이번 Toss Payments API(PG사)를 활용한 결제 시스템을 개발하며 정산 시스템에 대한 지속적이고 대량의 배치 처리가 필요한 이슈가 발생해 골머리를 앓았습니다... 특히 정산 엔티티를 통해 관리되는 결제 정산 내역을 효율적으로 처리하기 위한 기술적 스택이 필요해 심사숙고 한 결과! 분산 메시징 시스템인 Kafka를 도입하기로 결정했습니다.
Kafka는 높은 처리량, 데이터 내구성, 장애 복원력을 갖추고 있어 정산 트래픽 급증 시에도 안정적인 데이터 처리가 가능하여 지금 이슈를 해결하기 딱 알맞은 스택이라 생각이 들었습니다. 그리하여 이 글에서는 프로젝트에 적용하기 전 제가 공부한 Kafka의 기본 아키텍처와 이를 결제 정산 시스템에 적용한 로직 흐름에 대해 정리하고자 합니다.
"분산 시스템은 하나의 컴퓨터가 다운되어도 전체 시스템이 계속 작동하는 시스템이 아니라, 하나의 컴퓨터가 다운되었는데 아무도 눈치채지 못하는 시스템이다." - 레슬리 램포트
Kafka란 무엇인가?
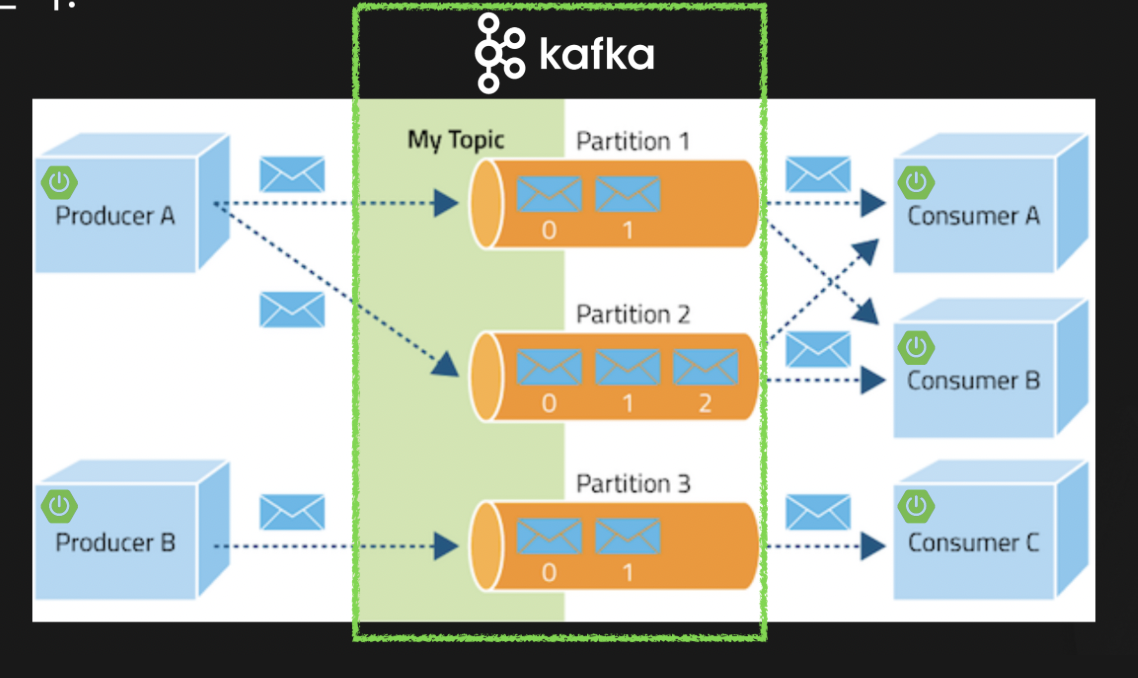
Kafka는 대량의 데이터를 안정적이고 실시간으로 처리할 수 있도록 설계된 분산 메시징 플랫폼입니다. LinkedIn에서 처음 개발되어 현재는 Apache 프로젝트로 성장한 Kafka는 단순한 메시지 큐를 넘어서 실시간 데이터 파이프라인과 스트리밍 애플리케이션을 구축할 수 있는 기반을 제공합니다. - 스프링에서 개발된 것도 있지만 그건 잘 안쓴다는...
공식 문서에 따르면 Kafka는 다음과 같이 정의됩니다.
대량의 데이터를 안정적이고 실시간으로 처리할 수 있도록 설계된 메시징 플랫폼을 말한다.
기업에서 대규모 데이터 처리 및 이벤트 기반 시스템을 구축하는데 널리 사용되며 인체에 **중추 신경계에**
해당하는 역할을 수행한다.처음에는 "또 하나의 메시지 큐 시스템인가... 중추 신경계라는 무슨 말이지?" 생각했는데, 공부할수록 Kafka의 설계 철학과 scaleablitiy에 감탄하게 됐습니다. 하루 종일 문서를 읽고 유튜브 강의를 보면서 이 기술의 깊이를 이해하려고 노력했고, 특히 로그 중심 아키텍처가 가져오는 이점에서 얼른 내 PG사 프로젝트에 도입해야 겠다는 생각을 했습니다.
Kafka vs 전통적인 메시지 큐의 차이점| 특징 | 전통적인 메시지 큐 | Kafka |
|---|---|---|
| 메시지 보존 | 소비 후 삭제 | 설정된 기간 동안 보존 |
| 확장성 | 제한적 | 높은 수평 확장성 |
| 처리량 | 중간 | 매우 높음 (초당 수백만 메시지) |
| 메시지 재처리 | 어려움 | 쉬움 (Offset 기반) |
| 순서 보장 | 부분적 | 파티션 내에서 완벽히 보장 |
| 복잡성 | 낮음 | 중간~높음 |
Kafka의 핵심 구성 요소
Producer: 메시지 생산자
Producer는 Kafka의 브로커에게 메시지를 발행하는 주체입니다. (브로커는 아래에서 설명드리겠습니다.) 이미지에서 볼 수 있듯이, Producer는 "보내는 이, 저자, 에디터"의 역할을 수행하며, 다음과 같은 핵심 과정을 거칩니다.
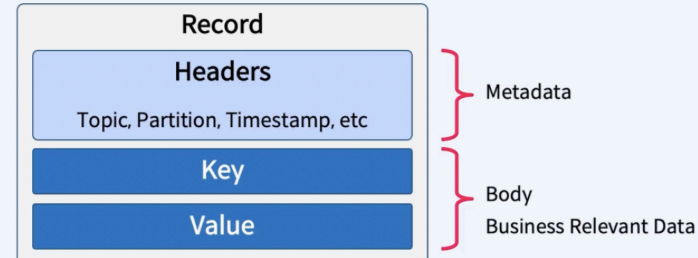
1. Records 직렬화
메시지를 직렬화하여 Key와 Value를 바이트로 변환합니다. 대표적인 직렬화 포맷은 JSON과 Avro가 있습니다.
