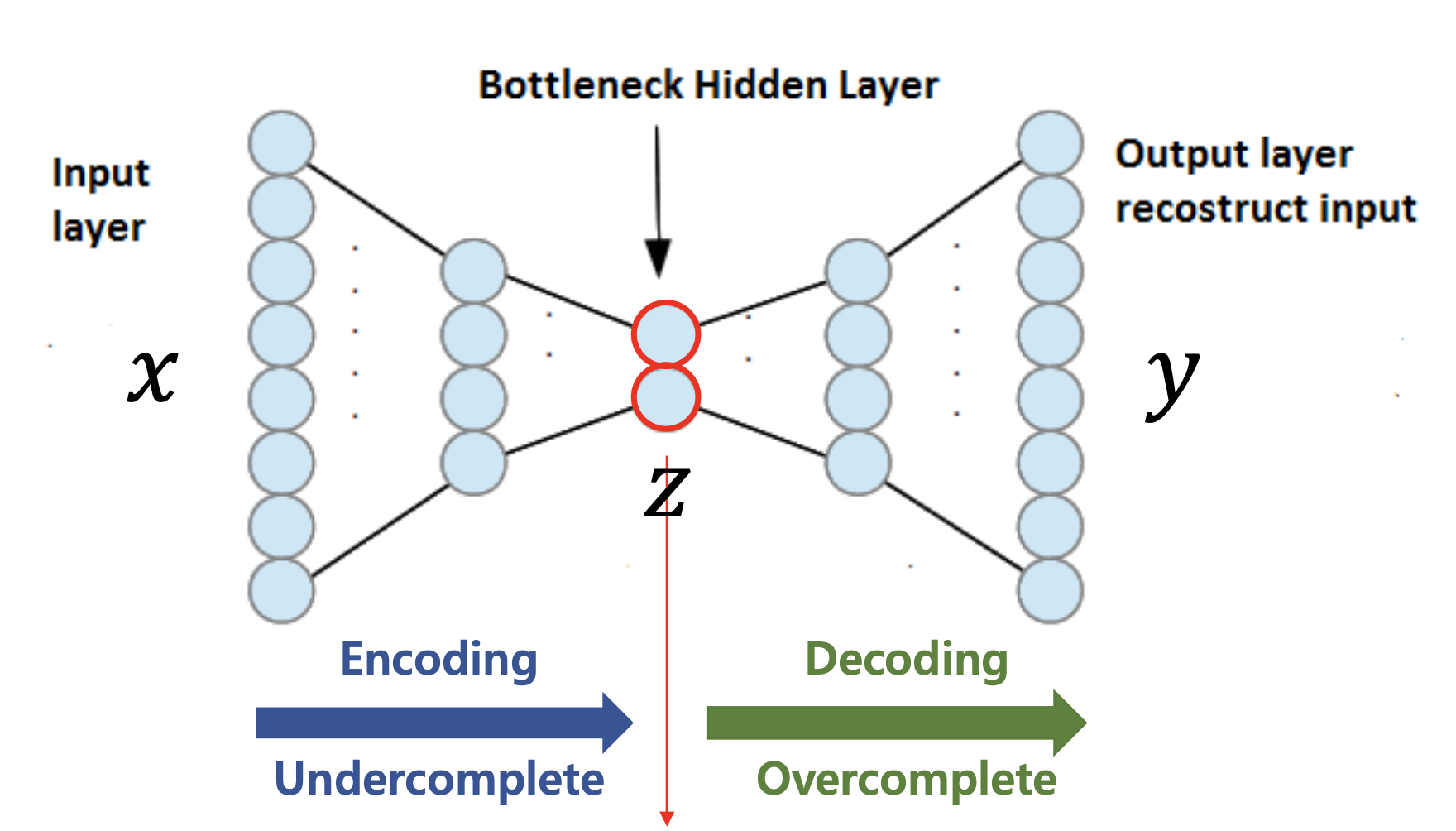
이제 오토인코더의 구조에 대해 자세히 살펴볼 차례이다.
