선형 회귀와 선형 분류_다중공선성과 규제
다중공선성 (multicollinearity)
앞에 글에서 선형 모델을 깨뜨리는 다중공선성 문제를 언급했었다.
다중 공선성이란 무엇일까?
입력 데이터가 갖고 있는 특징값들 사이에 상관 관계가 존재할 때 발생하는 문제 상황
-
이 상황에서는 머신 러닝 모델이 작은 데이터 변화에도 민감하게 반응
즉, 안정성과 해석력을 저하시킬 수 있음 -
다중공선성이 있는 데이터를 사용할 때,
-
정규 방정식으로 해를 구하는 상황에서는 치명적인 문제가 발생
- 정규 방정식 해 풀이에 사용되는 (XtX)^-1이 존재하지 않을 수 있음
- XtX 의 값이 점차 특이 행렬(Singular matrix)에 가까워짐
-
이 상황을 해결하기 위해 SVD-OLS라는 회피 방법이 존재
- 다중공선성을 해결하기 위한 방법이 아님
- 강한 다중공선성이 있는 경우 정규 방정식으로 풀 수 없는 해를 다른 방식으로 구하는 방법을 제시
SVD-OLS, Singular Value Decomposition-OLS
SVD-OLS란 SVD를 활용해 선형 회귀 모델의 해를 구하는 방법이다.
학습 데이터를 모아둔 행렬 X에 SVD를 적용해 특이값 분해 (X = UΣVt)
• 특이값이 분해된 입력 X에 OLS 방식의 풀이를 적용
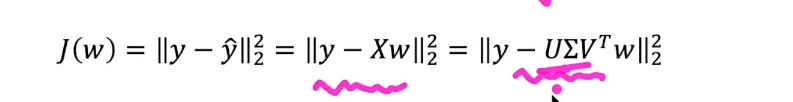
- 변경한 식을 바탕으로 해를 구하면
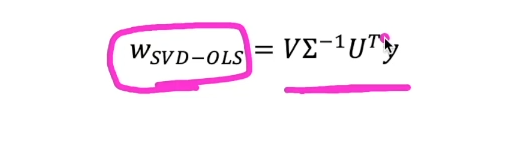
- 시간 복잡도 : O(np^2)
• n : 입력 데이터 수 / p : 사용하는 특성의 수
• 입력 데이터와 사용하는 특성의 수 모두에 영향을 받음
SVD-OLS VS OLS
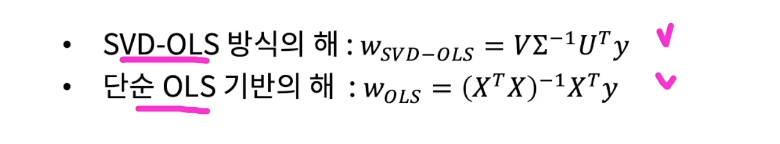
- 주목할 부분은 SVD-OLS에서는 (XtX^-1) 계산 부분이 존재하지 않음
• 다중공선성이 크게 존재하는 경우
• XtX 이 특이 행렬이 되거나 특이 행렬에 가까워짐
• 그렇다면 역행렬을 계산할 수 없음 - 따라서, XtX의 역행렬을 직접 계산하지 않고도 해를 구할 수 있음
• 물론 정확한 해를 구하는 것은 아님 - 단, 대신 SVD 계산으로 인한 시간 소요가 더욱 늘어남
• 단순 OLS : O(p^3)
• SVD-OLS : O(np^2)
• 일반적으로 n ≫ p 이므로 - Scikit-learn 패키지 안의 선형 회귀 알고리즘은 SVD류의 방식으로 구현되어 있음
SVD-OLS 방식으로 선형 회귀 문제 풀기
1. 다중공선성이 없는 경우 -> OLS와 동일한 해를 도출
# SVD-OLS 방식을 이용한 선형 모델 풀이
# w = V @ SIGMA-1 @ U^T @ y
def calc_SVDOLS(X, y):
# svd를 적용해 U, SIGMA, V^T(Vt)를 구함
U, s, Vt = np.linalg.svd(X, full_matrices=False)
SIGMA = np.diag(s)
# SVD-OLS 수식 적용
w_svdols = Vt.T @ np.linalg.inv(SIGMA) @ U.T @ y
return w_svdols
w_svdols = calc_SVDOLS(X, y)
w_ols = calc_OLS(X, y)
print('SVD OLS로 예측한 w0 : ', w_svdols[0])
print('SVD OLS로 예측한 w1 : ', w_svdols[1])
print('-'*50)
print('OLS로 예측한 w0 : ', w_ols[0])
print('OLS로 예측한 w1 : ', w_ols[1])
print('-'*50)
print('실제 w0 : ', w0)
print('실제 w1 : ', w1)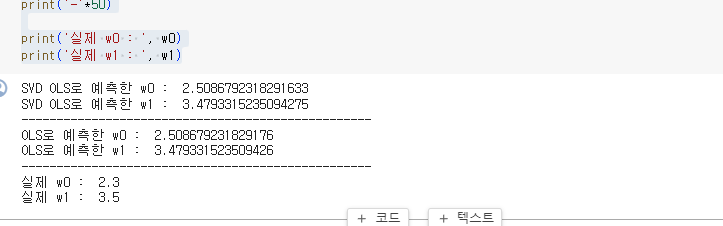
SVD OLS로 예측한 것과 OLS로 예측한 것의 결과값이 거의 동일한 것을 볼 수 있다.