JSON: 사람이 읽기 쉬운 텍스트 기반의 경량 데이터 교환 형식으로, 키-값 쌍으로 구성된 객체와 배열을 표현
Avro: 바이너리 기반의 데이터 직렬화 시스템
// JSON 직렬화 예시
StringSerializer keySerializer = new StringSerializer();
JsonSerializer<OrderEvent> valueSerializer = new JsonSerializer<>();2. 파티셔닝(Partitioner)
토픽의 어떤 파티션에 저장할지 결정하는 과정입니다. Partitioner는 정의된 로직에 따라 파티셔닝을 진행하는데, 별도의 설정을 하지 않으면 Round Robin 형태로 파티셔닝을 수행합니다.
// 커스텀 파티셔너 예시
public class CustomPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
// 주문 ID를 기준으로 동일한 주문은 항상 같은 파티션에 할당 => 지정 안 할 시 Round Robin 방식 수행
return Math.abs(key.hashCode()) % cluster.partitionCountForTopic(topic);
}
// ...기타 메서드 생략...
}3. 압축(Compression)
파티셔닝으로 어느 파티션으로 연결될지 결정 되었다면 해당 데이터(메시지)를설정된 포맷에 맞춰 압축합니다. 압축된 메시지는 브로커로 빠르게 전달할 수 있고 브로커 내부에서 빠른 복제가 가능합니다.
// 압축 설정 예시
props.put("compression.type", "gzip"); // gzip, snappy, lz4, zstd 중 선택간단히 압축된 데이터 예시를 보여드리겠습니다.
압축 전 메시지는 약 100byte의 용량을 차지하지만.
{
"order_id": "ORD-12345",
"customer_id": "CUST-789",
"timestamp": 1712579335,
"total_amount": 15000
}압축 후 (gzip 적용) 용량은 대략 66byte로 큰폭 감소해 성능적인 이점을 가져갈 수 있습니다.
H4sIAAAAAAAA/6tWSlavVjKpLEhVslJQSs7PK0nNK8lIVbIyNHX0C/Y1VNJRKi5ITE4FsQtz
zCGcktSKEiUrAAAAAP//4. 메시지 배치(Record Accumulator)
Producer는 메시지를 TCP 통신을 통해 Broker Leader 파티션으로 전송합니다. 메시지마다 전송하지 않고 네트워크 리소스를 효율적으로 사용하기 위해서 지정된 수 만큼 메시지를 저장해놓고 있다가 한 번에 브로커로 전달합니다. 브로커 Leader에 대해서는 아래 더 자세히 정리해 보겠습니다! Jdbc 배치 전략이 생각나는....
// 배치 설정 예시
props.put("batch.size", "16384"); // 16KB
props.put("linger.ms", "10"); // 최대 10ms 대기 후 전송5. 전달(Sender)
지정한 수 만큼 메시지가 배치 큐(Batch Queue)에 쌓이면 Sender가 Broker에게 레코드 배치(Record Batch) 형태로 전달합니다.
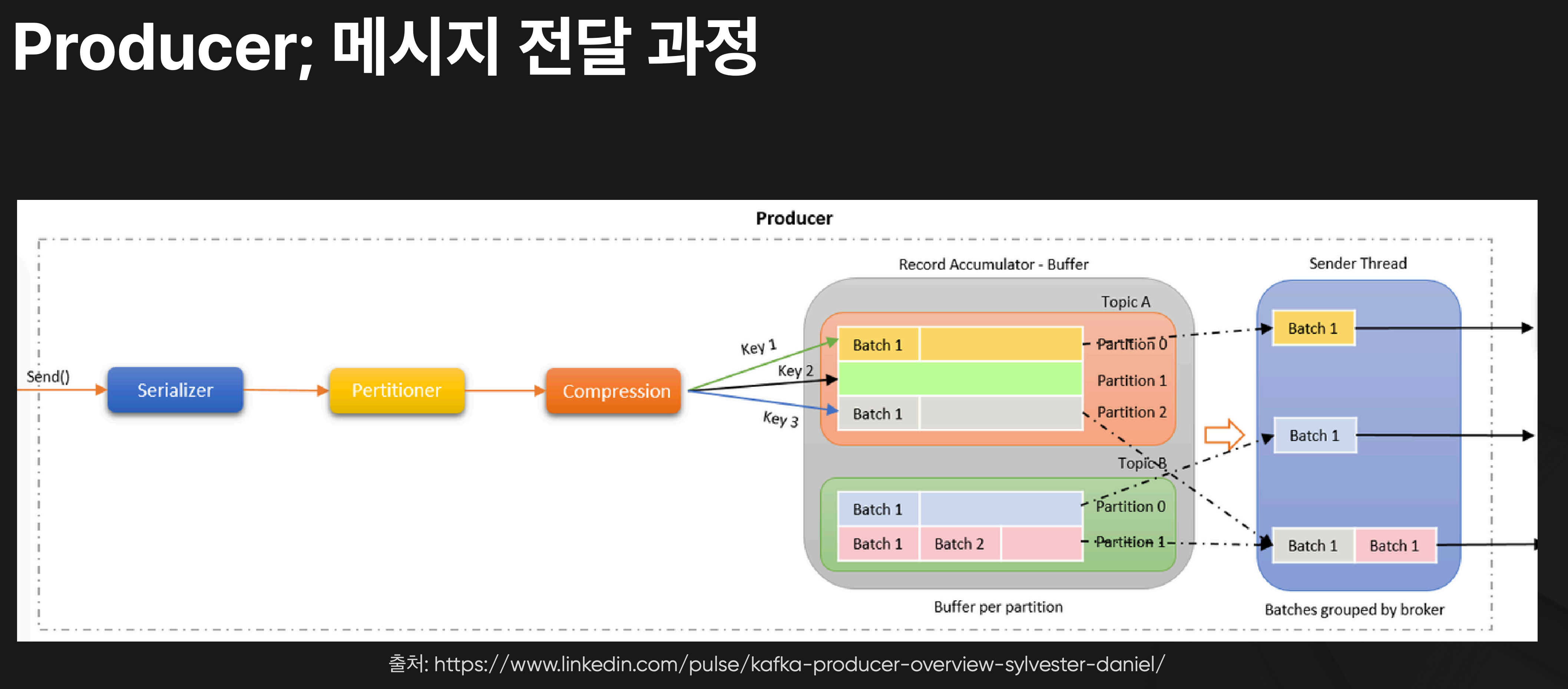
이렇게 Producer가 전송한 메시지들은 Kafka의 Topic과 Partition으로 전달됩니다. Producer의 파티셔닝 과정에서 언급했던 것처럼, 각 메시지는 특정 Topic의 Partition으로 전송되는데, 이 Topic과 Partition은 메시지를 어떻게 구조화하고 저장하는지를 결정하는 중요한 개념입니다. 다음으로 이 Topic과 Partition의 구조와 특징에 대해 살펴보겠습니다.
Topic과 Partition: 메시지 조직화
Topic은 Producer가 발행하는 메시지를 구분하는 기준(단위) 발행된 메시지를 구분하는 역할을 합니다. Topic은 여러 개의 Partition으로 나뉘는데, 이 구조가 Kafka의 병렬 처리 능력의 핵심입니다.
