캐글 타이타닉 문제를 진행하기 위해 위의 링크에서 작성되어 있는 튜토리얼을 참고하여 진행하려고 합니다.
Part 1:Get Started
Join Competition
먼저 Titanic: Machine Learning from Disaster 페이지를 보면
우측 하단 Join Competition 버튼을 클릭합니다.
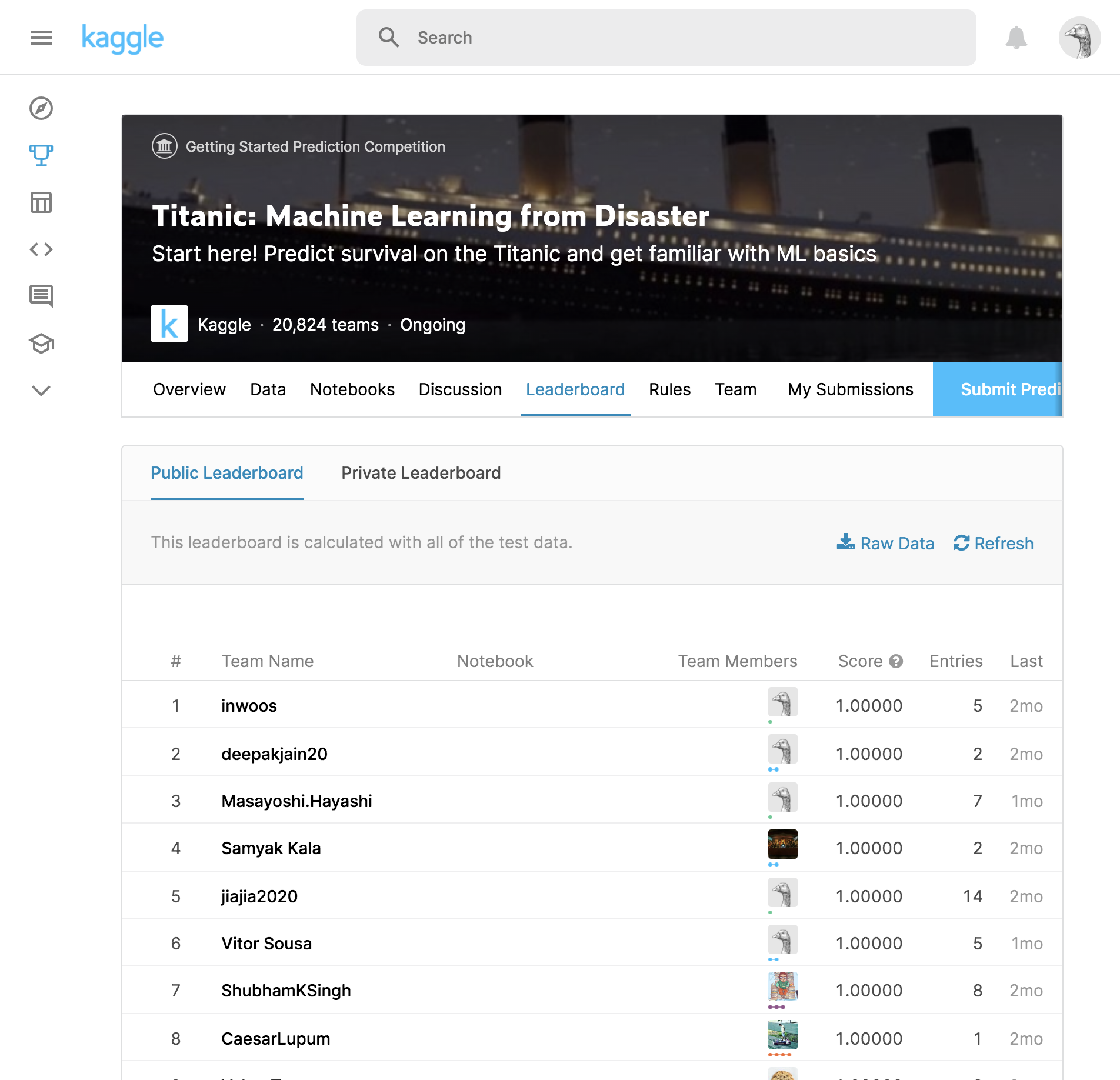
클릭하면 위와 같이 Leaderboard를 포함한 페이지가 출력됩니다.
이제 문제를 풀어 제출하면 채점되는 듯 합니다.
The Challenge
이 competition은 간단하다. 타이타닉의 승객 데이터(이름, 나이, 티켓 가격 등)를 사용하여 승객 생존 여부를 예측하는 것이다.
