[AI스쿨 7기, 13주차] KoNLPy, 형태소 분석기, 품사 태깅, Hannanum, Kkma, Komoran, Mecab, Twitter, 네이버 영화리뷰 데이터, pecab, okt, stemming, tqdm, 시퀀스, Tokenizer, oov, word_index, padding,
멋쟁이사자처럼
221214 멋쟁이 사자처럼 AI스쿨 7기, 박조은 강사님 강의
✅ 1104번 실습파일
실습 목적 : KoNLPy 로 한국어 형태소분석기를 사용해 보는 것
konlpy 문서 : https://konlpy.org/ko/latest/
- 대표적인 자연어처리 도구인 NLTK, Spacy 는 한국어를 지원하지 않는다. 영어를 사용한다면 해당 도구를 사용해도 된다. 하지만 한국어 형태소 분석 등의 기능을 제공하지 않기 때문에 KoNLPy로 실습한다.
- KoNLPy 는 설치가 까다롭다. Java, C, C++ 로 작성된 도구를 파이썬으로 사용할 수 있도록 연결해 주는 도구이기 때문에 여러 환경 의존성이 있다. 환경 의존성을 만족해야 동작하는 도구가 있다.
- 검색엔진 회사에 국문과 출신 분들이 있었다. 텍스트 전처리, 검색엔진 한국어에 대한 이해가 필요하기 때문이다.
- 튜닙(회사) : 윤리 분별 API, 텍스트 분석, 이미지 분석, 영상분석, 방언 번역 등 여러 API 를 만들어가고 있다.
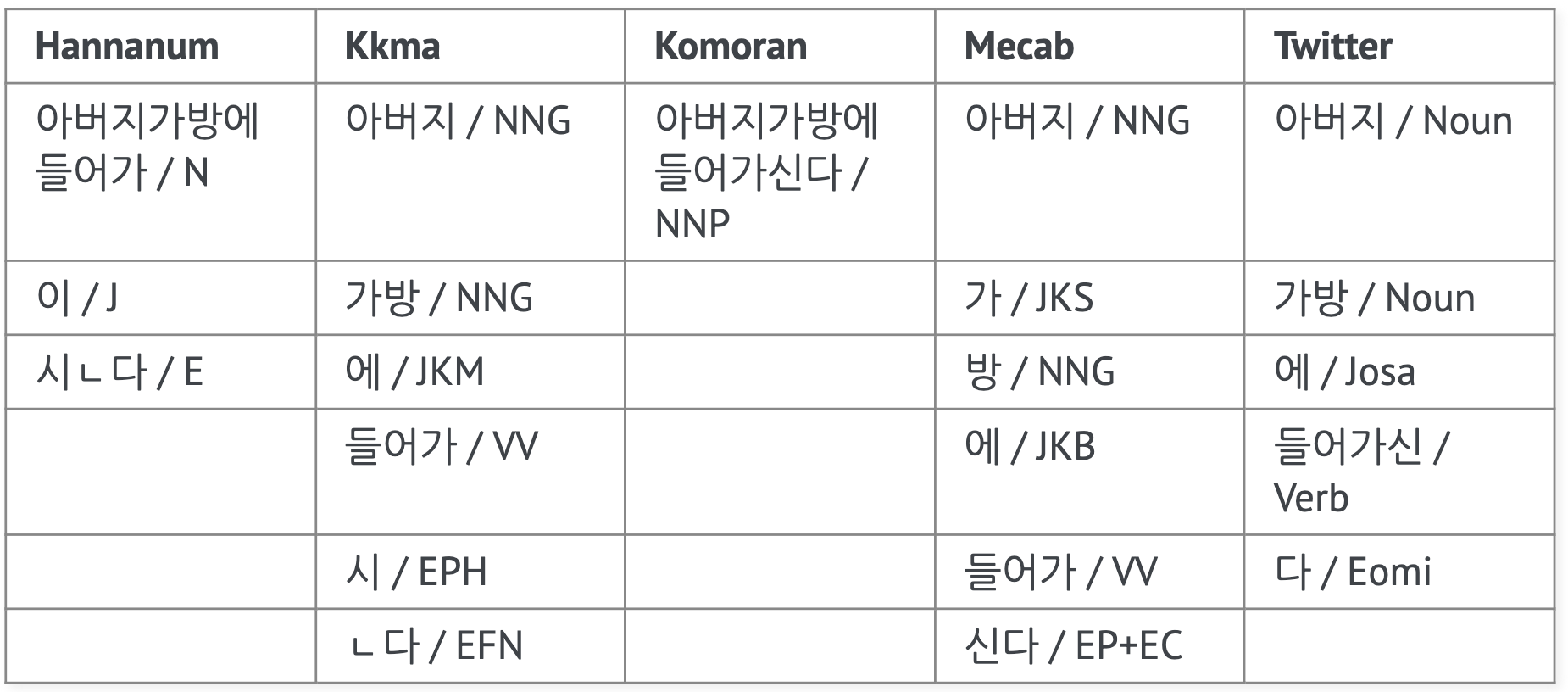