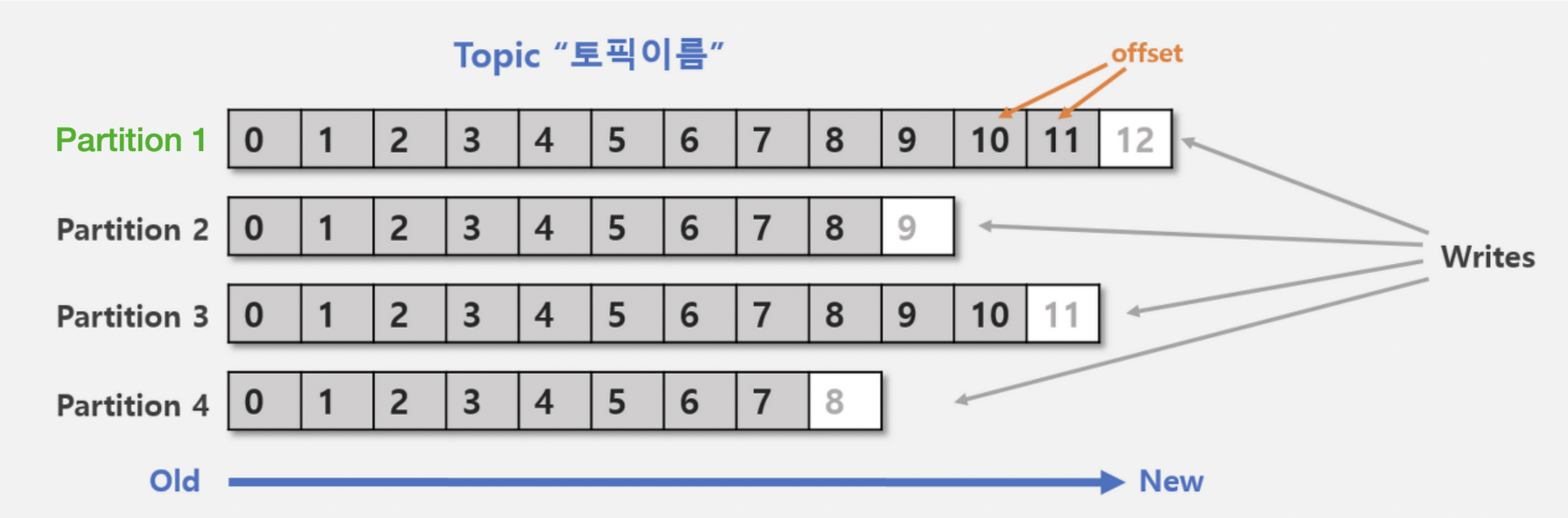
Topic에 대해 책이나 문서에서는 단순히 "메시지를 구분하는 기준"이라고만 설명하는 경우가 많았습니다. 직접 코드를 작성해보니 Topic은 사실상 '데이터의 카테고리' 또는 데이터의 파티셔닝 개념에 가깝다는 걸 느꼈습니다.
제가 이해한 Topic의 특징들을 정리해 봤습니다!
-
Topic은 단순한 '분류' 이상으로, 데이터의 흐름을 논리적으로 격리하는 파이프라인 자체입니다. 관계형 DB의 테이블이나 독립적인 큐 시스템과 유사한 역할을 한다는 생각이 들었습니다. 여기서 "논리적"으로 작동하는 것이 포인트 입니다.
-
하나의 Topic에는 다양한 메시지가 포함될 수 있지만, 일반적으로는 동일한 스키마나 포맷을 가진 메시지들을 하나의 Topic으로 그룹화합니다.
-
Partition은 실제 물리적인 로그 파일입니다. 처음에는 추상적 개념으로 생각했으나, 실제로는 디스크에
topic명-partition번호형태의 파일로 저장됩니다. -
Offset은 단순한 일련번호가 아니라 메시지의 '주소' 역할을 합니다. 각 메시지는 (Partition, Offset) 조합으로 유일하게 식별됩니다. 해당 Offset Commit 전략으로 Auto Commit, CommitSync, CommitAsync 전략이 존재합니다. (해당 전략들은 아래 상세히 정리하겠습니다.)
-
메시지가 항상 끝에만 추가되는(append-only) 구조는 처음에는 제한적으로 느껴졌으나, 이 특성이 오히려 순차적 I/O를 가능하게 하여 Kafka의 초고속 처리 성능의 핵심임을 알게되었습니다.
# 토픽 생성 명령어 예시
kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 3 \
--partitions 6 \
--topic user-eventsPartition을 여러 개로 나누면 병렬 처리 능력이 향상되지만, 특정 키에 대한 순서를 보장받고 싶다면 파티션 키 설계에 각별한 주의가 필요합니다. 예를 들어 사용자 ID를 키로 사용하면, 같은 사용자의 이벤트는 항상 같은 파티션에 저장되어 순서가 보장됩니다.
Offest Commit 전략
Kafka Consumer는 메시지를 읽고 처리한 후, 어디까지 처리했는지를 기록하기 위해 offset을 commit 합니다. 오프셋 커밋 방식에 따라 메시지 처리의 신뢰성과 성능이 달라질 수 있어 상황에 맞는 전략 선택이 중요합니다.
1. Auto Commit (Batch Type)
Consumer가 5초 간격으로 poll()을 통해 받은 메시지 중 마지막 메시지의 오프셋을 자동으로 커밋합니다. 코드가 단순해지는 장점이 있지만, 마지막으로 커밋한지 3초 후에 Consumer가 크래시되면 리밸런싱이 발생하고, 3초 동안 읽었지만 처리를 완료하지 못한 데이터를 다시 읽게 되어 중복 처리 문제가 발생할 수 있습니다.
// Auto Commit 설정 예시
properties.put("enable.auto.commit", "true");
properties.put("auto.commit.interval.ms", "5000"); // 5초마다 자동 커밋2. Manual Commit (commitSync())
메시지를 poll()한 후 바로 수동으로 커밋을 요청하는 방법입니다. 동기식으로 작동하여 커밋이 완료될 때까지 차단됩니다. 모든 레코드 처리가 완료되기 전에 commitSync()를 호출하면, 애플리케이션이 크래시됐을 때 커밋은 됐지만 아직 처리되지 않은 메시지가 있어 데이터 누락 문제가 발생할 수 있습니다.
// Manual Sync Commit 예시
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
// 레코드 처리
processRecord(record);
}
// 모든 레코드 처리 후 커밋
consumer.commitSync();3. Manual Commit (commitAsync())
메시지를 모두 처리한 후 비동기 방식으로 오프셋 커밋을 요청하는 방법입니다. Broker에게 커밋을 요청하고 응답을 기다리지 않아 처리 속도가 빠릅니다. 그러나 가져온 데이터를 처리하고 커밋하는 과정 중에 Broker에 크래시가 발생하면, 이후 오프셋이 업데이트될 때 데이터 중복 문제가 발생할 수 있습니다.
