클러스터링 기법을 활용한 실습
캐글데이터를 이용해 클러스터링 기법을 실습해보자.
데이터 셋 설명
[Mall Customers 데이터]
200명의 쇼핑몰 고객에 대한 정보 데이터
• 아래의 변수를 포함
• 고객 ID
• 성별
• 나이
• 연간 소득
• 쇼핑 점수
• 쇼핑 행동과 지출 성향을 기반으로 쇼핑몰에서 점수 부여
데이터 타입 및 고려사항
- 고객 ID
• 수치형 데이터
• 고유 식별자로 일반적으로 학습에서 제외 - 성별
• 범주형 (카테고리형) 데이터
• 인코딩 과정이 전처리로 필요함 - 나이, 연간 소득, 쇼핑 점수
• 수치형 데이터
• 각자 서로 다른 스케일을 갖고 있음
• 거리 기반 군집화에서 스케일 매칭이 매우 중요한 요소
문제 정의
풀어야 하는 문제
• 주어진 고객 데이터를 바탕으로 고객을 세분화(Customer Segmentation) 군집화
머신 러닝 모델의 입, 출력 정의
• 입력 : 고객 정보 데이터
• 출력 : 클러스터링 결과
군집화를 통해 어떤 문제를 정의하는지가 중요.
하지만 이번 실습은 문제정의 보다는 군집화에 집중!
1. 데이터 로드 및 기초 통계 분석
import pandas as pd
# 데이터 경로 지정 및 읽어오기
data_path = '/content/Mall_Customers.csv'
customers = pd.read_csv(data_path)
# 데이터 꼴 확인
customers.head()# 기본 정보
print('#'*20, '기본 정보', '#'*20)
customers.info() # info() 안에서 자동으로 print를 진행
# 기초 통계량
summary_statistics = customers.describe(include='all')
print('#'*20, '기초 통계량', '#'*20)
print(summary_statistics)2. 범주형 데이터 (성별) 분석
# 성별 데이터 분포 확인
category_columns = ['Genre']
category_data = customers[category_columns]
import matplotlib.pyplot as plt
plt.figure(figsize=(4, 4))
np.random.seed(seed)
