선형 회귀와 선형 분류_선형분류
선형 분류
로지스틱 회귀(Logistic Regression) 감 잡기
-
이진 분류 문제를 해결하기 위한 기본 알고리즘 중 하나로
입력 데이터가 후보 클래스 중 각각의 클래스일 확률을 예측하는 모델 -
확률이 갖는 값의 범위가 0~1의 실수값이므로
-
그 확률을 직접적으로 예측(→ 확률 추정!)하는 방식으로 문제를 해결
- 즉, 분류 문제를 풀지만 회귀 방식으로 문제를 접근 (그래서 이름도 로지스틱 ʻ회귀ʼ)

-
예측한 특정 클래스의 확률 값이 (일반적으로) 50% 이상이면 해당 클래스에 속한다고 예측
- 이를 양성(positive) 라고 부르며
- 그 반대의 경우는 음성(negative)라고 부름
-
다중 클래스 분류 문제의 경우 아래의 접근법이 있음
- One-vs-One (OvO)
- A B C가 있을 때 서로를 비교해서 맞는 것을 파악
- One-vs-Rest (OvR)
- A B C가 있을 때 각자가 맞는지 아닌지 파악
- Softmax Regression⭐
- A B C가 있을 때 각자가 얼마나 맞는지 확률적으로 파악
- One-vs-One (OvO)
로지스틱 회귀
로지스틱 회귀도 선형 모델의 조건(독립 변수간 독립성)을 가정
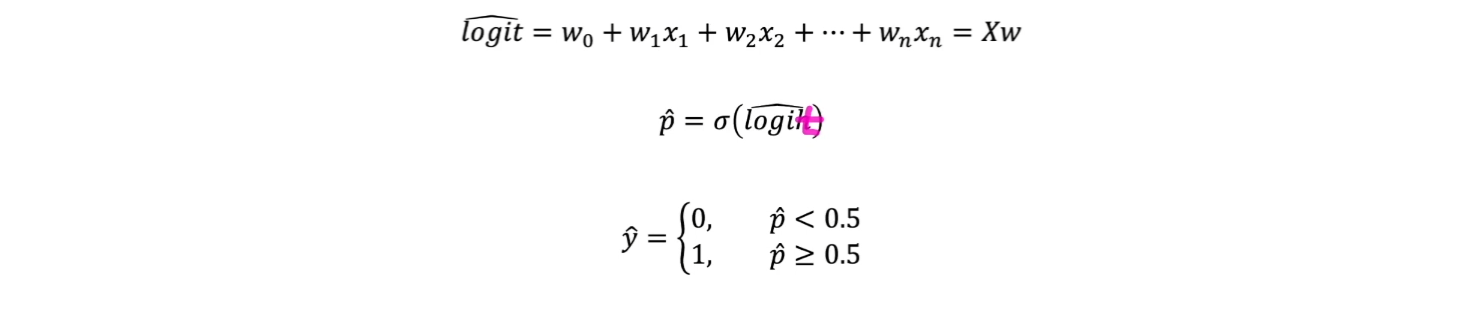

- 양성과 음성값을 찾아내기 위해
- 회귀 방식으로 풀고
- 확률로 만든 뒤
- 분류를 하는 것이다.
로짓(로그 오즈), 로지스틱 함수

- 로지스틱 회귀 모델의 출력 결과는 로짓(logit, log-odds)에 해당
- 따라서 특정 클래스일 확률(p)을 알기 위해 로지스틱 함수를 활용
- 왜 확률(p)를 바로 구하지 않는 건가??
- 선형 모델은 독립변수의 선형 변환에 따른 종속 변수의 관계를 알아보는 식
- 하지만 확률의 입장에서 변화량이 구간에 따라 다른 의미를 갖음
- 예를 들어) 0.49 ↔ 0.50 vs 0.98 ↔ 0.99
- 즉, 출력 결과의 해석이 선형적이지 않을 수 있음
- 이를 위해 선형적일 수 있는 다른 표현(여기서는 로짓, logit)을 사용
비용 함수 (1/2)
-
분류 문제 역시 정답과의 차이로 비용 함수를 계산
-
분류 문제는 log 함수를 이용한 로그 손실(log loss) 값을 사용
-
단순 회귀 보다는 직관적이지 않은 비용 함수를 사용
-
정답을 잘 예측해야 하는 과정을 담아낼 수 있는 함수를 활용
-
목적 데이터의 클래스가 양성일 경우(y = 1)와 음성일 경우(y = 0)로 나누어
-
하나의 데이터에 대한 비용 함수를 고려하면 아래와 같음
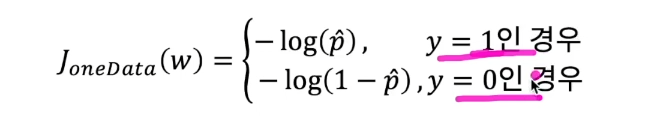

