저번 포스트에 이어서 ‘오토인코더의 모든 것’이라는 강의를 듣고 공부하였다. Manifold learning에 대해서 적어볼 예정이다!
Manifold learning
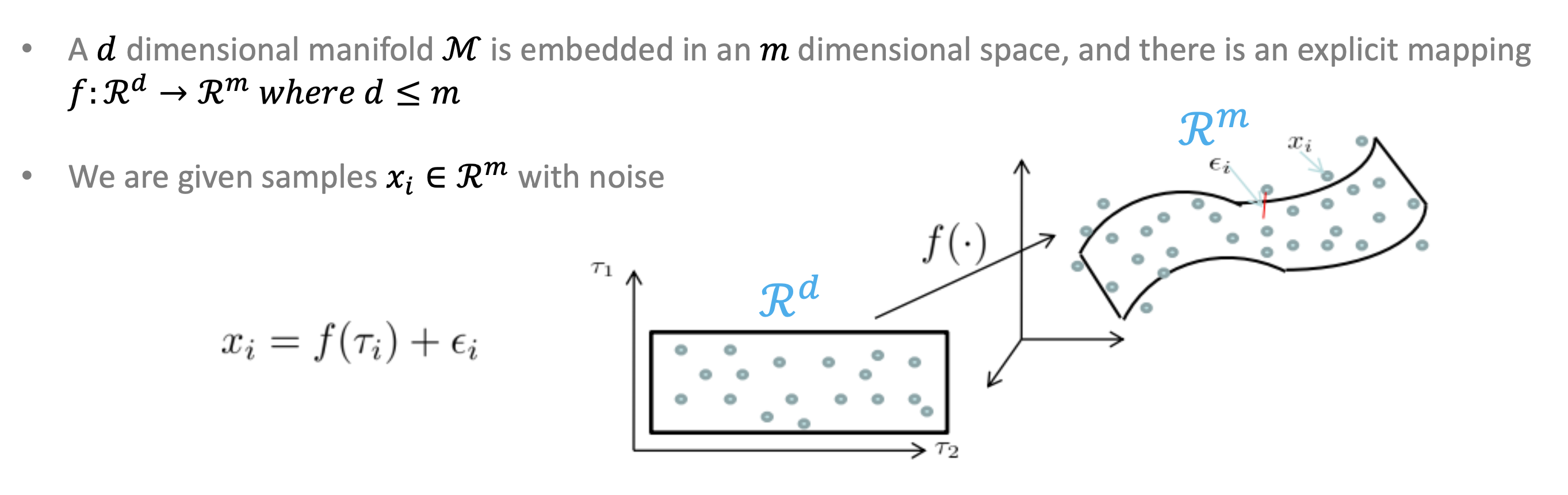
manifold는 엄청나게 복잡한 차원의 데이터를 2차원 혹은 3차원으로 축소시켰을 때 training data를 잘 아우르는 subspace가 있을 것이다!라고 추정할 수 있다는 의미를 가지고 있다.
