GoogleNet
GoogleNet은 Christian Szegedy가 발표한 논문이며 또다른 이름으로는
'Going Deeper with Convolutions'라고도 불립니다.
CNN 구조에 dropout, pooling, ReLu, GPU 기법이 적용된 AlexNet이 ILSVRC 2012년
대회에서 우승을 차지하고 CNN이 알려지게 되는데, 2년 뒤 Inception block이란 기술을
적용한 GoogleNet이 VGGNet을 이기고 ILSVRC 2014년에서 우승하게 됩니다.
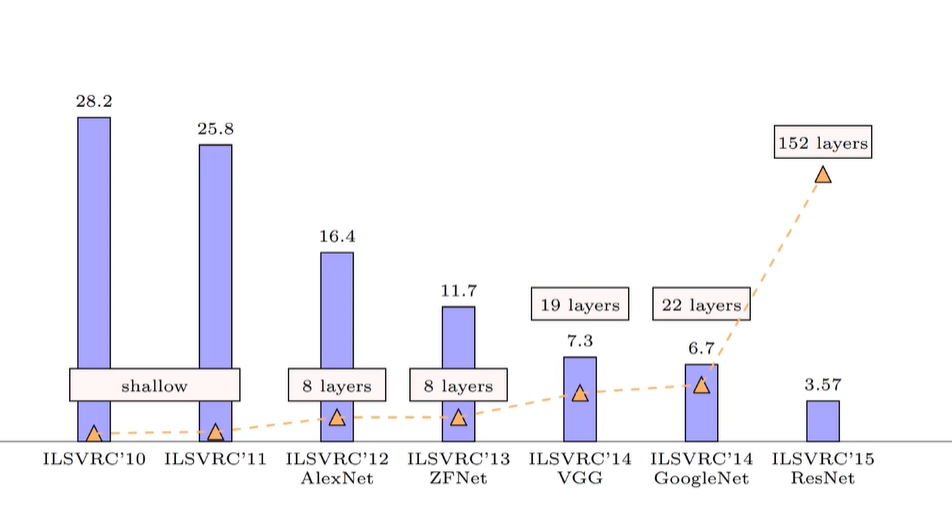
GoogleNet 배경
GoogleNet은 22개의 층을 가진 Deep neural network 입니다. 뉴럴 네트워크는
깊이와 넓이가 깊어지고 넓어질수록 더 높은 정확도를 얻을 수 있지만
두 가지의 큰 단점이 생기게 됩니다.
먼저 기하급수적으로 파라미터의 수가 증가하게 되고 결국 네트워크의 오버피팅과 병목현상을 야기합니다.
다음으로 메모리 사용량이 증가해 유한한 계산 용량의 효율적인 분배가 필요해집니다.
논문에서는 이 알고리즘을 메모리 용량이 제한되어 있는 컴퓨터나 모바일에 이식하기 위해
효율적인 네트워크를 만들어야 한다고 강조했습니다. 실제로 GoogleNet은 AlexNet보다
파라미터가 약 12배 적지만 정확도는 더 높은 모델을 구축하게 됩니다.
그래서 연산량은 1억 5000만번 이내로 구성하였습니다.
GoogleNet 구조
기존 모델들의 구성은 여러개의 convolution layer을 쌓은 다음 max pooling이나
Fully-connected layer을 그 위에 넣은 구조였습니다.
overfitting을 막기 위해 dropout을 적용하였으며 깊은 구조를 가지기 위하여 노력하였고
이전 논문들에서 MAX-pooling이 detection과 localization에 효과가 있음을 증명하였고
해당 논문 또한 pooling을 사용하였습니다.
1x1 convolution과 ReLu 활성화 함수 또한 사용되었습니다.
1x1 convolution layer은 병목현상을 해결하기 위해 차원 감소를 목적으로 도입되었으며
성능 저하 없이 네트워크의 크기를 증가시킵니다.
성능을 증가시키기 위해서는 모델의 크기를 키워야 하는데(깊이와 너비)
많은 파라미터로 overfitting에 취약하며 (고성능 모델에 적은 양의 training data 적용)
계산량이 많다는 단점을 지닙니다.
