[AI스쿨 7기, 13주차] 패딩, maxlen, post, 시퀀스, colah, timesteps, BackPropagation Through Time, 워드 임베딩, Bidirectional, adapt, GRUs, SimpleRNN, 토큰화, 텍스트 데이터 전처리, RNN,
멋쟁이사자처럼
221215 멋쟁이 사자처럼 AI스쿨 7기, 박조은 강사님 강의
✅ 1106번 실습 파일
머신러닝에서는 BOW, TF-IDF 인코딩 방식을 주로 사용하고 딥러닝에서도 사용한다. RNN 에서는 순차적으로 데이터를 인코딩해주는 시퀀스 인코딩 방식을 사용하면 좀 더 나은 성능을 내기도 한다.
패딩
- 문장의 길이가 제각각인 벡터의 크기를 패딩 작업을 통해 나머지 빈 공간을 0으로 채운다.
- shape 길이가 다르게 나오기 때문에 maxlen 으로 같게 맞춰준다. == maxlen은 패딩의 기준
- padding_type='post' 패딩을 앞(기본값) 이 아닌 뒤(post) 에 채운다.
from tensorflow.keras.preprocessing.sequence import pad_sequences
max_length = 500
padding_type = "post"
# X_train, X_test
X_train_sp = pad_sequences(train_sequence, maxlen=max_length, padding=padding_type)
X_test_sp = pad_sequences(test_sequence, maxlen=max_length, padding=padding_type)
X_train_sp.shape, X_test_sp.shapeRNN
시퀀스 데이터에 사용한다. 시퀀스 데이터란 연속의 데이터, 순서가 있는 자료.
기존 신경망과의 차이 : 결과값을 출력층 방향으로도 보내면서, 다시 은닉층 노드의 다음 계산의 입력으로 보내는 특징.
📌 https://colah.github.io/posts/2015-08-Understanding-LSTMs/ RNN 하면 많이 보이는 자료와 설명이 있는 블로그
- 타임스탭(timesteps) : 입력 시퀀스의 길이(input_length) 라고도 한다. 시점의 수. 인접한 타임스텝의 정보가 은닉층에 흐르기 때문에 이전 이벤트를 기억 가능(신경망 내부의 메모리 활용)
- 셀 : RNN 의 은닉층에서 활성화 함수를 통해 결과를 내보내는 역할을 하는 노드
- 메모리셀 : 이전의 값을 기억하는 메모리 역할을 수행하는 셀
- 은닉상태 : 은닉층의 메모리 셀에서 나온 값이 출력층 방향 또는 다음 시점의 자신(다음 메모리 셀) 에게 보내는 상태
- BackPropagation Through Time : 기존 역전파와는 달리 타입스텝별로 고려를 하기 때문에 Through Time. 타입스텝의 역방향으로 역전파를 통해 가중치 비율을 조정하여 오차 감소를 진행.
- 기울기 소실은 여전히 발생.
