어떤 프로젝트였는가
투빅스에서 컨퍼런스를 진행하며 진행한 프로젝트로, 사용자가 입력한 카페 이미지와 비슷한 카페를 찾아주는 모델을 만드는 것이 목표였다.
어떤 데이터를 사용했는가
크롤링
서울시의 프랜차이즈를 제외한 카페 약 2600여개에서 8000여개의 카페이미지와 리뷰를 '다이닝코드'(음식점 리뷰 웹사이트)에서 크롤링

한 카페당 3장의 사진, 가장 많은 공감수를 받은 리뷰 하나 크롤링
레이블링
카페 이미지에 대한 분위기 레이블링을 직접 시행, 3명 이상의 팀원이 사진에 대한 레이블링을 진행하고 다수결로 최종 레이블 결정
어떤 모델 사용했는가
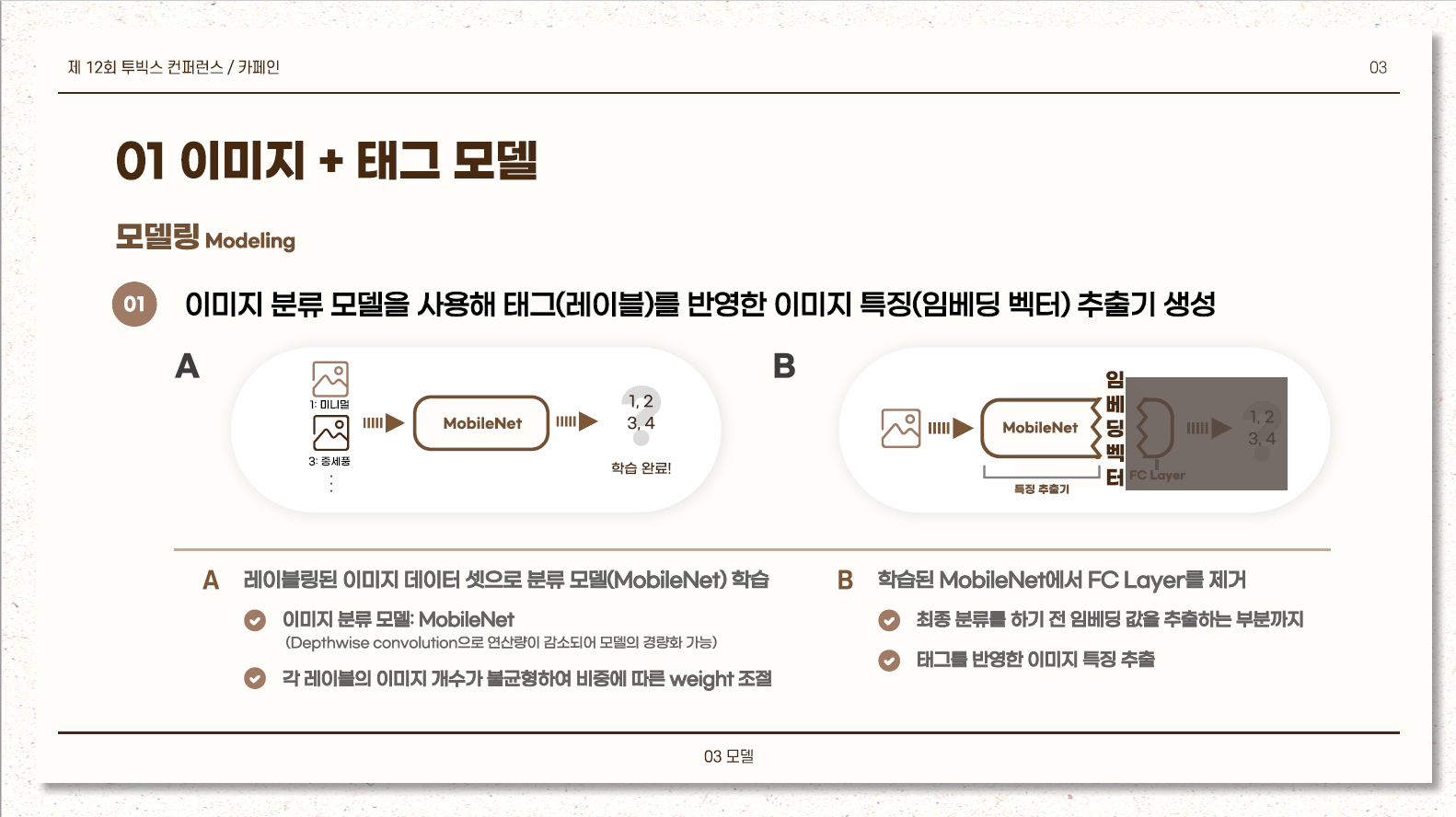
이미지 분류 모델
input: 카페이미지
output : 분위기 레이블
- MobileNet을 사용하여 이미지 분류모델을 만들고 FC-layer 이전의 가중치로 임베딩 형성
- 레이블별로 이미지 개수가 달라 loss에서 weight를 부여
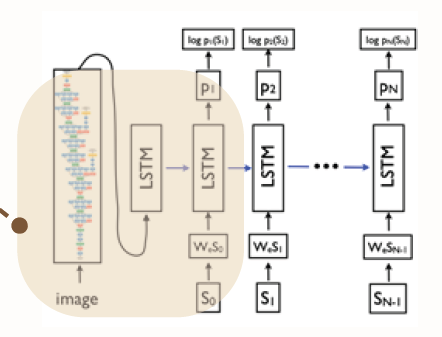
이미지 캡셔닝 모델
input: 카페 이미지
ouput: 카페 리뷰
Show and Tell
pre-trained된 CNN layer를 이용해 이미지를 인코딩하고 이를 RNN 디코더에 입력하여 문장을 생성하는 구조
