[추천 시스템] 별점 예측(Rating Prediction) 모델 이해하기
추천시스템

이제 과제들이 밀려오고 있어서 velog review가 좀 늦었슴니다.. (보시는 분이 있을진 몰겠지만 ㅎㅅㅎ)
추천시스템에서 별점을 예측하는 방법은 크게 두 가지로 나뉩니다.
1. 유사도 기반 (Memory-based CF): 원본 데이터를 매번 참조하여 유사도를 계산
2. 모델 기반 (Model-based CF): 데이터의 패턴을 수학적 파라미터로 학습
그럼 하나씩 살펴볼까용~~
1. 유사도 기반 Rating Prediction (Memory-based CF)
= Similarity-based Rating prediction- 가장 직관적인 방법에 해당합니다!
item 들 간의 유사도혹은user들 간의 유사도를 활용해 user가 item에 내릴 별점()을 가중평균으로 예측합니다.- 유사도 지표로 피어슨 상관계수(Pearson Correlation)를 사용하고, 그 결과값을 가중평균의 가중치로 사용합니다.
- 분자 ()
단순히 별점을 더하는 게 아니라, '나와 얼마나 닮았나()'를 곱해서 더합니다. 유사도가 높을 수록, 별점이 차지하는 비중(가중치)이 커집니다. - 분모 ()
왜 유사도의 합으로 나누냐면, 결과값의 단위(Scale)를 '별점'으로 되돌리기 위해서!
유사도를 곱해서 커진 값을 다시 유사도들의 총합으로 나누어줌으로써, 최종 예측값이 원래의 별점 범위(e.g. 1~5점) 안에 들어오게 만드는 '정규화' 과정입니다.
- : Item/혹은 User 사이 간의 유사도 (중 높은 N개)
- : 사용자 가 기존에 아이템 에 내린 점수
- : 사용자 가 평가한 아이템 집합
💡 Tip
수식에서는 분모의 유사도()에 절댓값을 씌우라고 되어 있지만, 실제 구현(Programming) 시에는 0 미만의 값은 모두 0으로 치부하는 것이 정확도가 더 높다고 합니다.유사도가 음수일 때 '0'으로 처리하는 이유?
- 성향 반대(Negative Correlation)의 불확실성
피어슨 상관계수에서 음수는 '정반대 취향'을 의미합니다. 하지만 추천 시스템처럼 데이터가 희소(Sparse)한 환경에서는 단순히 몇 개의 아이템에 대한 평가가 달랐을 뿐인데도 매우 큰 음수 유사도가 도출될 수 있습니다. 이를 '확신'으로 받아들여 예측에 반영하면 오히려 정확도가 떨어집니다.- Top-K Selection의 신뢰도 확보
유사도 순으로 상위 개를 정렬(Sorting)할 때, 신뢰도가 낮은 음수값들이 상위에 노출되는 것을 막아야 합니다. 0으로 처리함으로써 오직 '나와 조금이라도 닮은' 데이터들만 예측 계산에 참여하게 하여 노이즈를 제거하는 것입니다.⇒ 결론: 음수 유사도는 정보로서의 가치보다 노이즈로서의 성격이 강하므로, 실무에서는 이를 0으로 밀어버리는(Thresholding) 것이 일반적입니다.
1.1 Item-Item Collaborative Filtering
아이템 간의 유사도를 계산하여 user 가 item 에 내릴 별점()을 가중평균으로 예측합니다.