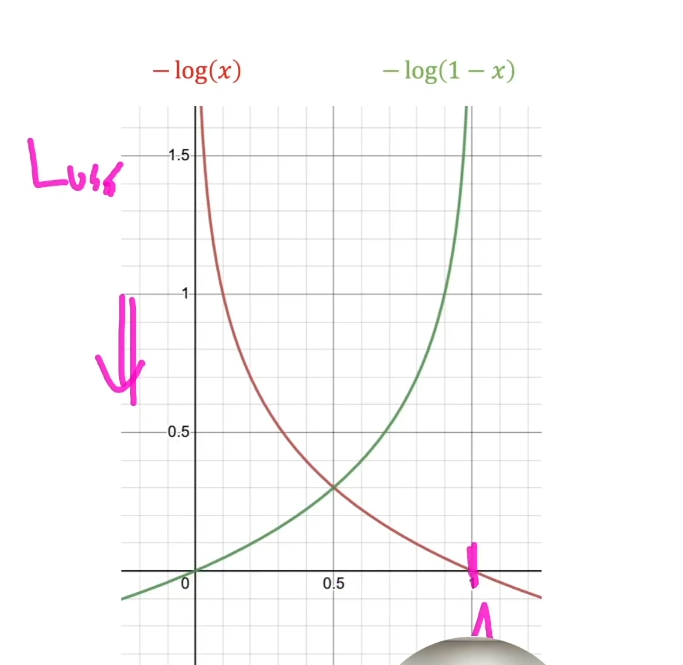
비용함수는 낮아야 되기 때문에 x가 1으로 갈 수 있게 진행되어야 한다.
비용 함수 (2/2)
앞서 살펴 본 식은 아래와 같이 하나의 식으로 사용할 수 있음
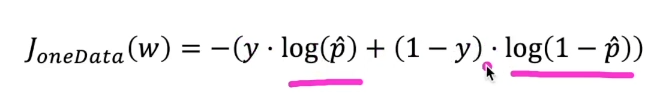
- 실제 정답(y)의 값에 따라 각 항이 삭제되어 똑같은 식으로 볼 수 있음
- 전체 학습 데이터에 대한 비용 함수는 모든 비용 함수의 평균
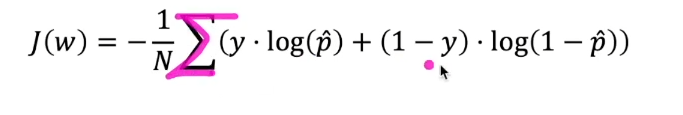
분류 문제의 최적화
비용함수를 최적화하는 방법을 알아보자
분류 문제도 비용 함수를 최소화 시켜야하는 최적화 문제이며 그러한 파라미터(w)들을 찾아야 함
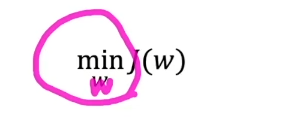
-
분류 문제에서 활용하는 로그 로스(log loss)의 경우,
회귀 문제의 정규 방정식과 같이 직접적으로 계산 가능한 해가 없음 -
따라서 경사 하강법 방법을 사용해서 파라미터(w)를 찾아야 함
-
또한 이전에 살펴본 라쏘(Lasso) 혹은 릿지(Ridge) 회귀의 규제 방법론을 사용할 수 있음
경사 하강법 ‒ 파라미터 업데이트 (로지스틱 회귀)

이 부분은 너무 깊게 이해 안 해도 될 듯..
