데브코스_데이터분석-머신러닝 기초[10주차]
1.[46일차]머신러닝 기초 개념
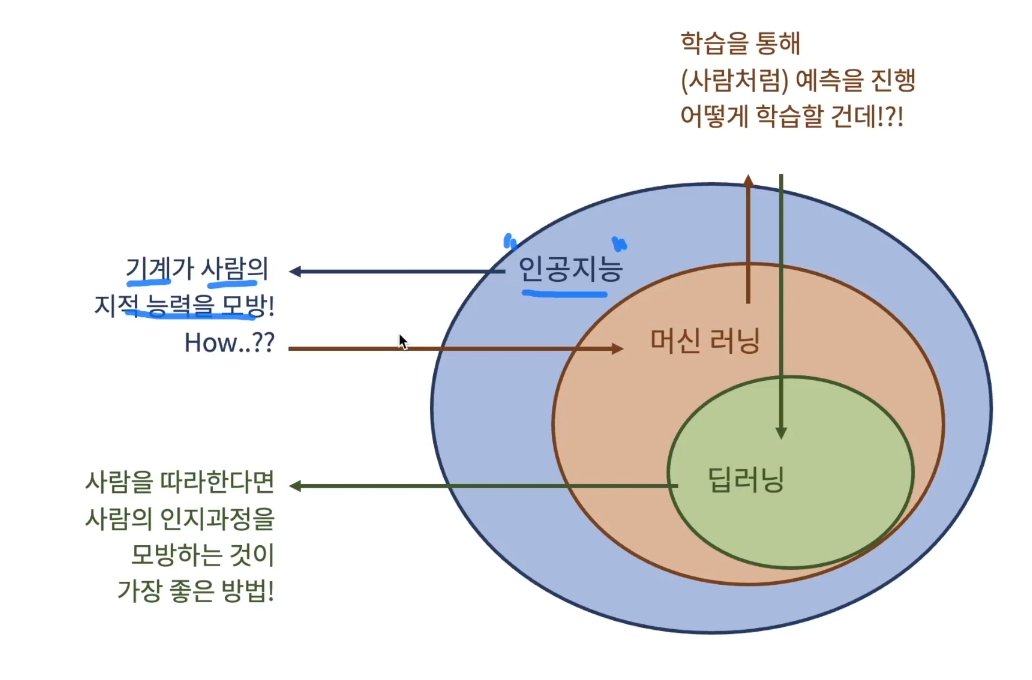
데이터에서 지식을 추출하는 작업즉, 머신 스스로가 데이터를 바탕으로 그 안에 있는 특징과 패턴을 찾아냄패턴을 찾아내는 일 : 학습특징과 패턴을 바탕으로 새로운 데이터에 대한 추론을 진행과거 머신러닝 정의“머신 러닝은 명시적인 프로그래밍(x가 들어오면 y를 출력하게 명시
2.[46일차]머신러닝 종류

메타 데이터란 주어진 기본 데이터에 추가적으로 제공하는 정보를 의미데이터의 출처, 형식, 위치 등 데이터 간의 관계와 구조를 파악하거나,데이터의 속성, 특성, 분류 등 데이터의 내용을 설명레이블이란 특정 문제에 해당하는 데이터의 설명 혹은 답변을 의미분류를 하는 문제라
3.[46일차]머신러닝에 필요한 선형대수 1
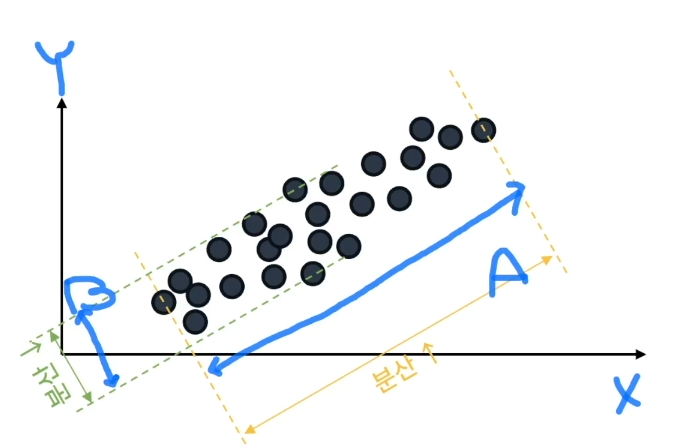
수 들이 모여있는 개념과 관련된 식을 연구하는 수학의 한 분야수가 모여있다는 것은 벡터 혹은 행렬이라고 함수를 다루는 많은 학문(데이터, 공학, 과학적 분석 등)에서 수의 연산을 빠르고 효과적으로 하기 위해 사용하는 도구!수의 집합을 기하학적인 형상으로 적용하여 표현시
4.[46일차]머신러닝에 필요한 선형대수 2
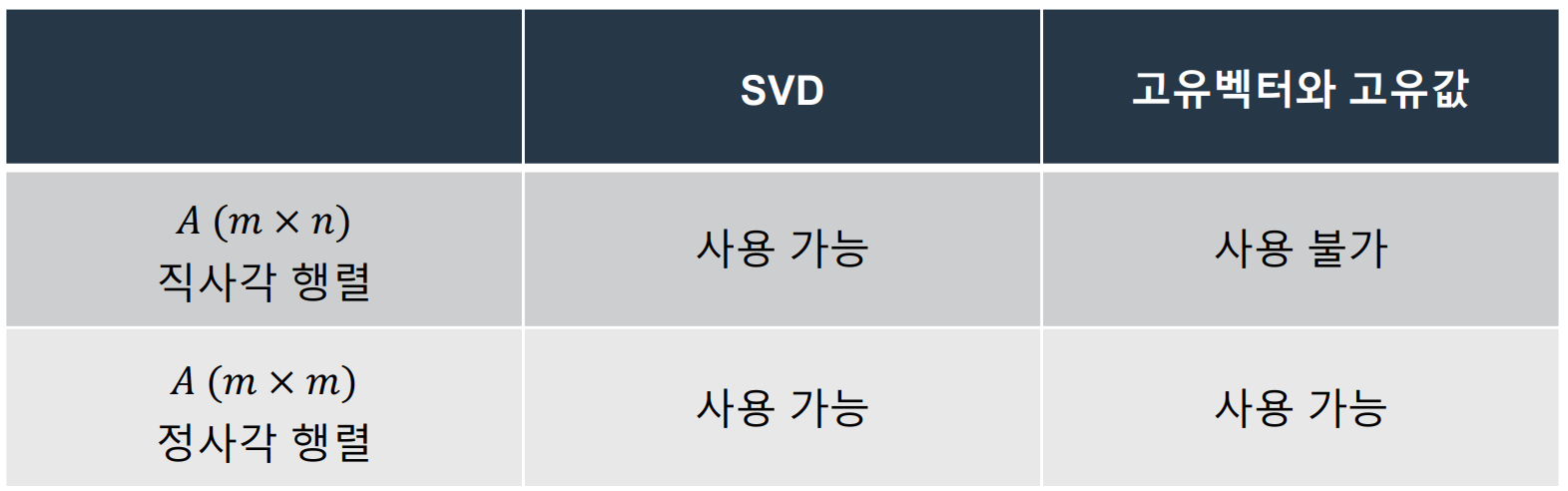
특이값 분해란?중학교 수학에서 배운 소인수 분해를 생각해 보자.30을 소인수분해한다면? 30 = 235로 진행된다.즉, 복잡한 수(30)를 그 수를 구성하는 기본적인 블록(소수 2,3,5)으로 분해.행렬에도 이와 비슷한 과정이 있다.복잡한 행렬 A(m\*n)을 더 간단