- 형태소 분석기마다 품사를 태깅하는 방법이 다 다르다. (품사 태깅 : https://docs.google.com/spreadsheets/d/1OGAjUvalBuX-oZvZ_-9tEfYD2gQe7hTGsgUpiiBSXI8/edit#gid=0)
❓ 품사 태깅표에서 명사는 어떤 공통점이 있을까?
◾ N으로 시작
◾ 동사는 V로 시작
❓ 어떤 형태소 분석기가 가장 빨라 보이나?
◾ Mecab 이 단어가 많을 때 빨라 보인다.
◾ 속도만 봤을 때는 mecab(은전한닢. 일본어 형태소 분석기를 한국어에 맞게 제작한 것) 이 가장 빨라 보이지만 목적에 따라 선택해서 사용하게 된다.
◾ 코모란은 자바에서 사용할 수 있도록 만들어진 형태소 분석기다. 파이썬 환경에서 느리다고 다른 환경에서도 느린 것은 아니다.
❓ tqdm 어디에서 사용했었을까? ❓ 사용목적은?
◾ 웹스크래핑
◾ 주식데이터분석
◾ 이미지 파일 저장할 때
◾ 오래 걸리는 작업을 할 때 진행상태를 표시
📌 네이버 영화리뷰 데이터로 학습해서 새로운 영화의 긍정부정을 예측하기 : https://elleryvernon-movie-streamlit-main-0w4ge5.streamlit.app/
github : https://github.com/ElleryVernon/movie-streamlit-for-public
kkma
!pip install konlpy --upgrade
from konlpy.tag import Kkma
kkma = Kkma()
kkma
kkma.pos(u'오늘의 발표는 2명입니다.')