여기서 디코더부분에서 임베딩 벡터 형성

kor2vec
'교착어'라는 한국어의 특성때문에 빈번히 발생하는 OOV(Out Of Vocabulary) 문제를 해결하기 위해 char-word 임베딩을 한국어에 적용한 임베딩 방식
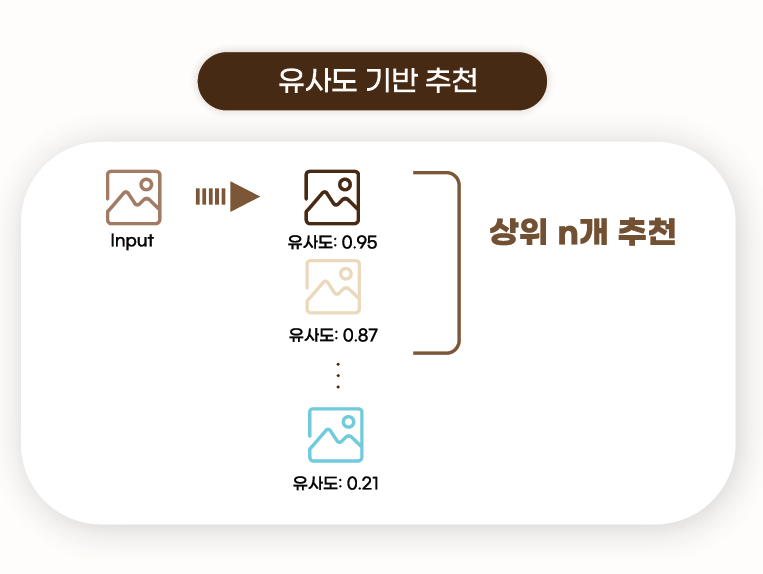
최종 예측
이미지 분류 모델의 임베딩과 이미지캡셔닝 모델의 임베딩을 concat하여 유클리디언 유사도가 가장 높은 상위 이미지를 추천
아쉬운점 및 발전방향
평가지표의 주관성
'비슷한 분위기'라는 것을 객관적이고 수치적인 지표로 평가하기 어려웠다. 그렇기에 기준이 되는 데이터셋을 고정하고 모델마다 추천결과를 살펴보며 팀원 다수결로 성능을 평가하였다.
일관된 구도의 이미지 수집 필요성
카페 리뷰 이미지에는 음료 사진, 카페 내/외부 사진으로 나눌 수 있었다. 따라서 이를 각각 나눠서 유사도를 보려는 시도를 했으나 대부분의 카페가 음료사진이 많았기에 데이터의 불균형으로 시도하지 못했다. 다른 지역의 데이터를 보충하여 진행해보는 것도 좋을 것 같다.
실제 고객의 피드백
추천시스템의 성능을 측정하는 것이 어렵다고 느꼈다. 실제 서비스를 제공하는 것이라면 a/b테스트를 시도해볼수 있고, 서비스에 대한 피드백을 확인할 수 있지만 그럴 수 없다는 것이 아쉬웠다.