5.[46일차]머신러닝에 필요한 확률 이론
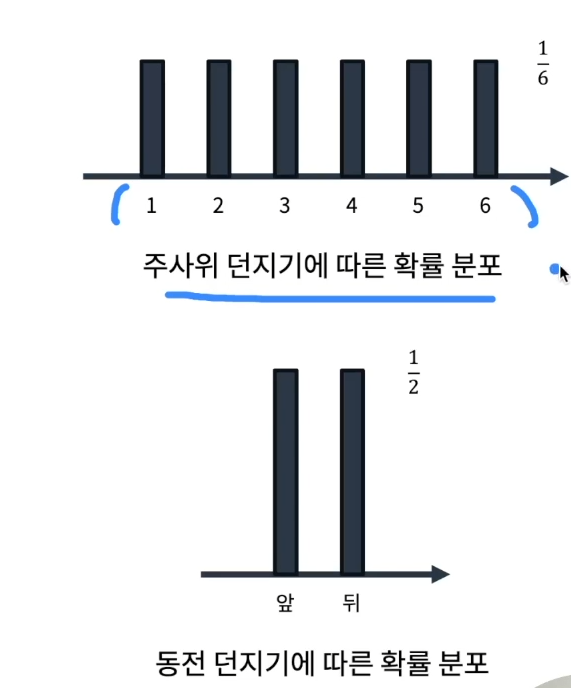
특정한 사건이 일어날 가능성을 수치로 표현0~1 사이의 값을 갖는다.일반적으로 확률(Probability)의 P를 활용해 확률을 표시• 또한, 어떠한 사건인지 사건을 알려주는 확률 변수(probability variable) x를 활용P(x) : 확률 변수 x가 특정
6.[47일차]지도학습 패키지 소개
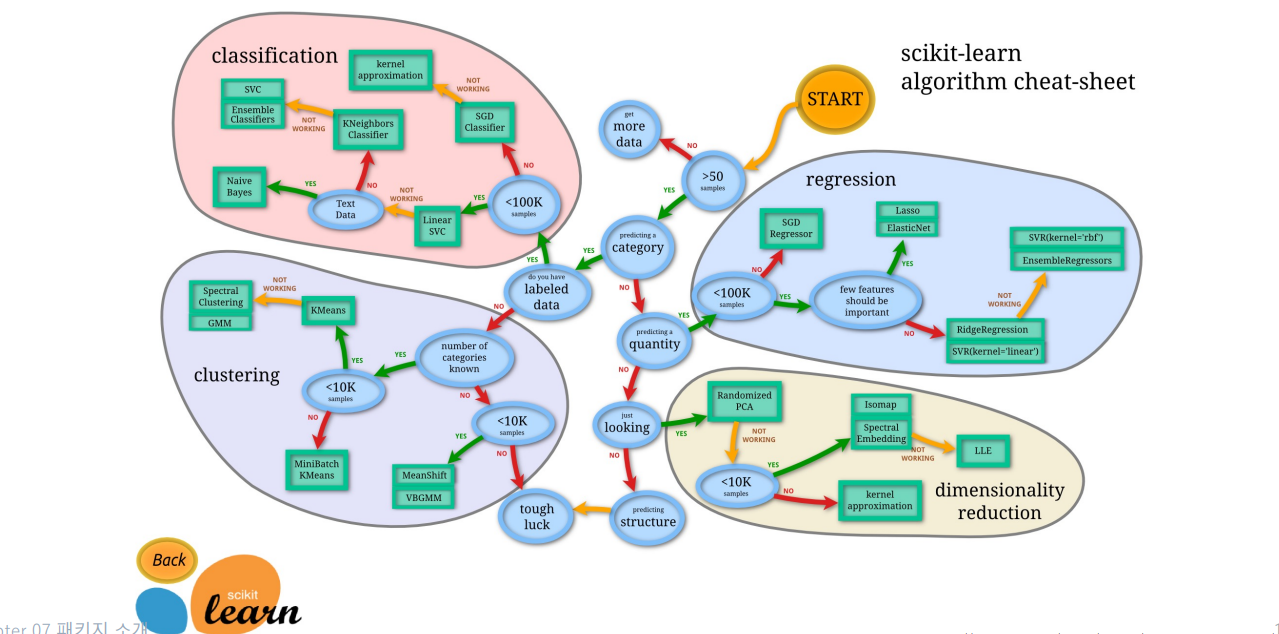
“사이킷런”은 다양한 머신ㅁ러닝 알고리즘이 구현되어 있는 오픈 소스 패키지이다.그렇기 때문에 내부 작동 과정을 하나하나 확인할 수 있다.데이터 처리, 파이프라인, 여러 학습 알고리즘, 전/후처리 등 다양한 기능을 제공.실제 산업 현장이나 학계에서도 널리 사용됨또한, 타
7.[47일차]지도학습의 개념과 대표 알고리즘

정답 레이블 정보를 활용해 알고리즘을 학습하는 학습 방법론• 이 방법으로 학습되는 알고리즘은데이터와 정답인 레이블 사이의 관계를 파악하는 목적을 갖고 있음특징 및 장점정답이 존재하므로 모델이 풀어야하는 문제가 비교적 쉽고 잘 학습 됨또한, 명확한 평가 수치가 존재하며
8.[47일차]선형 회귀와 선형 분류_선형의미

과자(가격 1,500원)와 우유(1,200원)를 사기위해 마트에서 장을 본다고 가정 해보자• 전체 구매 비용(TotalCost)은 아래와 같은 관계를 만족TotalCost = num(snack)1500 + num(milk)1200• 조건 물건 가격 할인과 서로 다른 물
9.[47일차]선형 회귀와 선형 분류_정규방정식
