cross_val_score 함수
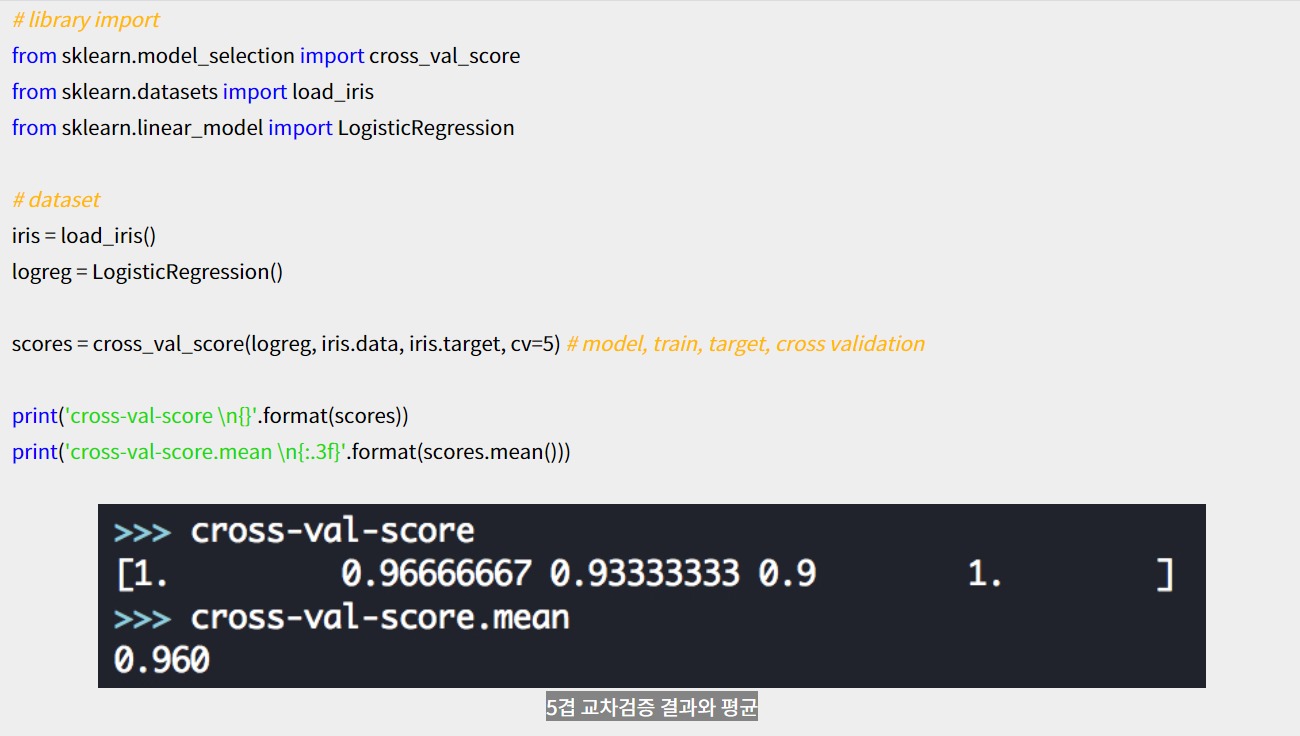
scores = cross_val_score(logreg, iris.data, iris.target, cv=5)모델, x, y, fold수 넣으면 각 폴드마다 정확도를 알려준다.
sklearn의 수치예측 scoring함수
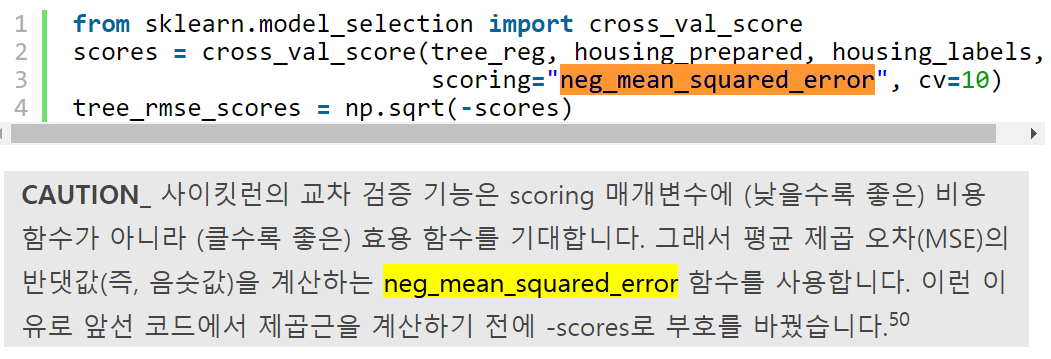
위와 같은 이유 때문에
scoring='neg_mean_squared_error'를 쓰는 이유는 scoring 매개변수에 클수록 좋은 함수를 기대하기 때문에 -mse를 쓰고 나서 나중에 다시 -를 곱해준다.