col = (np.random.random(), np.random.random(), np.random.random())
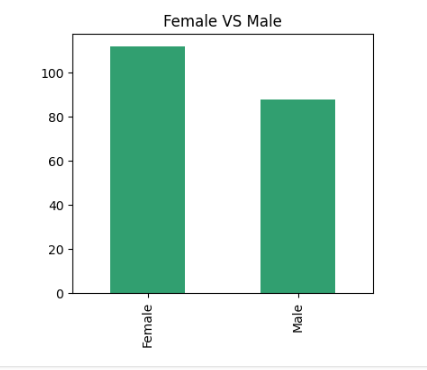
customers['Genre'].value_counts().plot(kind='bar', color=col)
plt.title('Female VS Male')
plt.tight_layout()
plt.show()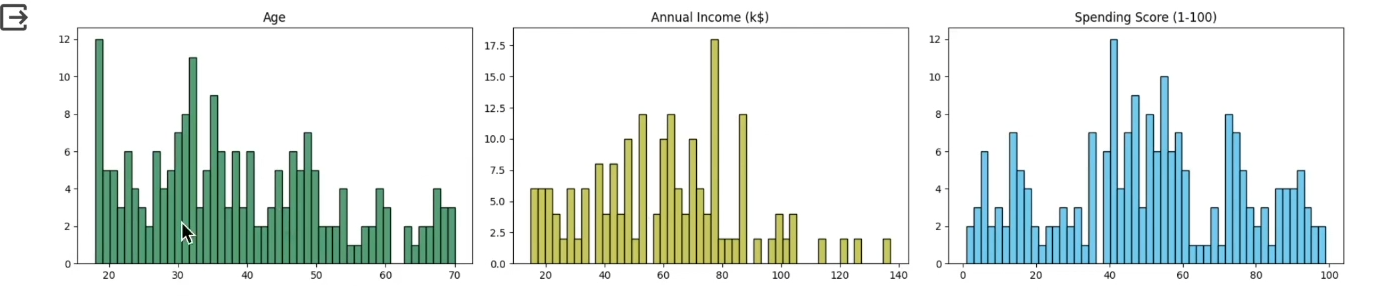
쇼핑 데이터이므로 약~간의 치우침이 있지만 큰 차이로 보이지는 않음
즉, 성별 분포는 비슷한 정도의 수준
- 치우침으로 인한 추가 전처리는 고려하지 않아도 될 것 같고
• 오히려 이런 약간의 치우침이 데이터의 특성을 잘 보여주고 있음
3. 수치형 데이터 (나이, 소득, 쇼핑 점수) 분석
# 데이터 가져와서
numeric_columns = ['Age', 'Annual Income (k$)', 'Spending Score (1-100)']
numeric_data = customers[numeric_columns]# 분포 시각화
plt.figure(figsize=(18, 4))
np.random.seed(seed)
for idx, numeric in enumerate(numeric_columns) :
col = (np.random.random(), np.random.random(), np.random.random())
plt.subplot(1, 3, idx+1)
plt.hist(numeric_data[numeric], bins=50, color=col, edgecolor='black')
plt.title(numeric)
plt.tight_layout()
plt.tight_layout()
plt.show()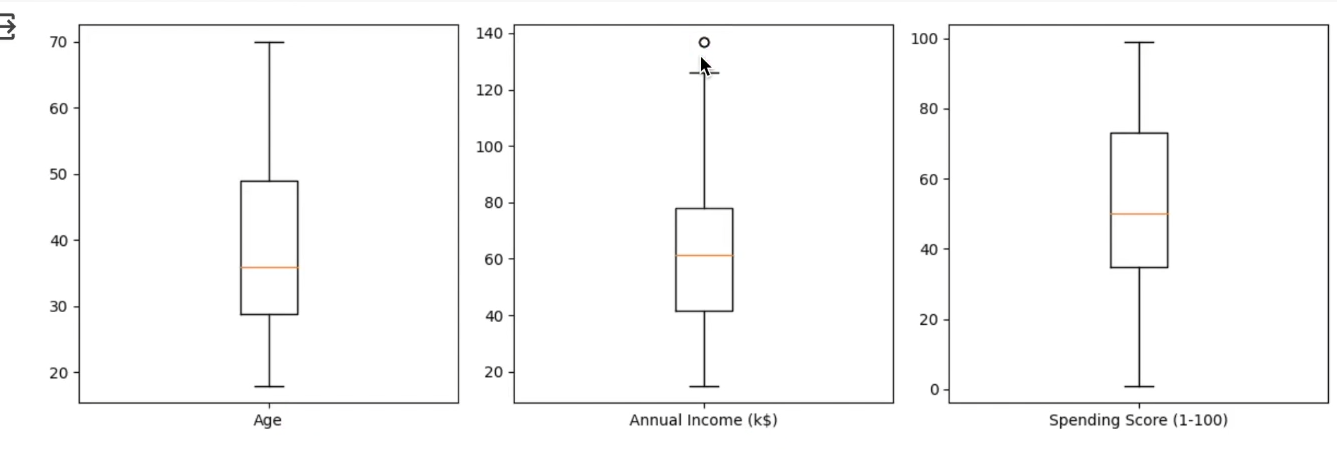
- 나이같은 경우 보통 자연적인 것이기 때문에 정규분포를 따르는 경우가 많다.
- 연간 소득 같은 경우 극단적으로 많이 버는 사람들의 경우 전처리를 해줘야 되지만 해당 자료는 따로 전처리를 안해줘도 될 듯.
- 쇼핑 점수의 경우도 정규 분포의 모습!