- 비교적 짧은 시퀀스에 대해서만 효과를 보임 -> 해결책 LSTM
워드 임베딩
https://www.tensorflow.org/text/guide/word_embeddings
https://www.tensorflow.org/text/tutorials/text_classification_rnn
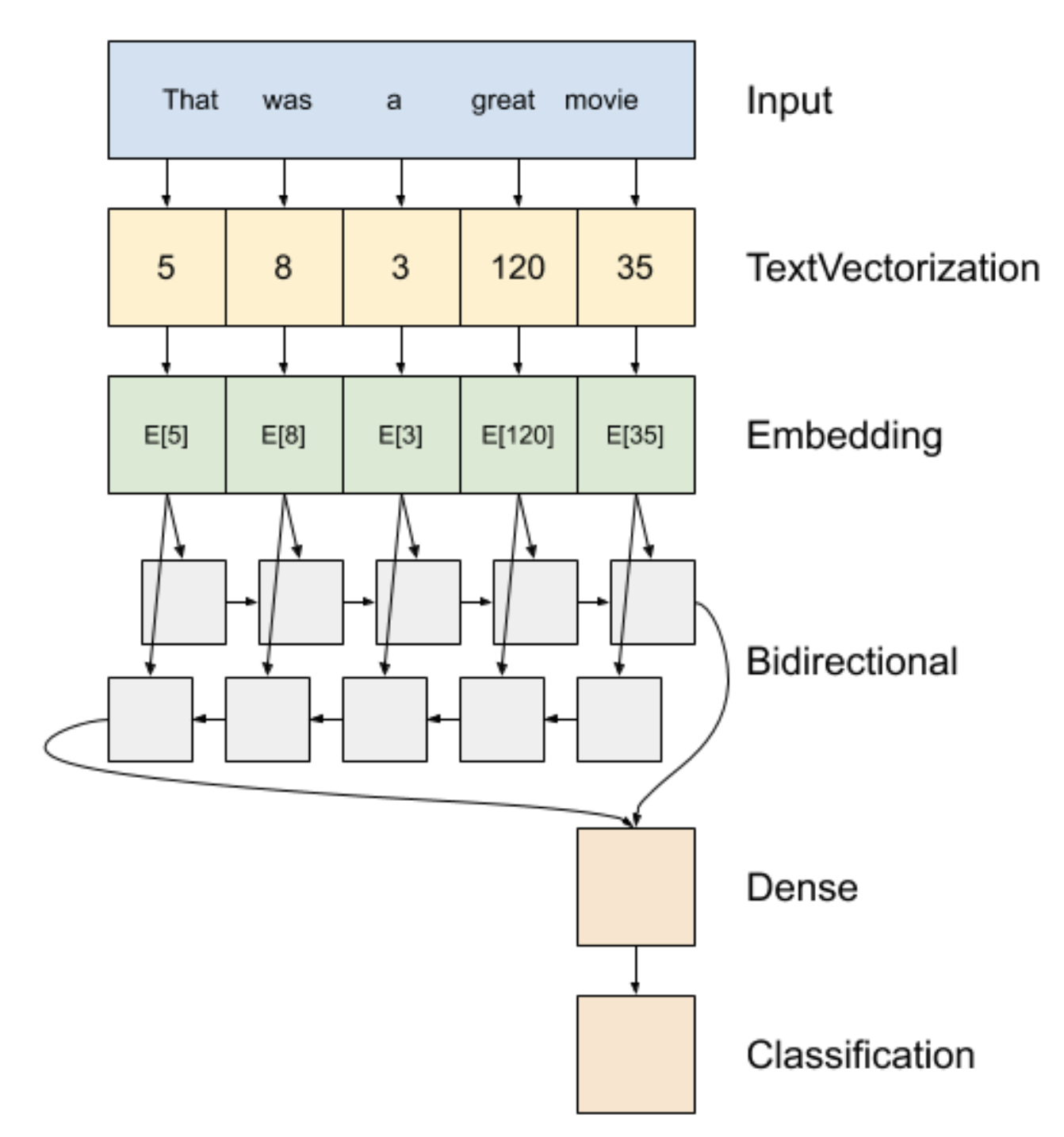
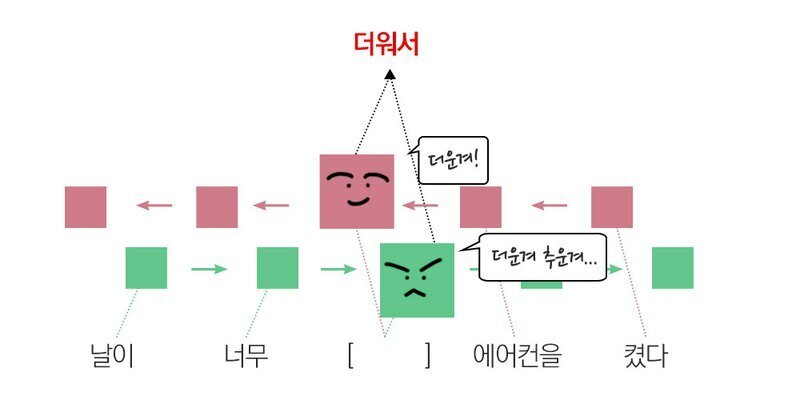
Bidirectional
순차 RNN으로만 하면 날이, 너무만 보고 날씨의 상태를 파악해야하지만 양방향 학습을 이용하면 켰다, 에어컨을 보고 날씨의 상태를 더 잘 유추할 수 있습니다
- 정수 인코딩은 모델이 해석하기 어려울 수 있습니다. 예를 들어 선형 분류기는 각 기능에 대해 단일 가중치를 학습합니다. 두 단어의 유사성과 인코딩의 유사성 사이에는 관계가 없기 때문에 이 기능 가중치 조합은 의미가 없습니다.