2. 다중공선성이 있는 경우 -> 해를 구할 수 없던 OLS와 다르게 해 도출 가능
w_svdols = calc_SVDOLS(X_col, y_col)
print('SVD OLS로 예측한 w0 : ', w_svdols[0])
print('SVD OLS로 예측한 w1 : ', w_svdols[1])
print('SVD OLS로 예측한 w2 : ', w_svdols[2])
print('-'*50)
print('실제 w0 : ', w0_col)
print('실제 w1 : ', w1_col)
print('실제 w2 : ', w2_col)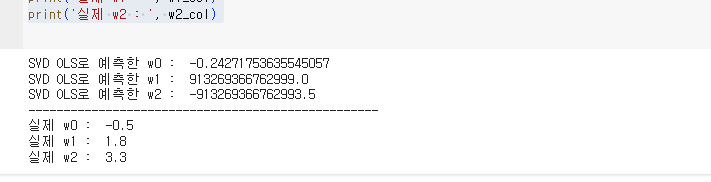
SVD OLS 값이 엄청 이상하게 나온다.
규제(Regulation)를 사용하는 선형 모델
-
과적합 문제 (Over-fitting)
- 머신 러닝 모델이 피해야 하는 중요한 문제
- 모델이 학습 데이터에 너무 집중해 일반화가 떨어지는 상황
-
과적합이 발생하면 파라미터인 w의 값이 매우 커지게 됨
-
따라서, w의 값이 너무 커지지 않도록 규제(regulation)를 가해 과적합 문제를 회피할 수 있음
-
선형 모델에서 규제를 추가해 일반화 성능에 도움이 되도록 설계한 모델이 있음
- 라쏘 회귀 (Lasso regression)
- 릿지 회귀 (Ridge regression)
라쏘 회귀와 릿지 회귀
-
머신 러닝 모델의 목적은 비용 함수의 최소화
-
이에 따라 기존 비용 함수에 제어할 변수 항목을 추가하는 방식으로 규제를 진행
-
추가로 규제 강도를 조절할 수 있는 새로운 변수 a를 추가
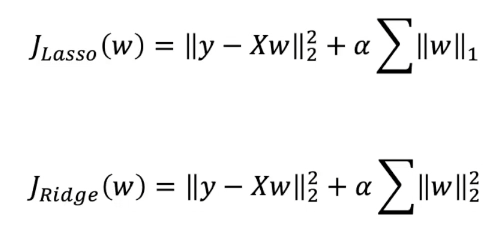
- 라쏘 회귀 비용 함수의 경우 머신 러닝 모델의 파라미터의 절댓값의 합 항을 추가
- 릿지의 경우는 제곱합항을 추가
라쏘 회귀
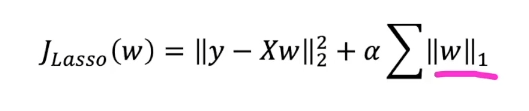
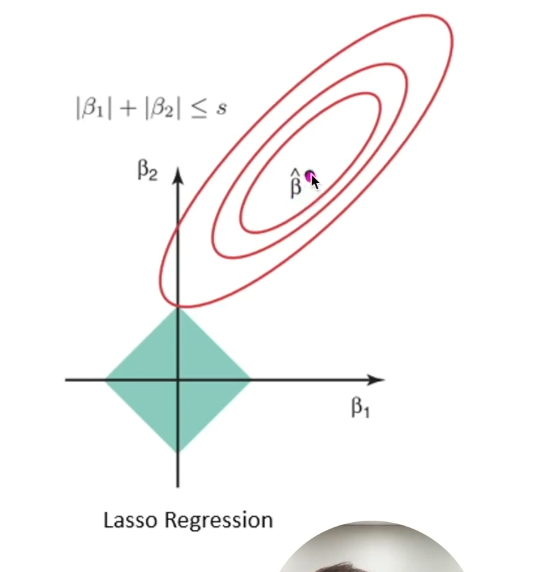
- 라쏘 회귀에 사용되는 L1 규제는 일부 파라미터의 값을 완전히 0으로 만들 수 있음
- 이를 통해 모델이 사용하는 데이터 특성 중 불필요한 특성을 무시하는 효과를 가져올 수 있음
- 모델이 단순화되어 해석이 용이함
- 변수가 많고, 일부의 변수가 중요한 역할을 하는 경우 활용될 수 있음!
