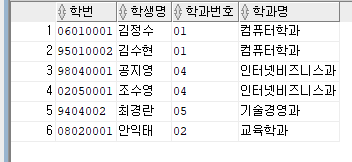
--1. 학번, 학생명(student)과 학과번호, 학과명(subject)을 출력하도록 쿼리문 작성해 주세요.
select sd_num 학번, sd_name 학생명, st.s_num 학과번호, s_name 학과명
from subject sb inner join student st
on sb.s_num = st.s_num;
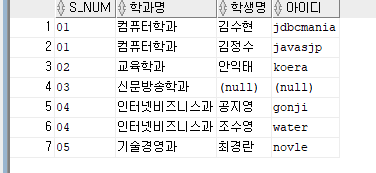
--2. 우리 학교 전체 학과명에 그 학과에 소속된 학생명, 아이디를 출력하도록 쿼리문을 작성해 주세요.
select sb.s_num, s_name 학과명, sd_name 학생명, sd_id 아이디
from subject sb left outer join student st
on sb.s_num = st.s_num
order by sb.s_num;
--3. 수강테이블(trainee)에서 수강 신청한 학생명, 과목명, 등록일(2018.12.28 형태)을
--출력하도록 쿼리문 작성해 주세요.
select sd_name 학생명, l_name 과목명, to_char(t_date, 'YYYY.MM.DD') 수강신청일
from trainee tr, student st, lesson le
where tr.sd_num = st.sd_num and tr.l_abbre = le.l_abbre;

select sd_name 학생명, l_name 과목명, to_char(t_date, 'YYYY.MM.DD') 수강신청일
from trainee tr inner join student st on tr.sd_num = st.sd_num
inner join lesson le on tr.l_abbre = le.l_abbre; --where가아니라 on(join의 조건)
아래 코드는 학과명을 추가한 위의 예제이다.
select s_name 학과명, sd_name 학생명, l_name 과목명, to_char(t_date, 'YYYY.MM.DD') 수강신청일
from subject su inner join student st on su.s_num = st.s_num
inner join trainee tr on tr.sd_num = st.sd_num
inner join lesson le on tr.l_abbre = le.l_abbre;

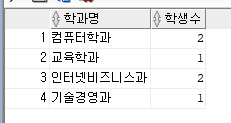
--4. 학과(subject)에 소속된 학생 수 (student)를 출력하도록 쿼리문 작성해 주세요.
select s_name 학과명,count(sd_num) 학생수
from subject sb inner join student st
on sb.s_num = st.s_num
group by s_name,sb.s_num
order by sb.s_num;
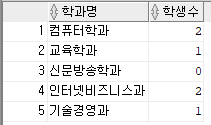
--5. 전체 학과명을 출력하고 그 학과에 소속된 학생 수를 출력하도록 쿼리문 작성
select s_name 학과명,count(sd_num) 학생수
from subject sb left outer join student st --left쓰면 left쪽 데이터를 전부가져옴 right 쓰면 오른쪽 데이터 다 가져옴
on sb.s_num = st.s_num
group by s_name,sb.s_num
order by sb.s_num;