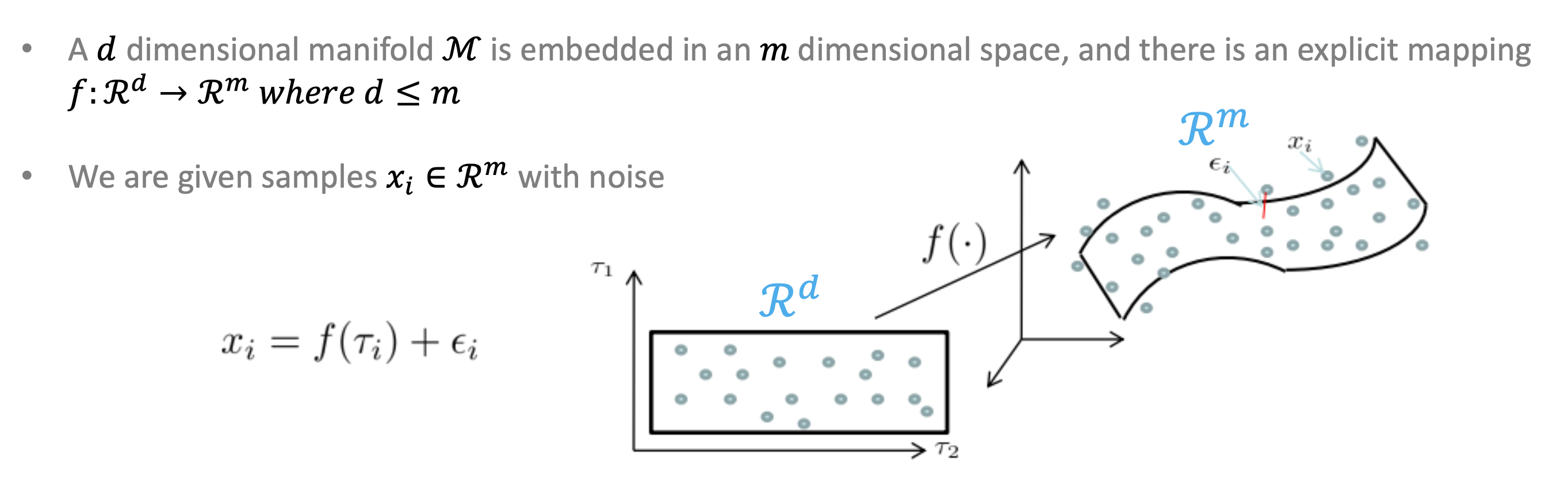
쉽게 말하자면 데이터를 압축해서 줄이고 싶다는 말이다. 그리고 사실 3차원이 넘으면 visualize를 하기 힘들다는 이유도 있긴 하다.
차원을 줄였을 때 그 줄인 데이터의 feature가 어떠한 의미를 가지고 있지 않을까?라는 생각을 가지고 시작한 것인데 확인해보니 실제로도 그렇다
Curse of dimensionaltiy
직역하자면 차원의 저주이다. 쉽게 설명하자면 차원이 점점 증가할 수록 공간이 기하급수적으로 커지므로 데이터의 밀도가 낮아지고 이는 당연하게 학습 성능 저하로 이어진다는 것이다.
공간 상에서 여러가지 데이터가 섞여있을 때 random sampling을 하면 당연히 노이즈만 섞여서 보일 것이라고 예측할 수 있다. 만약에 같은 부류의 데이터(ex. 같은 사람의 얼굴, 폰트 등)을 넣고 uniform sampling을 하면 분명 관계성이 있는 manifold가 존재할 것이라고 추정할 수 있다.
강의 당시(2017~2018년)에는 512x512와 같은 정도도 고차원 수준의 데이터이다. MNIST 데이터로 보았을 때 4를 적은 손글씨 데이터들이 아래와 같이 manifold를 이루고 있을 것이라고 추정할 수 있다. 아마 보는 사람들이 편하게 곡면으로 그린 것 같은데, 실제로 시각화한 manifold는 분명 다르지 않을까 생각한다.