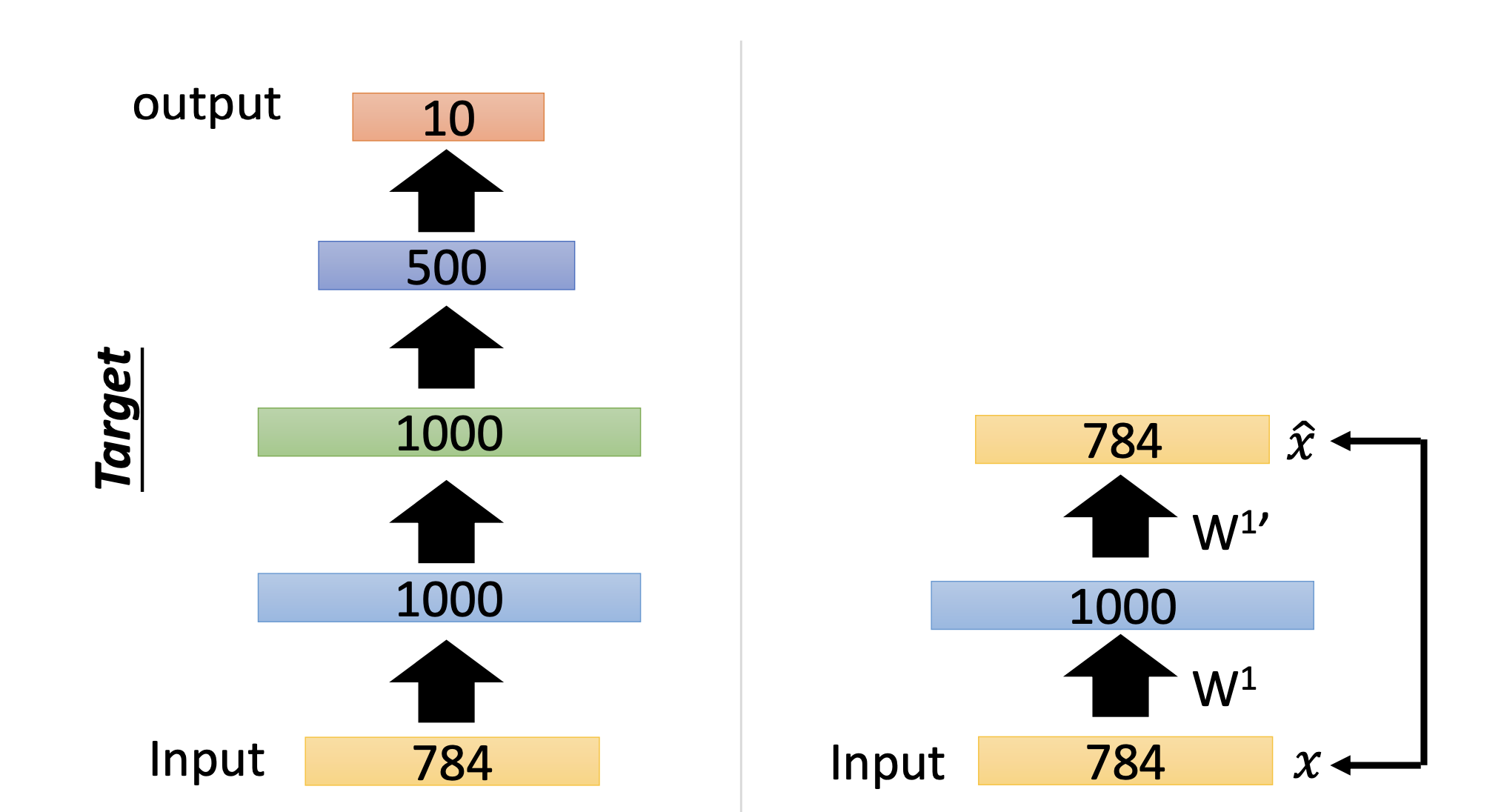
layer by layer로 설명되는 것이 핵심이다. 먼저 첫번째 레이어를 보면, 1000개의 차원을 가진 레이어에 input을 넣고 그 결과값을 다시 복원을 해본다. 그럼 간단하게 w1, w1’은 서로 transpose 관계이다.