각 기준별 소계를 요약해서 보여주는 ROLLUP 함수(자동으로 소계와 합계를 구해주는 함수)
GROUP BY 절에서 ROLLUP(expr1,expr2,...) 사용됨
-expr로 명시한 표현식을 기준으로 집계한 결과, 추가 정보 집계
-expr로 명시한 표현식 수와 순서에 따라 레벨 별로 집계
--부서별 같은 직무를 담당하는 사원의 급여의 합과 사원수
select d.department_id 부서 ,e.job_id, sum(e.salary) 급여의합 ,count(e.employee_id) 사원수
from departments d inner join employees e
on d.department_id = e.department_id
group by d.department_id,e.job_id
order by d.department_id;
--부서별 급여의 합과 사원수
select d.department_id 부서,null job_id , sum(e.salary) 급여의합, count(e.employee_id) 사원수
from departments d inner join employees e
on d.department_id = e.department_id
group by d.department_id
order by d.department_id;
--전체 사원의 급여의 합과 사원수
select null department_id,null job_id, sum(salary),count(*)
from employees
--위의 쿼리문을 집합 연산자로 표현하면 (union all 컬럼 개수 같아야함)
select department_id,job_id, count(), sum(salary)
from employees
group by department_id, job_id
UNION ALL
select department_id, null job_id, count(),sum(salary)
from employees
group by department_id
UNION ALL
select null department_id, null job_id, count(*), sum(salary)
from employees
order by department_id, job_id; --마지막에 정렬 꼭해주기
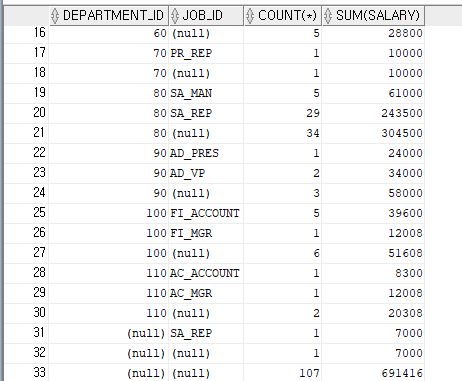
위의 쿼리문을 ROULLUP함수로 작성하면 동일한 결과를 얻을 수 있다.
-- 부서코드가 바뀔떄마다 부서별 집계가 출력되고 모든 부서가 출력되면 전체 집계정보가 출력
SELECT DEPARTMENT_ID, JOB_ID, COUNT(*), SUM(SALARY)
FROM EMPLOYEES
GROUP BY ROLLUP(DEPARTMENT_ID,JOB_ID)
ORDER BY DEPARTMENT_ID;
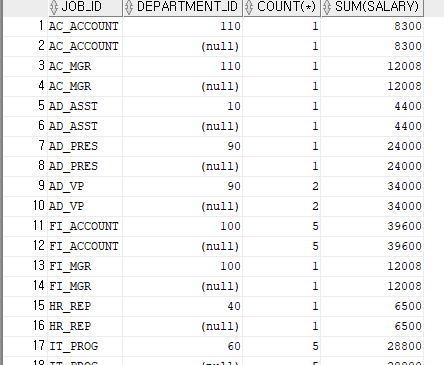
SELECT JOB_ID,DEPARTMENT_ID,COUNT(*),SUM(SALARY)
FROM EMPLOYEES
GROUP BY ROLLUP(JOB_ID, DEPARTMENT_ID)
ORDER BY JOB_ID; --직무별 집계 기준점(직무)
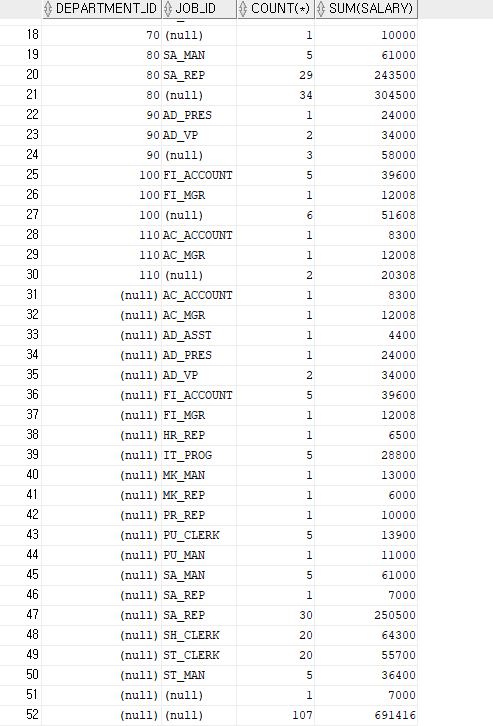
CUBE(exp1, exp2,...) -소계와 전체 합계(인자로 지정된 그룹들로 가능한 모든 조합 별로 집계한 결과 반환)까지 출력하는 함수
CUBE()는 명시한 표현식 개수에 따라 가능한 모든 조합별로 집계한 결과를 반환한다.
