ResNet
AI 관련 논문 중에서 굉장히 유명하다고 알려져 있는 ResNet 논문입니다.
논문의 저자는 Kaiming He이며 마이크로소프트 연구팀에서 발표했습니다.
ResNet이 유명해진 이유는 발표되고 난 이후로 컴퓨터 비전 작업에서
정확도를 크게 개선시킬 수 있었기 때문입니다.
ResNet이 등장하게 된 배경
딥러닝 연구에서는 layer가 깊어지면 깊어질수록 모델의 정확도가 saturating되고,
학습 에러가 높아져 성능이 저하되는 문제가 발생합니다.
saturating (무언가 가득 차서 더 이상 진전이 없어져 버림)
그래서 저자는 네트워크의 깊이의 중요성에 대한 질문을 합니다.
더 나은 네트워크를 학습시키는 것이 더 layer를 쌓는 것보다 쉬운가?
라는 접근이였습니다.
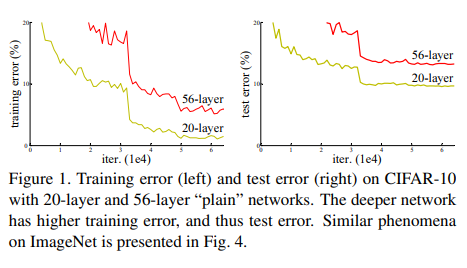
사진 왼쪽의 그래프는 training error, 오른쪽은 test error인데요,
layer가 더 깊은 빨간색 선이 에러율이 더 높은 것을 확인할 수 있습니다.
layer가 깊어지면 깊어질수록 기울기의 손실되거나 증가된다는 점이였습니다.
따라서 더 깊은 모델은 얕은 모델보다 높은 학습 에러를 생성하지 않아야 합니다.
그 문제점을 해결하기 위해 제시된 새로운 개념이
‘Deep Residual Learning’ 입니다.
layer에서 학습하는 양을 줄여 optimization 과정을 더 쉽게 만드는 방법입니다.
Deep Residual Learning
Residual(잔여) 네트워크의 기본 구조는 아래와 같습니다.
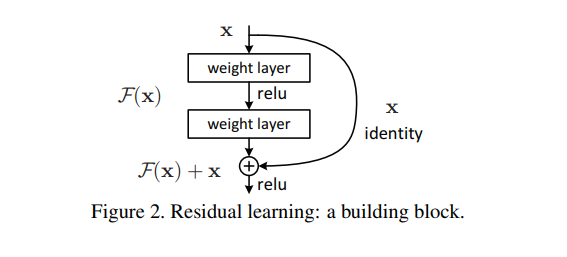
여기서 마지막의 F(x) + x는 identity 함수 h(x)와 Residual 함수 F(x)의 합에 대해
활성화 함수인 ReLU를 적용시킨 결과입니다.
Identity Mapping
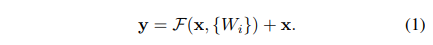
위의 그림에서 x는 바로 직전의 layer까지 학습된 값을 의미합니다.
shortcut mapping하는 h를 identity라 하고,
ReLU를 적용시키는 대상 f를 after-add mapping이라 이름붙입니다.
Residual learning을 수행하는 block들에 대해 shorcut connection 기법을 적용합니다.
위 Residual block을 통해 함수 h(x)를 identity mapping을 위한
short-cut connection이라고 부릅니다.
1개의 Residual Network만 보기 때문에 큰 차이가 없어 보이지만,
이를 여러 개 연결시킨다고 생각하면 addition 뒤에 오는 ReLU로 인해
Blocking이 일어나기 때문에 함수 f 처리를 꼭 해주어야 합니다.
따라서 f(x)+x 는 residual block에 속하는 layer들에 대한 학습 결과와 그 전까지
학습된 결과를 더해준 값입니다.
Shortcut connection
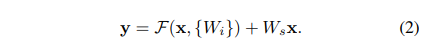
ResNet에서 layer는 Residual function F(x)=H(x)−x를 학습합니다.
그런 다음 이 x가 결과에 추가되며 이를 shortcut connection이라 합니다.
정리하면, 입력값 x를 출력값에 더하는 identity mapping을 수행해 기울기가 잘 흐를 수 있도록 지름길처럼 도와주는 것을 shortcut connection이라고 부릅니다
ResNet 구조

왼쪽은 VGG-19, 중간과 오른쪽은 VGG-19를 기반으로 설계된 plain network, residual network 입니다.
오른쪽의 ResNet을 보면 input/output dimension이 다른 경우는 점선으로 표현됩니다.