- : 아이템 와 아이템 사이의 유사도
- : 사용자 가 기존에 아이템 에 내린 점수
- : 사용자 가 평가한 아이템 집합
(유사도)를 구하는 공식: 피어슨 상관계수
- : 해당 아이템이 받은 모든 별점의 평균
- 분자 : 아이템 모두 평가한 공통 유저들의 편차 곱 합계
- 분모_왼쪽 루트 : 아이템 를 평가한 모든 유저의 편차 제곱합
- 분모_오른쪽 루트: 아이템 를 평가한 모든 유저의 편차 제곱합
🔵 예제 (Item-Item CF) - 아이템 와 아이템들 간의 유사도 ()
출처: 국민대학교 박하명 교수님
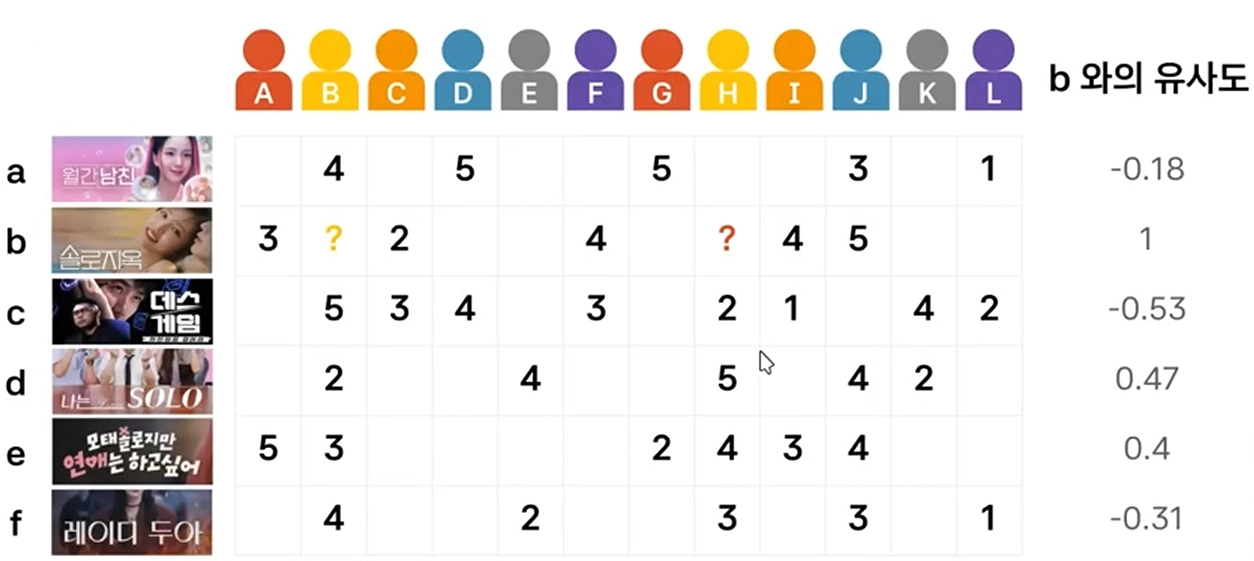
1. 사전 계산
- : 해당 아이템이 받은 모든 별점의 평균
- : 3.6
- : 3.6
- : 3.0
- : 3.4
- : 3.5
- : 2.6
- 각 아이템의 분모 항에 들어갈 편차 제곱합의 루트()
- 아이템 a ()
: - 아이템 b () :
- 아이템 c ()
: - 아이템 d ()
: - 아이템 e ()
: - 아이템 f ()
:
- 아이템 a ()
2. 아이템 와 각각의 유사도 도출 과정
①
- 분자 계산 :
- 공통 유저 : 유저
- 유저 :
- 공통 유저 : 유저
- 분모 계산:
- 아이템 를 본 5명의 편차 제곱합 :
- 아이템 를 본 5명의 편차 제곱합 :
- 최종 결과 ()
②
- 자기 자신과의 비교이므로 모든 데이터가 완벽히 일치합니다.
따라서 상관계수는 항상 이 됩니다.