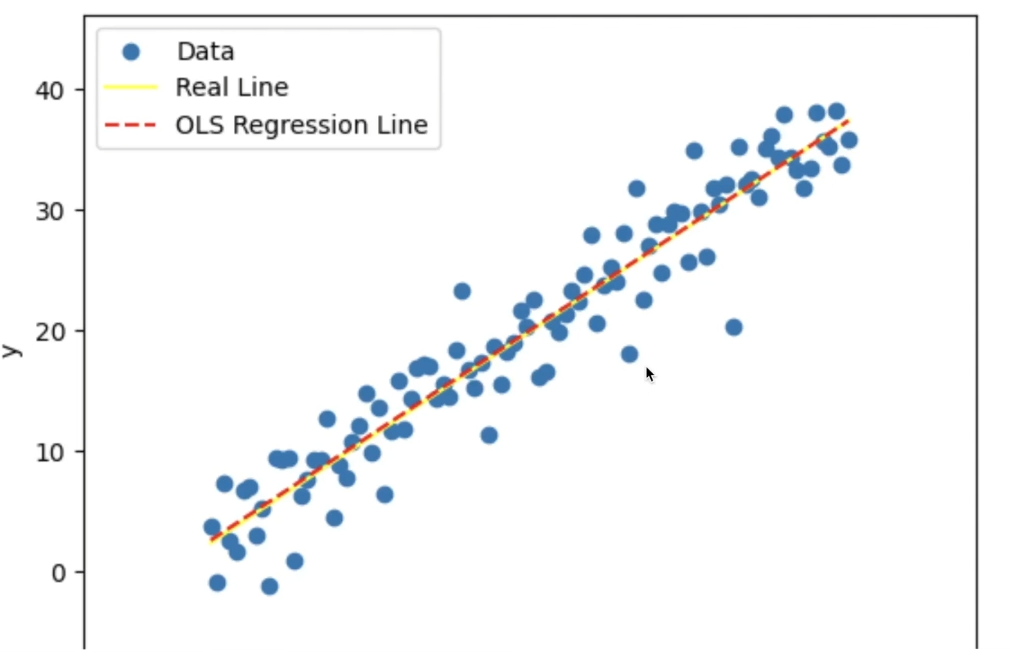
선형 회귀 모델을 사용한다는 것은입력 데이터 특징 사이의 독립성을 가정하고데이터 특징에 대한 선형 결합으로 회귀 문제를 풀겠다는 의미출력 결과(y_hat)는 예측값(실수)에 해당w0은 절편(혹은 편향)에 해당함• 목표값의 평균이 0에 맞춰 있다면, 절편을 추가하지 않을
10.[47일차]선형 회귀와 선형 분류_확률적 경사 하강법 (SGD)
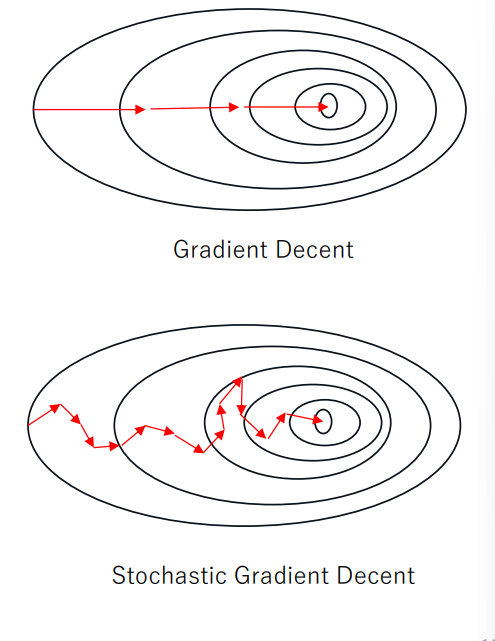
비용 함수를 최소화하기 위해 반복해서 파라미터를 조정해가는 방법임의로 잡은 초기 파라미터 값을 기준으로비용 함수의 기울기(Gradient)를 계산하여기울기가 줄어드는 방향으로 파라미터를 수정 이동반복 수행으로 기울기가 0에 가까워지면(최적값에 도달하면) Stop!주의
11.[47일차]선형 회귀와 선형 분류_다중공선성과 규제
앞에 글에서 선형 모델을 깨뜨리는 다중공선성 문제를 언급했었다.다중 공선성이란 무엇일까?입력 데이터가 갖고 있는 특징값들 사이에 상관 관계가 존재할 때 발생하는 문제 상황이 상황에서는 머신 러닝 모델이 작은 데이터 변화에도 민감하게 반응즉, 안정성과 해석력을 저하시킬
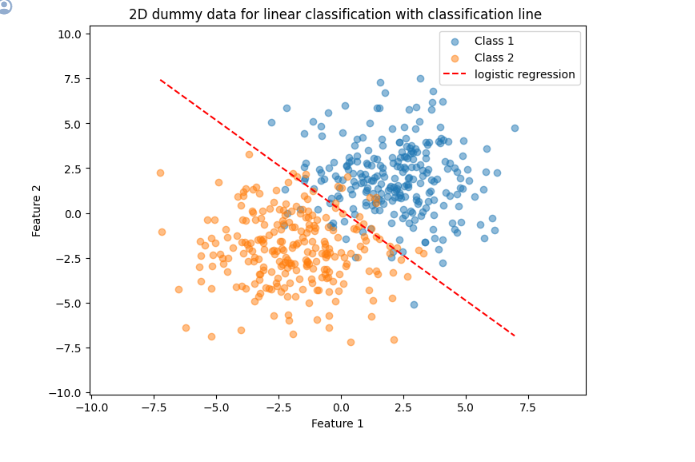
12.[47일차]선형 회귀와 선형 분류_선형분류

이진 분류 문제를 해결하기 위한 기본 알고리즘 중 하나로입력 데이터가 후보 클래스 중 각각의 클래스일 확률을 예측하는 모델확률이 갖는 값의 범위가 0~1의 실수값이므로그 확률을 직접적으로 예측(→ 확률 추정!)하는 방식으로 문제를 해결즉, 분류 문제를 풀지만 회귀 방식
13.[47일차]선형 회귀 모델을 이용한 실습_1