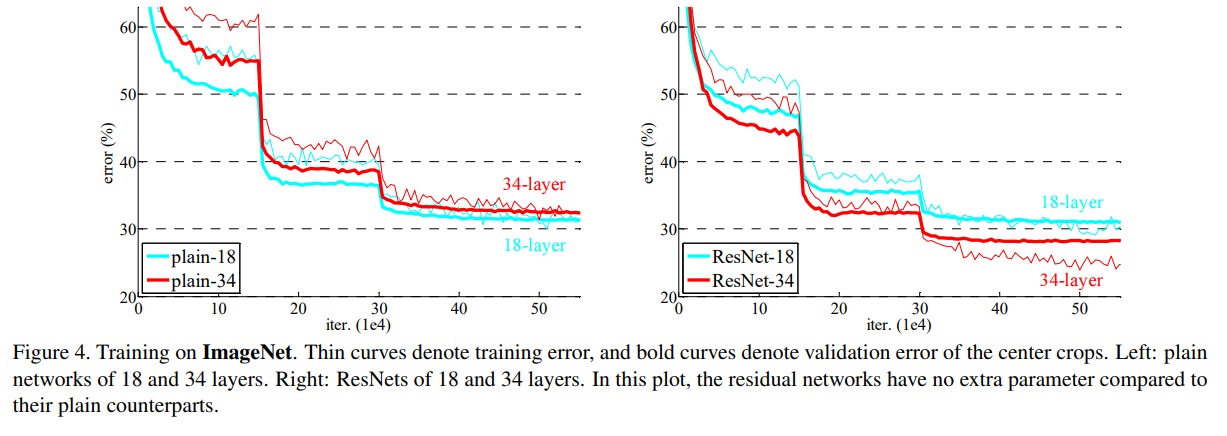
이미지넷 데이터셋을 바탕으로 실험한 결과이며 ResNet layer의 수에 따라 에러가 낮아짐을 확인할 수 있습니다. Figure 1과 비교하면 layer가 더 깊어졌지만,
error가 낮아지는 결과의 성능을 보여주고 있습니다.
Bottleneck Architectures
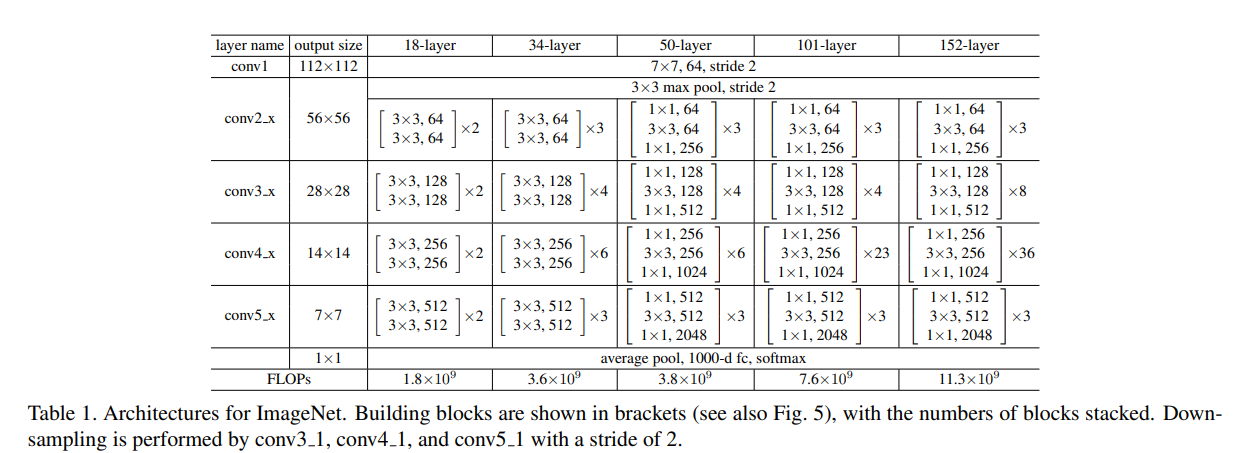
ResNet은 위 사진을 통해 확인해볼 수 있듯이, 18-layer부터 152-layer까지 layer를
점점 더 깊게 쌓았습니다.
layer가 더 깊어지면 dimension의 크기가 커집니다. 그러면 parameter 수가 많아지게 되고, 복잡도가 증가합니다.
이를 해결하기 위한 아이디어가 bottleneck architectures(병목 아키텍쳐)입니다.

병목 아키텍쳐는 필터의 사이즈를 1x1 사이즈를 사용합니다.
1x1 filter를 사용하여 dimension의 크기를 줄인 후에
다시 1x1 filter를 사용하여 dimension의 크기를 늘립니다.
위 그림에서 왼쪽과 오른쪽은 각각 64, 256 크기의 dimension이 input으로 들어옵니다.
하지만 ResNet의 경우 병목 아키텍쳐를 이용하기 때문에 두 그림의 time complexity는 비슷하게 맞춰집니다.
따라서 ResNet은 layer의 수가 많아지더라도 모델의 크기가 다른 모델에 비해 작습니다.
정리
논문의 저자는 classification 이외에 여러가지 computer vision task의 실험을 한 결과를 보여줍니다.
일반적인 CNN은 layer가 깊어질수록 오히려 error가 증가하는 모습을 보여주었는데
residual learning을 도입한 Deep residual learning framework을 통해 깊이가 증가함에 따라 error가 감소하고 plain network보다 훨씬 더 좋은 성능을 보여줍니다.
결론적으로 ResNet은 이전 model보다 더 깊은 layer를 가지지만,
parameter수는 적으므로 속도는 빠르며 성능면에서도 더 뛰어남을 입증했습니다.