부서별 사원수와 급여합, 직급별 사원수와 급여합, 부서와 직급별 사원수와 급여의 합, 전체 사원수와 급여의 합을 구하고자한다.
--CUBE 사용 예제
SELECT DEPARTMENT_ID, JOB_ID,COUNT(*), SUM(SALARY)
FROM EMPLOYEES
GROUP BY CUBE(DEPARTMENT_ID, JOB_ID)
ORDER BY DEPARTMENT_ID;
--GROUPING
--ROLLUP이나 CUBE에 의한 집계 산출몰이
--인자로 전달받은 컬럼 집합의 산출물이면 0 반환 아니면 1 반환
SELECT DEPARTMENT_ID, JOB_ID, SUM(SALARY)
FROM EMPLOYEES
GROUP BY ROLLUP(DEPARTMENT_ID,JOB_ID)
ORDER BY 1;
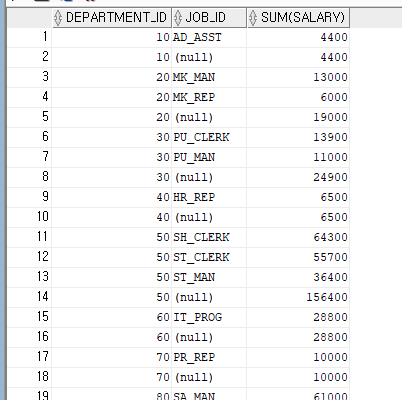
SELECT DEPARTMENT_ID, JOB_ID, SUM(SALARY),
CASE WHEN GROUPING(DEPARTMENT_ID) = 0 AND GROUPING(JOB_ID) = 1 THEN '부서별 합계'
WHEN GROUPING(DEPARTMENT_ID) = 1 AND GROUPING(JOB_ID) = 0 THEN '직급별 합계'
WHEN GROUPING(DEPARTMENT_ID) = 1 AND GROUPING(JOB_ID) = 1 THEN '총 합계'
ELSE '그룹별 합계'
END AS 구분
FROM EMPLOYEES
GROUP BY ROLLUP(DEPARTMENT_ID,JOB_ID)
ORDER BY 1;
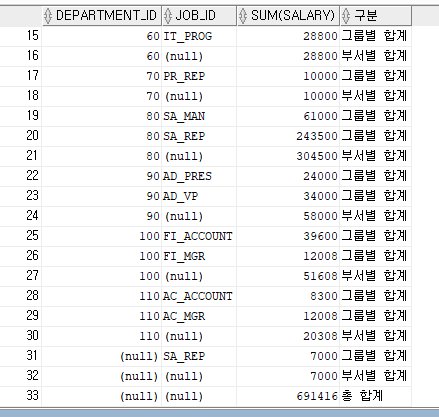
-- GROUPING SETS절
-- GROUPING SETS은 ROLLUP이나 CUBE처럼 GROUP BY 절에 명시해서 그룹 쿼리에 사용되는 절이다.
-- GROUPING SETS은 그룹 쿼리이긴 하나 UNION ALL 개념이 섞여 있기 때문이다.
