
이번장에서는 Airflow를 효과적으로 사용하는 방법을 사례를 통해 알아보자.
1. 깔끔함 DAG 작성
DAG를 구성하는 태스크는 시간이 지남에 따라 점점 복잡해질 수 있습니다.
최초 작성 이후 많은 수정을 거치며 기능이 추가될수록 지나치게 복잡해지거나 가독성이 떨어질 수 있습니다.
👉 개발자들 간에 코드 작성 규칙 통일이 필요합니다.
DAG 코드를 구조화하고 코드 스타일 규격화 등을 통해 가독성을 높일 수 있습니다.
구체적 방법을 알아봅시다.
1) 스타일 가이드 사용
- 스타일 가이드 규정
PEP8 스타일 가이드 및 구글과 같은 회사의 가이드를 포함하여 조직에서 사용할 수 있는 여러 스타일의 가이드를 참조하여 대표적으로 들여쓰기, 최대 줄 길이, 네이밍 등에 대한 스타일 가이드를 규정하여 사용할 수 있습니다.

- 정적 검사기를 통한 코드 품질 확인
코딩 규칙 및 스타일가이드 준수 여부를 확인할 수 있는 소프트웨어 도구 사용
가령, pylint 및 flake8 사용하여 정해진 기준을 얼마나 잘 지키는지 확인
pip을 통해 쉽게 설치 후 사용가능.


두 도구는 사용자의 선호도에 따라 특정 검사를 활성화/비활성화 구성할 수 있으며,
두 도구를 통해 포괄적인 피드백을 받길 원할 경우 같이 사용하기도 함.
- 코드 포맷터
앞선 소프트웨어는 코드 형식을 잘 따랐는지 검사해주는 도구였다면,
코드 포맷터는 지정된 형식으로 코드를 수정해주는 도구입니다.
가령, YAPF와 Black이 대표적입니다.
이 또한 사용자 선호도에 따라 vscode, pycharm 등 많은 편집기를 지원하여 코드를 보다 쉽게 포맷에 맞게 변경할 수 있고, --check 플래그를 사용하여 검정 테스트만 수행할 수도 있습니다.
이 또한, pip을 통해서 쉽게 설치해서 사용가능합니다.


- Airflow 전용 코드 스타일 규칙
앞선 규칙은 파이썬 코딩 스타일에 입각해 코드 규칙이나 변경, 테스트 등에 대하여 말하였는데 이는 Airflow 코드의 스타일 규칙에 대하여 이야기합니다.
Airflow는 동일한 결과를 내는 메소드/방법이 여러개 존재하는 데 그 경우 코드 작성자가 여럿일 경우 선호도에 따라 작성하게되면 여러 방법이 혼합되게 됨으로써 복잡해보이고 가독성이 떨어지게 됩니다.

둘다 DAG를 정의하는 것이지만 여러 방법이 있고 한 파일 내 여러 DAG 정의문을 혼합하여 사용할 경우 위의 문제의 상황이 발생합니다.
따라서, 조직내에서 일관된 스타일을 유지할 수 있게끔 여러 방법이 제공되는 Airflow 메소드에 대해 어떤 방법을 사용할 지에 대한 사전 규칙을 정하고 따르는 것을 권장합니다.
2) 중앙 자격 증명 관리
DAG는 다양한 시스템, 외부 시스템과 상호 작용하여 사용합니다.
가령, 데이터베이스, 클라우드 스토리지 등 이러한 서비스를 사용할 때 자격 증명을 요하는 경우가 있기에 자격 증명을 관리해야합니다.
Airflow를 사용하면 이러한 자격증명에 대해 Airflow의 연결 저장소에 관리할 수 있습니다. 정보들을 중앙위치에서 안전한 방식으로 유지되도록 보장해주며 사용자 작성 코드에서 연결 저장소를 사용하여 자격증명을 가져와서 작업가능합니다.
Airflow 내장 오퍼레이터 뿐만 아니라 사용자가 작성하는 코드에 대해서도 Airflow 연결 저장소 사용이 가능하며, 이를 사용하지 않고 DAG 자체나 외부 구성 파일에 보안 키를 하드 코딩하는 방법도 있겠지만 이에 비해 수고로움이나 안전성이 더 보장됩니다.