③
- 분자 계산 :
- 공통 유저 : 유저
- 유저 :
- 유저 :
- 유저 :
- 공통 유저 : 유저
- 분모 계산:
- 아이템 를 본 5명의 편차 제곱합 :
- 아이템 를 본 8명의 편차 제곱합 :
- 최종 결과 ()
④
- 분자 계산 :
- 공통 유저 : 유저
- 유저 :
- 공통 유저 : 유저
- 분모 계산:
- 아이템 를 본 5명의 편차 제곱합 :
- 아이템 를 본 5명의 편차 제곱합 :
- 최종 결과 ()
⑤
- 분자 계산 :
- 공통 유저 : 유저
- 유저 :
- 유저 :
- 유저 :
- 공통 유저 : 유저
- 분모 계산:
- 아이템 를 본 5명의 편차 제곱합 :
- 아이템 를 본 6명의 편차 제곱합 :
- 최종 결과 ()
⑥
- 분자 계산 :
- 공통 유저 : 유저
- 유저 :
- 공통 유저 : 유저
- 분모 계산:
- 아이템 를 본 5명의 편차 제곱합 :
- 아이템 를 본 5명의 편차 제곱합 :
- 최종 결과 ()
🟪 Python 구현 코드
import pandas as pd
import numpy as np
# 1. 데이터 정의: 행은 아이템(a~f), 열은 유저(A~L)
ratings = {
'a': {'B': 4, 'D': 5, 'G': 5, 'J': 3, 'L': 1},
'b': {'A': 3, 'C': 2, 'F': 4, 'I': 4, 'J': 5},
'c': {'B': 5, 'C': 3, 'D': 4, 'F': 3, 'H': 2, 'I': 1, 'K': 4, 'L': 2},
'd': {'B': 2, 'E': 4, 'H': 5, 'J': 4, 'K': 2},
'e': {'A': 5, 'B': 3, 'G': 2, 'H': 4, 'I': 3, 'J': 4},
'f': {'B': 4, 'E': 2, 'H': 3, 'J': 3, 'L': 1}
}
df = pd.DataFrame(ratings).T # 행/열 전환하여 아이템을 행으로 설정
# 2. 사전 계산 (Pre-calculation)
### 아이템별 평균 평점 계산
row_means = df.mean(axis=1)
### 모든 아이템의 에너지(편차 제곱합 루트) 미리 구하기
item_norms = {}
for idx in df.index:
# 각 점수에서 평균을 뺀 편차(deviation) 구하기
dev = df.loc[idx] - row_means[idx]
# 편차 제곱합의 루트 계산 (결측치는 제외)
item_norms[idx] = np.sqrt((dev.dropna()**2).sum())
# 3. 기준 아이템(b)와의 유사도 계산
### 기준값 고정 (루프 밖에서 선언하여 효율성 증대)
target = 'b'
results = {}
r_target = df.loc[target]
mean_target = row_means[target]
norm_target = item_norms[target]
### 유사도 계산
for other in df.index:
r_other = df.loc[other]
mean_other = row_means[other]
norm_other = item_norms[other]
# 분자: 공통 유저(Common Users)의 편차 곱 합산
common_idx = r_target.notnull() & r_other.notnull()
dev_target = r_target[common_idx] - mean_target
dev_other = r_other[common_idx] - mean_other
numerator = (dev_target * dev_other).sum()
# 분모: 미리 계산된 두 아이템의 에너지를 곱함
denominator = norm_target * norm_other
# 최종 유사도 계산
similarity = numerator / denominator if denominator != 0 else 0
results[other] = round(similarity, 4)
print("아이템 b 기준 유사도 결과:")
print(results)-
Q1. 아이템 B에 대한 유저 H의 별점 예측 ()
-
선정 아이템 : (유사도 0.1373), (유사도 0.1077)
-
유저 H의 해당 아이템 평점 : ,
-
계산 과정 :
결과: 유저 H는 아이템 b에 약 4.12점을 줄 것으로 예측됩니다.
-
-
Q2. 아이템 B에 대한 유저 B의 별점 예측 ()
- 선정 아이템 : (유사도 0.1373), (유사도 0.1077)
- 유저 B의 해당 아이템 평점 : ,
- 계산 과정 :
결과: 유저 B는 아이템 b에 약 2.88점을 줄 것으로 예측됩니다.
1.2 User-Item Collaborative Filtering
유저 간의 유사도를 계산하여 user 가 item 에 내릴 별점을 가중평균으로 예측합니다.