Kfold 함수
n_folds = 5
train = X
def rmse_cv(model):
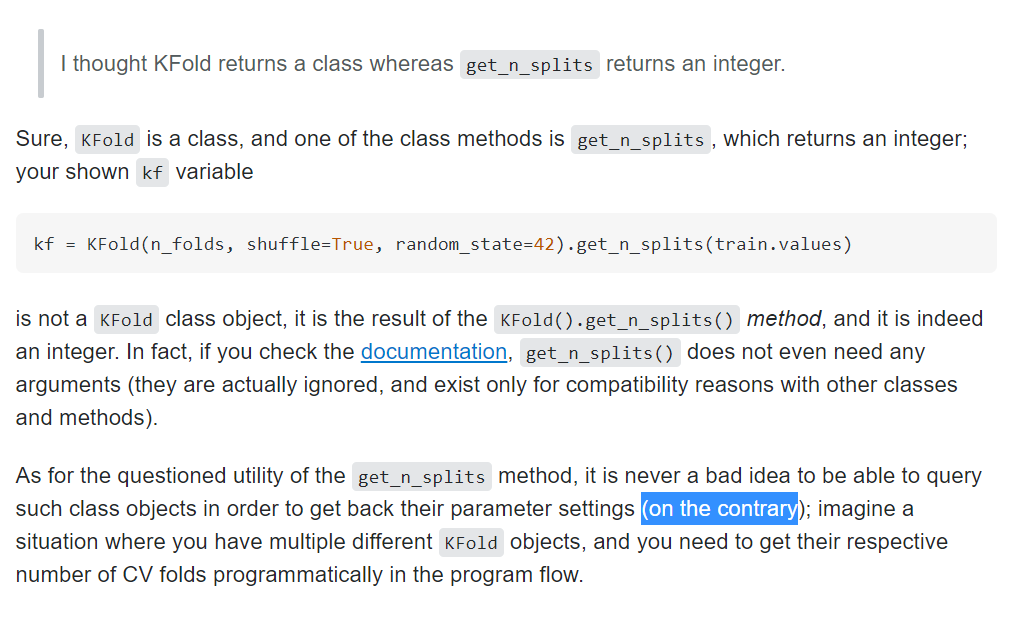
kf = KFold(n_folds, shuffle=True, random_state=42).get_n_splits(X_train.values)
rmse = np.sqrt(-cross_val_score(model, X_train.values, y_train, scoring='neg_mean_squared_error', cv=kf))
return (rmse)위 함수에서 굳이 get_n_splits(X_train.values)를 쓰는 이유는 요기에
pipeline함수와 grid search 같이 쓰기
pipeline정의하고 그냥 grid search돌리면 된다.
num_folds = 5
seed = 7
scoring = 'neg_mean_squared_error'
param_grid = {
"lgbm__n_estimators" : [10, 20, 30, 50, 100, 200, 300],
"lgbm__learning_rate" : [i for i in np.linspace(0.1,1, 10)],
"lgbm__num_iteration" : range(100, 1100, 200)
}
#pipeline 생성
step1 = ('select', SelectKBest(f_regression, k=20))
step2 = ('lgbm', lightgbm.LGBMRegressor(objective='regression'))
model = Pipeline([step1, step2])
kfold = KFold(n_splits=num_folds, random_state=seed)
#여기선 KFold객체자체를 grid에 넣어준다.
grid = GridSearchCV(estimator=model, param_grid=param_grid, scoring=scoring, cv=kfold, verbose=3)
grid_result = grid.fit(X_train, y_train)
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))- kfold의
get_n_splits(X_train.values)를 넣어주는 경우와 - 그냥 폴드 수를 숫자로 넣어주는 경우
- kfold객체를 넣는 경우
3개의 차이점은 무엇일까? 일단 1,2는 원리상 같은 것이고
2와 3의 차이가 뭘까..........?!
머신러닝과제하면서 계속 고민이었던 게 feature selection, engineering 이다.
- 범주형 피쳐의 카테고리가 너무 여러개일 때 어떻게 할까
- 범주형 피쳐를 one hot encoding, 가변수화 차이점은?
- 정규화는 꼭 해야하나?
- 변수선택을 어떻게 할까?
현재 결론은 이렇다.(우수과제도 참고하고, 서칭해보면 다른 좋은 방법이 있을 것 같다.)
1. 유사한 카테고리를 묶는다.
예시는 아래와 같다. 원래 6개 범주 -> 3개 범주
Everyone: 6세 이상
Everyone 10+ : 10세 이상
Teen : 13세 이상
Mature 17+ : 17세 이상
Adults only 18+ : 18세 이상
Unrated : 평가되지 않음
3단계로 재구성
Everyone/ Everyone 10+ Teen/ Mature 17+, Adults only 18+ (Unrated 데이터 1개 삭제)
def custom(COL) :
if COL=='Everyone':
return 'A'
elif COL=='Everyone 10+' or COL=='Teen':
return 'B'
else :
return 'C'
test["New_content_rating"] = test.apply(lambda x : custom(x["Content Rating"]) , axis = 1 )2. 범주형 피쳐를 one hot encoding, 가변수화 차이점
one hot encoding은 범주 갯수 만큼 피쳐가 생성되는 방법.
가변수화는 (범주갯수-1)만큼 생성.
회귀분석시에는 one hot encoding사용 시 선형종속, 다중공선성 문제때문에 두번째 방법을 사용한다.
그러나 대부분의 머신러닝, 딥러닝에서는 one hot encoding을 사용한다.
3. Scaling은 언제하나?
기본적으로 스케일링이 항상 필요한 줄 알았다.
그러나 트리기반 모델은 scaling, centuring이 필요없다.
모델 원리상 필요없다고 한다.
그러나 데이터간의 거리가 매우 중요한 knn 같은 모델을 scaling에 민감하다.
4. 변수선택
변수선택은 새로운 변수를 만드는 것이 아니라 원래 있는 변수중에서 중요한 것만 선택하는 것.
sklearn의 SelectKBest를 사용하면 편하다.
# target(Price)와 가장 correlated 된 features 를 k개 고르기.
## f_regresison, SelectKBest 불러오기.
from sklearn.feature_selection import f_regression, SelectKBest
## selctor 정의하기.
selector = SelectKBest(score_func=f_regression, k=20)
## 학습데이터에 fit_transform
X_train_selected = selector.fit_transform(X_train, y_train)
## 테스트 데이터는 transform
X_test_selected = selector.transform(X_test)
X_train_selected.shape, X_test_selected.shape