SELECT DEPARTMENT_ID,JOB_ID, COUNT(*), SUM(SALARY)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID,JOB_ID
ORDER BY DEPARTMENT_ID;
SELECT DEPARTMENT_ID, JOB_ID, COUNT(*), SUM(SALARY)
FROM EMPLOYEES
GROUP BY GROUPING SETS(DEPARTMENT_ID, JOB_ID)
ORDER BY DEPARTMENT_ID;
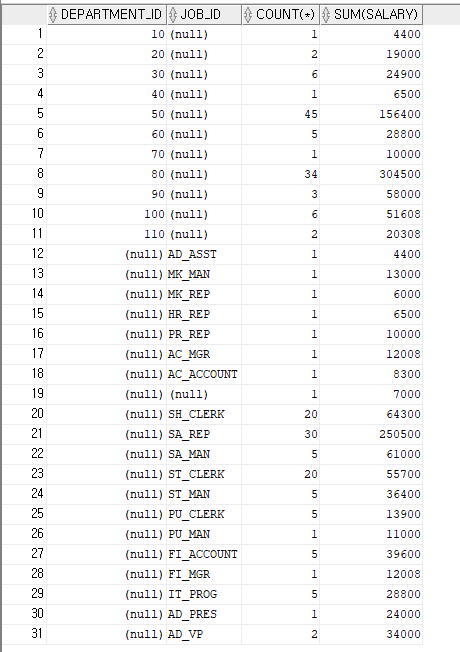
-- RANK() : 중복 순위 개수만큼 다음 순위 값을 증가 시킴
-- 형식 : RANK() OVER(ORDER BY 컬럼명 (ASC|DESC)) (AS 별칭)
-- DENSE_RANK() : 중복 순위가 존재해도 순차적으로 다음 순위 값을 표시함
-- ROW_NUMBER() : 중복값에 관계없이 SEQUENCE(순차적인 순위 값) 값을 반환
-- 사원테이블에서 80번 부서에 소속된 사원 중에서 급여를 가장 많이 받는 순으로
-- 사원번호, 사원명, 급여, 순위를 부여하여 출력해 주세요.
SELECT EMPLOYEE_ID AS 사원번호, FIRST_NAME 사원명, SALARY,
RANK() OVER(ORDER BY SALARY DESC) 급여순위
FROM EMPLOYEES
WHERE DEPARTMENT_ID=80;
SELECT EMPLOYEE_ID AS 사원번호, FIRST_NAME 사원명, SALARY,
DENSE_RANK() OVER(ORDER BY SALARY DESC) 순위
FROM EMPLOYEES
WHERE DEPARTMENT_ID=80;
SELECT EMPLOYEE_ID AS 사원번호, FIRST_NAME 사원명, SALARY,
ROW_NUMBER() OVER(ORDER BY SALARY DESC) 순위
FROM EMPLOYEES
WHERE DEPARTMENT_ID=80;
집합 연산자
데이터 집합이 대상이므로 집합연산자(union,union all, intersect, minus)를 사용할때 데이터 집합의 수는 한 개 이상을 사용할 수 있다. 즉 여러 개의 select문을 연결해 또 다른 하나의 쿼리를 만드는 역할을 하는 것이 집합연산자이다.
UNION ALL 각 쿼리의 결과 집합의 합집합. 중복된 행도 그대로 출력
UNION 각 쿼리의 결과 집합의 합집합. 중복된 행은 한 줄로 출력
INTERSECT 각 쿼리의 결과 집합은 교집합. 중복된 행은 한줄로 출력
MINUS 앞에 있는 쿼리의 결과 집합에서 뒤에 있는 쿼리의 결과 집합을 뺸 차집합이다.
중복된 행은 한줄로 출력
SELECT EMPLOYEE_ID,JOB_ID
FROM EMPLOYEES
UNION
SELECT EMPLOYEE_ID,JOB_ID
FROM JOB_HISTORY
ORDER BY 1;
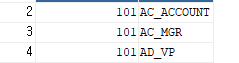
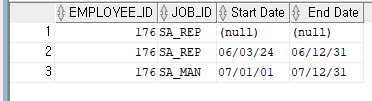
위 사진을 보면 101번 사원의 업무가 변경되었었단걸 알 수 있다.