// Manual Async Commit 예시
consumer.commitAsync((offsets, exception) -> {
if (exception != null) {
log.error("Commit failed for offsets {}", offsets, exception);
}
});각 전략 비교
| 전략 | 장점 | 단점 | 적합한 상황 |
|---|---|---|---|
| Auto Commit | • 구현 간단 • 개발자가 오프셋 관리 신경 안 써도 됨 | • 중복 처리 가능성 • 정확한 제어 어려움 | 약간의 중복 처리가 허용되는 경우 |
| Manual Sync | • 정확한 커밋 보장 • 데이터 손실 방지 | • 속도 느림 • 잘못 사용 시 데이터 누락 가능 | 모든 메시지 처리가 중요한 금융/결제 시스템 |
| Manual Async | • 높은 처리량 • 성능 우수 | • 오류 처리 복잡 • 커밋 실패 시 대응 필요 | 높은 처리량이 필요하고 간헐적 중복이 허용되는 경우 |
실제 프로젝트에서는 단일 전략보다는 상황에 따라 혼합하여 사용하는 경우도 많다고 합니다. 예를 들어, 일반적으로는 commitAsync()를 사용하다가 애플리케이션 종료 시에는 마지막 커밋을 확실히 하기 위해 commitSync()를 호출하는 방식입니다.
// 하이브리드 접근법 예시
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
processRecords(records);
// 비동기 커밋
consumer.commitAsync();
}
} catch (Exception e) {
log.error("Unexpected error", e);
} finally {
try {
// 종료 전 동기 커밋으로 확실하게
consumer.commitSync();
} finally {
consumer.close();
}
}시스템의 요구사항과 처리 중요도에 따라 적절한 커밋 전략을 선택하는 것이 중요한 것 같고 이러한 커밋 전략도 어떠한 메시지 또는 레코드 데이터를 분산 처리 하냐에 따라 신중히 선택해야 데이터 유실, 중복에서 그나마 안전한 설계를 할 수 있지 않을까 생각이 들었습니다. 특히 현재 진행 중인 PG사 결제 시스템과 같이 "정산", "결제 정보"등을 분산 처리해야 할 경우 데이터의 유실이 날 수 있는 전략은 무조건 피하고 중복을 어느정도 허용해 후차적으로 중복을 처리하는 방안이 좋다는 생각이 들었습니다.
Broker: Kafka의 핵심 서버
Broker는 일반적으로 "Kafka"라고 불리는 시스템을 말합니다. 즉, Broker는 Kafka의 다른 이름이라고 이해하면 좋을 것 같습니다.
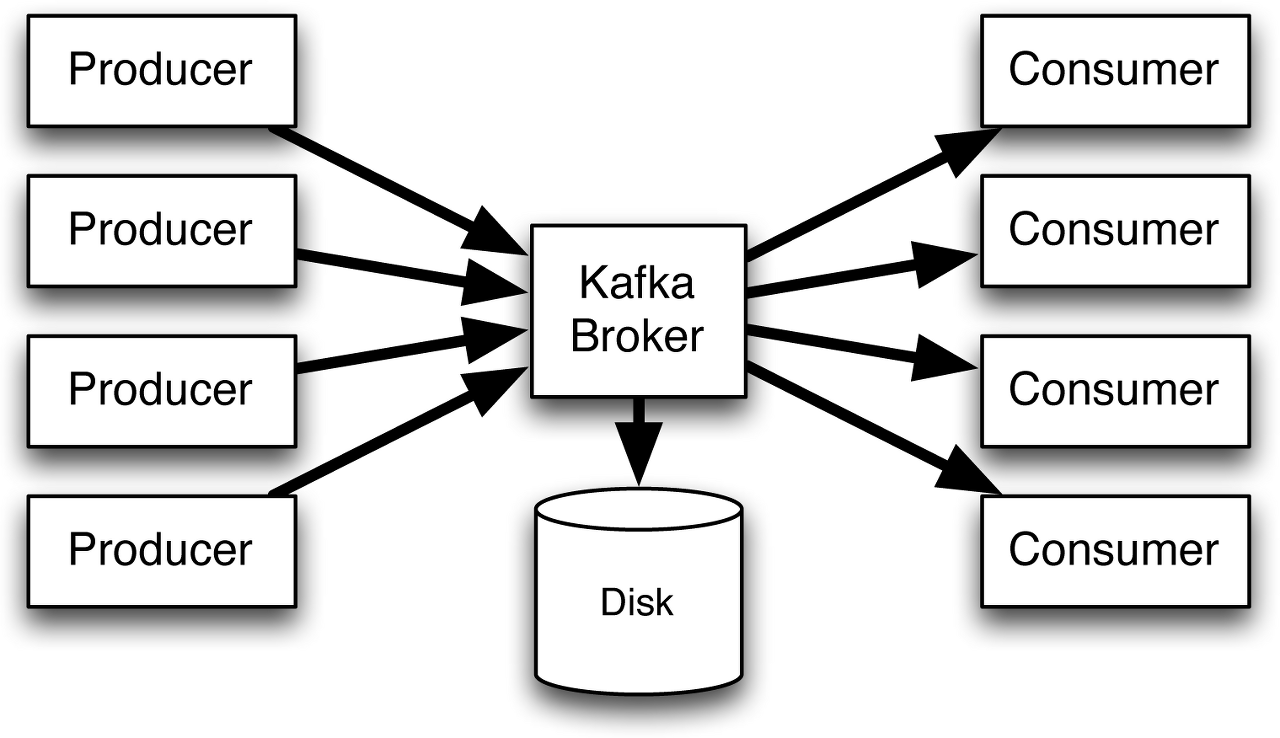
Broker의 핵심 역할
- Brokers 간의 통신을 하면서 메시지를 Primary/Replica 형태로 관리합니다. 이렇게 함으로써 메시지 유실이 없도록 하는 역할을 합니다.
- 발행한 메시지를 저장 및 삭제 등 메시지를 관리하는 역할
Broker의 주요 특징
- 메시지를 저장을 로그(Log) 자료구조 형태로 저장합니다.
- 쓰기 작업은 가장 뒤에서만 실행됩니다.
- 중간 수정 작업을 할 수 없습니다.
이러한 로그 중심 아키텍처는 Kafka가 높은 처리량과 내구성을 달성할 수 있는 핵심 요소입니다. 디스크에 순차적으로 쓰기 때문에 디스크 I/O가 효율적이며, 로그 파일이 충분히 커지면 새 세그먼트를 생성하는 방식으로 관리됩니다. 다만 중간에 파티션에 존재하는 데이터들을 수정할 수 없어 데이터에 대한 확실한 처리가 중요해 보이는 구조입니다.
Consumer: 메시지 소비자
Consumer는 Producer가 발행한 메시지를 구독하며 가져와서(Polling)하고 처리하는 주체입니다.
Consumer의 특징
- 구독하고 있는 Topic(우편함)을 지켜보고 있다가
- 새롭게 발행된 메시지를 감지하면! 가져와서 적절하게 처리하는 역할입니다.
- 지금까지 읽은 메시지의 offset을 기억합니다.
Polling 방식의 장점
다른 Message Queue와 다르게 Kafka는 메시지(Record)를 Consumer에게 전송(Push)하지 않습니다. 대신 Consumer가 메시지를 요청해서 가져(polling)옵니다. (사실상 consumer의 핵심)
// Consumer Polling 예시
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n",
record.offset(), record.key(), record.value());
// 비즈니스 로직 처리
}
}Polling 방식의 장점
- Consumer는 자신이 원하는 만큼의 Broker로 메시지를 요청할 수 있습니다.
