1. RNN
RNN(Recurrent Neural Network) 순환신경망
연속적인 시퀀스(순서있는 데이터) 처리하기 위해 쓰임
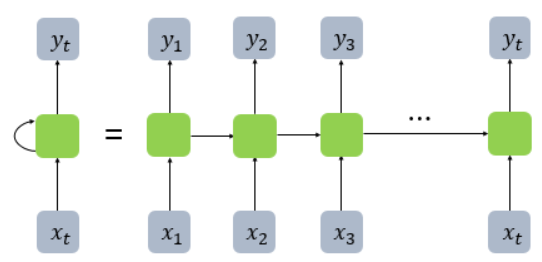
- 초록색 칸 = 셀의 벡터 크기 = layer 퍼셉트론 수
- 은닉층의 활성화함수를 거친 결과값을 [출력층 + 다음 은닉층노드]로 보냄
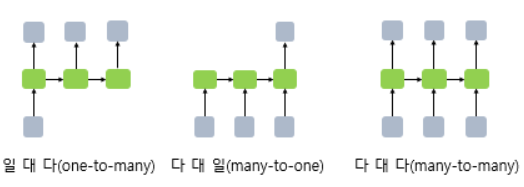
many-to-one: 스팸분류, 텍스트분류 등
many-to-many: 개체명인식, 품사태깅 등
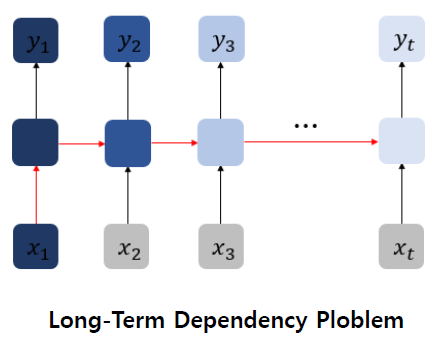
RNN은 이전 계산 결과에 의존(문장길어지면 성능)
장기의존성 문제 : 시간 길어질수록 앞 정보 소실
LSTM(Long Short-Term Memory)
RNN의 장기의존성 문제 해결
gate 개념 도입(~cell state) >> 어떤 정보는 기억, 기억X >> 기억력 높임
2. Seq2Seq
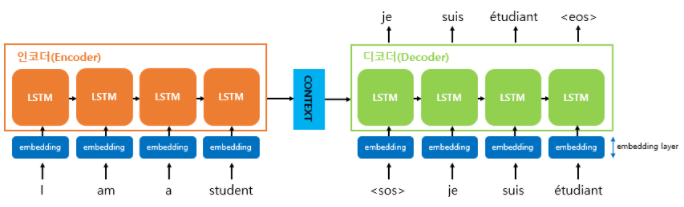
인코더는 입력 문장의 모든 단어들을 순차적으로 입력받은 뒤 context vector에 모든 단어 정보들을 압축해서 하나의 벡터 생성
context vector를 디코더가 받아서 번역된 단어를 한개씩 순차적으로 출력
- context vector = 인코더 마지막 히든스테이트 = 디코더 RNN 셀의 첫번째 히든스테이트
- 각 RNN셀의 입력 : [인풋 + 이전시점의 히든스테이트]
- 디코더 출력 시 매순간 softmax
- 번역기 학습시 데이터 3종류 : 인코더 입력 / 디코더 입력(sos입력) / 디코더 레이블(eos)
교사강요
학습시 예측값이 틀렸는데 입력으로 사용 >> 다음 예측 틀릴 가능성 높아짐 + 시간 오래걸려
-> 학습시 예측값을 입력으로 사용하지 않고 실제값을 입력으로 사용!
3. Attention
- Seq2Seq 문제점
- context vector가 고정된 크기(인코더의 히든스테이트 크기) >> 정보손실
- 기울기소실 문제
- Seq2Seq VS Attention
seq2seq는 문장번역시 입력문장 한번만 보고 다시 볼 수X(기억력 의존해서 번역)
Attention은 번역하고자하는 단어에 집중해서 원래 입력문장 다시 볼 수 있도록!