이제 실제로 아웃라이어를 확인해보자
# 아웃라이어 확인
plt.figure(figsize=(12, 4))
np.random.seed(seed)
for idx, numeric in enumerate(numeric_columns) :
plt.subplot(1, 3, idx+1)
plt.boxplot(numeric_data[numeric].dropna(), labels=[numeric])
plt.tight_layout()
plt.show()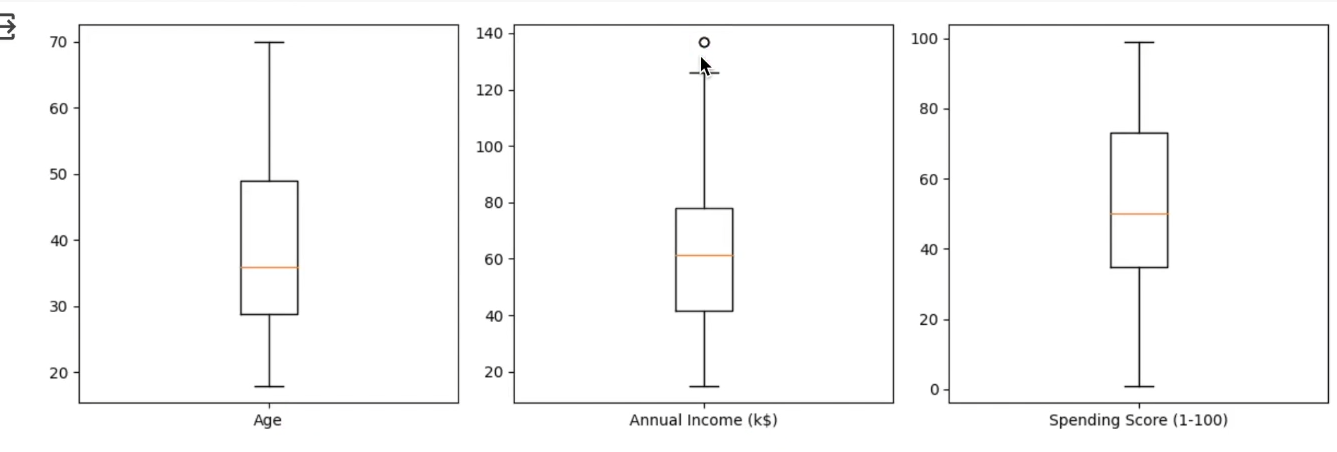
연간 소득 부분에서 하나의 데이터가 아웃라이어로 나왔지만 이는 무시해도 될 수준!
4. 상관관계 메트릭스
나이, 소득, 쇼핑 점수 각 컬럼들의 상관계수를 보
# 상관관계 메트릭스
correlation_matrix = numeric_data.corr()
# 상관관계 메트릭스 시각화
plt.figure(figsize=(4, 4))
plt.matshow(correlation_matrix, fignum=1)
plt.colorbar()
plt.xticks(range(len(correlation_matrix.columns)), correlation_matrix.columns, rotation=90)
plt.yticks(range(len(correlation_matrix.columns)), correlation_matrix.columns)
for (i, j), val in np.ndenumerate(correlation_matrix):
plt.text(j, i, '{:0.2f}'.format(val), ha='center', va='center', color='black')
plt.show()
5. 데이터 전처리
결측치 제거
결측치는 없음.
카테고리형 변수 인코딩
성별을 1, 0으로 변경
# 성별을 이진 변수로 변환
encoding_map = {'Female': 1, 'Male': 0}
categori_data_encode = pd.DataFrame(customers['Genre'].replace(encoding_map))
categori_data_encode.columns = ['Gender']
categori_data_encode수치형 데이터 스케일링
수치형 데이터의 크기를 동일한 형태로 스케일링
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# 수치형 데이터 스케일링
numeric_data = customers[numeric_columns]
numeric_data_scaled = scaler.fit_transform(numeric_data)
numeric_data_scaled = pd.DataFrame(numeric_data_scaled)
numeric_data_scaled.columns = numeric_columns
numeric_data_scaled
이후 해당 데이터를 원래 데이터에 합쳐준다.
customers_combined = pd.concat([numeric_data_scaled,
categori_data_encode],
axis=1)
customers_combined
군집화 진행 및 결과 확인
이제 실제로 군집화를 진행해 보자.
1. 최적 K 값 찾기
K클러스터 사용 전 일단 최적의 K값을 찾아야 된다.
이를 엘보우 메소드 SSE, 실루엣 방식으로 찾을 것이다.
K값을 통해 나오는 값을 시각화해보았다.