- : 유저 와 유저 사이의 유사도
- : 유저 가 기존에 아이템 에 내린 점수
- : 유저 와 유사한 유저들의 집합 (아이템 를 평가한 유저들 중 상위 명)
1.3 특징 및 한계
- Item-Item vs User-User:
- 유저는 주관적이고 변동성이 크지만, 아이템은 속성이 안정적이어서 Item-Item 방식이 더 정확합니다.
- Lazy Learning:
- 유사도 기반 Rating Prediction은 Lazy Learning에 해당합니다.
- 미리 학습하지 않고, 추천 요청이 들어온 그 순간에 모든 유사도를 계산한다는 의미입니다.
- 따라서, 데이터가 커질수록 실시간 연산량이 급증하여 비효율적입니다.
2. 모델 기반 Rating Prediction
- 수학적 모델(함수)을 학습하여 효율성과 정확도를 높이는 방식입니다.
- Lazy Learning 방법의 비효율을 해결하기 위한 접근 방법입니다.
1️⃣ 가장 단순한 모델 (Mean Model)
가장 단순한 모델?의 예측 함수는 다음과 같이 정의됩니다.
1.1 가장 단순한 모델의 구조
- input, output 상관없이 특정값을 반환하는 함수입니다,
- 이 목적함수를 최소화 하는 를 찾으면, 결국 평균(mean)을 의미하게 될 것d입니다.
- 왜 평균인가?
오차(MSE)를 최소화하는 지점을 미분으로 찾으면, 그 값은 항상 데이터의 평균에 수렴하기 때문입니다.
(mse를 가장 줄이는 것은 평균)

2️⃣ Bias Model
단순히 유사도만 보는 것이 아니라, 유저와 아이템의 고유한 성향(편향)을 수학적으로 모델링합니다.
- 유저와 아이템의 고유한 성향 반영이 필요한 경우 예시
- User Bias: 평소에 모든 영화에 1점만 주는 '박한 사람' vs 5점만 주는 '후한 사람'
- Item Bias: <왕과 사는 남자>처럼 누구나 좋아해서 점수가 높은 영화 vs 호불호가 갈리는 영화
2.1 Bias 모델 구조
Bias 모델의 예측 함수는 다음과 같이 정의됩니다.
목적함수 구성 요소
1. (Global Bias): 전체 시스템의 평균 별점
2. (User Bias): 사용자의 성향 (평점을 후하게 주는지, 박하게 주는지)
3. (Item Bias): 아이템의 성향 (대체로 높은 점수를 받는지, 낮은지)
2.2 Bias 모델의 목적함수 (규제항의 필요성)
모델은 실제값()과 예측값 사이의 오차를 줄이려 노력합니다. 하지만 데이터가 부족할 때 모델이 특정 편향을 무리하게 키우는 과적합이 발생하므로, 이를 방지할 규제항(Regularization)이 필수적입니다.
이 식은 크게 두 부분으로 나누어 볼 수 있습니다.
A. 오차 제곱합 (Sum of Squared Errors) :
⇒ 의미: "내가 예측한 점수와 실제 유저가 준 점수가 얼마나 다른가?"를 잽니다.
이 값이 작을수록 실제 데이터와 잘 맞는 모델이 됩니다.
B. 규제 항 (Regularization Term) :
⇒ 의미: "모델이 너무 복잡해지거나 특정 유저/아이템에 과하게 맞춰지지(Overfitting) 마라!"라고 브레이크를 거는 장치입니다.
- (람다): 규제의 강도를 조절합니다. 람다가 클수록 모델은 안전하고 보수적으로 변합니다.
💡 왜 규제가 필요한가?
모델은 가장 안전한 전체 평균(α)에서 출발합니다. 하지만 오직 현재의 오차를 0으로 만드는 데만 집착하는 모델은 다음과 같은 극단적인 선택을 합니다.
- 실제가 평균보다 클 때 (): 오차를 없애려고 β를 양수(+) 방향으로 깊숙이 보냅니다. (예: )
- 실제가 평균보다 작을 때 (): 오차를 없애려고 β를 음수(-) 방향으로 깊숙이 보냅니다. (예: )
문제는 데이터가 부족할 때입니다. 단 한 번의 평가만 보고 모델이 β를 0에서 너무 멀리 보내버리면, 그 유저나 아이템에 대해 "남들보다 무조건 2점 높다(혹은 낮다)"는 강한 편견을 갖게 됩니다. 이것이 바로 과적합입니다.