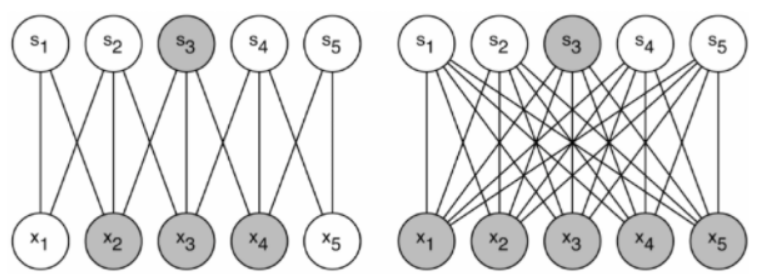
이같은 문제점을 해결하기 위해 고안한 방법이 기존 밀집한(dense) 연결들을
드문드문(sparse)나게 연결하는 것입니다.
논문에서는 sparse connection 을 통하여 dropout과 같은 오버피팅 방지를 기대하였으나
해당 시기 sparse connection 연산이 많이 연구되지 않아 매우 비효율적이었으며
100배정도의 연산이 줄었지만 cache missing과 오버헤드 등으로 사실상 dense와
거의 비슷한 성능을 보여주었습니다.
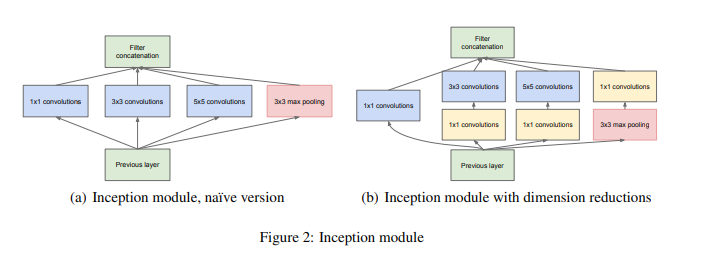
다음으로 inception module입니다.
계산량을 줄이기 위하여 3x3, 5x5 이전 1x1 필터의 사용으로 차원을 줄여주며
pooling 사용의 경우 localization, detection 등에서 좋은 성능을 보여주기 때문에 사용하였고,
max pooling 이후의 1x1 conv의 경우에는 pooling시 차원 축소가 되지 않으므로
pooling 한 결과의 차원을 적당량 사용해 주기 위해 구성합니다.
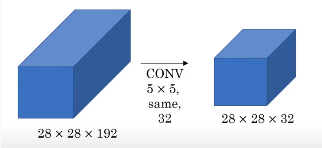
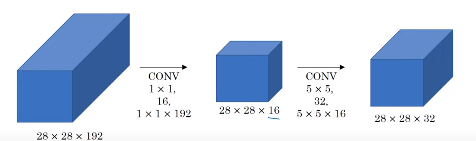
1x1 convolution layer의 연산량 감소를 보여주는 사진입니다.
상단의 경우는 28 x 28 x 192 x 5 x 5 x 32로 1억 2천만번의 연산이 필요하지만
하단의 경우는 (28 x 28 x 16 x 192) + (5 x 5 x 32 x 16)으로 약 1240만의 연산이
필요합니다.
사용된 inception module은 하단의 모델이며 총 22 layer로 구성되어 있습니다.
Deep network에서는 기울기 소실 문제가 발생할 수 있으므로
auxiliary classifiers 을 사용합니다
auxiliary classifiers : 중간중간 결과를 출력해 역전파를 통해 기울기를 역전파해
정규화 효과를 가지며 지나치게 영향을 주는 것을 막기 위하여 0.3을 곱한 값을 사용합니다. 4(a),4(b)에 위치하고 5 x 5(stride=3) average pooling 입력 사용, 70% dropout 시키며, 차원축소를 위한 128개의 1x1 filter 사용,
1024 Fully-connected layer , softmax 분류기를 가집니다
최종 결과에는 Global average pooling이 사용되며 결과로 top1 정확도가 0.6% 증가했습니다.