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
inertia, silhouette = [], []
K_range = range(2, 11)
for k in K_range:
kmeans = KMeans(n_clusters=k, init='k-means++', n_init=10, random_state=0)
kmeans.fit(customers_combined)
inertia.append(kmeans.inertia_)
y_kmeans_silhouette = kmeans.predict(customers_combined)
silhouette.append(silhouette_score(customers_combined, y_kmeans_silhouette))plt.figure(figsize=(8, 10))
plt.subplot(2, 1, 1)
plt.plot(K_range, inertia, label='SSE', marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('Inertia')
plt.title('Elbow Method - SSE')
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(K_range, silhouette, label='Silhouette', marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('Silhouette')
plt.title('Elbow Method - Silhouette')
plt.legend()
plt.show()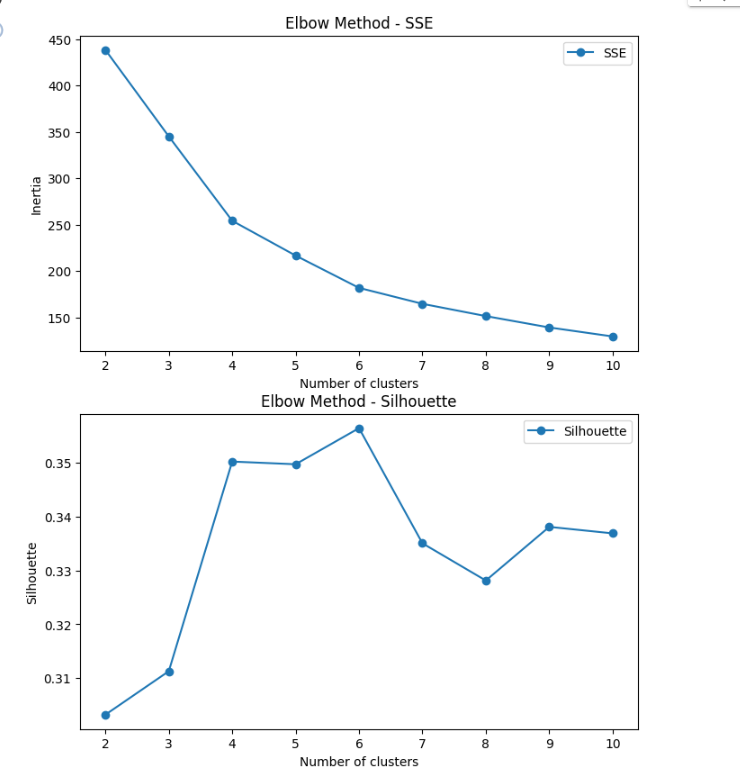
- SSE 에서는 점진적으로 값의 변화가 있다.
- K=4 혹은 K=6에서 감소율 변화가 보임
- 실루엣에서는 좀 뚱땅거리는 변화가 있다.(이게 정상)
- K=6에서 최고 값을 갖고있음.
최적 K=6으로 선택!
실루엣 계수의 변동이 있는 것은 매우 일반적인 현상
• 데이터 구조의 복잡성
• 잡음과 이상치
• 균일하지 않은 밀도 & 데이터 간 거리
• 실루엣 계수 간 차이가 크지 않다면 작은 K를 기준으로 하는게 좋은 선택
2. 학습진행
이제 K=6으로 학습을 진행해 보자
- 학습!
kmeans = KMeans(n_clusters=6,
init='k-means++',
n_init=10,
random_state=0)
kmeans.fit(customers_combined)- 결과!
y_pred = kmeans.predict(customers_combined)
silhouette_avg = silhouette_score(customers_combined, y_pred)
print("SSE Value : {:.2f}".format(kmeans.inertia_))
print("Silhouette Score: {:.2f}".format(silhouette_avg))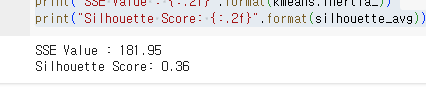
실루엣은 양수임으로 나쁘지 않은 결과이다.
하지만 SSE의 경우 181이 나왔는데 이게 좋은지 나쁜지 모르겠다.
즉! 군집화가 잘되었는지 확인하기 위해서는 수치가 아닌 실제로 그려서 판단하는 것이 좋다.
3. 결과 해석을 위한 시각화
여기서 2차원의 각 컬럼에는 어떤 계산 결과가 들어간다.
어떤 계산 결과란.. 실제 데이터 내부에서 자동으로 나오는 것으로 알 수 없다.
