선형 분류 모델을 이용한 실습 2
이제 모델을 학습 해보자.
1. 데이터 분리
학습에 사용될 데이터와 평가에 사용될 데이터를 분리해준다.
from sklearn.model_selection import train_test_split
X = data.drop(y_column, axis=1)
y = data[y_column]
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
random_state=42)print('#'*20, 'X_train', '#'*20)
print(X_train.head, end='\n')
print('#'*20, 'Y_train', '#'*20)
print(y_train.head, end='\n\n')
print('#'*20, 'X_test', '#'*20)
print(X_test.head, end='\n')
print('#'*20, 'Y_test', '#'*20)
print(y_test.head, end='\n')2.학습 진행
from sklearn.linear_model import LogisticRegression
# 선형 회귀 모델 초기화 및 학습
logistic_reg = LogisticRegression()
logistic_reg.fit(X_train, y_train)
# 학습된 모델의 계수(coefficients) 및 절편(intercept) 출력
coefficients = logistic_reg.coef_
intercept = logistic_reg.intercept_
print('#'*20, '학습된 파라미터 값', '#'*20)
print(coefficients)
print('#'*20, '학습된 절편 값', '#'*20)
print(intercept)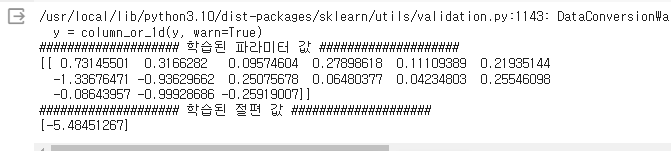
16개의 w들이 나온다.
3.학습 모델 평가 진행
accuracy_score 전체 갯수 중에 맞춘 갯수를 출력해준다.
from sklearn.metrics import accuracy_score
# 예측 수행
y_train_pred = logistic_reg.predict(X_train)
y_test_pred = logistic_reg.predict(X_test)
# 평가 지표 계산: 정확도 (맞은수/전체)
acc_train = accuracy_score(y_train, y_train_pred)
acc_test = accuracy_score(y_test, y_test_pred)
print('학습 데이터를 이용한 Acc 값 :', acc_train)
print('평가 데이터를 이용한 Acc 값 :', acc_test)
이 방법 외에도 다른 방법이 있다.
바로 Confusion Matrix !
# Confusion matrix 생성을 위한 준비
from sklearn.metrics import confusion_matrix
cm_train = confusion_matrix(y_train, y_train_pred)
cm_test = confusion_matrix(y_test, y_test_pred)# 학습 데이터를 활용한 confusion matrix
plt.imshow(cm_train, interpolation='nearest', cmap='Blues')
plt.title("Confusion Matrix (Train)")
plt.colorbar()
tick_marks = np.arange(len(np.unique(y_train)))
plt.xticks(tick_marks, np.unique(y_train))
plt.yticks(tick_marks, np.unique(y_train))
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
# 각 셀에 숫자 표시
for i in range(cm_train.shape[0]):
for j in range(cm_train.shape[1]):
plt.text(j, i, cm_train[i, j], ha="center", va="center", color="black")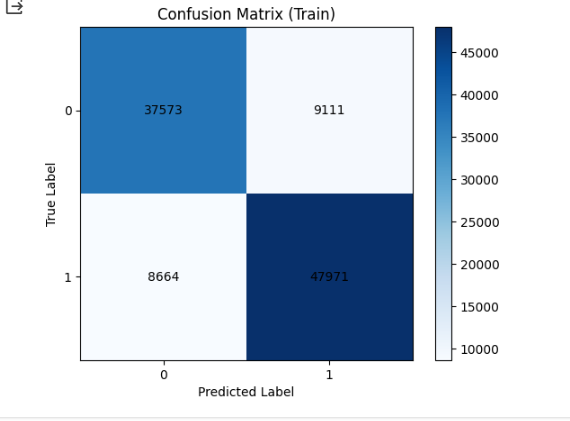
좌상 → 우하 방향 대각선 위치의 값이 클 수록 좋은 결과
반대로 좌하→우상 방향 대각선 위치의 값이 작을 수 록 좋다.
4.결과 해석
결과 해석 - 변수의 중요도
로지스틱 회귀 모델에 영향을 미치는 변수의 중요도를 확인해보자
coeff_df = pd.DataFrame({'feature': X_train.columns, 'coefficient': logistic_reg.coef_.flatten()})
# 계수의 절대값을 기준으로 내림차순 정렬
coeff_df['abs_coefficient'] = coeff_df['coefficient'].abs()
coeff_df_sorted = coeff_df.sort_values(by='abs_coefficient', ascending=False)
# 변수의 영향력을 확인
coeff_df_sorted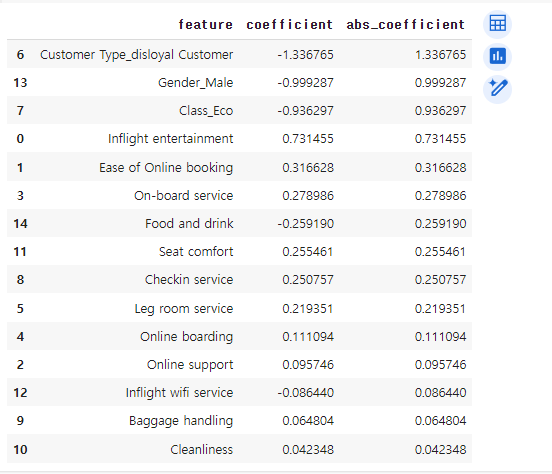
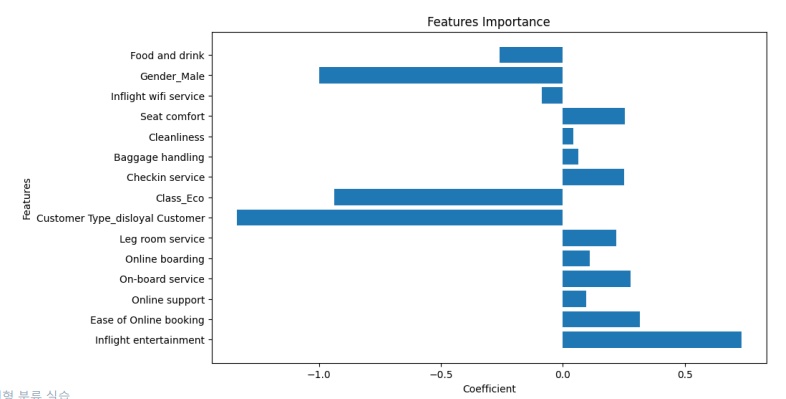
이를 시각화 하면 아래와 같이 볼 수 있다.
숙제

이건 주말에 해보자..

LV. 1