- 각 컨슈머가 자신의 환경에 메시지 구독 성능을 최적화할 수 있다는 것입니다.(Back pressure)
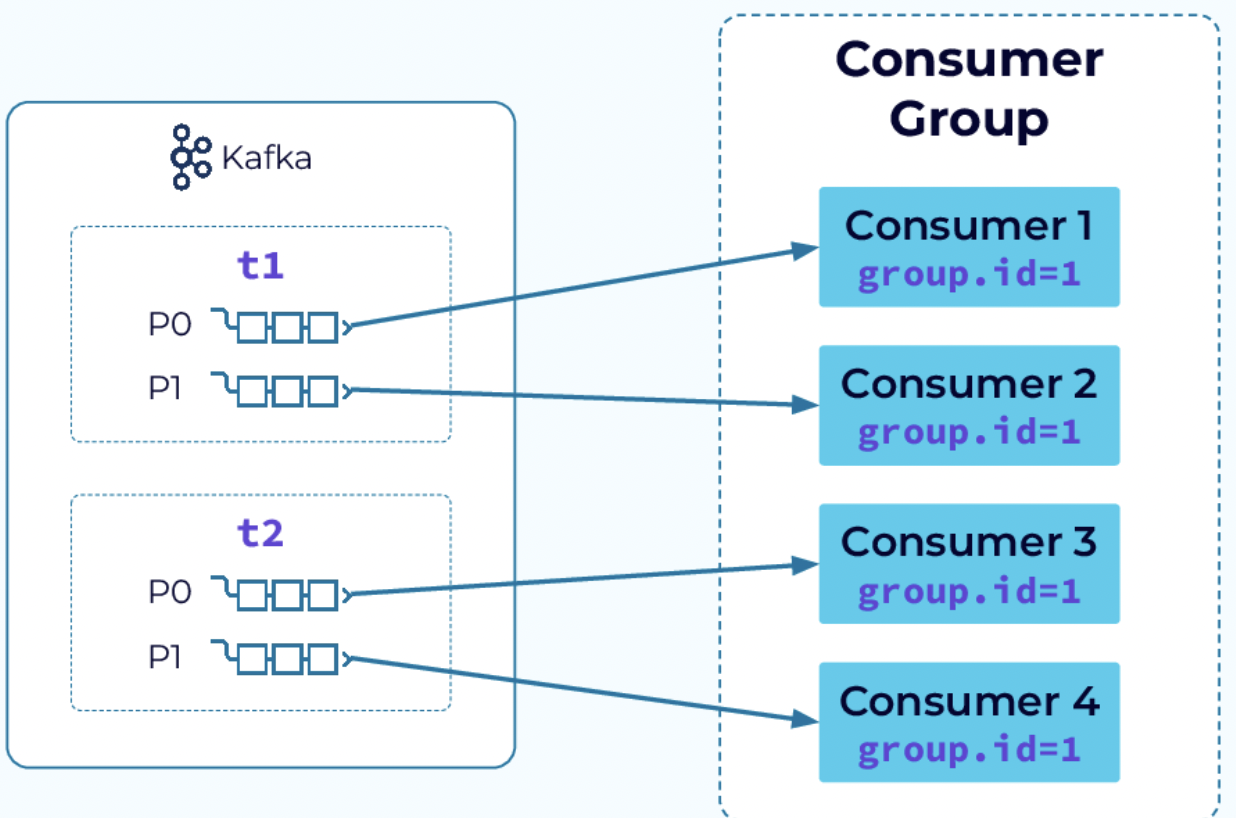
Consumer Group: 병렬 처리의 핵심
Consumer Group의 특징
- 여러 개의 Consumer가 같은 토픽으로부터 데이터를 분산해서 읽어 올 수 있습니다.
- 동일한 컨슈머 그룹에 속한 여러 개의 컨슈머들이 동일한 토픽을 구독할 경우, 각각의 컨슈머는 해당 토픽의 파티션들과 각각 1대1 매핑되고 서로 다른 파티션의 메시지를 받습니다.
이 구조는 확장성 측면에서 매우 강력합니다. 처리량을 늘리고 싶을 때는 단순히 Consumer를 추가하면 되기 때문입니다. (파티션 수 이내에서) 보통은 broker내 파티션들과 컨슈머 또는 컨슈머 그룹은 1대1 매칭되는 경우가 많습니다.
Confluent Schema Registry: 메시지 형식 관리
Confluent Schema Registry는 Kafka Client 사이에서 메시지의 스키마(구조, Format)를 저장 및 관리하는 애플리케이션입니다.
Schema Registry의 필요성
-
비즈니스 요구사항의 변경으로 발행되는 메시지의 형태만 변경이 되었고 아직 Consumers는 변경된 메시지의 형태를 알지 못하는 상황에 빠지게 된다면, Consumers는 메시지 처리를 정상적으로 하지 못하고 오류가 발생할 것입니다.
-
그래서 지속적으로 메시지가 변경되어야 하는 경우, 메시지의 스키마를 관리하고 안전한 방향으로 진화하고 있는지 확인하는 것이 중요해졌고 필요성이 제기되서 스키마 레지스트리 구조가 구현되었습니다.
스키마 진화 전략
-
Backward(Default): 스키마 배포 순서; 1. Consumer 2. Producer
새로운 스키마로 이전 데이터를 읽는 것이 가능한 것을 의미합니다. 새로운 스키마에 필드가 추가되었는데 해당 필드에 default value가 없다면 오류가 발생하고 허용을 하지 않습니다. 하지만, 새로운 스키마에 추가된 필드에 default value를 지정한 경우, 새로운 스키마 등록이 허용되고 이전 데이터를 읽을 수 있습니다. -
Forward: 스키마 배포 순서; 1. Producer 2. Consumer
이전 스키마에서 새로운 데이터를 읽는 것이 가능한 것을 의미합니다. 새로운 스키마에서 특정 필드가 삭제 된다면, 해당 필드는 스키마에서 default value를 가지고 있어야 합니다. -
Full: Backward와 Forward를 모두 만족한다는 의미입니다.
-
None: 호환성을 검사하지 않아 스키마 변경 시 기존의 스키마로 데이터를 읽는 Consumer는 오류를 일으킬 수 있습니다.
