선형 회귀와 선형 분류_확률적 경사 하강법 (SGD)
경사 하강법, Gradient Decent
-
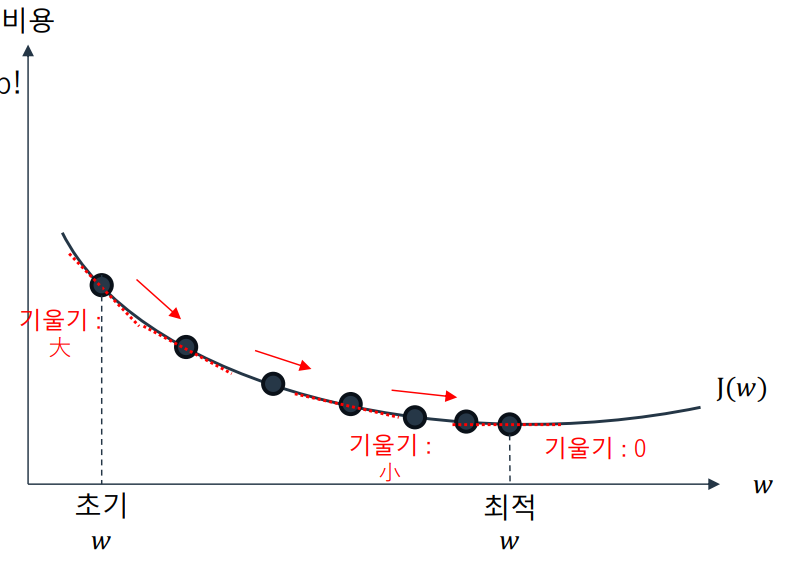
비용 함수를 최소화하기 위해 반복해서 파라미터를 조정해가는 방법
-
임의로 잡은 초기 파라미터 값을 기준으로
비용 함수의 기울기(Gradient)를 계산하여
기울기가 줄어드는 방향으로 파라미터를 수정 이동 -
반복 수행으로 기울기가 0에 가까워지면(최적값에 도달하면) Stop!
-
주의 사항
- 적절한 학습률(learning rate, 학습 속도)에 대한 탐구가 필요
- 값이 너무 작다면 최적화 소요 시간 ↑
- 값이 너무 크다면 발산 혹은 최적값 도달 가능성 ↓
- 적절한 학습률(learning rate, 학습 속도)에 대한 탐구가 필요
경사 하강법 - 파라미터 업데이트
- 비용 함수(J(w))를 통해 구한 전체 비용을 대상으로
- 각 파라미터의 미분값(편미분)을 구하고
- 현재 값을 기준으로 기울기가 작아지는 방향( -gradient )으로 이동
- 너무 빠른 혹은 느린 학습을 방지하고자 적절한 학습률(learning rate, lr)이 사용
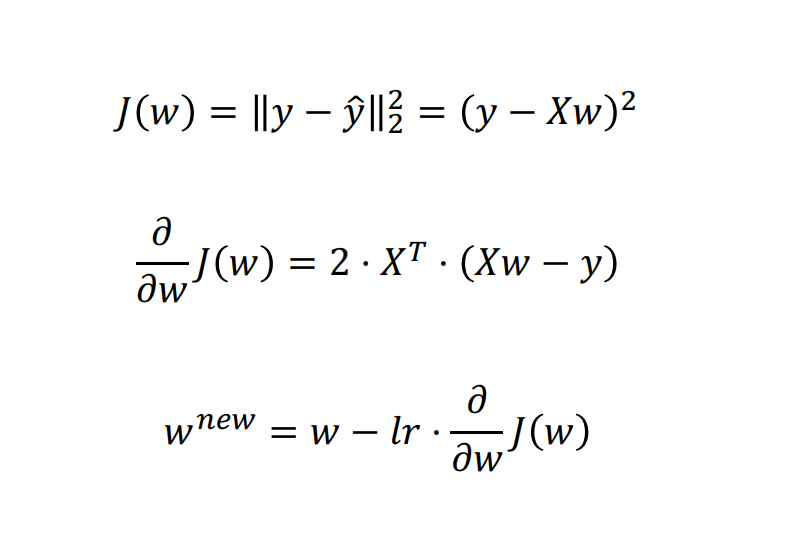
확률적 경사 하강법으로 선형 회귀 문제를 풀어보자
학습률, 학습량 설정
np.random.seed(seed)
# 학습률 및 학습량 설정
lr = 0.0001 #학습률
epochs = 1000 #몇번 학습할지.