💡 규제항의 원리와 설계 의도
모델이 β를 0에서 너무 멀리 보내지 못하도록 목적함수에 을 더합니다. 여기서 제곱을 쓰는 이유는 방향에 상관없이 '0으로부터의 거리'에 벌금을 매기기 위해서입니다.
- 방향 무관 벌금: β가 양수(+)로 멀어지든, 음수(-)로 멀어지든 제곱을 하면 모두 큰 양수(+) 벌금이 됩니다. 즉, "어느 방향이든 0(평균)에서 멀어지면 무조건 벌금이다!"라는 원칙입니다.
- 중심으로 당기는 힘: β가 0에서 멀어질수록 벌금()이 제곱으로 폭등합니다.
🤖 모델 내부의 밀당 과정
e.g) 전체 평균이 3점인데 어떤 유저가 1점을 줬다면
- 모델의 유혹: "오차를 0으로 만들게 를 로 보내버릴래!"
- 규제항의 경고: "어허, 0에서 그렇게 멀어지면 제곱 벌금이 로 너무 커지는데?
- 모델의 타협: "음... 벌금이 너무 세네. 그냥 를 정도로만 실제값 정도로 움직이고, 남은 오차는 그냥 감수하자. 그게 전체 점수 관리에는 유리해."
✅ 요약
결국 규제항()은 모델에 탄성력(고무줄)을 달아주는 것과 같습니다.
- 오차 제거: 실제 데이터 쪽으로 를 당기는 힘 (예측을 정확하게!)
- 규제(벌금): 다시 평균(0) 쪽으로 를 끌어오는 힘 (너무 튀지 않게!)
이 두 힘이 균형을 이루는 지점에서 가장 안정적인 가 결정됩니다. 덕분에 데이터가 적은 상황에서도 모델이 미쳐 날뛰지(?) 않고 평균에 기반한 안정적인 예측을 할 수 있게 됩니다.
2.3 Bias 모델 최적화
(1) 경사하강법
함수의 기울기를 구하여 오차가 작아지는 방향(경사 아래)으로 파라미터를 조금씩 업데이트하며 최소값을 만드는 파라미터를 찾아가는 방식입니다.
(2) Alternating Least Squares(ALS)
변수가 여러 개()일 때, 한꺼번에 최적값을 찾기 어렵기 때문에 나머지 변수를 고정하고 하나씩 순차적으로 업데이트하는 방식입니다.
이를 반복하면 전체 오차가 최소화되는 지점에 수렴하게 됩니다.
2.4 특징 및 한계
Bias 모델은 개별 성향은 잘 파악하지만, "사용자가 특정 장르를 선호한다"와 같은 유저-아이템 간의 상호작용(Interaction)은 파악하지 못합니다.
이를 해결하기 위해 이후 Latent Factor Model(잠재 요인 모델)로 발전하게 됩니다.
3️⃣ Latent Factor Model
잠재 요인 모델
Bias 모델이 유저/아이템의 '평균적인 성향'만 봤다면,
잠재 요인 모델은 유저와 아이템 사이에 숨겨진 특징을 반영하는 모델입니다.
- Bias 모델의 한계: "아현님은 평소 5점을 잘 주고, 영화 <라라랜드>는 원래 인기가 많아"까지만 압니다. 유저와 아이템이 만났을 때 발생하는 '특수한 선호 관계'는 설명하지 못합니다.
- Latent Factor 모델의 목표: "아현님은 '로코 장르'를 좋아하고, <라라랜드>는 '로코 요소'가 강한 영화야. 그래서 둘이 잘 맞아!"라는 숨겨진 특징을 찾아내는 것입니다.
이러한 유저와 아이템의 속성을 벡터(Vector)로 표현하여 그들 사이의 특수한 선호 관계를 모델에 반영하는 것이 핵심입니다. 데이터(별점) 속에 숨겨져 있는, 무엇인지는 정확히 모르지만 분명히 존재하는 패턴을 찾아냅니다.