즉, 모든 자격증명과 관련된 내용이 모두 한곳에서 관리될 수 있습니다.
3) 구성 세부 정보 일관되게 지정
앞선 자격증명 외에도 파일 경로 등과 같이 DAG 구성 정보로 전달해야하는 매개변수가 있다.
DAG는 파이썬으로 작성되므로 구성정보 전달방법도 전역변수, 구성파일, 환경 변수 등 다양하다.
Airflow Variables를 사용하여 메타스토어에 구성정보를 저장할 수 있습니다.
- 구성파일 yaml으로 구성 정보 전달하기

- Airflow Variables

위의 코드는 스케줄러가 DAG 정의를 읽어올 때마다 Airflow가 데이터베이스에서 변수를 매번 호출하기 때문에 비효율적입니다.
👉 구성정보는 DRY원칙에 따라 단일위치에 저장하기
DAG 간에 구성정보를 공유하는 경우가 있는데, 한쪽에서 구성 값을 변경하고 다른 곳에서 변경하지 않는경우 문제가 발생할 수 있습니다.
따라서, 공유되는 구성정보는 DRY(don't repeat yourself)원칙에 따라 단일위치에 구성값을 저장하는 것이 좋습니다.
👉 구성옵션은 DAG내에 참조되는 위치에 따라 다른 콘텍스트에 로드될 수 있다.
- main 부분에 로드
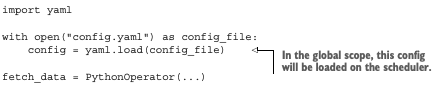
구성파일(config.yaml)이 Airflow 웹 서버나 스케줄러를 실행하는 호스트의 로컬 파일시스템에서 로드됩니다. 따라서, 두 호스트는 구성파일에 대한 접근 권한이 있어야합니다, - 태스크의 일부로 로드

태스크 영역에서 구성내역이 워커에 로드됩니다.
Airflow 워커가 해당함수를 실행하면 Airflow 워커의 콘텍스트에서 호출됩니다.
이렇게 구성방법에 따라 완전히 다른 환경(파일 시스템 엑세스 권한 등)에 구성됨으로 잘못된 결과가 발생하거나 태스크 실패가 생길 수 있으므로 유의해야합니다.
따라서, 자신에게 잘 맞는 하나의 구성 방식을 선택하고 DAG 전체에서 동일한 접근 방식을 고수하여 이러한 상황을 피하는 것이 좋습니다.
4) DAG 구성 시 연산 부분 배제
Airflow DAG는 파이썬으로 작성되므로 작성에 유연성이 높습니다.
그러나, DAG 동작정보를 파악하거나 변경사항을 적용하려면 DAG 파일을 실행시켜야합니다.
따라서, DAG 파일을 반복시키면서 내용을 파악해야한다면 DAG 파일을 로드하는 데 오래걸리는 경우 문제가 발생할 수 있습니다.
가령, 장기간 실행 또는 과도한 계산 수행
👉 해결방법
- 실제 계산이 필요한 시점에만 해당 태스크 실행
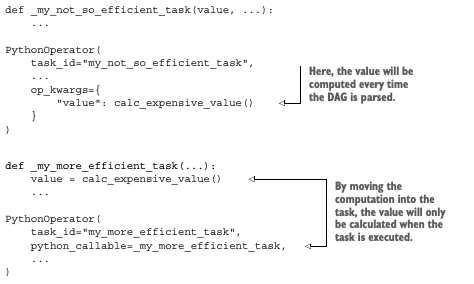
- 실행에 필요할 때만 자격증명을 가려오는 훅/오퍼레이터 작성
개발 요함. 가령, DAG 파일 안에서 구성 정보를 외부 데이터 소스 또는 파일 시스템으로부터 로드하는 경우.
Airflow 메타스토어로부터 자격 증명을 로드하고 몇가지 태스크를 통해 자격 증명을 공유

위 방법은 DAG가 구문 분석될 때마다 데이터베이스에서 자격 증명을 가져오므로 반복적으로 요청이 발생하게되므로 비효율적입니다.
이는 자격증명 가져오기 태스크가 실제로 동작하는 시점으로 연기하여 해결할 수 있습니다.