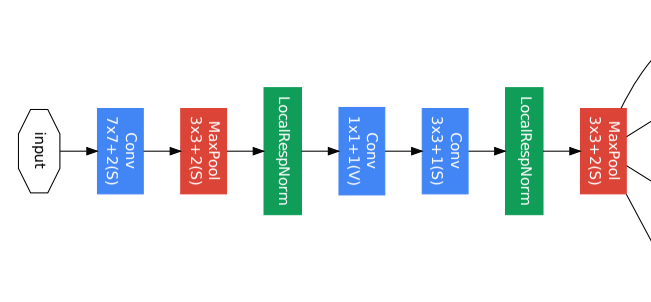
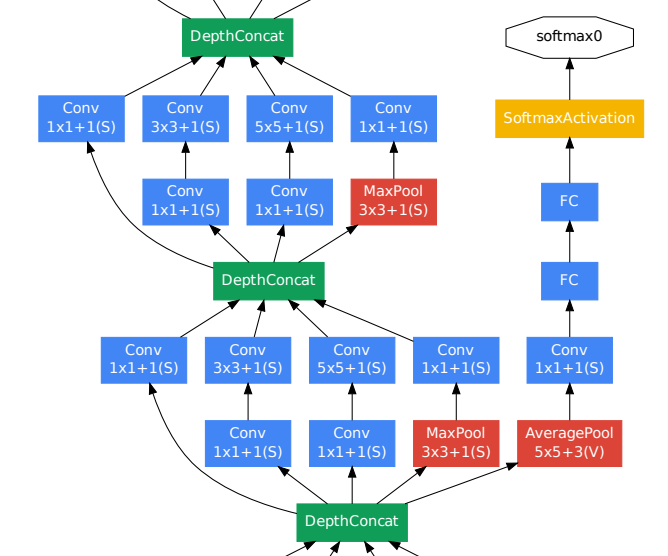
GoogLeNet의 구성 모습입니다.
low layer에는 cnn high layer에는 inception module이 적용되었으며
back propagation을 위한 auxiliary classifiers의 구성 또한 확인할수 있습니다.
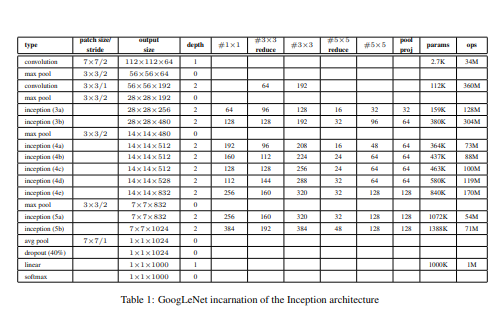
모델의 전반적인 구성 표입니다.
3x3 reduce 부분은 3x3을 최적화 시키기 위한 1x1의 채널 수 입니다.
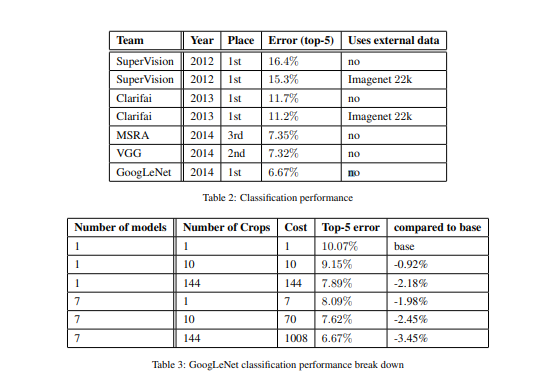
classification 부분 결과를 보면
120만개 training set , 5만개 validation set ,10만개 test set,
7개의 모델로 결합을 진행하였으며 총 4개(256, 288, 320, 352)로 잘랐습니다.
4개의 scale 에서 3장의 정사각형 이미지 선택(왼쪽,중앙,오른쪽)
각 정사각형 이미지에서 각 모서리 + 중앙2장 총 6장의 224x224 이미지 crop
좌우반전 총 1개의 이미지를 4x3x6x2=144개의 이미지로 추출합니다
GoogleNet 결과
Detection 부분에서도 뛰어난 성능을 가집니다.
2013년 대비 정확도가 약 2배 증가하였으며 Bounding box regression을
미리 훈련하지 않았음에도 뛰어난 성능을 보여줍니다. Deep insight가 가장 높은 정확도를
보여주긴 하지만 해당 방식은 결합 적용시 정확도의 차이가 거의 없는 것에 비해
GoogLeNet 방식은 앙상블을 진행하였을때 정확도가 큰 폭으로 개선되었습니다