pecab
!pip install pecab
from pecab import PeCab
pecab = PeCab()
pecab.pos("디코 이모티콘을 키우고 싶다면 .large() 로 입력하세요")
Okt (Open Korea text)
https://konlpy.org/ko/latest/api/konlpy.tag/#konlpy.tag._okt.Okt
from konlpy.tag import Okt
okt=Okt()
okt.pos(small_text)
-
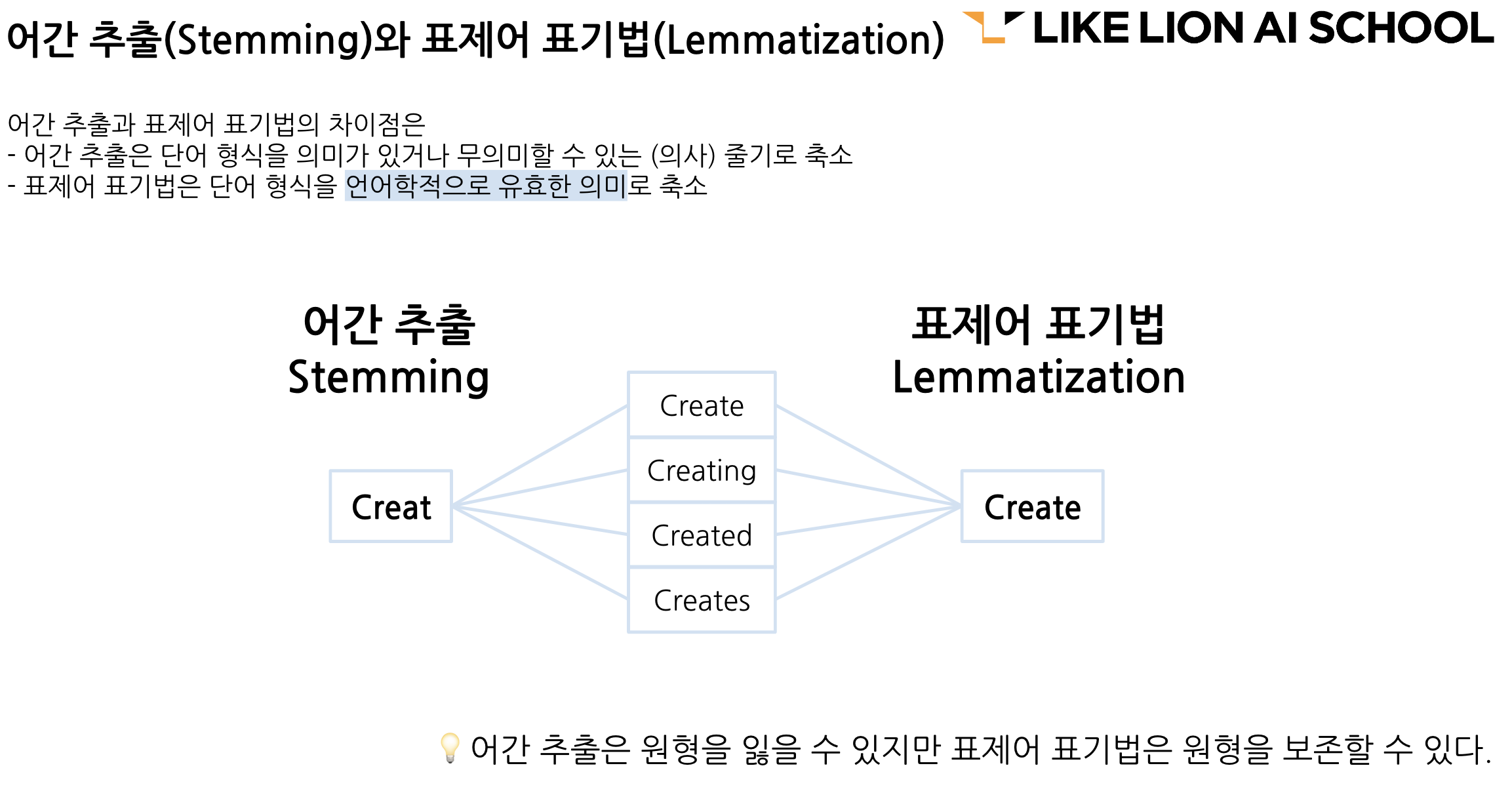
Stemming(어간추출)
- 형태소 분석기마다 어간추출, 표제어 표기법을 제공하기도 하고 제공하지 않는 것도 있다.
- 문의 했습니다. 했다. 했었다. -> 모두 하다로 바뀐다.
-
함수 만들기
형태소 분석기(Okt) 불러오기
['Josa', 'Eomi', 'Punctuation'] 조사, 어미, 구두점 제거
전체 텍스트에 적용해 주기 위해 함수를 만듭니다.
1) 텍스트를 입력받는다.
2) 품사태깅을 한다. [('문의', 'Noun'), ('하다', 'Verb'), ('?!', 'Punctuation')]
3) 태깅 결과를 받아서 순회한다.
4) 하나씩 순회 했을 때 튜플 형태로 가져오게 된다.('을', 'Josa')
5) 튜플에서 1번 인덱스에 있는 품사를 가져온다.
6) 해당 품사가 조사, 어미, 구두점이면 제외하고 append 로 인덱스 0번 값만 다시 리스트에 담아준다.