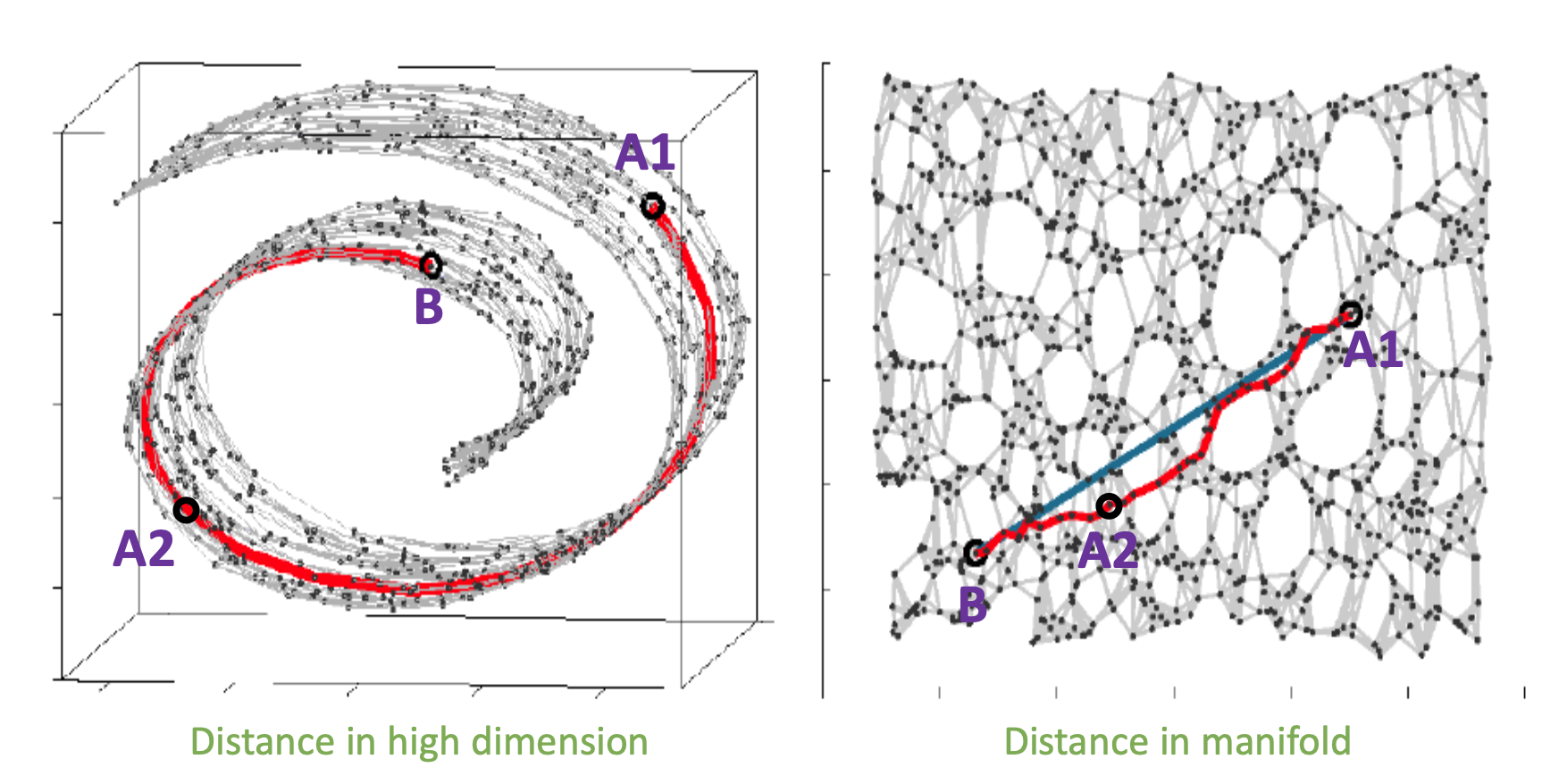
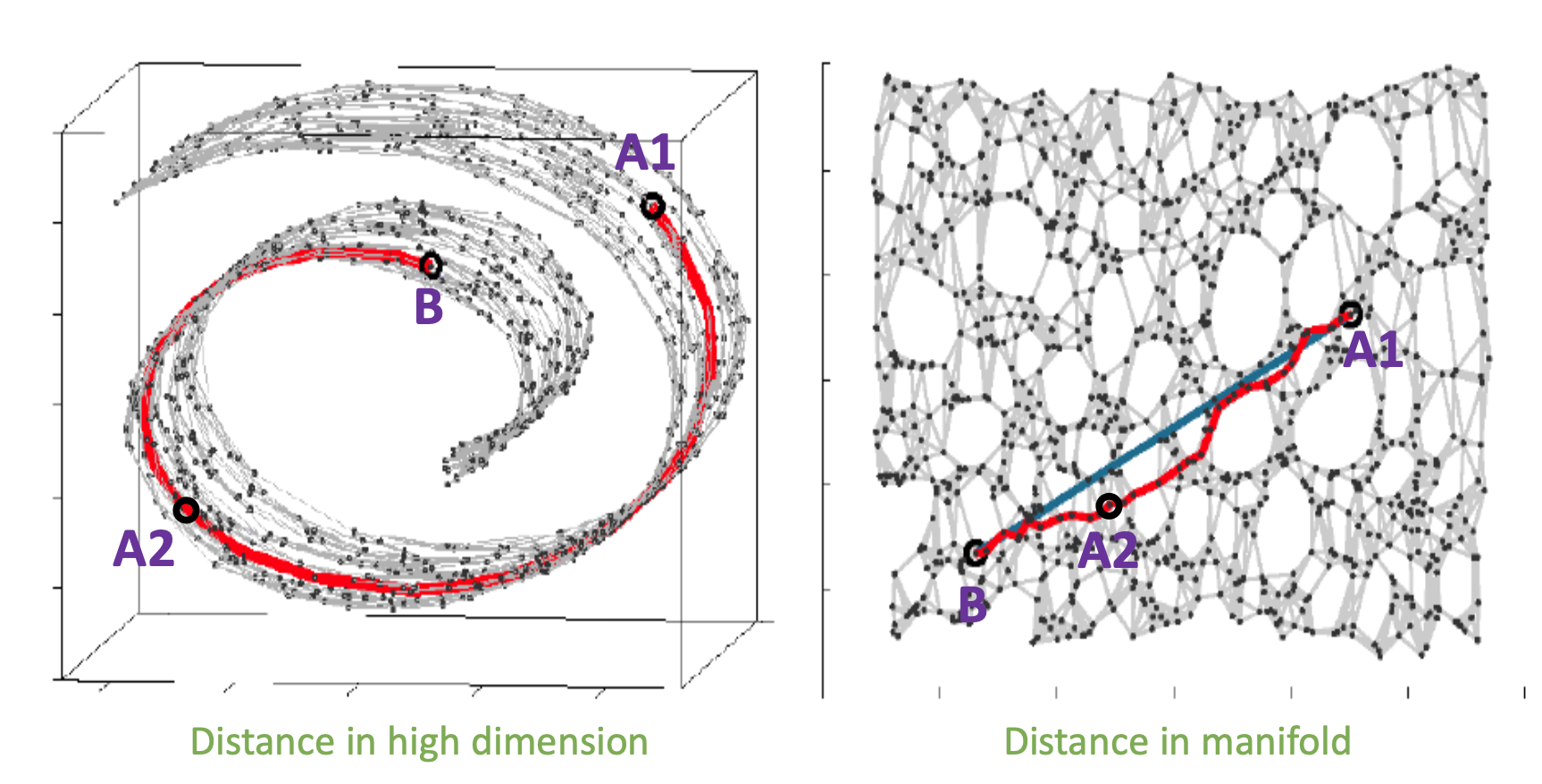
그렇다면 이제 가까운, 즉 유사한 데이터는 어떻게 찾는가?에 대해서 논해볼 때이다. 밑의 그림에서 B와 더 가까운 데이터는 어떤 것일까?
일반 공간 상의 물리적인 거리로는 A1이 맞다. 하지만 데이터들이 이루고 있는 manifold 위에서는 A1과의 거리보다 A2와의 거리가 더 짧다. 오른쪽의 그림처럼 차원을 더 줄였을 때는 A2가 더 가깝다는 것을 알 수 있다.
