버블정렬이란?
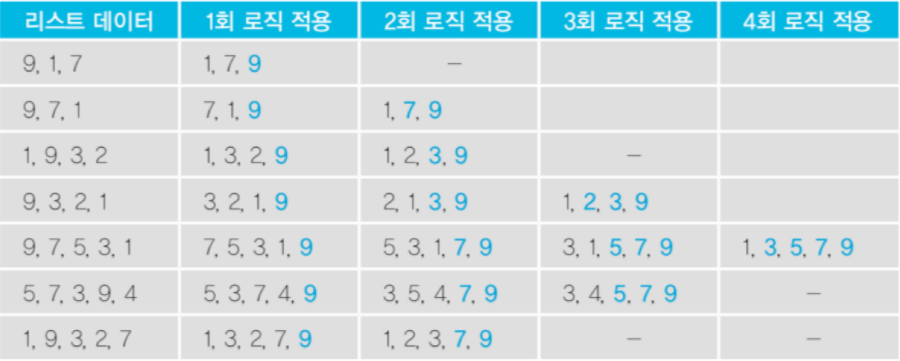
- 두 인접한 데이터를 비교하여, 앞에 있는 데이터가 뒤에 있는 데이터보다 크면, 자리를 바꾸는 정렬 알고리즘
- n개의 리스트가 있는 경우 최대 (n-1)번의 로직을 적용한다.
- 로직을 1번 적용할 때마다 가장 큰 숫자가 뒤에서부터 1개씩 결정된다.
- 로직이 경우에 따라 일찍 끝날 수도 있다. 따라서 로직을 적용할 때 한 번도 데이터가 교환된 적이 없다면 이미 정렬된 상태이므로 더 이상 로직을 반복 적용할 필요가 없다.
- for num in range(len(data_list)) 반복
- swap = 0 (교환이 되었는지를 확인하는 변수를 두자.)
- 반복문 안에서, for index in range(len(data_list) - num - 1) #n-1번 반복해야 하므로
- 반복문안의 반복문 안에서, if data_list[index] > data_list[index + 1]이면
- data_list[index]. data_list[index + 1] = data_list[index + 1], data_list[index]
- swap += 1
- 반복문 안에서, if swap == 0 이면, break 끝
def bubblesort(data):
for index in range(len(data) - 1):
swap = False
for index2 in range(len(data) - index - 1):
if data[index2] > data[index2 + 1]:
data[index2], data[index2 + 1] = data[index2 + 1], data[index2]
swap = True
if swap == False:
break
return dataimport random
data_list = random.sample(range(100), 50)
print(bubblesort(data_list))알고리즘 분석
- 반복문이 두 개 -> O(𝑛2)
- 최악의 경우, 𝑛∗(𝑛−1) / 2 - 완전 정렬이 되어 있는 상태라면 최선은 O(𝑛)

자율주행 개발자가 되고싶은 대학생입니다.