3.1 모델의 핵심 원리: 행렬 분해
수학적으로 이 벡터를 찾는 가장 정석적인 방법은 SVD입니다.
- SVD (Singular Value Decomposition):
행렬 를 라는 세 개의 행렬로 분해하여, 데이터의 핵심 특징만 남기고 나머지는 압축할 수 있다는 것을 수학적으로 증명한 정리입니다. 즉, 행렬을 쪼개서 적은 양의 정보로도 원본을 복원할 수 있습니다.
"거대한 평점 표(행렬)를 유저 벡터와 아이템 벡터의 곱으로 쪼개서 볼 수 있다"는 아이디어의 근거를 SVD에서 가져온 것입니다
즉, '유저 수 아이템 수'만큼의 엄청난 차원을 가진 원래 표를 우리가 정한 개의 잠재 요인(Latent Factors)으로 압축하는 것이 목적입니다.
예제
출처: 국민대학교 박하명 교수님
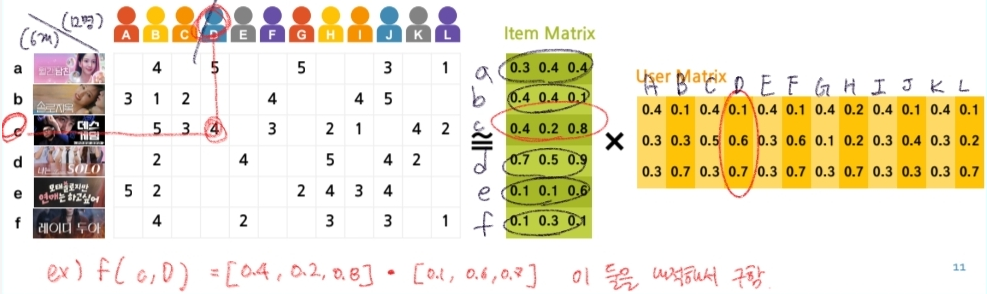
- 별점 행렬 = 아이템 행렬 * 유저 행렬
- 별점 행렬()이 두 개의 작은 행렬의 곱(Item Matrix User Matrix)으로 표현되어 있습니다.
- 아이템 행렬 (Item Matrix):
- 각 아이템(a~f)을 3개의 잠재 요인으로 요약한 벡터입니다.
- e.g) 아이템 의 벡터 .
- 유저 행렬 (User Matrix):
- 각 사용자(A~L)가 그 3개의 잠재 요인을 얼마나 좋아하는지 나타낸 벡터입니다.
- e.g) 사용자 의 벡터 .
- 실제 별점 예측 과정:
- 이미지의 예시인 "사용자 가 아이템 를 보고 평점 얼마를 줄까?"
- 계산
: - 의미: 아이템 가 가진 잠재적 속성들과 사용자 가 선호하는 잠재적 취향을 내적하여 나온 이 점수가 바로 우리가 예측한 별점이 됩니다.
추천 시스템에서의 한계
하지만 추천 시스템에서는 이 SVD를 그대로 쓰기 어렵습니다.
- 빈칸(Sparse) 문제
추천 데이터는 유저가 안 본 영화가 훨씬 많아 구멍이 숭숭 뚫려 있습니다. SVD는 빈칸이 있으면 계산이 안 됩니다. - 연산 효율
데이터가 거대해질수록 정통 SVD는 너무 느립니다.
원래 유저-아이템 행렬()은 빈칸이 많은 거대한 행렬입니다. 이를 유저 행렬()과 아이템 행렬()이라는 두 개의 작은 행렬로 쪼개는 것이 기본 원리입니다.
따라서 우리는 SVD의 수식을 그대로 푸는 대신, "빈칸은 무시하고, 이미 있는 값이라도 가장 잘 설명하는 벡터()들을 찾아내자"는 방식으로 아이디어를 발전시켜 사용합니다.