실습에 사용할 데이터 셋은 ‘의료비 개인 데이터셋’이다.데이터를 받으면 항상 문제부터 정의해야 된다!풀어야 되는 문제주어진 건강 및 인구통계학적 정보를 바탕으로 개인의 연간 의료 보험료를 예측머신 러닝 모델의 입, 출력 정의• 입력 : 앞선 독립 변수들• 출력 : 개인
14.[47일차]선형 회귀 모델을 이용한 실습_2

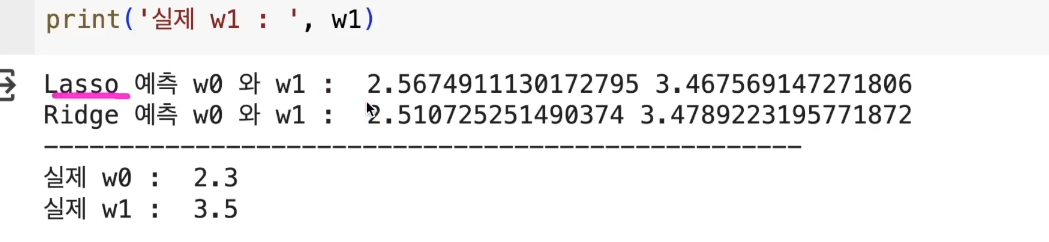
이제 ai 모델 구축 및 결과를 확인해 보자w0 값을 위해 bias를 추가해줌• 이전에도 결과를 봤지만 내장 함수를 이용하면• 자동으로 추가해서 결과를 보여줌• LinearRegression() 객체를 생성 후 학습 진행총 8개의 범주를 가지고 학습.MSE 값을 이용해
15.[47일차]선형 분류 모델을 이용한 실습 1

비행 경험 만족도 데이터풀어야 하는 문제• 주어진 탑승객의 개인 및 여행 경험 정보를 바탕으로 전반적인 비행의 만족도를 예측전체 데이터셋 크기• 총 129,880개의 개별 데이터• 총 23개 특성데이터 타입수치형 (Numerical)서수형 (Ordinal)순서나 등급을
16.[47일차]선형 분류 모델을 이용한 실습 2

이제 모델을 학습 해보자.학습에 사용될 데이터와 평가에 사용될 데이터를 분리해준다.16개의 w들이 나온다.accuracy_score 전체 갯수 중에 맞춘 갯수를 출력해준다.이 방법 외에도 다른 방법이 있다.바로 Confusion Matrix !좌상 → 우하 방향 대각선
17.[48일차]SVM(Support Vector Machine) - 선형 이론