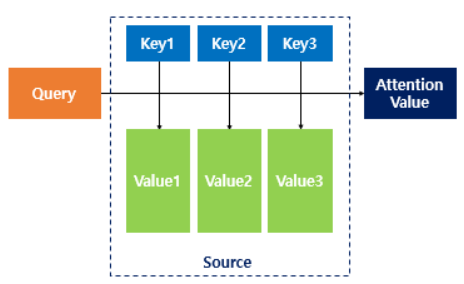
Q와 K의 유사도(구하는 방법따라 attention이름 바뀜) >> 유사도값 * V(각각) >> 유사도 반영된 값(Value)을 모두 더해 = attention value
닷-프로덕트 어텐션(Dot-Product Attention)
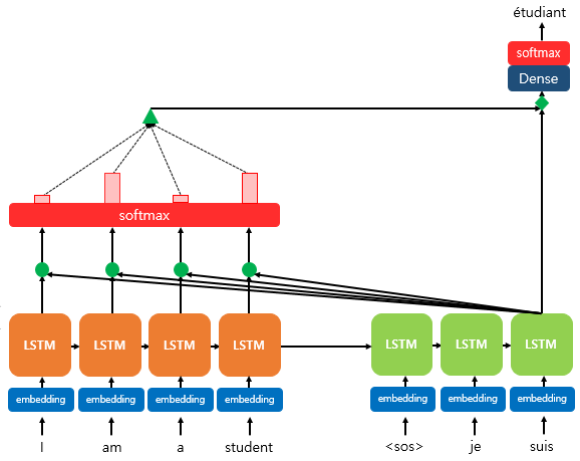
Q = t 시점의 디코더 셀의 히든스테이트(St)
K = 모든시점의 인코더 셀의 히든스테이트들
V = 모든시점의 인코더 셀의 히든스테이트들
- Q와 K의 유사도 구해(내적) : attention score
- softmax 함수 통과
- 정규화된 유사도 값을 인코더 히든스테이트(K=V)에 각각 곱하고 다 더해(가중합) : attention value = context vector
- attention value + 디코더 히든스테이트 concatenate : Vt
- tanh(Wc*Vt + b) = St 값을 출력층으로 보냄
- Yt = softmax(Wy*St + b)
4. 트랜스포머
Attention is All you need
attention으로 모든 state에 접근(RNN쓰지않고)
하이퍼파라미터
dmodel = 512 / 인코더, 디코더 입출력 크기 = 임베딩 벡터 차원
num_layers = 6 / 인코더, 디코더를 몇층으로 구성되어있는지
num_heads = 8 / 어텐션 병렬의 개수
dff = 2048 / FFNN 신경망 은닉층 크기 / FFNN 입출력층 크기 = dmodel
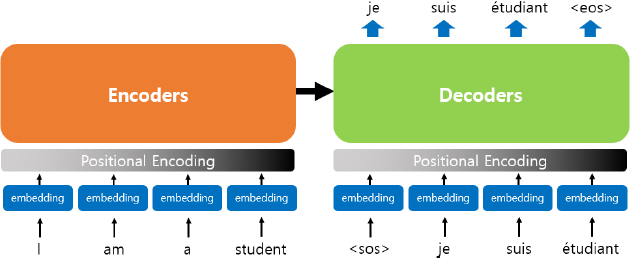
RNN은 순차적으로 입력 받음
트랜스포머는 한번에 입력 받아서 병렬연산 >> 위치정보 갖도록 Positional Encoding(벡터값을 더해줌)
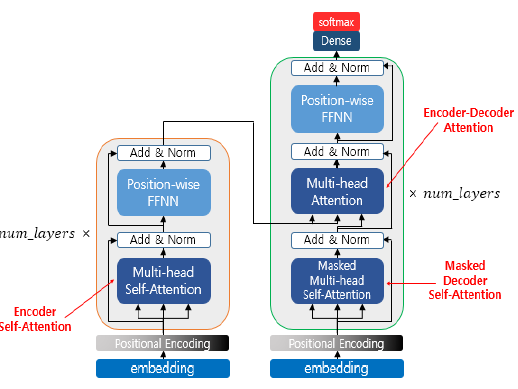
인코더 : attention 1종류 = Multi-head Self-Attention
디코더 : attention 2종류 = Masked Multi-head Self-Attention / Multi-head Attention(인코더-디코더 어텐션)
self-attention(Q=K=V)
문장 하나에 대해서만 모든 단어의 유사도를 구한다
Q = 입력문장의 모든 단어벡터들
K = 입력문장의 모든 단어벡터들
V = 입력문장의 모든 단어벡터들
- seq2seq + attention
Q = t 시점의 디코더 셀의 히든스테이트(St)
K = 모든시점의 인코더 셀의 히든스테이트들
V = 모든시점의 인코더 셀의 히든스테이트들
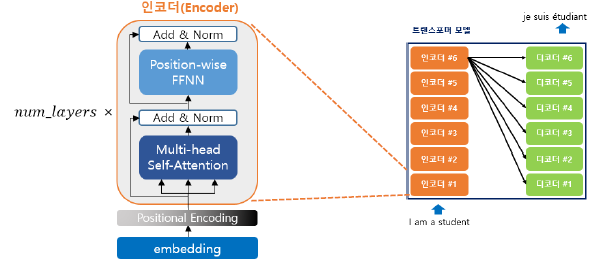
{ 인코더에는 두개의 큰 연산 = 두개의 서브층 } * 6 (인코더 6개라 6번 반복)