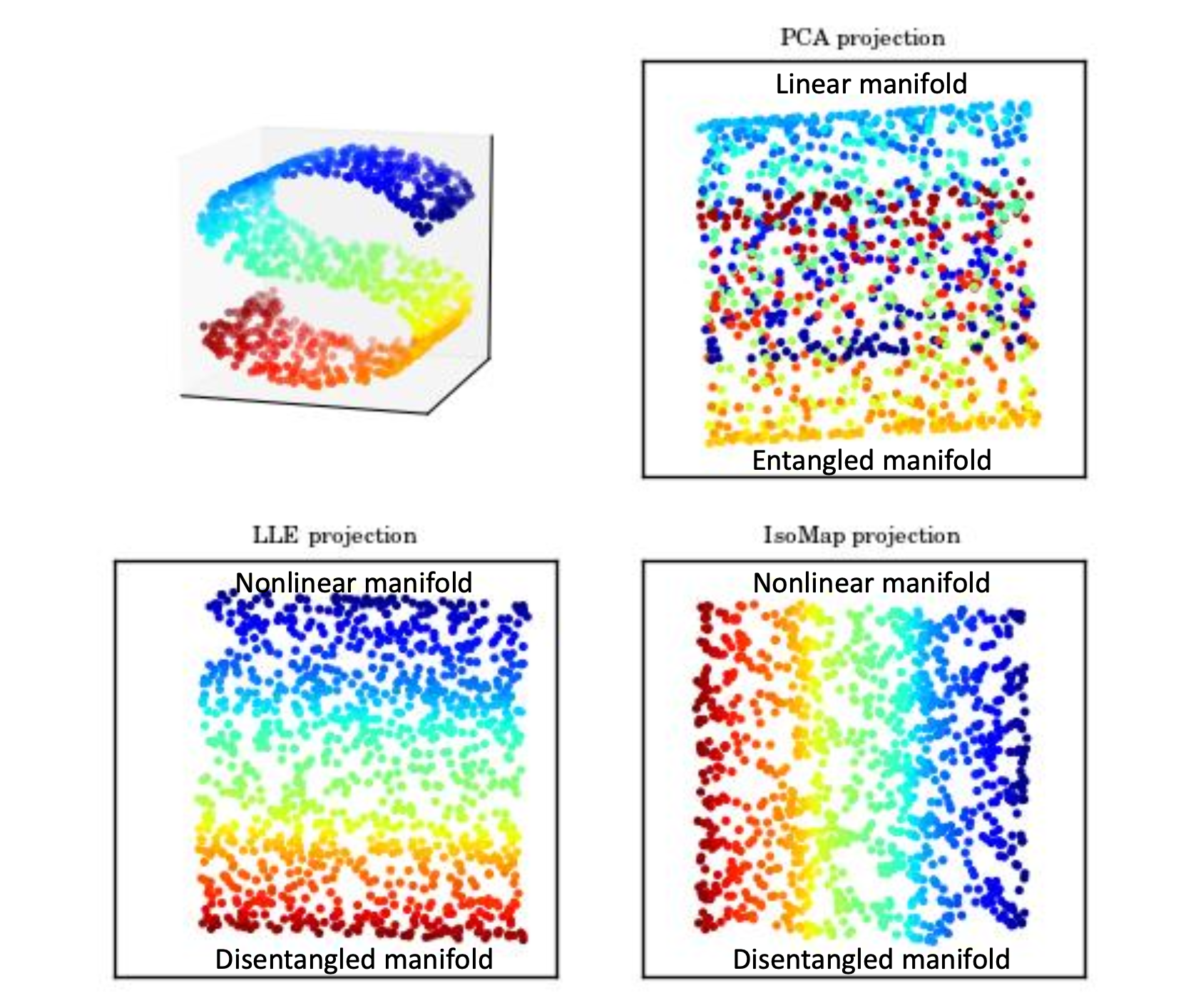
이제 manifold를 투영해서 섞여있는(entangled) 데이터들을 잘 분류해야 한다. 투영한다는 것은 앞서 언급했던 차원을 축소한다는 것과 같은 말이고 linear하게 projection했을 때에는 정말 운이 좋은 경우가 아니라면 entangled manifold가 얻어질 수 밖에 없다. 그래서 LLE projection, IsoMap projection과 같은 nonlinear projection이 필요하다.
Manifold learning의 결론은 Neighbourhood based learning이라는 것이다. 2, 3차원에서는 유클리디안 거리가 분명 의미 있는 거리이지만 오토인코더에서는 고차원 데이터를 다룬다는 것을 가정하기 때문에 neighborhood가 더 의미 있는 것이다! 여기서 neighborhood를 가르는 기준은 manifold 위에서의 거리로 판단하는 것이다.

