
3주 동안 나 포함 4명이서 잠도 잘 못자며 진행했던 프로젝트를 마감 했다.
아직도 기억에 남는건 거의 매일 새벽까지 코딩을 하느라 누군가 옆에서 크리스마스와 새해라고 얘기하기 전까지는 알지도 못했다.
처음으로 개발 리더를 맡았고 프론트 뿐만 아니라 데이터 분석까지 일정을 신경써야 해서 부담이 있었다.
하지만 이 프로젝트에 참가한 분들이 실력자에 열정이 가득하신 분들이라 배운 것도 많았다.
리더의 자리를 맡게된 순간부터 3~4일은 정말 하루 종일 팀을 어떻게 끌어가야 하는가에 대한 고민만 했었다.
'개발 리더', '개발 팀 일정 관리' 등등의 단어들을 구글링하고 이 프로젝트에 참여한 이전 기수 분들 것도 참고를 했었다.
말만 '스프린트', '에자일' 해봤지 사실상 뭔지도 몰랐고 깃은 혼자만 사용해봤기 때문에 깃으로 협업하는 방법도 알지 못했다.
스프린트, 에자일, 스크럼을 팀 프로젝트 일정 관리에 사용하고자 아래 글을 참고하였다.
먼저 에자일 방법론의 스크럼을 도입해 매일 9:30에 구글 미트에서 팀원들과 소통하였다. 오늘 일정을 간단하게 브리핑 후 각자 어제 한 일, 오늘 한 일, 에러사항을 발표하도록 하였다. 원래 스크럼은 10분~20분을 limit으로 세웠으나 생각보다 많은 내용을 나눠 회의가 된 적도 있었다. 우리는 팀원이 적어서 이렇게 진행하는 것이 개발에 도움이 됐으나 팀원이 많아진다면 그에 따라 limit을 확정 짓는 것도 좋을거 같다.
둘째로, 스프린트 일정을 세웠다. 1주차에 기획, 2주차에 주요 기능 개발을 목표로 잡았다. 마지막 3주차에는 유지 보수 및
서브 기능 개발에 주력하고자 하였다.


(실제로 진행된 개발 일정)
셋째로, 기타 팀 규칙을 세웠다. 팀 규칙은 길어봤자 정한 사람 외에는 아무도 기억을 못하기 때문에 최대한 간결하고 필요한 것만 정리했다.

아래는 팀 일정 관리를 위해 사용한 노션 페이지이다.
https://www.notion.so/cdbd8daeb67d4d9287f5ed1649de2727
위와 같이 간단한 계획을 세운 뒤 1주차의 기획을 시작 하였다.
<데이터 분석>
[데이터 분석 프로젝트] 이기에 가장 중요한건 유의미한 데이터의 존재 여부였다. 따라서 첫 회의 시작 전에 각자가 찾아온 데이터와 그에 맞는 아이디어를 기록하도록 하였다. 데이터 셋은 주로 데이터 분석가들의 깃이라 불리는 kaggle에서 찾았다.
우리는 ott 서비스와 관련된 내용의 데이터 분석을 하기로 하여 kaggle에서 ott, movie, drama 등등의 단어들을 검색한 후 최근의 모든 dataset을 열어 보았다. kaggle은 해외에 한정적인 부분도 많아 국내 데이터도 수집하기 위해 정부 기관 공공 데이터 포털도 찾아 보았다.
가지고 온 dataset만 40개가 넘었고 여기서 사용 가능한 데이터를 추리는데만 3일, 아이디어에 맞게 가공하기까지 일주일이 걸렸다. 실제로 사용한 dataset은 3개였으며 이를 바탕으로 아이디어도 구체화 하였다.
보통 ott 서비스 데이터 분석 프로젝트라 하면 사용자에게 컨텐츠를 추천해주는 프로그램을 개발 할 것 같아 우리는 영화 제작사나 투자자들을 타깃으로 글로벌 시장에 대한 인사이트를 제공하는 프로그램을 개발하기로 하였다.
