올해 개발 쪽 진로를 제대로 고민해보고 싶어서 휴학을 했다. 올해 초에는 게임 개발도 잠깐 공부했었고, 자연어처리 딥러닝 수업도 수강해봤다. 이후 알고리즘 문제만 계속 풀다 음성인식쪽에 관심이 생겨 TTS 모듈에 대해 공부하는 시간을 잠깐 가져봤다.
깃허브를 잘 못 다룰 때라 정리가 안 되어있긴 하지만 올해 정리한 프로젝트(1)이다. GTTS와 speechrecognition등을 이용해 이어폰 마이크를 통해 말하면-> 말한 내용을 받아 텍스트로 정리하고 -> 관련된 대답을 mp3로 변환해 출력하는 아주 간단한 프로그램이다. 이것저것 공부한 모듈이 그냥 다 들어있어서 따로 리뷰는 안 할 예정이다.
2022 toy project 2
Chatbot with voice synthesis/generation using GTTS module
0. 기획
첫번째 프로젝트를 진행하면서 공부했었던 GTTS모듈을 딥러닝 챗봇에 활용하고 싶어져서 이번 프로젝트를 기획하게 됐다. 목표는 간단한 대화가 가능한 파이썬 딥러닝 챗봇 구현 + 답변을 음성으로 출력하는 기능 추가 삽입이었다.
1. 딥러닝 챗봇의 작동방식 공부
올해 여름에 수강했던 강의에서 배운 transformers모듈과 다른 언어모델, optimizer등의 기초 용어와 이론에 대해 복습하는 시간을 가졌다.
용어나 이론 관련 정리는 노션에 해둬서(...) 링크를 첨부. 나중에 기회가 된다면 다시 공부해서 여기에 정리해둬야겠다.
https://thdgml33o.notion.site/7-14-Transformer-ec9f3b0bdad34b44a2c172c874d91865
2. 필요한 모듈 찾기
GTTS를 제외하고 음성 출력 기능을 수행할 모듈 등을 추가로 검색해야했다. 기존 프로젝트(1)에서는 playsound 를 import해서 사용했으나, 후에 구글 코랩등에서 작동시키니 로컬환경에서 나지 않았던 오류들이 다수 발생해 여러번의 구글링을 통해 Ipython의 audio를 import해서 사용했다. 아래 서술 예정. 딥러닝 프레임워크로는 Pytorch를 사용했다.
3. 코딩하기
- Google TTS : https://gtts.readthedocs.io/en/latest/module.html
- KoGPT2 : https://github.com/SKT-AI/KoGPT
- Korean conversation dataset : https://raw.githubusercontent.com/songys/Chatbot_data/master/ChatbotData.csv
다른 언어로 딥러닝 챗봇을 먼저 구현해봤던 친구에게 물어보니 GPT3를 사용했다는 답변을 들었다. 강의는 BERT모델에 관한 내용이었기 때문에 BERT를 쓸지, GPT를 쓸지 고민하다 한국어에 특화된 koGPT를 사용하기로 했다. koGPT쪽이 내가 이해하기 조금 더 쉬워서(자료가 잘 나와서..) koGPT를 선택했다.
4. 에러 고치기
사실상 에러때문에 이 글을 쓰고 있었는데 생각보다 서론이 너무 길어졌다. 로컬환경(파이참)에서 먼저 딥러닝 챗봇을 구현하는 과정에서 발생했던 에러들(1)과 데이터셋의 크기때문에 구글 코랩으로 옮기는 과정에서 발생했던 에러들(2)에 대해서 써보려고 한다. 자잘한 에러들 말고 고치는데 신경쓰였던 것들만 간단히 정리.
4-1-1. tokenizer class is not the same type
코드C:\Users\user\anaconda3\envs\toy2\python.exe C:/Users/user/PycharmProjects/toy2/importLibrary.py
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'GPT2Tokenizer'.
The class this function is called from is 'PreTrainedTokenizerFast'.를 입력하세요이건 사실 에러까진 아닌데 tokenizer를 다른 걸 쓰고 있다는 메시지였다. 딱히 문제가 되지 않는 것 같아..? 일단 뜨는 대로 놔두고 구현했더니 결과가 나와서 일단 보류해뒀다.
4-1-2. module not found
모듈 설치의 문제. 설치되지 않은 모듈은 anaconda3 cmd에서 명령어 pip install ~로 설치해줬다. 구글 코랩에서는 !pip install~.
4-2-1. RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
해결하기 제일 까다로웠던 에러.
데이터셋때문에 로컬환경에서 구글코랩으로 옮기는 도중 발생한 에러였다. 내 노트북에 GPU가 없기 때문에 GPU를 쓰는 코랩에서 쓰려면 코드를 수정해줘야 했다. 그래서
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)를 해줬는데 런타임 에러가 자꾸 떴다. 무슨 에러인지는 알겠는데 to("cuda:0")를 해주고서도 에러가 자꾸 떠서 이 에러 고치는데 시간이 가장 오래 걸렸다. 관련 에러 다 찾아봤는데 안 고쳐져서 정말 슬펐던 친구...
질문 올리고 받은 답변으로 해결 완료. 학습과정에서 batch와 같은 변수들도 gpu에 전부 올려줘야 하는 거였다. 어떤 변수를 GPU에 올려야 하는지 몰라서 고치기 어려웠던 에러.
gen = Trainer.tokenizer.convert_ids_to_tokens(torch.argmax(pred, dim=-1).squeeze().cpu().numpy().tolist())[-1]그렇지만 numpy계산은 gpu에서 안돌아가니 cpu를 써서 계산하도록 수정해줘야한다.