-
multi-head self-attention
Q, K, V 벡터 얻기위해 가중치(dmodel/num_heads=dk 크기) 곱함
* 스케일드 닷-프로덕트 어텐션
attention 메커니즘과 같이 Q와 K의 유사도(attention score) : 내적
루트dk로 나눠줌
소프트맥스(하나의 쿼리에 대해서 = Q방향으로(가로로))
V에 곱하고 다 더해 = attention value
{ attention value * num_heads >> [ 8개 head concatenate ] } * 가중치
= multi-head attention matrix -
FFNN(Position-wise Feed Forward Neural Network)
기본 MLP(multi-layer perceptron) = dense layer 의미 -
Add & Norm
인코더, 디코더 서브층 끝날때마다 적용 >> 학습돕기위해 부가적으로
1. Add(residual connection) : 잔차연결
연산값 + 기존x값 = F(x) + x = 멀티헤드어텐션 결과값 + 입력문장행렬
2. Norm(layer normalization) : 층 정규화
residual connection 결과값을 가로방향으로 각 층별 평균과 표준편차로 정규화
-
디코더 masked self-attention
어텐션 스코어 매트릭스에 직각삼각형 마스킹 추가
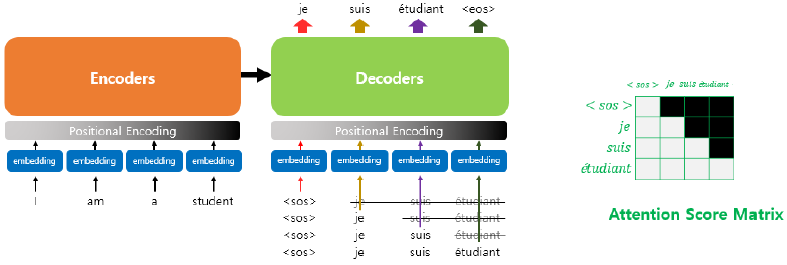
Masking
- pad masking = 열방향 = 독립적
K가 < pad >인 경우 softmax 전에 -무한대 값 박아놔 >> attention 연산에서 제외 - 디코더 self-attention 마스킹 = 대각선
cf) 디코더 셀프어텐션 열(K) 에 < pad > 있으면 추가적으로 pad masking 수행
- pad masking = 열방향 = 독립적
-
디코더 multi-head attention(인코더-디코더 어텐션)
Q = 디코더 벡터
K, V = 인코더 벡터
5. DQN
마르코프 상태(Markov State)
"모든 상태는 오직 그 직전의 상태와 그 때 한 행동에서만 의존한다.”는 가정
MDP(Markov Decision Process)
순차적으로 행동 결정하는 문제 해결하는 기법
- 구성요소 : 상태s, 행동a, 보상함수, 상태변환확률, 감가율
벨만방정식
[현재상태 가치함수]와 [다음상태 가치함수] 관계 나타내는 식
최적의 의사결정으로 가치를 최대화
가장 높은 누적보상을 얻을 수 있는 행동을 선택

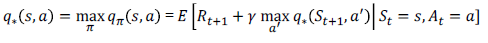
DQN
Value-based RL(가치기반강화학습)
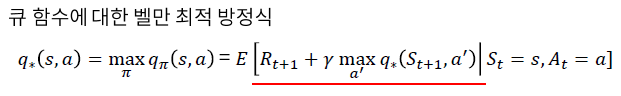
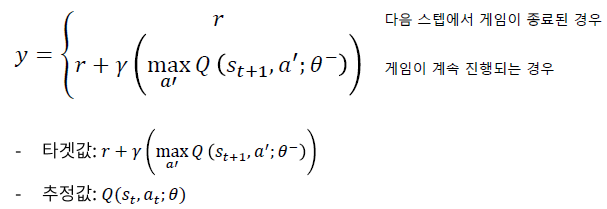