--예제) 위 결과를 이용하여 출력된 176번 사원의 업무 이력의 변경 날짜 이력을 조회하시오. 조회할때 레코드 수 같아야함
SELECT EMPLOYEE_ID,JOB_ID, NULL AS "Start Date", NULL AS " End Date"
from EMPLOYEES
WHERE EMPLOYEE_ID = 176
UNION
SELECT EMPLOYEE_ID, JOB_ID, START_DATE, END_DATE
FROM JOB_HISTORY
WHERE EMPLOYEE_ID = 176;
--UNION
SELECT GOODS FROM EXP_GOODS_ASIA
WHERE COUNTRY='한국'
UNION
SELECT GOODS FROM EXP_GOODS_ASIA
WHERE COUNTRY ='일본';
--UNION ALL은 중복된항목도 모두 조화된다는 점이다.
SELECT GOODS FROM EXP_GOODS_ASIA
WHERE COUNTRY='한국'
UNION ALL
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY='일본';
--INTERSECT는 합집합이 아닌 교집합을 의미. 즉 데이터 집합에서 공통된 항목만을 추출
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY='한국'
INTERSECT
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY='일본';
4)MINUS는 차집합을 의미. 즉 한 데이터 집합을 기준으로 다른 데이터 집합과 공통된 항목을 제외한 결과만 추출.
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY='한국'
MINUS
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY='일본';
--집합 연산자의 제한사항
--집합 연산자와 연결되는 각 SELECT문의 SELECT 리스트의 개수와 데이터 타입은 일치해야 한다.
--ORA-01789: 질의 블록은 부정확한 수의 결과 열을 가지고 있습니다
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY='한국'
UNION
SELECT SEQ, GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY='일본';
--ORA-01790: 대응하는 식과 같은 데이터 유형이어야 합니다
SELECT SEQ
FROM EXP_GOODS_ASIA
WHERE COUNTRY='한국'
UNION
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY='일본';
--집합 연산자로 SELECT문을 연결할 때 ORDER BY 절은 맨 마지막 문장에서만 사용할 수 있다.
--ORA-00933: SQL 명령어가 올바르게 종료되지 않았습니다
/SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY='한국'
ORDER BY GOODS
UNION
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY='일본';
/
-- 위의 쿼리문을 수정하면
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY='한국'
UNION
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY='일본'
ORDER BY GOODS;
--서브쿼리 작성 전 코드.
--조인을 사용하지 않는다는 가정하에 Susan 사원이 소속된 부서명을 출력
--[순서]
--1. Susan 사원이 부속된 부서번호 확인 => 사원테이블(EMPLOYEES)
--2. 부서번호를 가지고 부서명 확인 => 부서테이블(DEPARTMENTS)
--Susan 사원이 소속된 부서명 구하기
SELECT DEPARTMENT_ID
FROM EMPLOYEES
WHERE FIRST_NAME='Susan';
SELECT DEPARTMENT_NAME
FROM DEPARTMENTS
WHERE DEPARTMENT_ID=40;
두 개 이상의 테이블의 정보가 필요할 경우 서브쿼리를 사용
단일 행 Sub Query, 다중 행 Sub Query에 대해서 학습
서브쿼리문을 이용해서 테이블 생성
서브 쿼리문을 이용해서 테이블에 데이터를 추가, 수정, 삭제
1)서브 쿼리의 기본 개념
서브 쿼리는 하나의 select 문장의 절 안에 포함된 또 하나의 select 문장이다. 그렇기에 서브 쿼리를
포함하고 있는 쿼리문을 메인쿼리, 포함된 또 하나의 쿼리를 서브쿼리라 한다.
--조인을 대체할 수 있는 서브쿼리
SELECT DEPARTMENT_NAME
FROM DEPARTMENTS
WHERE DEPARTMENT_ID=(SELECT DEPARTMENT_ID
FROM EMPLOYEES
WHERE FIRST_NAME='Susan'); --괄호 안이 서브쿼리
실행 순서는 서브쿼리가 우선이다.
서브쿼리는 비교연산자의 오른쪾에 기술해야 하고 반드시 괄호로 둘러싸여야 함.
서브쿼리는 메인 쿼리가 실행되기 전에 한번만 실행된다.