- 큰 데이터 세트로 작업할 때 8차원(작은 데이터 세트의 경우), 최대 1024차원의 단어 임베딩을 보는 것이 일반적
https://damien0x0023.github.io/rnnExplainer/ 시퀀스 인코딩을 해준 것. -> 임베딩
TextVectorization 레이어로 초기화하고 text_ds 에서 adapt 을 호출하여 해당 어휘를 구축
결과 차원은 (batch, sequence, embedding)
❓ 출력값이 어떤 형태로 나올까? Dense(1)
▪ 0~1 사이 확률값
GRUs(Gated Recurrent Units)
LSTM 을 변형시킨 알고리즘. 기울기 소실 문제 해결
GRUs 는 Update Gate 와 Reset Gate를 추가해, 과거의 정보를 어떻게 반영할 것인지 결정(GRU 는 게이트가 2개, LSTM 은 게이트가 3개)
GRU를 개발한 조경현 교수님의 강의도 부스트 코스에 있다.
모델
다음으로 시퀀스를 넘길 것인지 말 것인지. 그 다음이 마지막 층이라면 return_sequences 가 없다.
model.add(SimpleRNN(units=64, return_sequences=True))
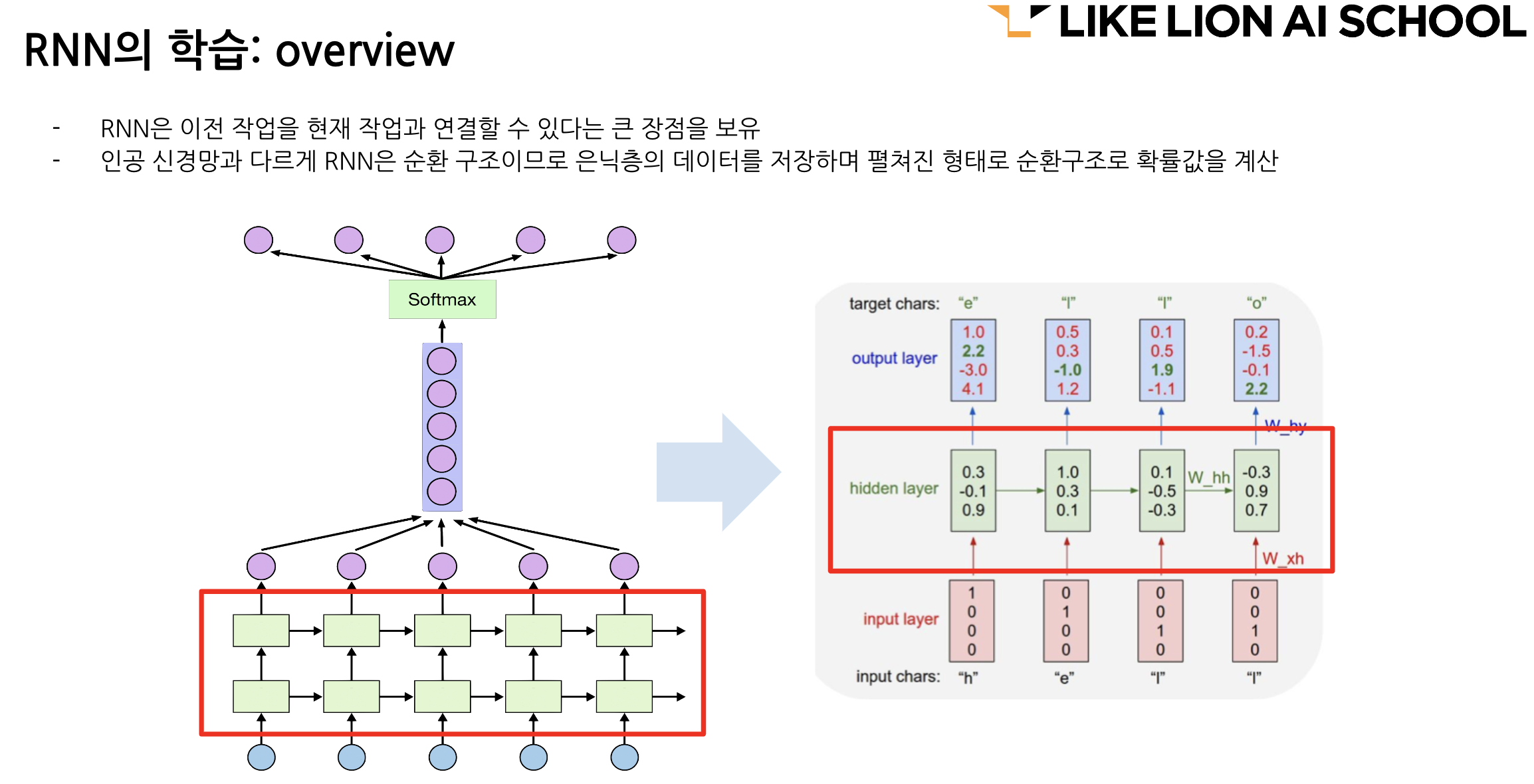
# # Simple RNN 레이어를 사용한 모델을 정의합니다.
model = Sequential()
# 입력-임베딩층
model.add(Embedding(vocab_size, embedding_dim, name='embedding', input_length=max_length))
model.add(SimpleRNN(units=64, return_sequences=True))
model.add(SimpleRNN(units=32))
model.add(Dense(units=16))
# 출력층 - 정치, 복지, 행정 3개를 반환
model.add(Dense(units=n_class, activation='softmax'))