The Data
Competition 데이터를 보려면 Competition 페이지 상단의 Data tab을 클릭한다.
그 다음 스크롤을 내려서 파일 목록을 찾습니다.

데이터가 포함된 3개의 파일(train.csv, test.csv, gender_submission.csv)이 있습니다.
(1) train.csv
train.csv는 승객의 디테일한 subset(891 passengers, to be exact - where each passenger gets a different row in the table)을 포함합니다.
이 데이터를 조사하려면 페이지 좌측에 위치한 "Data Sources" column 에서 파일 이름을 클릭해야 합니다.
여기까지 했다면 모든 column 이름들이 내용에 대한 간단한 설명과 함께 화면 우측의 "Columns" 타이틀 아래에 list로 보일 것입니다.
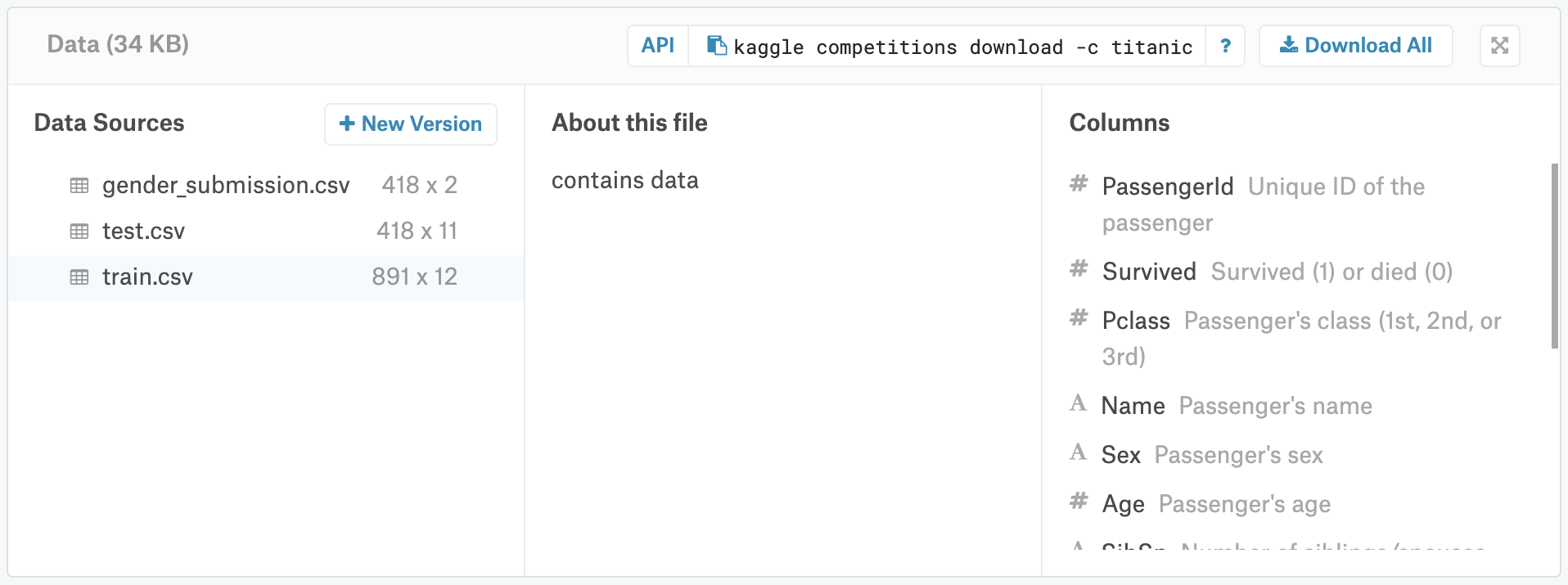
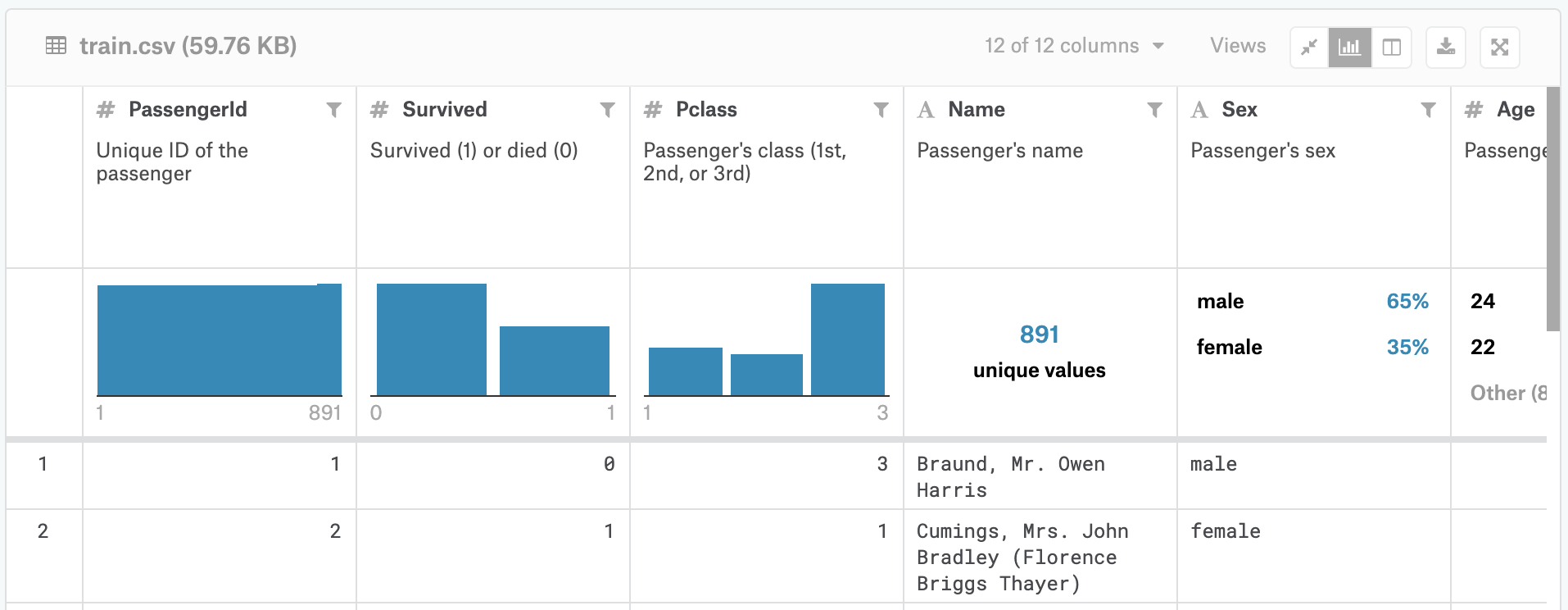
실제로 진행해보면 뭔가 레이아웃이 변경된 것 같은데 착각인가 ?
Data Dictionary
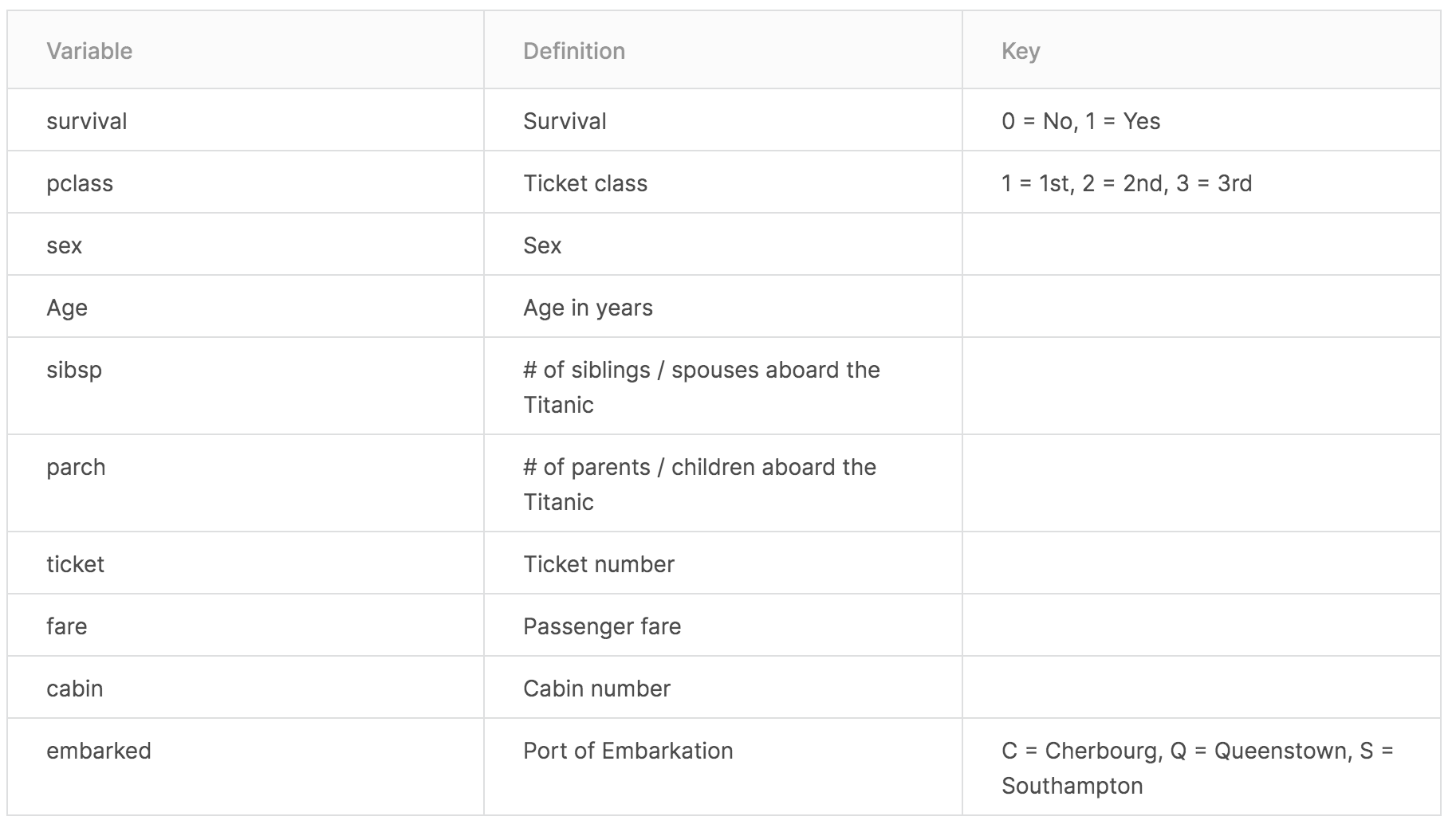
DataSet에 대한 정보는 위의 Table을 참고하면 쉽게 알 수 있습니다.
각 Column에 대한 정보 :