3.2 최종 예측 모델: "기본점수 + 알파"
그럼 구체적으로 latent factor 모델에 어떻게 반영할까요?
SVD는 단 한 번의 복잡한 수식 연산으로 행렬을 쪼개지만 , MF는 최적화(Optimization) 과정을 거칩니다.
- 초기화 : 유저 벡터()와 아이템 벡터()에 아무 숫자(랜덤값)나 채워 넣습니다. (당연히 처음엔 엉터리 점수를 예측하겠죠?)
- 예측 및 비교: 우리가 알고 있는 실제 점수()와 두 벡터를 내적 해서 나온 점수()를 비교합니다.
- 오차 수정: "어라? 실제는 5점인데 내 모델은 2점이라고 하네?" 그러면 오차(3점)를 줄이는 방향으로 벡터 속의 숫자들을 아주 조금씩 수정합니다.
이 과정을 반복하면, 모든 유저와 아이템은 각각 고유한 숫자 묶음(벡터)을 갖게 됩니다.
이렇게 채워진 벡터와 아이템 벡터를 내적 해보면, 기존에 유저가 보지 않은 아이템에 대한 평점을 그럴싸하게 예측한 점수가 튀어나옵니다.
이것이 바로 잠재 요인 모델이 데이터 속에 숨겨진 유저의 취향 패턴을 '학습'했기 때문에 가능한 결과입니다!
위 과정을 수식으로 나타내보면 아래와 같습니다.
앞선 Bias 모델에 유저와 아이템의 상호작용 항을 더한 형태입니다.
즉, 유저와 아이템의 고유 성향(Bias)과 숨겨진 취향(Latent Factor)을 모두 결합한 최종 예측 모델입니다.
- Baseline ():
유저가 원래 후한지, 아이템이 원래 인기 있는지 같은 평균적인 성향(Baseline)을 잡아줍니다.- : Global baseline (전체 평균)
- : 사용자 의 bias (사용자 성향)
- : 아이템 의 bias (아이템 성향)
- Interaction ():
유저 벡터()와 아이템 벡터()의 내적값입니다.
Baseline만으로는 설명할 수 없는 '유독 이 유저가 이 아이템을 좋아하는 이유'를 잡아내는 역할을 합니다.
e.g) "이 유저는 액션을 좋아하는데(), 이 영화는 액션 요소가 얼마나 들어있는가()"를 계산합니다.- : 사용자 의 latent vector (사용자 잠재 요인)
- : 아이템 의 latent vector (아이템 잠재 요인)
3.3 목적함수와 규제항 (Regularization)
최적화의 구조는 Bias 모델과 똑같습니다.
오차(MSE)를 최소화하되, 파라미터들이 너무 튀지 않게 규제를 거는 원리입니다.
잠재 요인 모델에서도 목적함수에 규제항()이 추가됩니다. 이는 모델이 오차를 줄이려고 벡터 안의 숫자들을 무리하게 조정하는 것을 방지하기 위함입니다.
A. 오차 제곱합 (Sum of Squared Errors) :
"내가 예측한 점수가 실제 별점()과 얼마나 차이 나는가?"를 계산합니다.
B. 규제 항 (Regularization Term) :
"모델이 너무 복잡해지거나 특정 취향에 편향되지 마라!"라고 브레이크를 거는 장치입니다.
💡 과 , 왜 형태가 다른가요?
두 기호는 모양만 다를 뿐, 본질적으로 "값이 평균에서 멀어지면 벌금을 매기겠다"는 원리가 똑같습니다. 단지 는 벡터(숫자 묶음)이라서 L2 Norm(제곱의 합)의 형태를 띠는 것입니다.
| 구분 | 대상 | 규제 형태 | 의미 |
|---|---|---|---|
| Bias () | 스칼라 (숫자 1개) | 숫자 하나의 크기를 제한 | |
| Latent Vector () | 벡터 (숫자 개 묶음) | $ | 벡터 안 모든 숫자의 제곱 합 |
💡 왜 Latent Vector()에도 규제가 필요한가?