가치기반강화학습은 큐함수를 학습하여 최적 큐함수 얻고 이를 통해 의사결정
상태입력 >> 각 행동에 대한 Q함수값 도출 >> 최적Q함수 학습
타겟값 = 벨만최적방정식
->시간차오차(벨만최적방정식과 Qk(St,At)[예측값]) 줄이는 방향으로 학습
손실함수 : Huber loss
1. Go Deep
2. Replay Buffer 사용
강화학습은 연속적인 의사결정 과정으로 순차적 데이터 = 상관관계 O
상관관계 없애고 전체적 경향 알기위해 데이터 랜덤하게 샘플링
경험데이터 리플레이버퍼에 저장 > 임의로 추출 > 미니배치학습
* 경험데이터 : 현재상태, 행동, 보상, 다음상태, 종료정보(매스탭마다 저장)
3. target network 사용
- 일반네트워크 : 행동결정하거나 큐함수값 예측(매스텝마다 업데이트)
- 타겟네트워크 : 타겟값(벨만최적방정식) 계산(특정스텝마다 일반네트워크 복제)
6. Reinforce & Actor-Critic
Reinforce 알고리즘
Policy-based RL(정책기반강화학습)
Policy gradient(PG)
목적함수 : J(θ) 최대화 = 기대되는 보상의 합을 최대화 하는 방향으로 학습

Reinforce = Monte-Carlo Policy Gradient 방법
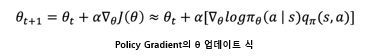

Q함수를 Gt값으로 대체
Reinforce VS Actor-Critic
reinforce 단점
- 하나의 에피소드가 끝나야 policy 업데이트 가능
- gradient의 분산이 매우 크다
- on-policy 방법 (off-policy는 리플레이버퍼 사용)
reinforce 의 Q함수를 근사 >> Critic network(Value) 학습
Actor-Critic
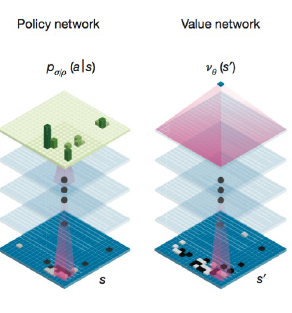
가치기반과 정책기반 강화학습 결합
두종류 네트워크 사용(Value network + Policy network)
- 가치네트워크(Critic)(Value)
DQN과 동일하게 가치학습(예측값이 타겟값과 유사하게 도출하도록 학습)
상태와 행동에 대한 가치 도출
바둑판에서의 승률 - 정책네트워크(Actor)(Policy)
정책 직접 학습 : Policy gradient(PG)
목적함수 최대화 하는 방향으로 학습 = 가치 최대화 하는 정책 학습
학습한 정책따라 에이전트의 의사결정 수행 = 행동결정
각 칸에 바둑 놓을 확률
Actor-Critic VS A2C(Advantage-Actor-Critic)
A2C는 advantage 함수 사용(state의 가치를 빼줌)
advantage(내행동에 대한 상대적가치) 함수 = Q함수 - baseline
A2C 손실함수



자세하고 좋은설명 감사합니당ㅎㅎ