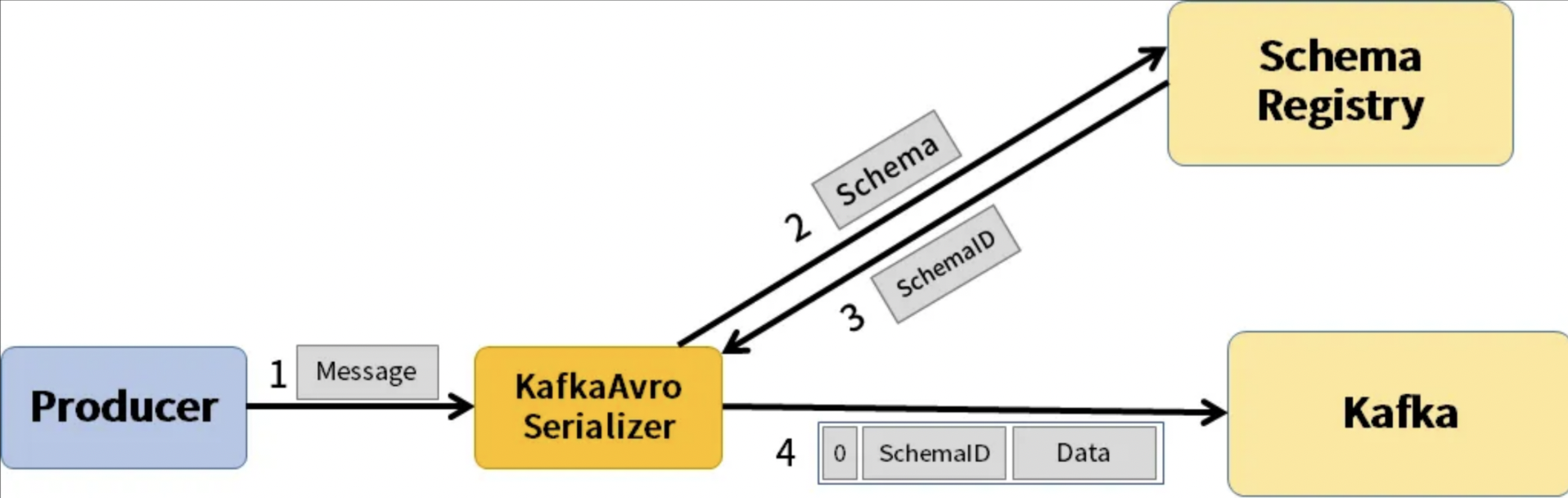
Schema Registry 동작 원리
- Producer가 메시지를 발행할 때 Apache Avro 포맷의 스키마 정보를 토대로 메시지를 발행하고 있는지 확인하고, Broker에게 메시지를 전달합니다.
- Schema Registry에 스키마 정보를 등록합니다.
- Schema Registry는 스키마 ID를 반환합니다.
- Producer는 메시지에 스키마 ID와 데이터를 포함하여 Kafka에 전송합니다.
이 구조를 통해 메시지 스키마가 변경되더라도 Producer와 Consumer 간에 호환성을 유지할 수 있습니다.
실제 코드로 알아보는 Kafka
이론적 개념을 이해한 후에는 실제 코드로 테스트해보는 과정이 중요했습니다. Spring Boot를 이용해 간단한 Producer와 Consumer를 구현하면서 이론적인 개념들을 한 번더 복습했습니다.
Producer 구현
@Service
public class KafkaProducerService {
private static final String TOPIC = "user-events";
private final KafkaTemplate<String, UserEvent> kafkaTemplate;
private final ObjectMapper objectMapper;
public KafkaProducerService(KafkaTemplate<String, UserEvent> kafkaTemplate, ObjectMapper objectMapper) {
this.kafkaTemplate = kafkaTemplate;
this.objectMapper = objectMapper;
}
public void sendUserEvent(String userId, UserEvent event) {
log.info("Sending user event: {} for user: {}", event, userId);
// 1. 직렬화 (KafkaTemplate이 자동으로 처리)
// 2. 전송 (파티셔닝은 userId 기준으로 자동 처리)
ListenableFuture<SendResult<String, UserEvent>> future =
kafkaTemplate.send(TOPIC, userId, event);
// 3. 비동기 결과 처리
future.addCallback(new ListenableFutureCallback<SendResult<String, UserEvent>>() {
@Override
public void onSuccess(SendResult<String, UserEvent> result) {
log.info("Message sent successfully: topic={}, partition={}, offset={}",
result.getRecordMetadata().topic(),
result.getRecordMetadata().partition(),
result.getRecordMetadata().offset());
}
@Override
public void onFailure(Throwable ex) {
log.error("Failed to send message", ex);
// 재시도 로직 또는 에러 처리
}
});
}
}Producer 설정 (application.yml)
spring:
kafka:
producer:
bootstrap-servers: localhost:9092
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
properties:
# 배치 설정
batch.size: 16384
linger.ms: 1
# 압축 설정
compression.type: snappy
# 안정성 설정
acks: all
retries: 3Consumer 구현
@Service
public class KafkaConsumerService {
private final ObjectMapper objectMapper;
public KafkaConsumerService(ObjectMapper objectMapper) {
this.objectMapper = objectMapper;
}
@KafkaListener(
topics = "user-events",
groupId = "user-analytics-group",
containerFactory = "kafkaListenerContainerFactory"
)
public void consumeUserEvent(ConsumerRecord<String, String> record) {
try {
log.info("Received message: topic={}, partition={}, offset={}, key={}",
record.topic(), record.partition(), record.offset(), record.key());
// JSON을 객체로 변환
UserEvent event = objectMapper.readValue(record.value(), UserEvent.class);
// 비즈니스 로직 처리
processUserEvent(event);
// 오프셋은 KafkaListener가 자동으로 커밋
} catch (Exception e) {
log.error("Error processing message", e);
// 에러 처리 로직 (Dead Letter Queue, 재시도 등)
}
}
private void processUserEvent(UserEvent event) {
// 실제 비즈니스 로직 구현
log.info("Processing event: {}", event);
// 예: DB 저장, 분석, 알림 등
}
}Consumer 설정 (application.yml)
spring:
kafka:
consumer:
bootstrap-servers: localhost:9092
group-id: user-analytics-group
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
properties:
# 한 번에 가져올 최대 레코드 수
max.poll.records: 500
# 오프셋 커밋 전략
enable.auto.commit: falseSchema Registry 활용 예시
Schema Registry를 사용할 경우, Avro 직렬화/역직렬화를 설정해야 한다는 걸 잊고 안 했다가... 너무 고생했습니다.