# 우리가 사용한 4차원 데이터를 시각화하기 위해 2차원 데이터로 변환 (t-SNE 알고리즘 활용)
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, random_state=seed)
customers_tsne = tsne.fit_transform(customers_combined)2차원에서 나온 두개의 데이터 컬럼명을 ['TSNE1', 'TSNE2']로 줘서 데이터 프레임 생성.
# 2차원으로 변화된 데이터에 feature 이름을 넣어주고
# K-means가 예측한 각 데이터의 클러스터링 인덱스를 제공
customers_tsne_df = pd.DataFrame(data=customers_tsne, columns=['TSNE1', 'TSNE2'])
customers_tsne_df['Cluster'] = y_pred
customers_tsne_df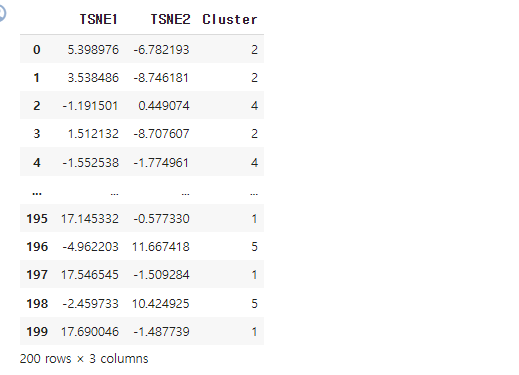
이후 이를 시각화 한다면?
# 시각화
np.random.seed(seed)
plt.figure(figsize=(10, 8))
for idx in range(kmeans.n_clusters):
_color = (np.random.random(), np.random.random(), np.random.random())
cluster_data = customers_tsne_df[customers_tsne_df['Cluster'] == idx]
plt.scatter(cluster_data['TSNE1'],
cluster_data['TSNE2'],
color=_color,
label=f'Cluster {idx+1}',
marker='o')
plt.title('Customer Segments - t-SNE 2D')
plt.legend()
plt.show()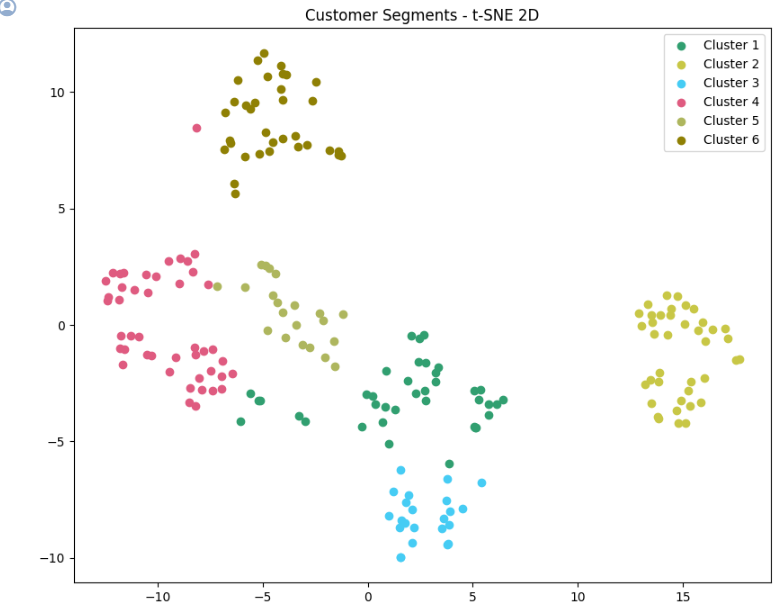
K=6으로 잘 나눠진 모습을 볼 수 있다.
좀 튀어나간 부분은 고차원 부분에서는 군집화되었다고 볼 수 있다.
와~ 군집화 끝! 에서 끝나면 안된다.
이 군집화를 통해 새로운 인사이트를 찾아내야 된다!!!!!!!!
아래 데이터 프레임을 기준으로 어떤 인사이트를 도출해 낼 수 있을지 분석해보자
클러스터별 의미 찾기
군집화레벨 데이터가 있는 클러스터컬럼을 추가해준다.