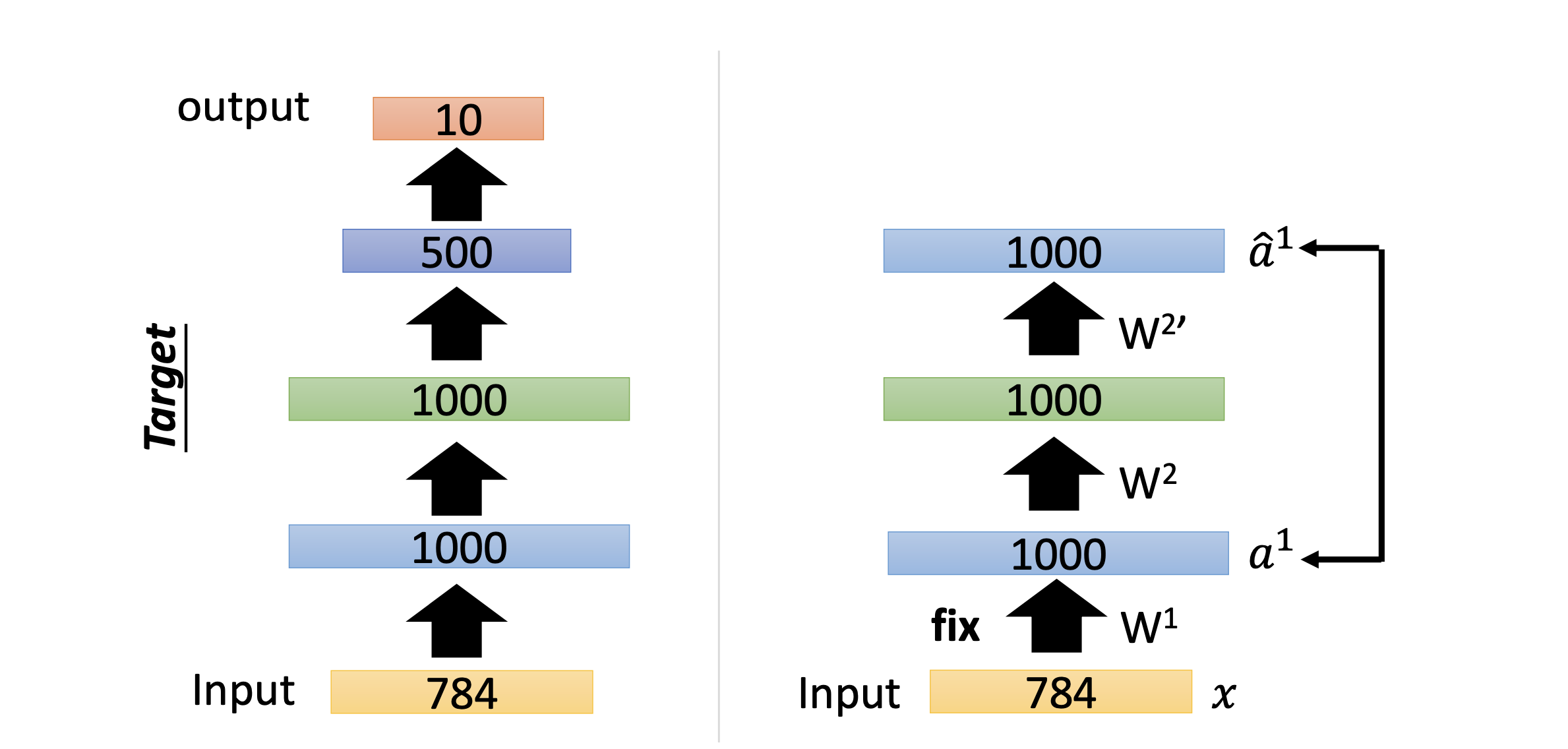
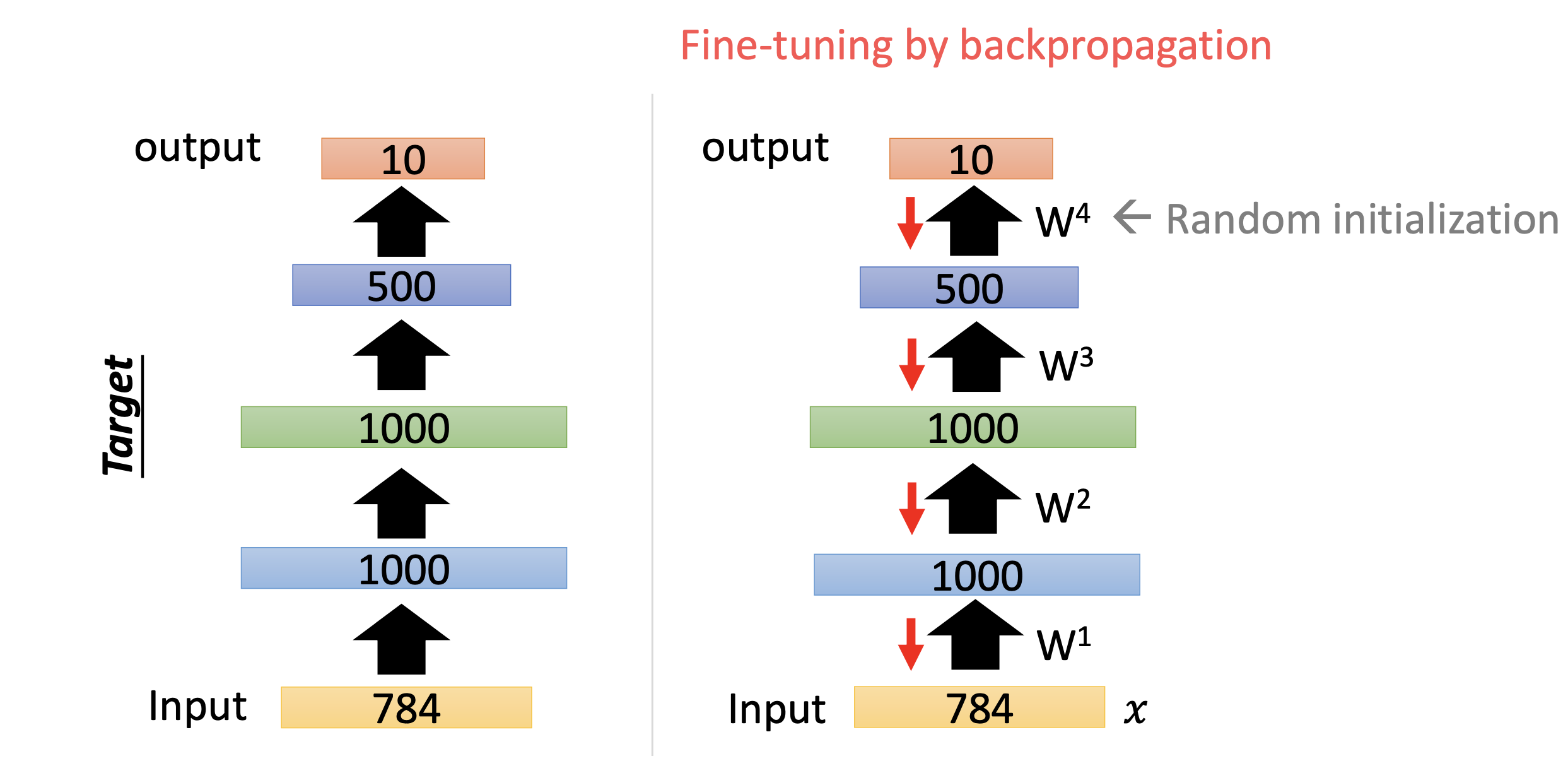
이 과정을 뒤의 레이어에도 똑같이 진행하고 마지막으로 backpropagation을 진행한다. 오토인코더가 공개된 초기에는 weight initialization에 좋더라.. 라는 말들 때문에 이와 같은 방법으로 많이 쓰였다고 한다. 여기서 설명된 오토인코더를 stacking autoencoder라고 부른다.