7) " ".join() 으로 공백문자로 연결해 주면 다시 문장이 된다.
8) 전처리 후 완성된 문장을 반환 -
tqdm 으로 전처리
문자열 전처리를 정규화 한다고 표현하기도 한다.
정규화를 해주게 되면 불필요하게 희소한 행렬이 생성되는 것을 방지할 수 있으며 같은 의미를 묶어줄 수 있다. 학습 속도가 너무 느려지는 것을 방지할 수 있다.
속도를 개선하고자 한다면 멀티스레드를 만들어서 처리하는 방법을 찾아도 좋다.
학습 예측 데이터
X_train_text = train['title']
X_test_text = test['title']
label_name = 'topic_idx'
y_train = train[label_name]
TF-IDF
from sklearn.feature_extraction.text import TfidfVectorizer
tfidfvect = TfidfVectorizer()
tfidfvect.fit(X_train_text)
transform => 🔥주의해서 볼 것은 열(columns, 어휘)의 수가 같은지 확인
X_train = tfidfvect.transform(X_train_text)
X_test = tfidfvect.transform(X_test_text)
X_train.shape, X_test.shape
오랜만의 복습(모델, cross validation, 학습예측)
🔧 모델
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state=42)
model
🔧 cross validation
from sklearn.model_selection import cross_val_predict
y_predict=cross_val_predict(model, X_train, y_train,
cv=3, n_jobs=-1, verbose=1)
y_predict[:5]
🔧 accuracy score
(y_train == y_predict).mean()
🔧 학습과 예측
y_test_predict = model.fit(X_train, y_train).predict(X_test)
y_test_predict[:5]
✅ RNN 강의파일(33p)
Bag of Words 와 TF-IDF 방식과 시퀀스 방식이 어떤 차이가 있는지 알아본다.
✅ 1105 실습파일
https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/text/Tokenizer
시퀀스 방식의 인코딩을 사용해 본다 => Bag of Words 와 TF-IDF 방식과 시퀀스 방식이 어떤 차이가 있는지 알아본다.

출처 : 위 링크
Tokenizer
단어수를 너무 많이 하면 나중에 학습을 할 때 오래 걸릴 수도 있고 문장 길이가 제각각이다. 단어수를 제한하면 어휘에 없는 단어가 등장했을 때 시퀀스에 누락되기 때문에 이런 값을 처리하는 방법이 있다. oov 토큰을 사용하면 없는 어휘는 없는 어휘라고 표현해준다.
vocab_size = 5
tokenizer = Tokenizer(num_words=vocab_size)
Check out sessions from the WiML Symposium covering diffusion models with KerasCV, on-device ML, and more. Watch on demand
TensorFlow
API
TensorFlow v2.11.0
Python
도움이 되었나요?
tf.keras.preprocessing.text.Tokenizer
bookmark_border
See Stable See Nightly
View source on GitHub
Text tokenization utility class.
View aliases
tf.keras.preprocessing.text.Tokenizer(
num_words=None,
filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n',
lower=True, # 소문자
split=' ', # 띄어쓰기 기준으로 나눈다.
char_level=False, # 캐릭터 단위가 아니라 워드 단위로
oov_token=None,
analyzer=None,
**kwargs
)- tokenizer의 word_index 속성으로 키-값 쌍을 포함하는 딕셔너리를 반환하게 한 후, key, value, 빈도 확인
word_to_index.keys()
word_to_index.values()
word_to_index.items()
tokenizer.word_counts - CountVectorizer 로 빈도를 세고 sum() 을 했던 것과 같은 결과
wc = tokenizer.word_counts
pd.DataFrame(wc.items()).set_index(0).T - ❓ 기존 BOW 방식과 시퀀스 방식의 차이?
◾ texts_to_sequences를 이용하여 text 문장을 숫자로 이루어진 리스트로 변경한다.
◾ BOW 는 등장한다, 안한다 였으면 시퀀스 방식은 해당 어휘사전을 만들고 해당 어휘의 등장 순서대로 숫자로 변환.