# 원래 데이터에서 재건하기
customers_combined['Cluster'] = kmeans.labels_
# 수치형 데이터 스케일링 작업을 역으로 수행하기
original_numeric_data = pd.DataFrame(scaler.inverse_transform(customers_combined[numeric_columns]))
original_numeric_data.columns = numeric_columns
# 범주형 데이터 역 인코딩 (필요시)
# 수치형으로 되어있던 데이터를 다시 범주형으로 바꾸면 특성 파악이 눈에 안들어올 수 있음!
reverse_encoding_map = {v: k for k, v in encoding_map.items()}
original_category_data = pd.DataFrame(customers_combined['Gender'].replace(reverse_encoding_map))
original_category_data.columns = category_columns
# pandas로 원래 데이터 다시 만들기
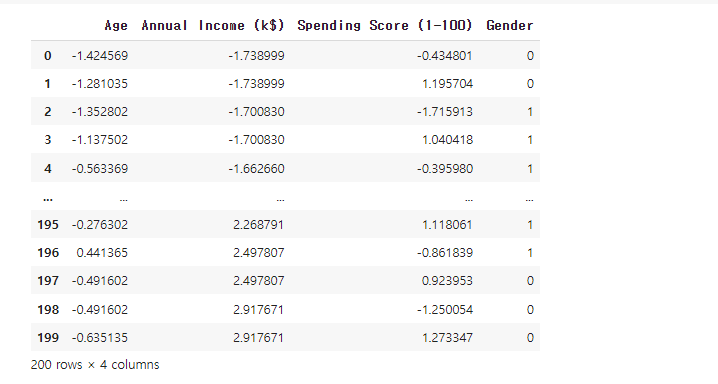
labeled_origin_date = pd.concat([customers_combined['Cluster'],
original_numeric_data,
customers_combined['Gender']],
# original_category_data], # 범주형 데이터 필요시 사용
axis=1)
labeled_origin_date
이제 각 군집에 대한 통계를 확인해보자
# 각 군집에 대한 기술통계 계산
cluster_description = labeled_origin_date.groupby('Cluster').describe().transpose()
# 군집별 평균값
cluster_means = labeled_origin_date.groupby('Cluster').mean().transpose()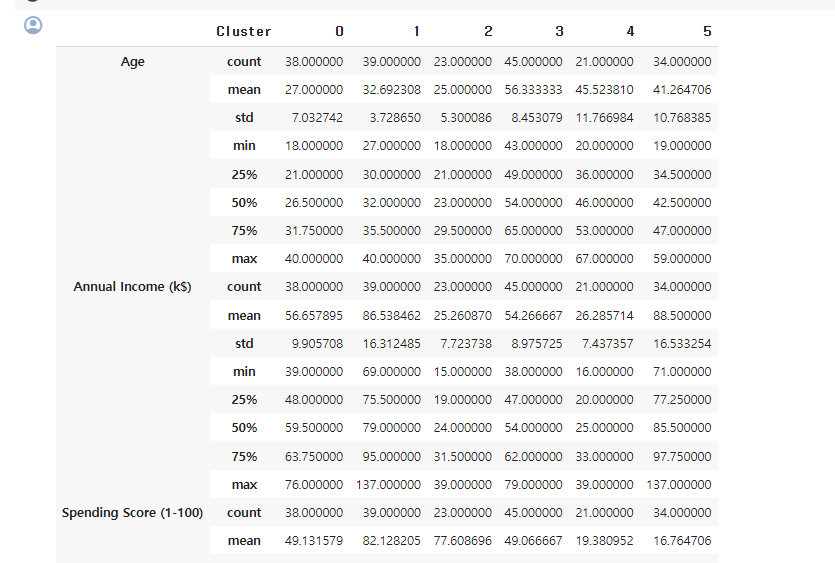
각 클러스터별로 나이, 수익 등등 을 확인해보면서 어떤 기준으로 군집화가 되었는지 확인해볼 수 있다.
일반적으로는 만들어진 클러스터가 어떤 의미가 있는지 도메인 지식을 이용해 추측해야 함
원래 데이터의 형태로 전처리의 역과정을 거쳐 데이터의 재건한 뒤
각 클러스터에 포함된 데이터의 의미를 확인해야 함
• 이때 정해진 방법이 있는 건 아니다.
• 간단하게 기본 정보 혹은 기술 통계를 보거나
• 상관관계 분석, 다른 머신 러닝 모델 생성 등의 과정이 필요하다.