삼각형과 원을 나누는 선아래 두 경우 중 원과 삼각형을 더 잘 나눈 경우는 어디일까.잘 나눈다는 정의 필요• 정확히 나누었는가? (빨강, 파랑)• 일반화가 잘 되었는가? (파랑)왜 파란색이 더 일반화가 좋다고 했을까?파란 분류 선의 경우• 원과 삼각형을 잘 나누고 있을
18.[48일차]SVM(Support Vector Machine) - 선형 실습
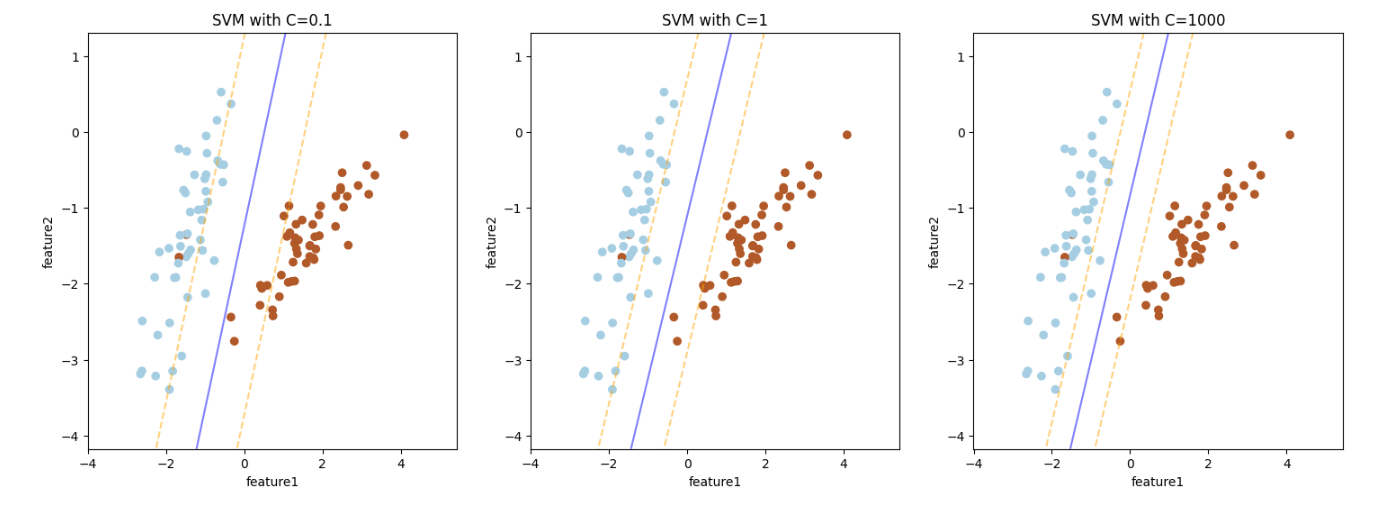
먼저 데이터를 만들어보자make_classification : 더미데이터를 생성할 수 있다.그럼 이런식의 데이터가 나온다!SVC 메소드를 이용하여 하드 마진을 사용할 수 있다.kernel= 선형 모델을 사용할 것이기 때문에 linear 입력 C= : 슬랙변수이다.파란색
19.[48일차]SVM(Support Vector Machine) - 비선형
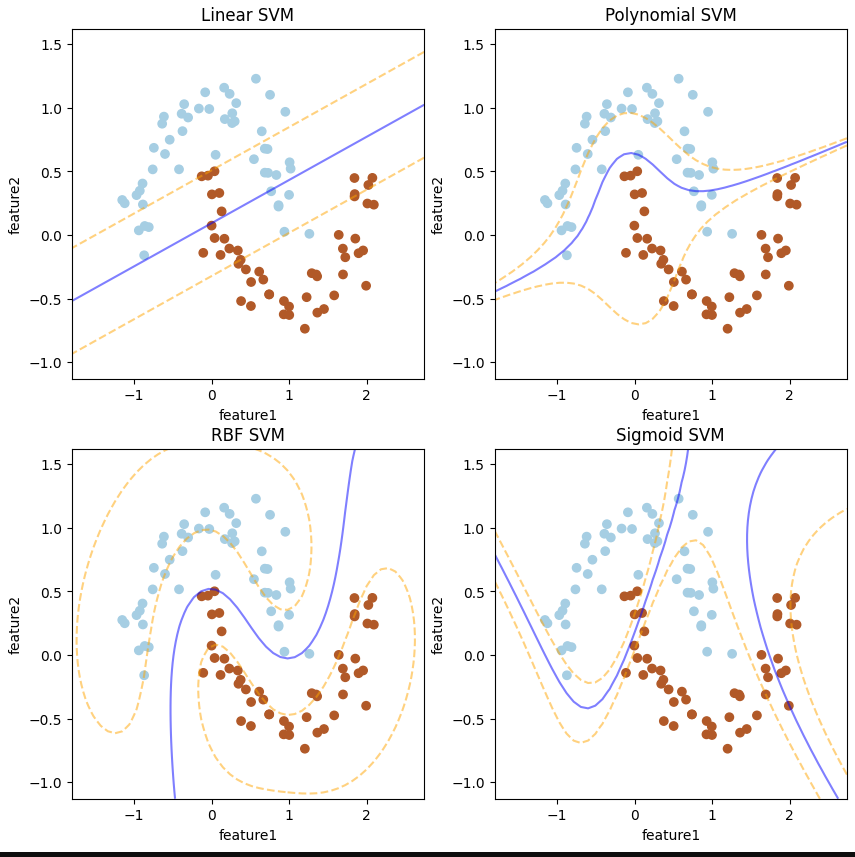
데이터의 복잡성으로 인해 선형 결정 경계로 데이터를 분류할 수 없는 경우가 있음특히 데이터가 휘어진 형태로 분포한다면 선형 SVM 으로는 분류할 수 없음비선형 SVM은 이러한 데이터에 대해 효과적으로 작동선형적으로 분리할 수 없는 데이터를 고차원으로 변형하면•고차원의
20.[48일차]SVR (Support Vector Regresson)
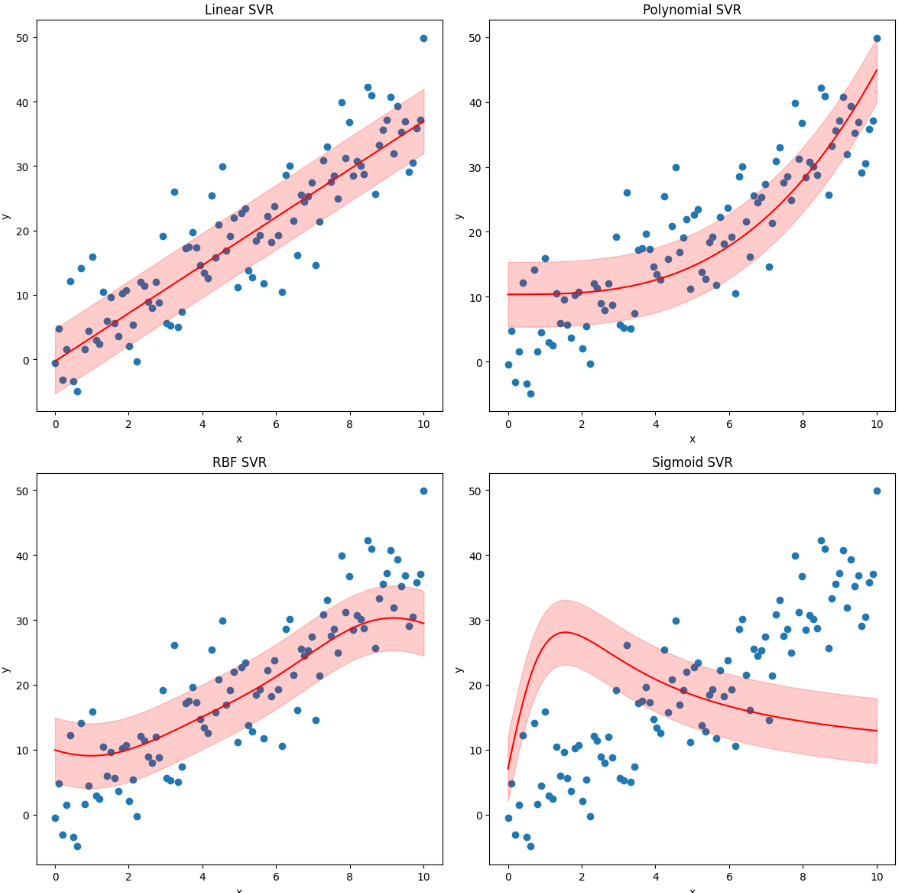
회귀 문제로 확장한 SVM 방법을 SVR (Support Vector Regression)이라고 함주어진 데이터에서 가능한 많은 데이터 포인트(초록색들)를 포함하는 마진 구역을 설정• 이 마진 구역은 사용자가 선언한 허용 오차내부의 구역그 마진 구역 안에서 회귀선(혹은
21.[48일차]Decision Tree - 용어