4-2-2. about voice generation
위에 서술했던 것처럼 프로젝트(1)에서는 playsound모듈을 이용해 간단하게 생성한 음성을 출력하는 것이 가능했다. 그런데 왜인지 몰라도 코랩에선 또 실행이 안 되더라...^^ pyglet, pygame등의 모듈을 이용하려다 파이썬 버전의 문제등이 자꾸 겹쳐서 Ipython 모듈을 다운받아 audio를 import해서 출력했다.
from IPython.display import Audio
def reply(text, a): #a=fileNum Count
tts = gTTS(text=text, lang='ko')
fileName = text+str(a)+'.mp3'
tts.save(fileName)
respond = Audio(fileName, autoplay=True)
display(respond)
5. 코랩-깃허브 연동하기
https://velog.io/@shong676/Colab%EA%B3%BC-GitHub-%EC%97%B0%EB%8F%99%ED%95%98%EA%B8%B0
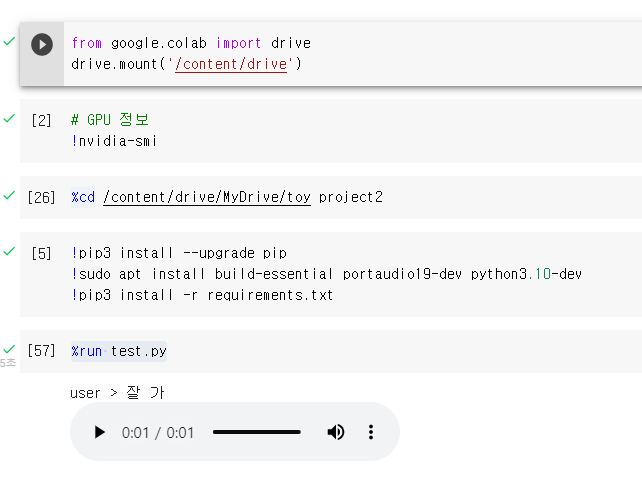
결과 화면.
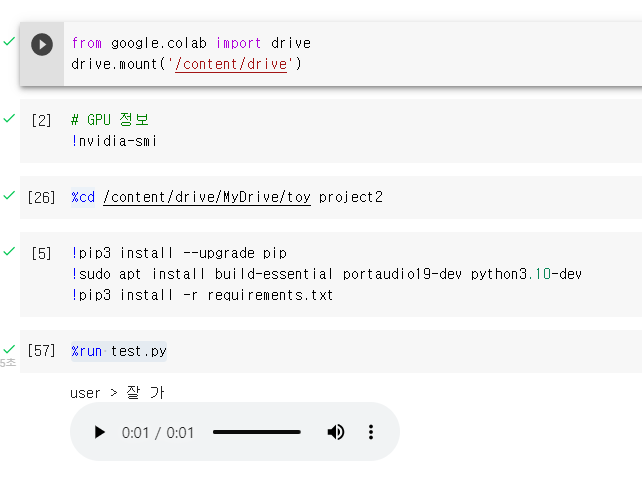
여기서 테스트를 진행해 볼 수 있다.
6. 마치며
-
배운 것을 만들고 싶은 것에 적용하다는게 정말 어렵다는 걸 다시금 깨달았다. 딥러닝 분야는 아무래도 계산량이 현저하게 많다보니 GPU로 진행하는게 편할테니 구글 코랩에도 더욱 익숙해져야겠다. 깃허브 관련해서는, 혼자 작업하는 프로젝트 말고 여러 명이 작업하는 프로젝트를 거치면서 형상관리에 익숙해지고 싶다. 아직 기능을 많이 쓸 수 있지 못해 늘 아쉽다.
-
챗봇의 성능을 높이는 방법에 대해서도 추가적으로 알아봤는데 현재로서는 데이터셋 크기를 늘리는 것이 가장 최선인것 같다. 살짝 주제를 빗나가는 듯한 답변이 꽤 자주 나와서 fine tuning을 다시 진행해볼까 생각중이다. 모델이나 tokenizer등도 바꿔가며 테스트를 더 진행해보고 싶지만 일단은 KoGPT로.
-
transformers 모델 관련해서 추가적인 공부를 더 해야겠다는 생각이 든다. 언제나 이론을 실전에서 써보는 과정이 제일 어렵다. 관련해서 GTTS말고 다른 API도 써 보고 싶은데 다른 API들은 제휴(카카오)나 유료시간제다. 주제나 작동방식에 조금 익숙해지면 다른 API도 활용해봐야겠다.
-
음성인식 관련해서 다른 프로젝트도 올해가 가기전에 하나 더 진행해보고 싶다. 개인이 할 수 있는 음성'인식'관련 프로젝트가 없을까? 조사해본 바로는 많은 데이터가 오차없이 정확해야 한다는데, 프로젝트(1)를 진행하면서 주변 소음이 많은 환경에서 발음이 상대적으로 부정확한 내가 얘기하니 GTTS가 쉽게 알아듣지 못했었다. 프로젝트(2)에서 인식 기능을 아예 빼버린 이유이기도 하다. 조금 더 자료조사 과정을 거치고 다음 프로젝트를 빨리 진행해보고 싶다.
-
그래도 혼자서 재밌게 만들었다.
7. references & studies
KoGPT2 쓴 챗봇 결과물 확인(웹으로 구현한 곳이 있었다)
[HuggingFace] Tokenizer의 역할과 기능, Token ID, Input ID, Token type ID, Attention Mask