suvival: '0'은 사망, '1'은 생존pclass: Ticket의 등급을 나타내며 수가 높을 수록 낮은 등급입니다.sex: 성별age: 나이sibsp(sibling + spouse): 해당 row의 승객의 Sibling과 Spouse 합입니다..- Sibling : brother, sister, stepbrother, stepsister
- Spouse : husband, wife(여자 주인이나 약혼자는 제외되었습니다.)
parch(parent + child): 해당 row의 승객의 parent와 child의 합입니다.- Parent : mother, father
- Child : daughter, son, stepdaughter, stepson (오직 유모와 여행한 어린이는 parch가 0입니다.)
ticket: 티켓의 번호입니다.fare: 여객 운임(지불한 금액)입니다.cabin: 선실 번호입니다.embarked: 승선한 지역입니다.- C : Cherbourg
- Q : Queenstown
- S : Southampton
(2) test.csv
train.csv에서 찾은 패턴을 이용하여 탑승한 다른 418명의 승객(test.csv)이 생존했는지 예측해야 합니다.
Data Sources Column 아래에 있는 test.csv을 클릭하면 내용을 확인할 수 있습니다. 다만, test.csv 에는 Survived Column이 없습니다.
해당 정보는 감추어져 있으며 이 값을 얼마나 정확하게 예측하느냐에 따라 점수가 결정됩니다.
(3) gender_submission.csv