릿지 회귀
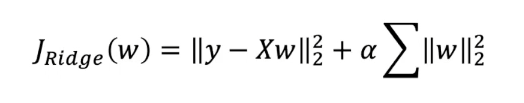
-
릿지 회귀에 사용되는 L2 규제는 파라미터 값을 적당히 작게 만듦
- 0에 가까운 값이지만 0이 되지는 않음
-
이는 입력으로 받는 데이터의 모든 부분을 이용해 출력을 판단하는데 사용
-
따라서, 모든 특성이 출력 결과에 적당히 영향을 미치는 경우에 유용함
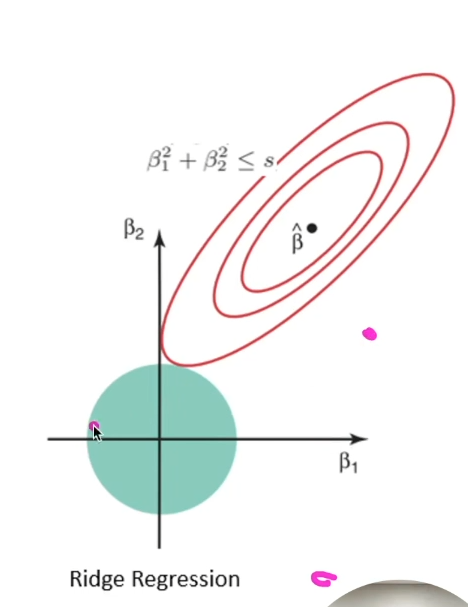
라쏘(Lasso)와 릿지(Ridge) 회귀
from sklearn.linear_model import Lasso, Ridge
lasso_reg = Lasso(alpha=0.1)
lasso_reg.fit(X, y)
print('Lasso 예측 w0 와 w1 : ', lasso_reg.intercept_, lasso_reg.coef_[1])
ridge_reg = Ridge(alpha=0.1)
ridge_reg.fit(X, y)
print('Ridge 예측 w0 와 w1 : ', ridge_reg.intercept_, ridge_reg.coef_[1])
print('-'*50)
print('실제 w0 : ', w0)
print('실제 w1 : ', w1)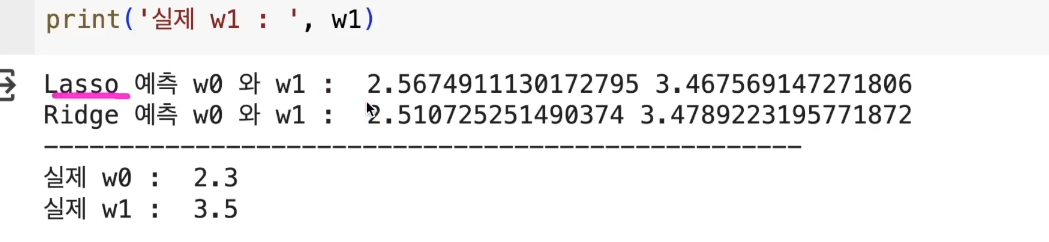
Lasso에서 w1이 0이 아닌경우도 있다
Lasso에서 0으로 만드는 것은 의미가 없는 것만 0으로 만들기 때문!