// Avro 스키마 예시 (user-event.avsc)
{
"namespace": "com.example.events",
"type": "record",
"name": "UserEvent",
"fields": [
{"name": "eventId", "type": "string"},
{"name": "eventType", "type": "string"},
{"name": "timestamp", "type": "long"},
{"name": "userId", "type": "string"},
{"name": "data", "type": ["null", "string"], "default": null}
]
}Producer 설정
@Configuration
public class KafkaProducerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Value("${spring.kafka.schema-registry-url}")
private String schemaRegistryUrl;
@Bean
public ProducerFactory<String, GenericRecord> producerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class);
configProps.put("schema.registry.url", schemaRegistryUrl);
return new DefaultKafkaProducerFactory<>(configProps);
}
@Bean
public KafkaTemplate<String, GenericRecord> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}실습을 통한 복습
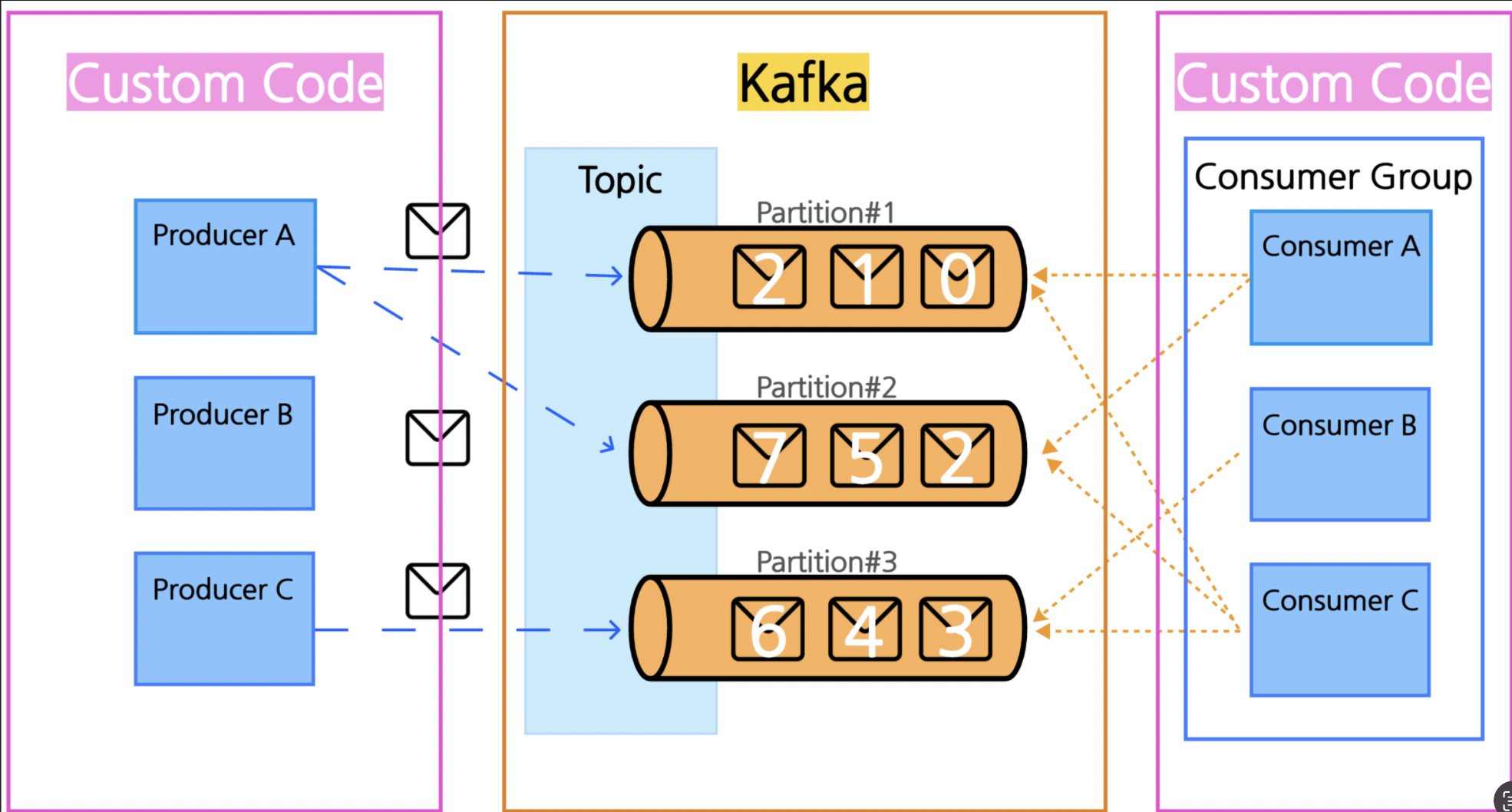
현재 진행 중인 PG사 결제 처리 시스템 구축 프로젝트에 Kafka를 도입하려는 계획을 세웠습니다. 이유는 아이템 결제 후 정산 결과에 대한 배치 시스템이 필요했기 때문입니다.
처음에는 기본적인 REST API 컨트롤러로 구현을 했다가 만약에 해당 프로젝트 규모가 커지고 트레픽이 증가했을 때 정산 요청을 한건 한건 수동으로 보내는 것은 서버 성능 이슈 및 비용이 매우 많이 들 것이라고 생각해 메시지 큐로 레코드를 관리하며 주기적으로 일정 정산 데이터가 모이면 자동으로 PG사에 정산을 요청하는 시스템 아키텍처를 생각해 봤습니다. 프로젝트에 사용하기 위에서 정리한 아키텍처를 가지고 간단히 예시 Producer와 Consumer를 만들어봤습니다.
1. 이벤트 설계
먼저 수집할 이벤트 타입과 스키마를 간단히 설계했습니다.
| 이벤트 타입 | 설명 | 필요한 데이터 |
|---|---|---|
| PageView | 페이지 조회 | userId, pageId, timestamp, referrer |
| Click | 버튼/링크 클릭 | userId, elementId, timestamp, pageContext |
| Search | 검색 수행 | userId, searchQuery, timestamp, resultCount |
| Purchase | 구매 완료 | userId, orderId, products, amount, timestamp |
2. 토픽 구성
이벤트 특성에 따라 토픽을 구성합니다.
# 사용자 행동 이벤트 (높은 볼륨)
user-behavior-events: 24 partitions, replication factor 3
# 트랜잭션 이벤트 (중요도 높음, 순서 보장 필요)
transaction-events: 12 partitions, replication factor 3
# 시스템 메트릭 (모니터링용)
system-metrics: 6 partitions, replication factor 23. 아키텍처 설계
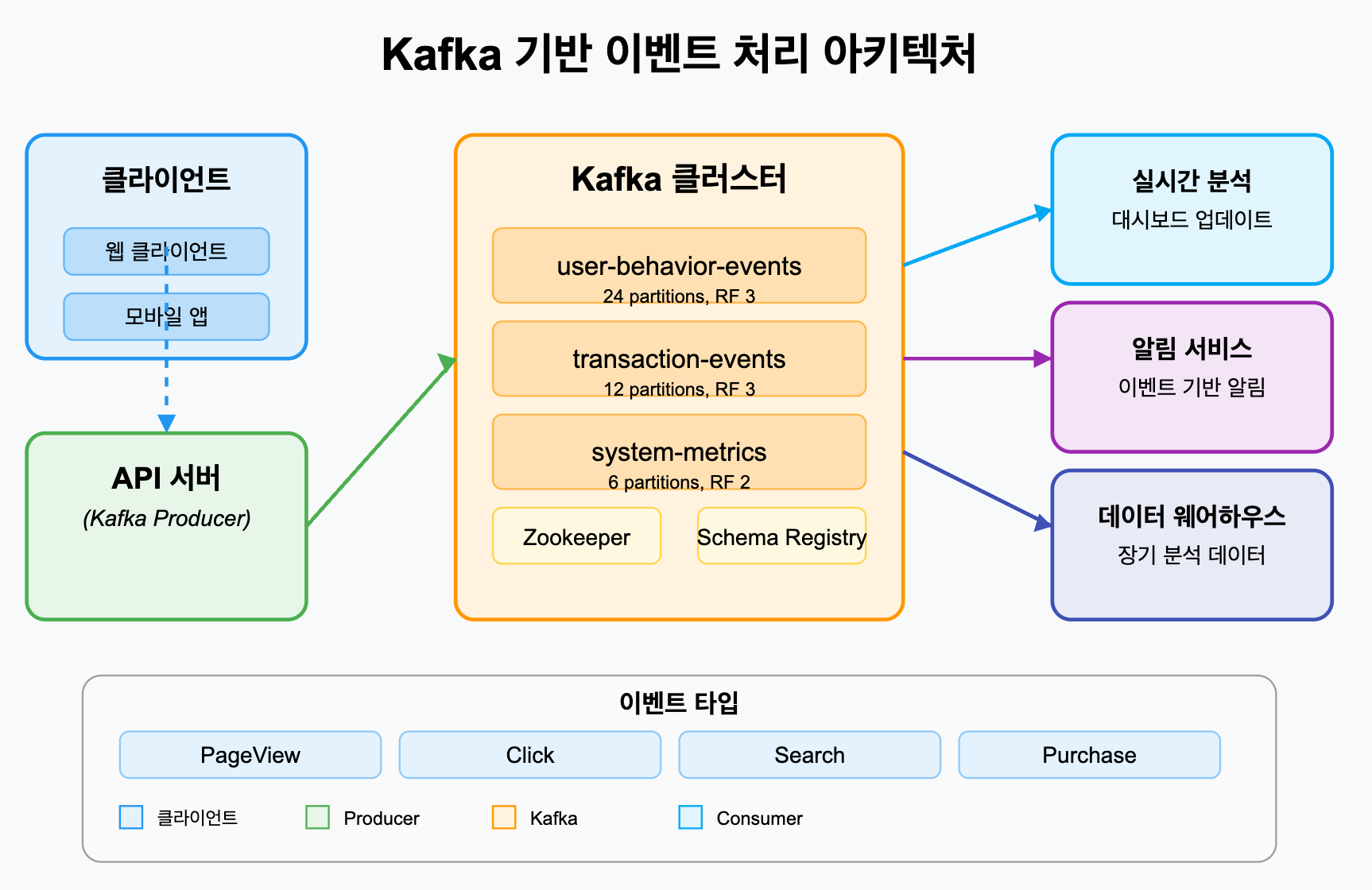
해당 아키텍처에 대해 간단히 정리했습니다. (그리는데 힘들었습니다..)