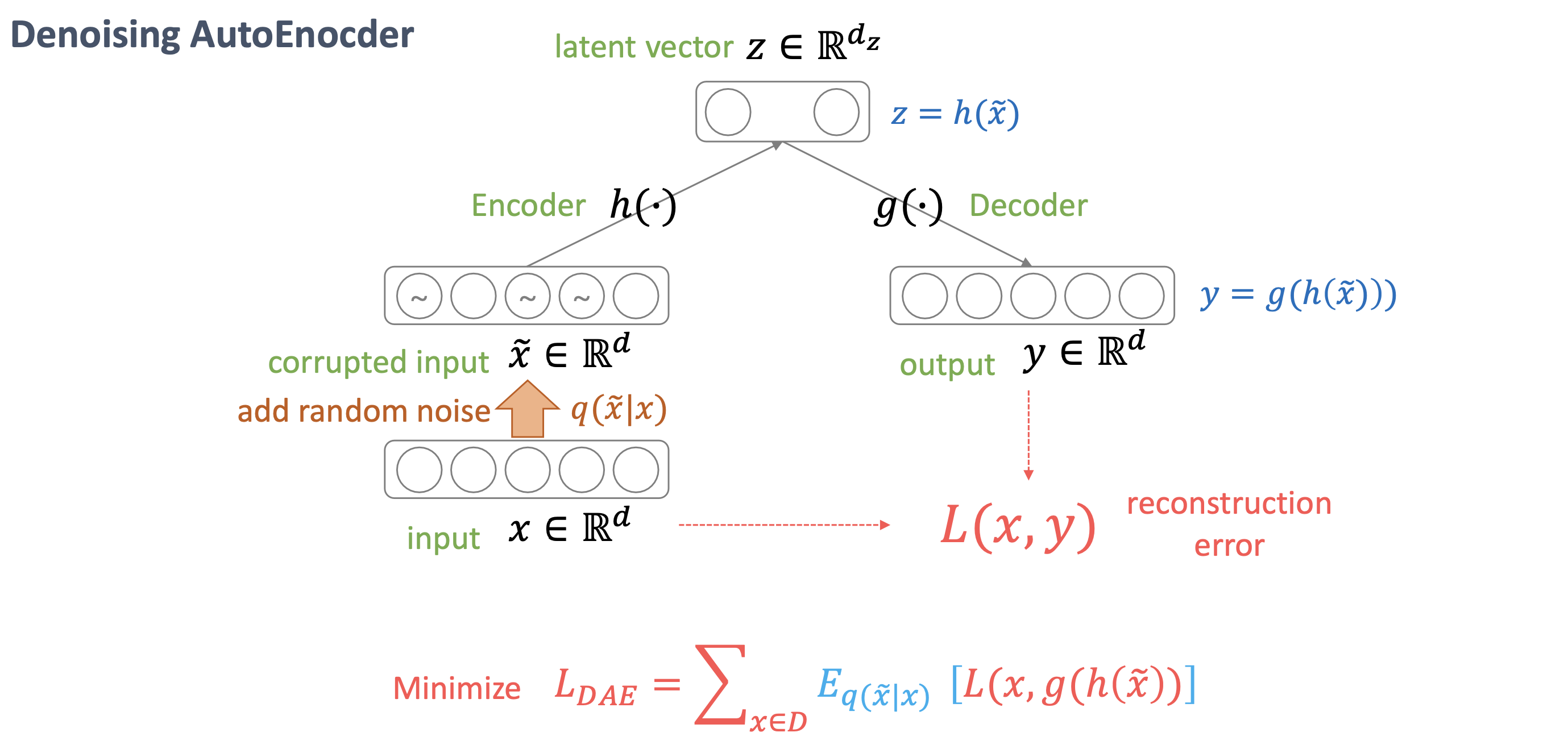
다음은 Denoising에 관련된 내용이다. 이전까지는 이미지를 넣을 때 원본 그대로를 넣었지만, 노이즈와 함께 넣고난 뒤 복원된 결과인 y는 노이즈가 섞이기 전의 x여야 한다는 것이 핵심이다. 노이즈가 섞인 데이터를 넣고 노이즈가 없는 데이터를 얻는 과정이기 때문에 Denoising AutoEncoder라고 부른다. 노이즈를 추가할 때는 알아보지 못할 정도로 추가하는 것이 아니라, 사람이 보기에도 원래의 형상이 보일 정도로 적당히 넣어야 한다.

위 사진은 오토인코더의 레이어에서 feature를 시각화한 것이다. 확실히 edge가 더 잘 detect되는 것을 볼 수 있다.

위에서는 AutoEncoder와 Denoising AutoEncoder의 차이를 확실하게 보여주는 feature visualitation이다. AutoEncoder는 랜덤하게 분포되어 있지만, Denoising AutoEncoder는 확실히 edge를 다양한 방향으로 잘 보고있는 것을 알 수 있다.