◾ 순서를 아는지 모르는지
oov
길이가 맞지 않아서 제대로 numpy array 가 만들어지지 않는다. 원했던 것은 shape(3,5) 로 만들어지길 기대했지만 그렇지 않다. 그래서 패딩을 사용한다.
tokenizer = Tokenizer(num_words=10, oov_token="[oov]")
tokenizer = Tokenizer(num_words=10, oov_token="?모름?")
tokenizer = Tokenizer(num_words=10, oov_token="[PAD]")
tokenizer = Tokenizer(num_words=10, oov_token="<패딩?")
tokenizer = Tokenizer(num_words=10, oov_token="[종결]")
tokenizer = Tokenizer(num_words=10, oov_token="[MASK]")
tokenizer = Tokenizer(num_words=10, oov_token="[마스크]")
tokenizer = Tokenizer(num_words=10, oov_token="<oov>")
tokenizer.fit_on_texts(corpus)
print(tokenizer.word_index)
print(corpus)
corpus_sequences = tokenizer.texts_to_sequences(corpus)
corpus_sequencespadding
시퀀스 방식의 인코딩. 시퀀스를 고려하는 알고리즘에서 더 나은 성능을 보여준다. 머신러닝에서 사용했을 때는 오히려 TF-IDF 가 더 나은 성능을 보여주기도 한다.
pad_sequences(sequences, maxlen=None, dtype='int32', padding='pre', truncating='pre', value=0.0)
>>> sequence = [[1], [2, 3], [4, 5, 6]]
>>> tf.keras.preprocessing.sequence.pad_sequences(sequence)
array([[0, 0, 1],
[0, 2, 3],
[4, 5, 6]], dtype=int32)
>>> tf.keras.preprocessing.sequence.pad_sequences(sequence, value=-1)
array([[-1, -1, 1],
[-1, 2, 3],
[ 4, 5, 6]], dtype=int32)
>>> tf.keras.preprocessing.sequence.pad_sequences(sequence, padding='post')
array([[1, 0, 0],
[2, 3, 0],
[4, 5, 6]], dtype=int32)
>>> tf.keras.preprocessing.sequence.pad_sequences(sequence, maxlen=2)
array([[0, 1],
[2, 3],
[5, 6]], dtype=int32)from tensorflow.keras.preprocessing.sequence import pad_sequences
pads = pad_sequences(corpus_sequences, maxlen=10)
print(corpus)
print(word_to_index)
print(pads)
np.array(pads)
-> 가장 긴 배열에 맞춰서 나온다.
pad_sequences(sequences, maxlen=None, dtype='int32', padding='pre', truncating='pre', value=0.0)
❓ 순서, 맥락, 시퀀스 가 중요한 데이터는 어떤 데이터가 있을까?
◾ 시계열 데이터, 주식, 날씨, 악보, 영상, 대본, 유전자, DNA, 심전도
-> 순서가 중요한 시계열 데이터는 섞지 않고 순서대로 나누기도 한다.
✅ 1106 실습파일
KLUE 뉴스 헤드라인은 제목만 있었는데 이 데이터는 내용까지 조금 더 분량이 많다.
label, one-hot 형태
get_dummies 를 사용하여 label 값을 one-hot 형태로 만듭니다. LabelEncoder 를 사용할 수도 있고, keras 전처리 도구를 사용할 수도 있다. one-hot-encoding 을 해주는 이유
❓ RNN 모델을 만들 예정이며, 출력층은 기존에 만들었떤 것처럼 만들 예정이다. "행정", "경제", "복지" label을 one-hot-encoding 을 해주는 이유?
◾ 분류 모델의 출력층에서 softmax 함수를 쓰기 위해서
◾ softmax는 각 클래스의 확률값을 반환하며 각각의 클래스의 합계를 구했을 때 1이 된다.
train_test_split 으로 학습과 예측에 사용할 데이터를 나눈다.
시계열 데이터는 train_test_split 으로 나누지 않지만
여기에서는 각각의 문서가 순서가 있지는 않기 때문에 섞어서 나눠도 무방하다.