- 웹/앱 클라이언트는 이벤트를 API 서버에 전송합니다.
- API 서버는 Producer로 동작하여 이벤트를 적절한 토픽에 발행합니다.
- 여러 Consumer 서비스가 필요에 따라 토픽을 구독합니다.
- 실시간 분석 서비스: 대시보드 업데이트
- 알림 서비스: 특정 조건 충족 시 알림 발송
- 데이터 웨어하우스 적재 서비스: 장기 분석을 위한 데이터 저장
4. 구현 계획
1단계: 로컬 개발 환경 설정
# Docker Compose로 Kafka 환경 구성
version: '3'
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
environment:
ZOOKEEPER_CLIENT_PORT: 2181
kafka:
image: confluentinc/cp-kafka:latest
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
schema-registry:
image: confluentinc/cp-schema-registry:latest
depends_on:
- kafka
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_CONNECTION_URL: zookeeper:21812단계: Producer 서비스 구현 (Spring Boot)
3단계: Consumer 서비스 구현
4단계: 통합 테스트 및 성능 튜닝
5단계: 모니터링 설정 (Prometheus + Grafana)
예상되는 문제점과 해결 전략
Kafka를 도입하면서 예상되는 몇 가지 문제점과 해결 전략을 미리 생각해보았습니다.
1. 메시지 순서 보장 문제
문제점: 파티션이 여러 개일 경우, 전체 메시지의 글로벌 순서는 보장되지 않습니다.
해결 전략
- 순서가 중요한 데이터는 같은 파티션 키를 사용하여 같은 파티션에 할당되도록 합니다.
- 예를 들어, 주문 처리 시스템의 경우 주문 ID를 파티션 키로 사용하여 같은 주문에 대한 모든 이벤트가 순서대로 처리되도록 합니다.
// 순서 보장이 필요한 경우의 Producer 코드
kafkaTemplate.send("order-events", orderId, orderEvent);2. 메시지 중복 처리 문제
문제점: Producer가 메시지를 보냈지만 응답을 받지 못하면 재시도할 수 있어 중복 메시지가 발생할 수 있습니다.
해결 전략
- Consumer 쪽에서 멱등성(Idempotence)을 보장하도록 설계합니다.
- 각 메시지에 고유 ID를 부여하고 처리 여부를 추적합니다.
// 중복 처리 방지를 위한 Consumer 코드
@KafkaListener(topics = "order-events")
public void listen(ConsumerRecord<String, OrderEvent> record) {
String messageId = record.key() + "-" + record.offset();
if (processedMessageRepository.exists(messageId)) {
log.info("Duplicate message detected: {}", messageId);
return;
}
// 메시지 처리
processMessage(record.value());
// 처리 완료 기록
processedMessageRepository.save(new ProcessedMessage(messageId));
}3. Consumer 장애 대응
문제점: Consumer가 장애로 다운되면 메시지 처리가 중단될 수 있습니다.
해결 전략
- Consumer Group을 활용하여 다른 Consumer가 자동으로 파티션을 인계받도록 합니다.
- Dead Letter Queue를 구현하여 처리 실패한 메시지를 별도로 저장합니다.
// 에러 핸들링이 포함된 Consumer 설정
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setErrorHandler(new SeekToCurrentErrorHandler(
new DeadLetterPublishingRecoverer(kafkaTemplate(),
(record, ex) -> new TopicPartition("dead-letter-topic", record.partition())),
new FixedBackOff(1000L, 3)));
return factory;
}4. 스키마 변경 관리
문제점: 메시지 스키마가 변경되면 Consumer가 메시지를 처리하지 못할 수 있습니다.
해결 전략
- Schema Registry를 도입하여 스키마 호환성을 관리합니다.
- 하위 호환성을 유지하는 스키마 진화 규칙을 적용합니다.
결론 및 느낀점
Kafka를 심층적으로 공부하면서 분산 시스템의 설계 철학에 대해 많은 것을 배웠습니다. 특히 로그 중심 아키텍처와 파티션 기반 병렬 처리 모델은 대용량 데이터를 처리하는 시스템을 구축하는 데 큰 인사이트를 주었습니다. 얼른 써봐야겠습니다...
공부하면서 가장 기억에 남는 개념은 다음과 같습니다. 아래는 사실 정리된 글을 간단히 더 정리해 적었습니다~
-
디자인 심플리시티: Kafka는 복잡한 기능보다 핵심 기능(로그 기반 스토리지, 파티션 기반 병렬 처리)에 집중하여 확장성과 안정성을 높였습니다.
-
Trade-off 선택: 모든 시스템 설계에는 Trade-off가 있는데, Kafka는 일부 기능(예: 복잡한 라우팅)을 포기하는 대신 처리량과 내구성을 극대화하는 방향으로 설계되었습니다.
-
확장성 고려: 처음부터 대규모 확장을 고려한 설계로, LinkedIn에서 시작된 프로젝트가 이제는 글로벌 기업들의 핵심 인프라로 자리 잡았습니다.
앞으로 실제 프로젝트에 Kafka를 적용하면서 더 많은 경험과 인사이트를 얻을 수 있기를 기대하면 얼른 플젝을 진행하러 가야겠습니다!! 오늘도 두서없는 글 열심히 적어봤습니다! 감사합니다 ㅎㅎ
참고 자료