예시 )
- 잠재 요인을 3개()로 잡았다면, 각 벡터의 숫자는 [액션, 로맨스, 영상미] 같은 숨겨진 특징들의 강도를 의미합니다.
- 두 모델이 똑같이 0.3이라는 점수를 예측했다고 가정해 봅시다.
- 모델 A (안정적)
- 유저 벡터() :
- 아이템 벡터() :
- 모델 B (불안정)
- 유저 벡터() : (유저 벡터 값이 상대적으로 큼)
"나는 액션을 매우 좋아하고(1.0), 로맨스는 관심 없고(0), 영상미는 조금 따져(0.5)"
Error를 줄이는 데만 집착해서, 특정 벡터 값을 비정상적으로 크게 키워버린 경에 해당됨. - 아이템 벡터() :
- 유저 벡터() : (유저 벡터 값이 상대적으로 큼)
- 만약 아이템의 정보가 아주 살짝 바뀌어서 가 가 된다면?
- 모델 A : (기존 0.3에서 0.05 변화)
- 모델 B : (기존 0.3에서 0.10 변화)
✅ 결론
- 특정 파라미터()의 절대값이 크면, 데이터가 아주 조금만 흔들려도 예측값이 요동치는 Fluctuation이 발생합니다.
- 규제항()은 이 벡터들의 크기(L2 Norm)를 작게 유지시켜, 모델이 노이즈에 일희일비하지 않고 안정적으로 학습되도록 돕는 '고무줄' 역할을 합니다.
3.4 최적화 기법: ALS (Alternating Least Squares)
학습 과정에서 이 파라미터들을 찾는 것은 Bias 모델보다 훨씬 까다롭습니다.
Bias 모델은 Convex(볼록)하지만, Latent 모델은 Non-Convex(비볼록)하기 때문입니다.
-
Convex(볼록)와 Non-Convex(비볼록) 란?
- Convex (볼록): 함수 모양이 매끄러운 '그릇' 모양인 경우.
⇒ 어디서 시작해서 내려가든 무조건 최솟값(Global Optimum, 전역 최적해)에 도착합니다. - Non-Convex (비볼록): 함수 모양이 울퉁불퉁한 모양인 경우.
⇒ 최솟값이라 생각하고 내려갔는데 알고 보니 작은 웅덩이(Local Optimum, 지역 최적해)에 빠져버릴 수 있습니다.
- Convex (볼록): 함수 모양이 매끄러운 '그릇' 모양인 경우.
-
왜 Non-Convex인가?
: 유저와 아이템의 "곱하기()" 때문입니다!- 더하기 (): 와 가 서로 간섭하지 않아 그래프가 매끄러운 그릇 모양을 유지합니다.
- 곱하기 (): 를 키웠을 때 결과가 커질지 작아질지가 상대방인 의 값에 따라 바뀝니다.
- 이렇게 변수끼리 엉키는 '상호작용' 때문에 그래프가 울퉁불퉁한 산맥 모양이 되어 최적해를 찾기 어려워집니다.
-
그럼 어떻게 최적해를 찾는가?
: 사용자 또는 아이템 행렬 중 하나를 상수로 고정하면 다시 Convex 형태로 만들 수 있습니다!
이를 활용하여 "번갈아 가며 를 고정합니다."- 유저 벡터()를 고정하고, 아이템 벡터()를 최적화합니다.
- 아이템 벡터()를 고정하고, 유저 벡터()를 최적화합니다.
- 장점:
- 하나를 고정하는 순간 선형 회귀 문제로 바뀌어 풀기가 매우 쉬워집니다.
- 유저별, 아이템별 계산이 독립적이라 병렬 처리(Parallelization)가 가능해 대규모 데이터에 유리합니다.
요약: 추천 시스템의 진화
- 아이템 기반 / 유저 기반 CF: "이거 산 사람들이 이것도 샀어" (단순 통계)
- Bias Model: "이 유저는 원래 좀 짜게 줘" (개인 성향 반영)
- Latent Factor Model: "이 유저는 이런 '잠재적인 특징'을 가진 아이템을 좋아해" (숨겨진 취향 저격)