model.summary()- validation_split 을 사용하면 성능이 잘 안나온다. 그런데 train_test_split 으로 train 을 train, valid 로 나눠준 데이터를 사용하면 좀 더 나은 성능을 낸다.
- stratify 유무의 차이 때문
# train 으로 validation 데이터 만들기 => validation_split 을 사용하면, y 값이 균형있게 학습되지 않는다.
X_train_val, X_valid, y_train_val, y_valid = train_test_split(
X_train_sp, y_train, test_size=0.2, random_state=42, stratify=y_train)
X_train_val.shape, X_valid.shape, y_train_val.shape, y_valid.shapeRNN 문서 : https://www.tensorflow.org/guide/keras/rnn
✅ 정리
❓ 텍스트 데이터 벡터화 하는 방법?
▪ 토큰화(str.split()) => one-hot-encoding => bag of words(min_df, max_df, analyzer, stopwords, n-gram)
▪ => TF-IDF(너무 자주 등장하는 단어는 낮은 가중치, 특정 문서에만 등장하는 단어는 높은 가중치)
▪ RNN 은 순서가 있는 데이터를 예측할 때 주로 사용하는데, BOW 는 순서를 보존하지 않는다.
▪ 그래서 시퀀스 방식의 인코딩을 사용했다.
▪ Embedding => 여러 각도에서 단어와 단어 사이의 거리를 본다. 가까운 거리에 있는 단어는 유사한 단어이고, 거리가 멀 수록 의미가 먼 단어이다.
▪ => 의미를 좀 더 보존할 수 있게 되었다.
❓ 텍스트 데이터 전처리 방법?
▪ 정규표현식 => 텍스트 정규화
▪ 불용어
▪ 형태소 분석 => 의미가 없는 조사, 어미, 구두점 등을 제외
▪ 어간추출(stemming 원형을 보존하지 않음), 표제어표기법(lemmatization, 원형을 보존)
RNN
- time-step 을 갖는 데이터에 주로 사용.