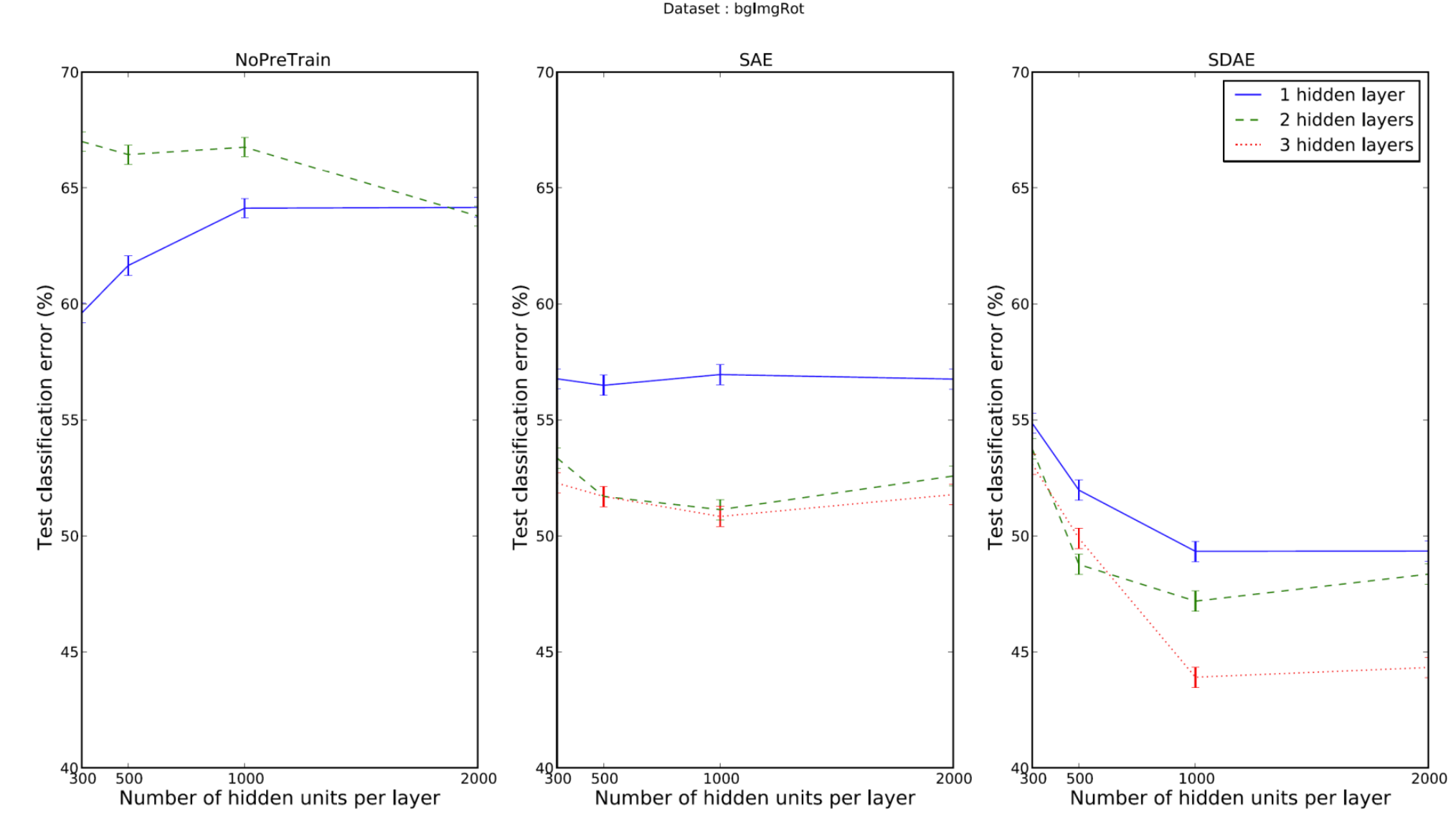
다음은 더 나아가서 Stacking AutoEncoder와 Stacking Denoising AutoEncoder를 비교해보았다. error(오차)를 살펴보니 Stacking Denoising AutoEncoder이 더 좋은 성능을 보여주는 것을 알 수 있었다.

CAE는 Contractive AutoEncoder인데 참고용….이라고 한다. 확실히 노이즈를 넣고 decode하는 방법이 feature를 잘 잡는 것 같다. 오늘도 드는 생각이지만 “왜 그렇게 했는가?”는 설명하기 힘들고 “노이즈를 넣고 원본을 복원하는 방식으로 잘 되더라~”인 것 같다. 딥러닝 분야도 만사가 능통인 건 아니고 끊임 없이 탐구하는 자연과학 연구와 별 다를 게 없는 것 같다. 그래서 다른 공학 분야들 보다 연구가 더 활발한거 아닐까 싶다.