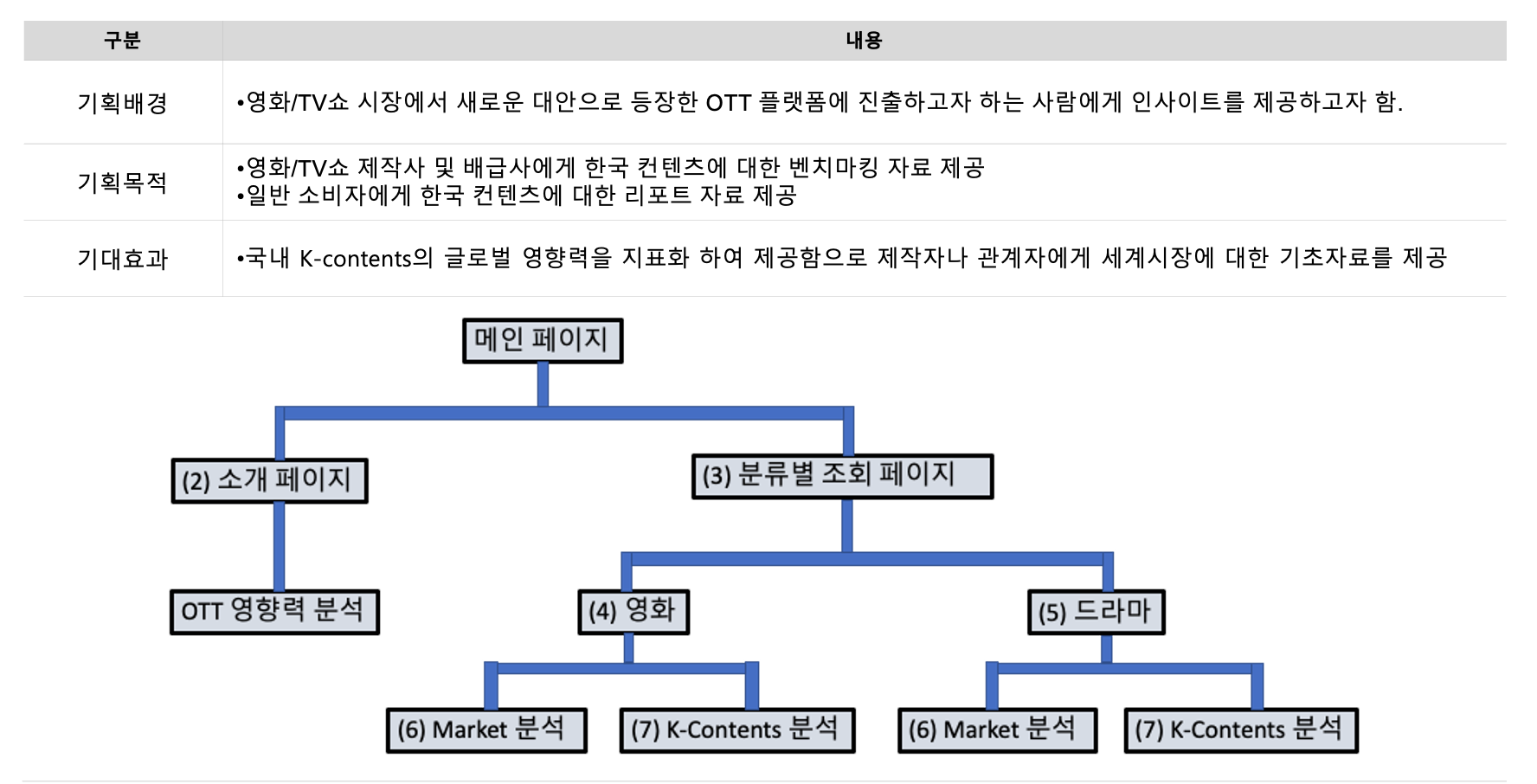
<프론트엔드>
기획의 가닥이 잡히자마자 프런트 담당자 분이 바로 와이어프래임을 제작하였고 이를 바탕으로 프런트 분과 소통하며 스토리보드 제작에 들어갔다. 리더여서 스토리보드를 함께 제작하기도 했지만 백엔드 담당자로서 스토리보드는 각 페이지별 Rest-api 설계에 가장 중요한 역할을 하였다. 회의 시간에는 프론트엔드 팀원이 와이어 프레임을 설명하고 데이터 분석 팀원들이 피드백 하여 분석 결과에 대한 시각화 자료를 구체화하고 디자인을 확정시켰다. 이때부터 프론트엔드는 개발 단계에 들어갔다.