# 임의의 초기 파라미터 세팅
init_params = np.random.randn(2, 1)
print('초기 파라미터 크기 : ', init_params.shape)
print('초기 파라미터 값 : ', 'w0 : ', init_params[0][0], '/ w1 : ', init_params[1][0])
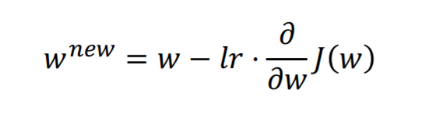
위의 식을 넣어주자(gradient가 위의 마지막쪽 곱셈)
def calc_SGD(x, y, lr, epochs, init_params):
# 반복적인 계산을 위해 for문 활용
for i in range(epochs):
# 예측과 오차 계산뺏어 그대로 이제 여기다가
y_pred = init_params[0] + init_params[1] * x
error = y_pred - y
# 그래디언트 계산
gradient = 2 * X.T @ (X @ init_params - y.reshape(-1, 1)) # reshape : vector를 2차원 matrix로 변환
# 파라미터 업데이트
init_params -= lr * gradient
return init_params
w_SGD = calc_SGD(x, y, lr, epochs, init_params)
print('SGD로 예측한 w0 : ', w_SGD[0][0])
print('SGD로 예측한 w1 : ', w_SGD[1][0])
print('-'*50)
print('실제 w0 : ', w0)
print('실제 w1 : ', w1)확률적 경사 하강법, Stochastic Gradient Decent
경사 하강법은 사용하는 모든 학습 데이터에 대해 기울기 계산이 진행된다.
따라서 학습 데이터가 많은 경우 시간 소요가 크다.
피쳐의 수 보다 학습데이터의 수가 많을 경우 매우 치명적!
- 이를 극복하기 위해
전체 데이터 중 임의로 일부 데이터를 샘플링하여
그것을 대상으로 경사 하강법을 진행
- 이를 확률적 경사 하강 방법 이라고 한다. Stochastic Gradient Decent - 작은 데이터로 수정 이동을 반복하므로 빠른 수렴이 가능!
- 데이터가 많거나(n ≫) 특성 feature가 많은 경우(p ≫) 사용하기 용이함
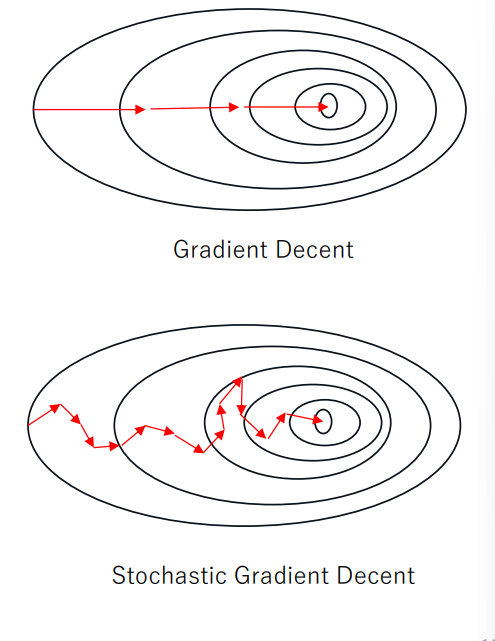
정규 방정식 vs 경사 하강법
이전 글에서 배운 정규 방정식과
이번 글에서 배운 경사 하강법 둘 중에 무엇을 써야 될까?
데이터 상황에 맞춰 선택할 수 있다.
-
정규 방정식
- 튜닝할 변수가 없이 명시적으로 해를 제공
- 하지만 특성의 수가 많다면 계산 복잡도와 메모리가 많이 필요
- 따라서 훈련 세트가 크지 않은 상황에서 빠르게 해를 구하기 좋음
-
경사 하강법
- 특성 수와 샘플의 수에 민감도가 적음
- 하지만 반복적인 연산이 필요하며 변수 튜닝이 결과에 영향을 줄 수 있음
-
두 방법이 모두 같은 해를 제공하나요?
- 그렇, 하지만
선형 모델의 큰 가정인 독립 변수 간의 강한 상관 관계가 있다면, 다중공선성(multicollinearity) 문제가 발생
- 그렇, 하지만

LV. 1