ㆍ서브 쿼리에서 SELECT 하지 않은 컬럼은 주 쿼리에서 사용할 수 없다.
ㆍ특별한 경우 (인라인 뷰 등)를 제외하고는 Sub Query절에 Order by 절이 올 수 없다.
ㆍ서브 쿼리 안에 서브쿼리가 들어갈 수 있다. 메모리가 허용하는 한 무제한으로 중첩할 수 있다.
ㆍ단일 행 Sub Query 와 다중 행 Sub Query에 따라 연산자를 잘 선택해야 한다.
--예제EMPLOYEES 테이블에서 Lex와 같은 부서에 있는 모든 사원의 이름과 입사일자(형식: 2003-01-13)를
--출력하는 select문을 작성
--Lex 사원이 소속된 부서번호를 구한다.
select department_id
from employees
where first_name='Lex';
--그 부서에 소속된 동료들을 구한다.
select first_name, to_char(hire_date, 'YYYY-MM-DD') AS HIRE_DATE, DEPARTMENT_ID
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 90;
--서브 쿼리로 작성하면
--서브 쿼리가 먼저 실행되어 90 부서번호를 구하고 메인쿼리가 실행되어 90번 소속된 사원을 구한다.
select first_name, to_char(hire_date, 'YYYY-MM-DD') AS HIRE_DATE, DEPARTMENT_ID
FROM EMPLOYEES
WHERE DEPARTMENT_ID = (select department_id
from employees
where first_name='Lex');
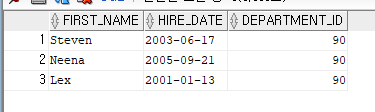
--<문제>EMPLOYEES 테이블에서 CEO에게 보고하는 직원의 모든 정보를 출력하는 SELECT문을 작성하시오.
SELECT EMPLOYEE_ID
FROM EMPLOYEES
WHERE MANAGER_ID IS NULL;
SELECT * FROM EMPLOYEES
WHERE MANAGER_ID = 100;
SELECT *
FROM EMPLOYEES
WHERE MANAGER_ID=(SELECT EMPLOYEE_ID
FROM EMPLOYEES
WHERE MANAGER_ID IS NULL);
SELECT * FROM EMPLOYEES;
-- Guy와 같은 부서에서 근무하는 사원의 사원번호, 이름, 급여, 커미션(NULL이면 0으로 대체),
-- 입사일(2002.12.07)를 출력하되 Guy 사원은 제외한다.
select department_id from employees where first_name ='Guy';
select department_id,first_name,salary,commission_pct,hire_date
from employees
where department_id=30;
select department_id,first_name,salary,nvl(commission_pct,0),to_char(hire_date,'yyyy-mm-dd')
from employees
where department_id=(select department_id
from employees
where first_name ='Guy')
and first_name <>'Guy';

--단일 행 서브쿼리 예제
--문제1) employees 테이블에서 last_name 컬럼에서 Kochhar의 급여보다 많은 사원의 정보를
--사원번호, 이름, 담당업무, 급여를 출력
select department_id,first_name,last_name,job_id,salary
from employees
where salary > (select salary
from employees
where last_name='Kochhar');

--문제2) 가장 적은 급여를 받는 사원의 사번, 이름, 급여를 출력해 주세요.
select min(salary) from employees;
select department_id,first_name,salary
from employees
where salary=2100;

--문제3) 가장 오랜 기간 근무한 사원의 이름과 이메일, 담당업무, 입사일 출력
select first_name,email,job_id,hire_date
from employees
where hire_date = (select min(hire_date)from employees);
select
count(decode(department_id,10,1))"10번부서인원수",
count(decode(department_id,20,1))"20번부서인원수",
count(decode(department_id,30,1))"30번부서인원수",
count(decode(department_id,40,1))"40번부서인원수",
count(decode(department_id,50,1))"50번부서인원수"
from employees;

JDBC(Java DataBase Connectivity)
ㆍ자바 프로그램에서 데이터베이스와 연결하여 데이터베이스 관련 작업을 할 수 있도록 해주는 API, 다양한
종류의 관계형 데이터베이스에 접근할 때 사용되는 자바 표준 SQL 인터페이스이다.