~~와이어프레임:https://www.figma.com/file/j88GAXJlMdhWLJCRbtNtow/%EC%97%98%EB%A6%AC%EC%8A%A4-%ED%8C%80-%ED%94%84%EB%A1%9C%EC%A0%9D%ED%8A%B8?node-id=0%3A1
~~
<Backend&Deploy&Leader>
첫주차부터 제일 난감했던건 '개발 협업을 어떻게 하는가?' 와 '배포를 어떻게 할 것인가?' 였다. 팀 내 개발 프로젝트 및 배포를 진행해본 팀원이 전무했다. 이때 직방 개발자인 남자친구에게 sos를 매우 많이 쳤고 실제로도 많은 도움을 주었으나 문제는 내가 EC2가 뭔지, Docker가 뭔지, Nginx가 뭔지 아무것도 모른다는 것이었다. 아무리 설명을 들어도 이해가 가지 않아 3~4일 동안 인강만 보고 구글링을 해가며 겨우 aws EC2를 만들었다. 만든 이후에는 ssh로 접속할 수 있도록 비번을 설정해 팀원들에게도 전송 하였다.
깃 개발 협업을 위해 브런치는 frontend, backend, 기획(문서를 위한), sprint, master 브런치로 나눴고 스프린트 하나가 완료 될때마다 frontend와 backend 브런치를 머지 시켰다. sprint 브런치가 deploy때 마다 사용되었으며 마감때 master 브런치로 전부 merge 시키도록 했다.
기획이 완료되자 2주차의 주요기능 스프린트 개발이 시작 됐다.
<데이터 분석>
데이터 전처리가 완료되고 유의미한 분석 결과가 나오기 시작했다. 이때부터 시각화를 위한 작업이 시작되었으며 백엔드에 전송할 더미 데이터가 만들어졌다. 넷플릭스에 방영된 영화 259편과 드라마 229편의 IMDB점수, 시상, 릴리즈된 국가, IMDB 투표자수를 바탕으로 각 컨텐츠들을 평가할 지표를 도출해냈다. 또한 한국 영화관 매출액과 넷플릭스 코리아 매출액을 2017~2021년을 기준으로 비교해 ott의 영향력을 분석했다.
<프론트엔드>
디자인이 구현되자마자 더미데이터를 활용하여 시각화 자료를 모든 페이지에 넣었고 페이지별 기능들을 개발하기 시작했다. 스프린트 후 test 때 팀원들의 피드백에 따라 페이지와 기능이 추가 되었으며 이에대해 프론트 팀원이 유연하게 대처하여 바로바로 업데이트를 진행했다.
또한 백엔드와의 swagger 사용을 진행했고, api를 받아오는 것까지 구현하였다.
<Backend&Deploy&Leader>
리더로서 스프린트 마감을 일주일 앞두고 팀원들에게 계속해서 푸쉬를 해야 했다. 나는 누구보다도 즐겁게 자유로운 분위기에서 일하는 것을 추구하는 편이라 최대한 푸쉬가 푸쉬같이 느껴지지 않도록 스크럼때마다 이번주 팀 목표를 상기 시키는 정도로만 끝을 냈다. 물론 다 알아서 잘하시는 팀원 분들이라 애초에 푸쉬할 필요가 없기도 했다.
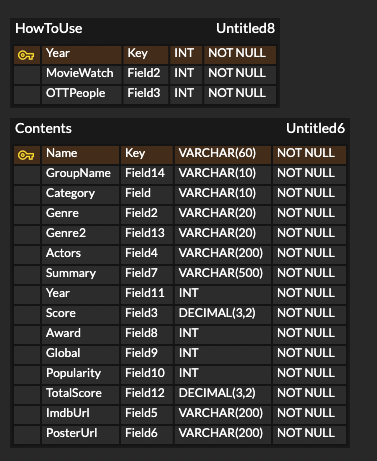
Backend 담당자로서 일주일간 애를 먹은 er-diagram을 완성 했다. 어떻게 만들어야하는지 도무지 감도 안와서 며칠을 머리를 쥐어 뜯었으나 실무자이신 코치님께 피드백받으며 해결해냈다. 알려주신 방법은 페이지마다 필요한 데이터를 정리하고 이걸 계속 해서 최대한 적은 테이블로 줄여나가는 것인데, 이때 줄이는 방법은 사용할 수 있는 쿼리를 생각하는 것과 각 데이터의 연관성을 이용하는 것이었다. 이게 말로 하면 어렵지만 막상 해보면, 아래와 같은 로직으로 쉽게 할 수 있다는 걸 알게 된다.