gender_submission.csv 파일은 당신이 어떻게 예측을 진행할 지를 보여주는 예시가 포함되어 있습니다.
여성 승객은 모두 생존하고 남성 승객은 모두사망했다고 예측하지만, 생존에 대한 당신의 예측은 아마 다를 것이고 당신의 예측은 다른 제출 파일에 아래의 정보가 포함되도록 작성해야 합니다.
PassengerId: test.csv의 각 승객 ID가 포함되어야 합니다.Survived: 해당 승객의 생존 여부를 '0' 또는 '1'로 나타내어야 합니다.
First submission
당신은 밴치 마크로 gender_submission.csv 파일을 다운로드하고 제출해야 합니다.

파일 이름 오른쪽에 있는 다운로드 링크를 클릭하면 다운로드가 시작됩니다.
컴퓨터에 다운로드를 한 뒤 아래를 진행합니다.
- competition 페이지 우측 상단에 위치한 파란색의 "Submit Predictions" 버튼을 클릭합니다.
- "Step 1: Upload submission file" 까지 스크롤을 내립니다. 그리고 방금 다운로드한 파일을 업로드하고 파란색의 "Make Submission" 버튼을 클릭합니다.
몇 초가 지나면 당신의 submission이 채점될 것 입니다. 그리고 리더 보드에 당신이 보일 것입니다.
실제 제출 결과
score가 0.76555 이다.
내가 예측해서 제출하면 저것보다 낮은 점수가 나올 것 같은데 ...
한것도 없지만 뭔가 순위가 할당되었다.