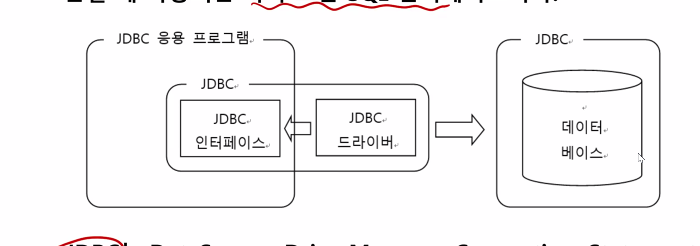
ㆍJDBC는 DataSource, DriverManager, Connection, Statement, PreparedStatemnet, CallableStatement,ResultSet 등 여러 개의 클래스와 인터페이스로 구성된 패키지 java.sql와 javax.sql로 구성되어 있다.
자바와 데이터 베이스
각 DBMS와 관련하여 회사도 많고 그로 인해 사용하는 방법이 달라진다면 > 이러한 문제를 해결하기 위해 SUN은 표준이 되는 인터페이스를 제공하고있는것
데이터베이스를 만드는 회사는 SUN사에서 JDBC 인터페이스를 통해서 자신들의 데이터베이스에 맞게 기능들을 구현 인터페이스만 알면 데이터베이스 조작가능
데이터베이스 회사들이 SUN사의 표준이 되는 인터페이스를 상속받아 구현해 놓은 것이 바로 JDBC 드라이버이다.
ㆍJDBC 드라이버
해당 DBMS에서 JDBC 관련 API 호출이 가능하도록 관련 인터페이스와 클래스를 구현한 클래스 라이브러리

.java를 컴파일한 .class를 압축한 파일이 .jar
ORACLE이나 MS, IBM 등의 DBMS(Database Management System)제품 회사들이 자신들의 DBMS에 알맞는 기능들을 일반적으로 JDBC Driver로 구현하여 제공해 주기 때문에 사용자들은 인터페이스만 이해하면 데이터베이스를 조작할 수 있다. JDBC는 이런 드라이버들으 공통된 인터페이스인 것이다.
JDBC 를 세분화 하면 JDBC INTERFACE ,JDBC DRIVER
ㆍJDBC는 SQL문을 DBMS에 전달하고 결과셋을 반환해주는 중개자 역할을 담당
ㆍ결과로 받은 데이터를 자바에서 사용할 수 있는 형태로 변환하여 프로그램에 반환
ㆍJDBC는 이 매개변수로 넘어온 SQL문을 DBMS에 전달
JDBC interface를 각 회사가 특성에 맞게 구현하여 jar 또는 zip 등의 형태로 제공
쿼리의 조건을 만족하는 레코드들의 집합 > 결과집합(ResultSet)
커서(cursor)는 커서란 특정 SQL문장을 처리한 결과를 담고있는 영역을 가리키는 일종의 포인터
기본 구현 순서
JDBC를 이용하여 데이터베이스에 데이터를 액세스하기 위해서는 기본적인 순서가 있다.
java.sql.*;
JDBD API를 사용하기 위해서는 반드시 선언
JDBC 드라이버 로딩 및 레지스터등록
Class.for.Name() 사용
데이터 베이스 연결(Connection 객체 얻는다.)
DriverManager.getConnection() 사용
SQL을 위한 Statement 객체 생성
Connection.createStatement() 사용
SQL 실행
(select)executeQuery()/ executeUpdate()/ execute() 사용
ResultSet 결과셋 얻기
SQL문의 실행 결과셋 얻기. ResultSet에 저장된 데이터 값 출력
객체 자원 반납(연결 해제)
close()

