경영통계에선 이런 느낌으로 과제가 나온다고 한다.
앞으로도 종종 볼 일이 있을 것 같아서 관련해서 기록해두기로 하였다.
저런 식으로 xlsx 형식의 파일을 이용해 신뢰구간을 구한다거나, T-test를 위해 p-value를 구하려 할 때 알아두어야 할 것이 있다.
import pandas as pd
import numpy as np
import scipy.stats as st
xlsx = pd.read_excel("data.xlsx")이렇게 엑셀 파일을 pandas 를 이용해 읽어오면, 첫 번째 시트만 읽게 된다.
엑셀 파일의 특정 시트의 데이터를 읽어오고 싶으면 sheet_name = [읽어오고 싶은 시트의 번호 또는 '이름'] 을 추가해준다.
import pandas as pd
import numpy as np
import scipy.stats as st
xlsx = pd.read_excel("data.xlsx", sheet_name = [ 2, 'lightbulbs', 4, 5])데이터를 읽어왔으면 t-test를 해보자.
import scipy.stats as stimport한 scipy.stats의 ttest_1samp() 또는 ttest_ind() 함수를 사용하면 간단하게 t-test가 가능하다.
t-test는 sample의 차이가 실제 모집단의 차이가 있음을 의미하는지? 검증하는 방법이다.
이 함수는 t-statistic과 p-value를 리턴한다.
t-statistic의 값이 중심에서 멀어질수록 귀무가설을 기각할 가능성이 커진다.
p-value는 어떤 결과가 정말 우연히 나올 확률이라 할 수 있다.
즉, (significance level α가 0.05이라고 할때) t-statistic이 커져서 p-value가 0.05보다 작아지면 우연히 그런 차이가 날 확률이 0.05보다 작기 때문에 95%의 확률로 귀무가설을 기각할 수 있는 것이다.
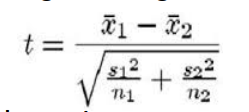 t-statistic
t-statistic
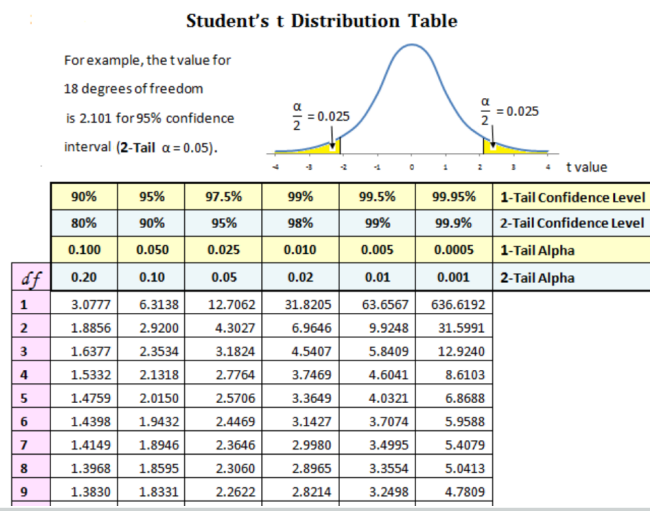 (그래프에서 가로 축은 t-statistic, 세로 축은 p-value)
(그래프에서 가로 축은 t-statistic, 세로 축은 p-value)
ttest_1samp() 함수는 단측검정, ttest_ind() 함수는 양측검정 시 사용한다.
data = xlsx['lightbulbs']
# H0(null hypothesis) : life tiem <= 1000
st.ttest_1samp(data['Lifetime'], 1000, alternative = 'greater')귀무가설 : 전구 수명의 평균이 1000시간보다 짧거나 같다.
대립가설 : 전구 수명의 평균이 1000시간보다 길다. (alternative='greater')
data = xlsx[5]
# H0(null hypothesis) : Score_Before = Score_After
st.ttest_ind(data['Score_Before'],data['Score_After'], equal_var=True)귀무가설 : 교육 이후 점수의 평균과 이후 점수의 평균의 차이가 없다. (equal_var=True)
대립가설 : 교육 이후 점수의 평균과 이후 점수의 평균의 차이가 있다.
참조