"아! 이 페이지에서는 각 영화의 클래스들의 평균 점수가 들어가는구나
-> 그러면 클래스와 클래스의 평균 점수를 테이블에 넣어야 겠네!
-> 클래스별 평균 점수는 클래스를 조회해서 해당 클래스의 영화 점수만 평균을 내면 되겠네!
-> 그러면 테이블은 영화 이름, 클래스, 점수 로 구성되면 되겠다."
그리고 데이터를 csv 파일에서 읽어오면서 굉장히 많은 에러를 거쳤는데,
data.to_sql(name='contents', con=engine, if_exists='append', index=False)if exists='replace' 일때도 잘 안됐고 특히 index=True 줬다가 테이블이 다 깨져서 다시 만든게 열번은 넘을 것이다.
id 값으로 index를 설정한다면 auto increment 이므로 따로 index=True를 주지 않아도 된다는 걸 기억하자.
또, 테이블 깨지면 sql 다시 입력할 필요 없이 models.py 에 아래의 코드를 입력하면 자동 생성 된다.
db = SQLAlchemy(app)
db.create_all()
if __name__ == "__main__":
app.run(debug=True)
이때 실행은 python3 models.py로 해주는게 좋다. 그러면 DB에 테이블이 생성 된다.
DB는 EC2에 만드려 계획했으나 개념 이해까지 너무 어려워 aws RDS를 사용하였다. 확실히 RDS는 매우 편하나 문제는 서버가 무료일 경우 오하이오주에 있기 때문에 살짝 구린 느낌이 있다. 이때 RDS의 인바운드 설정과 아웃바운드 설정을 잊지않고 해주도록 하자.
Swagger 사용을 위해 NGINX 배포도 시작하였고 이때 flask의 restful을 사용하려 했으나 계속되는 버그에 버전 관리가 현재는 이루어지지 않는다는 설명을 보고 Restx로 갈아탔다. 확실히 cors 관리도 편하고 swagger 사용도 쉬워 프론트와 api를 편하게 진행할 수 있었다.
@api.route('/movie/k-contents/{class}')
@api.doc(params={"class": "MovieA,MovieB,MovieC,MovieD 중 하나"})
@api.param("class")
class K_contents(Resource):
def get(self):
classname = request.args.get('class', type=str)위에는 restx 코드 예시이다.
이렇게 프론트 배포를 제외한 모든 스프린트를 마무리 지었다.
마지막 주차는 최종 배포 및 세부 기능 개발에 들어갔다.
<데이터 분석>
이때부터 데이터 분석은 최종 데이터를 백엔드에 제공하고 문서화 작업을 진행 했다. 기획서 초안을 전면 수정하고 발표자료 피피티를 만들기 시작했다. 더욱 더 완벽한 프로그램으로 만들기 위해 스프린트를 보며 시각화 자료 피드백을 제공했고 그 결과 워드 클라우드 및 장르 지수 테이블을 추가하였다. 또한 프런트 기능에 대한 피드백을 진행했다.
<프론트엔드>
배포는 처음에 pm2로 무중단 배포를 진행하기로 계획했으나,
https://engineering.linecorp.com/ko/blog/pm2-nodejs/
프런트 팀원분의 컴퓨터가 윈도우라는 점과 당시에 vs code에 remote explorer라는 패키지가 있다는 걸 몰랐던 우리는 결국 새벽 두시가 다 되서 verssel로 배포하였다. verssel은 프로젝트 세개까지 무료이고 깃허브에 연동하여 지정 브런치 merge마다 자동 build 후 deploy를 진행한다는 매우 큰 장점이 있다. 당시 우리 팀은 깃랩을 사용하고 있어서 아래 링크처럼 미러링한 깃허브로 연동해서 사용했다.
https://day0404.tistory.com/37
배포 이후 프론트에서는 계속해서 피드백에 따라 기능들을 개선해나갔고 반응형으로 CSS도 변경하였다.