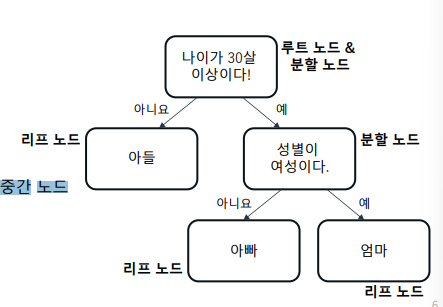
3인 가족 나누는 예로 한번 알아보자어떤 기준을 사용해 가족 구성원을 나눠봐야 되나?구성원을 나누기 위한 조건은 다양함• 어떤 조건을 선택하는지에 따라 빠르게 나눌 수 있고, 더디게 나눌 수 있음 \- 여기서 데이터를 잘 나눌 수 있도록 하는 것이 Decision
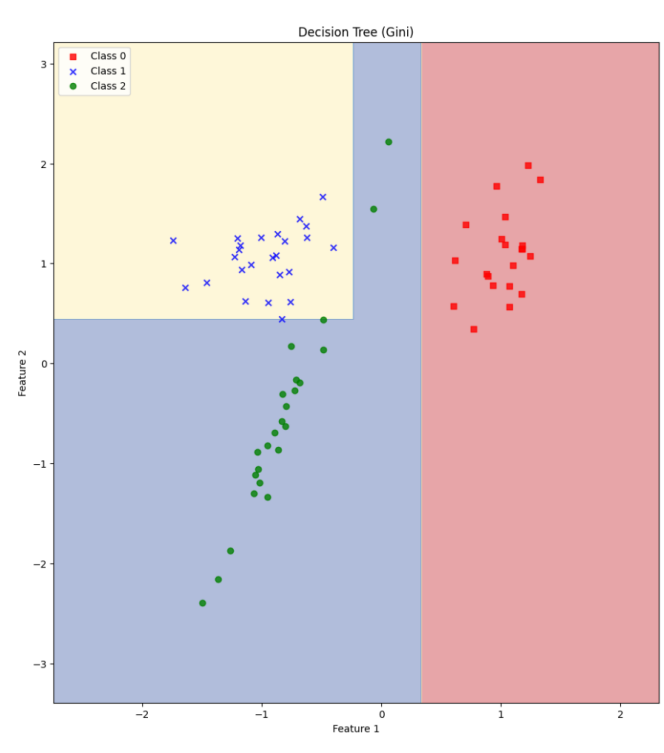
22.[48일차]Decision Tree - 분류
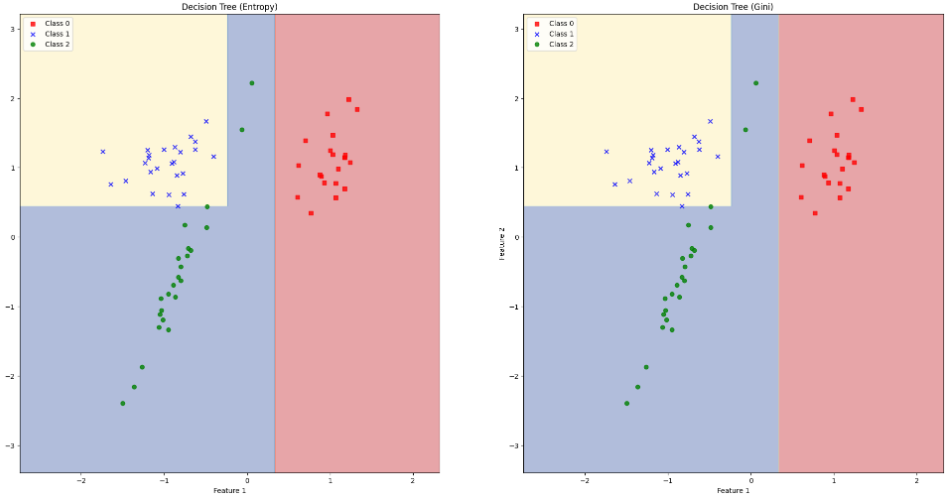
데이터를 분할하는 기준을 결정하는데 사용되는 방법론트리의 각 단계에서 최적의 분할을 찾기 위해 사용되며이를 통해 트리의 깊이와 복잡성을 관리할 수 있음좋은 결정 기준은 트리를 더욱 간결하고 효율적으로 만들며과적합을 방지하고 일반화 성능을 향상시킴!분류 과정에서 사용되는
23.[48일차]Decision Tree - 회귀
Decision Tree에서 회귀 문제를 푸는 주요한 방식 중 하나위와 같은 데이터가 있다고 할 때각 데이터들이 모여있는 부분에 직선을 그려주는 형식.각 노드에서 실제 정답과 예측 값 사이의 평균 제곱 오차(MSE)의 평균을 계산하고이 값을 최소화하는 노드를 찾아가는
24.[48일차]SVM과 Decision Tree 실습

47일차에 사용 했었던 비행 경험 만족도 데이터 를 사용해서 실습해 볼 예정이다.전처리 까지는 동일하게 진행하였다.복습을 할 겸 Logistic Regression 를 진행해보자예측 수행예측을 얼마나 잘했는지, 피쳐가 결과에 얼마나 영향을 끼치는지 를 볼 수 있다.이제
25.[49일차]K-means Clustering 이란?