- 예) 자연어(챗봇), 시계열 데이터(주가 데이터), 음성(주파수), 심전도
- RNN, LSTM, GRU
- BPTT
✅ 1107 실습파일(시계열)
시계열 https://www.tensorflow.org/tutorials/structured_data/time_series
시계열 데이터 정규화 링크 https://www.tensorflow.org/tutorials/structured_data/time_series#%EB%8D%B0%EC%9D%B4%ED%84%B0_%EC%A0%95%EA%B7%9C%ED%99%94
❓ 이렇게 정규화를 하면 어떻게 변환이 될까?
train_mean = train_df.mean()
train_std = train_df.std()
train_df = (train_df - train_mean) / train_std
val_df = (val_df - train_mean) / train_std
test_df = (test_df - train_mean) / train_std▪ standard scaler
▪ 평균을 0, 표준편차를 1로 만들어준다. 그러나 이상치가 있다면 평균과 표준편차에 영향을 미쳐 변환된 데이터의 확산은 매우 달라지게 되므로 이상치가 있는 경우 균형 잡힌 척도를 보장할 수 없다.
📌 채용공고
linkedin, 자소설닷컴, 잡플래닛, 원티드, 잡코리아, 캐치, 점핏, 슈퍼루키, 사람인
면접 보러 가기 전에는 잡플래닛 면접 후기
이력서나 포트폴리오에 JD에 있는 내용을 최대한 반영하면 좋다.
linkedin => AIS7 에 참여했던 분들끼리 서로 추천사를 써주기!
https://jasoseol.com/
https://www.superookie.com/
https://www.jobplanet.co.kr/
https://www.jobkorea.co.kr/
퀴즈
10/10문제 (어려운데 왜지..)
1. 타임스텝(timesteps)을 가져 시퀀스 데이터(sequence data, 순서가 있는 자료로 시계열 자료나 텍스트 자료)를 처리하는 데 탁월하며 음성인식, 자연어 처리 등에 사용되는 딥러닝 기술은 무엇일까요?
- RNN
- 자연어 처리 중 주어진 코퍼스(corpus)에서 의미있는 단위로 나누는 작업을 위해 사용되는 방법은 무엇일까요?
- Tokenizer
- 딥러닝 모델에 자연어 데이터를 바로 넣는다면 인식하지 못하는 문제가 있어, 문자열 데이터를 숫자형으로 바꿔주는 작업(인코딩)을 위해 사용되는 방법은 무엇일까요?
- Vectorizer
- 각기 다른 문장(또는 문서)의 길이를 동일한 길이로 맞춰주어 모델에서 같은 길이의 문장에 대해서 하나의 행렬로 보고, 한꺼번에 묶어서 처리할 수 있도록 하는 방법은 무엇일까요?
- Padding
- 문자열 데이터를 숫자형으로만 바꿔 넣으면 단어 사이의 유사도를 파악하기 어려워 숫자형을 벡터형으로 변환해주는 작업이 필요합니다. 모델 구성층 중 각 단어의 유사도를 계산하여 주어진 배열을 정해진 길이로 압축해주는 층은 무엇일까요?
- Embedding layer
- embedding()함수는 입력과 출력을 위해 최소 2개의 매개변수가 필요한데 무엇일까요? (*참고: 2개의 매개변수는 차례로 입력될 총 단어수, 벡터의 크기(차원)을 뜻합니다.)
- vocab_size, embedding_dim
- return_sequences는 시퀀스 출력 여부로 레이어를 여러개로 쌓아올릴 때는 return_sequence=True 옵션을 사용한다.
- SimpleRNN은 RNN의 가장 기초적인 레이어로서 단순한 네트워크들이 이어져있는 모양이다.
- 다음은 자연어처리를 위한 RNN (Recurrent Neural Network) 모델층구성입니다. 다음 Embedding layer에 대한 설명으로 옳지 않은 것을 선택해주세요.
- Embedding layer을 통해 출력된 임베딩 벡터는 출력 배열에 새로운 차원으로 추가된다.
- Embedding layer을 통해 출력된 임베딩 벡터는 모델이 훈련되면서 학습된다.
- Embedding layer는 정수로 인코딩된 단어를 입력 받고, 각 단어 인덱스에 해당하는 임베딩 벡터를 찾는다.
- Embedding layer을 통해 출력된 임베딩 벡터의 최종 차원은 ( vocab_size, embedding_dim, batch_size)이 된다. => (batch_size, vocab_size, embedding_dim)