<Backend&Deploy&Leader>
백신 부작용으로 며칠동안 약을 달며 프로젝트를 진행한 결과 마지막에 밤을 여러번 새게 되었다. 이게 가장 아쉬운 점이었는데, 리더로서 계속해서 푸쉬하며 하나하나 체크하지 못해 생긴 구멍이 있었고, 이걸 막기 위해 막판에 8시간 넘게 질주 했던것 같다. 3주차는 스크럼이 제대로 진행되지 않았기 때문에 아직까지 구현되지 못한 기능의 데이터와 개발이 있었다는 것을 알아 차리지 못했다. 그 당시에는 너무 속상했으나 뭐, 내 잘못이니 감안하고 가는 수 밖에 없어 최대한 팀원들의 도움을 요청해 모든 것을 마칠 수 있었다.
Backend 담당자로서 지속적인 cors문제가 발생해 찾아본 결과 HTTPS로 통하는 SSL 인증서 문제였다는걸 알게 되었다. 이를 위해 도메인을 하나 구입했는데, 무료 도메인도 많으니 다른 곳도 이용해도 된다. 나는 가비아를 통해 구입했고 550원으로 .shop의 제일 싼 도메인을 가지고 왔다.
그 도메인으로 Nginx(flask) 연결, front 와 backend 도메인 구성, ssl 인증까지 받았다. ssl은 무료로 let's encrypt를 통해 받았다. 아래 링크가 정말 자세하게 설명되어 있으므로 다음에 또 사용하기 위해 저장하였다.
https://luminitworld.tistory.com/85
Flask는 gunicorn을 사용하여 배포하려 했으나
여러 문제가 많이 발생하여 야매로 빽그라운드에서 돌렸다. 명령어는 아래와 같다.
$ python3 app.py
$ ^z <- Ctrl+z 누르기
$ bg
$ disown -hdeploy시 껐다 켰다 해야하긴 하는데 뭐.. 많은 사용자가 접속하는 것이 아니라서 크게 서버가 꺼질 일도 없어 이대로 배포 했다.
그리고 백엔드 속도 향상을 위한 코드 리팩토링을 진행했다. 이때 group_by 쿼리를 이용하여 쉽게 코드를 변경 하였다. 그리고 쿼리로 func.avg()이나 혹은 func.sum() 사용시 맨 뒤를 .first()로 하고 print 해보고 데이터가 아닌 클래스(객체) 타입이 출력 된다면 그 뒤에 [0]을 붙여보길 권장한다.
아래는 리팩토링 이전의 반복되는 코드 예시 이고,
popularity = db.session.query(func.avg(Contents.popularity)).filter_by(
category="Series", group_name=classname).first()[0]
award = db.session.query(func.avg(Contents.award)).filter_by(
category="Series", group_name=classname).first()[0]
global_score = db.session.query(func.avg(Contents.global_score)).filter_by(
category="Series", group_name=classname).first()[0]
scores = (db.session.query(func.avg(Contents.score)).filter_by(
category="Series", group_name=classname)).first()[0]아래는 리팩토링 이후 한줄로 바꾼 코드이다.
score_list = (db.session.query(func.avg(Contents.score), func.avg(Contents.award), func.avg(Contents.global_score), func.avg(Contents.popularity), func.avg(Contents.total_score)).filter_by(category="Series", group_name=classname)).first()
이렇게 3주간의 모든 프로젝트가 마감되었다. 4명이서 10분 동안 각자 맡은 부분을 발표했는데 리허설도 한번 진행을 해서 그런지 굉장히 매끄러웠다는 평가를 받았다. 좋은 팀원을 만나서 값진 경험을 할 수 있어서 매우 기뻤다. 같이 새벽에 구글미트에서 될때까지 해보기도 하고 카톡으로 계속해서 서로 소통해가며 만들어간 프로젝트가 빛을 발해서 행복했다. 작년부터 극심한 무기력증으로 고생하다가 오랜만에 도파민 자극으로 뿌듯하다. 아래 링크는 서버 종료 및 도메인 구매일 종료시 사라지겠지만 당분간은 살아있으니 첨부했다.