ʻK-평균 군집화ʼ라고 부르며전체 데이터를 K개의 덩어리(클러스터)로 나누는 비지도 학습법위쪽 그림은 K=3인 경우의 클러스터링 그럼 3개로 나뉘겠쥐?• 삼각형(△)은 클러스터의 중심점을 표시• 중심점은 클러스터 안에 포함된 데이터의 평균값방법이 간단하며 효과적이고•
26.[49일차]클러스터링 기법을 활용한 실습
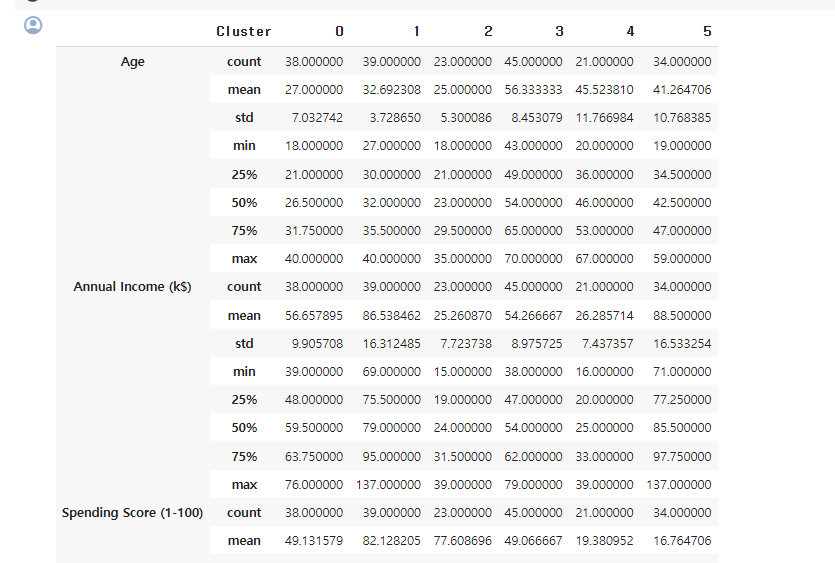
캐글데이터를 이용해 클러스터링 기법을 실습해보자.Mall Customers 데이터 200명의 쇼핑몰 고객에 대한 정보 데이터• 아래의 변수를 포함• 고객 ID• 성별• 나이• 연간 소득• 쇼핑 점수• 쇼핑 행동과 지출 성향을 기반으로 쇼핑몰에서 점수 부여고객 ID• 수
27.[49일차]이상탐지와 Isolation Forest
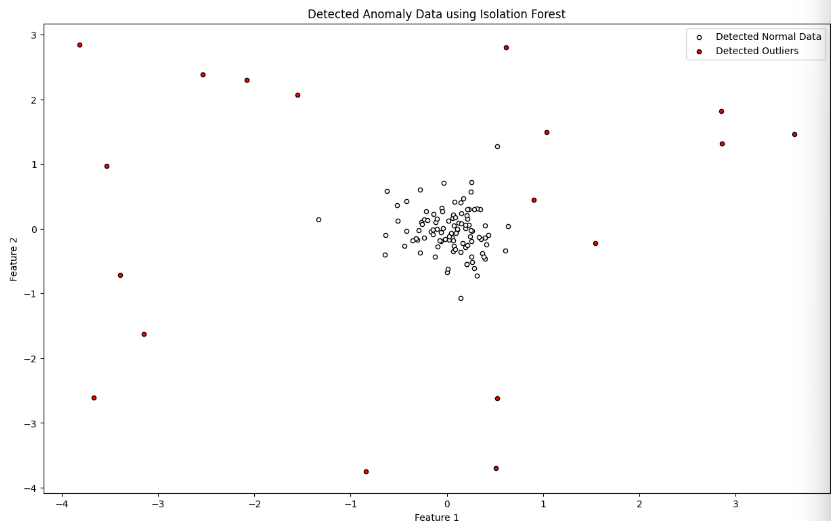
이상 탐지에는 여러가지 알고리즘이 있는데 이번시간에는 Isolation Forest 라는 알고리즘으로 진행해보겠다.데이터에서 비정상적인 패턴, 이상치, 또는 예외적인 사례를 탐지하는 과정데이터에서 일반적으로 볼 수 있는 특성에서 많이 벗어난 데이터를 식별하는 과정에서
28.[49일차]이상탐지 실습
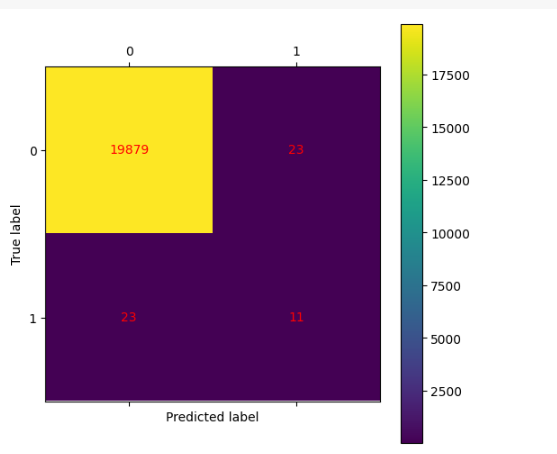
캐글의 신용카드 거래 데이터를 가지고 실습을 진행해 보자Credit Card Fraud Detection 데이터Credit Card Fraud Detection신용카드 거래에서의 사기 탐지를 위해 설계된 데이터셋• 2013년 유럽 카드 소지자들의 거래 데이터를 포함•
29.[50일차]딥러닝 개요
딥러닝이란 머신러닝의 학습 방법 중 하나!사람의 신경망을 기반으로 학습과 추론을 진행하는 학문• 사람을 모방해야 하니, 사람의 신경 구조를 모방하는 게 어찌보면 그럴듯한 접근사람의 신경 구조는 뉴런(neuron)을 기본 단위로 함• 그리고 사람의 신경계는 매 ~우 매~
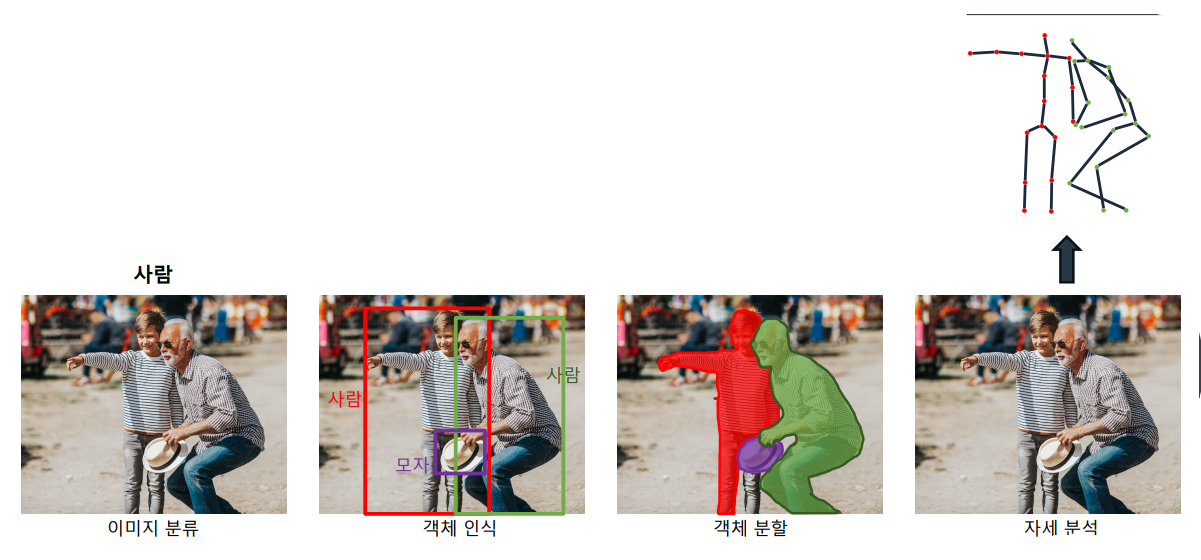
30.[50일차]이미지 처리(CNN)와 텍스트 처리(RNN)

이미지를 처리하는 딥러닝 모델은 사람의 시각 정보 처리 방법을 모방따라서 사람의 시각 정보 처리 과정을 확인과정분석 단위를 설정 후 정보를 추출주변 정보를 통합해 차츰 상위 개념을 구성목적하는 상위 개념에 도달할 때까지 반복우리가 물고기를 이해해 가는 과정예시!아래 그
31.[50일차]이미지 분류 실습
학습된 이미지 분류 모델을 활용해 이미지 분류 실습을 진행이미지 분류란,이미지의 대부분을 차지하는 객체의 종류를 예측하는 문제를 의미함입력으로 하나의 이미지를 제공하고해당 이미지의 종류(클래스)를 예측일반적으로 선택 가능한 모든 클래스에 대한 정답 점수값을 예측따라서
32.[50일차]성능 평가 - 교차 검증
ʻ검증 (validation)ʼ이라는 단어를 언제 사용했을까요? >> 검증 데이터 (validation data)검증이란,• 모델의 학습이 잘 진행되었는지(일반화 능력)를 판단하는 평가 과정• 학습이 잘 되고있는지 혹은 과적합이 진행되는지를 판단• 모델 학습의 최종 의
33.[50일차]성능 평가 - 성능 평가 메트릭
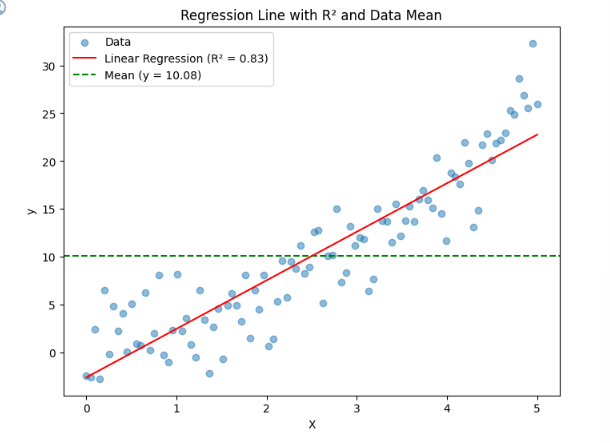
머신 러닝 모델의 성능을 객관적으로 측정하고 비교하는 과정에서 사용이를 통해 모델의 강점과 약점을 파악성능 평가에 사용되는 지표를 metric이라고 함Metric에는 다양한 종류가 있으며각각의 지표가 제공하는 정보가 다름• 목적에 맞는 올바른 metric을 선택해야 함