이렇게 하면 태스크가 실제로 실행될 때만 자격증명을 가져오므로 더 효율적으로 동작합니다.
다음처럼 실수로 DAG 정의에 계산을 포함시키는 '연산의 늪'을 피하기 위해서는 DAG 작성 시점에 주의 깊게 고려해야합니다.
5) factory 함수를 사용한 공통 패턴 생성
DAG를 조금씩 수정하면서 새로운 DAG를 계속 생성하는 경우가 있습니다.
유사한데 동일한 과정과 변환이 필요하여 많은 DAG에 걸쳐서 반복처리되는 공통적인 데이터 처리가 회사에서는 많이 필요할 수 있습니다.
이러한 경우 공통 DAG 구조를 생성하는 프로세스의 속도를 높일 수 있는 factory 함수를 사용합니다.
factory 함수의 기본 개념은 각 단계에 필요한 구성을 가져와서 해당 DAG나 태스크 세트를 생성하는 것입니다.

다른 구성값으로 태스크 집합을 생성하고 DAG 인스턴스를 전달하여 태스크를 DAG에 연결하면 똑같은 구성의 DAG를 여러 세트 생성할 수 있습니다.
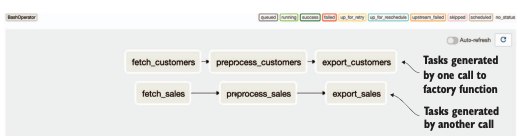
위는 factory 함수를 사용한 반복 태스크 패던이 생성되었습니다.
factory 함수를 이용한 구성 내역을 토대로 거의 동일한 태스크가 포함되어 있습니다.
하나의 DAG 파일을 사용하여 여러 DAG를 생성할 수도 있습니다.

for문의 다른 구성으로 여러 DAG를 생성하빈다.
이 DAG가 서로 덮어쓰여지지 않도록 고유 이름을 할당하기 위해 {}를 사용하였습니다.
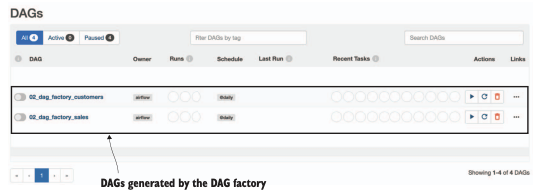
DAG factory 기능을 사용하여 단일 파일에서 생성된 여러 DAG들 입니다.
그러나 이런식으로 하나의 DAG 파일에 여러 DAG를 생성할 대는 한 파일에 여러개가 구성되어있는 것을 예상하지 못하면 차원의 늪같은 패턴에 당황할 수 있으니 주의해야합니다.
이렇게 DAG 파일에 여러 DAG가 있는 것을 쉽게 파악하고 보기위해 태스크 그룹을 사용할 수 있습니다.
6) 태스크 그룹
복잡한 DAG 구조를 체계화하기 위해 Airflow2에서는 태스크 그룹이라는 새로운 기능을 도입하였습니다.
태스크 그룹을 사용하면 태스크 세트를 더 작은 그룹으로 효과적으로 그룹화하여 DAG 구조를 보다 쉽게 관리하고 이해할 수 있습니다.
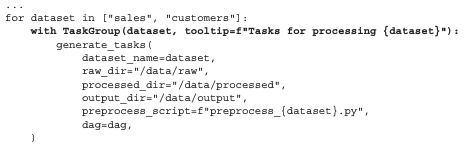
sales와 customers 데이터 세트에 대해 생성된 태스크 세트를 두개의 그룹으로 효과적으로 그룹화하는데, 각 데이터 세트마다 하나의 태스크 그룹을 만듭니다.
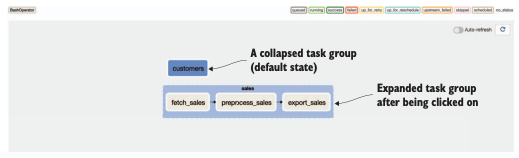
축소된 태스크그룹을 클릭 시, 태스크 그룹의 확장 구조를 볼 수 있습니다.
태스크 그룹 기능은 더 복잡한 경우에 시각적 복잡성을 감소시키는 데 효과적으로 쓸 수 있습니다.
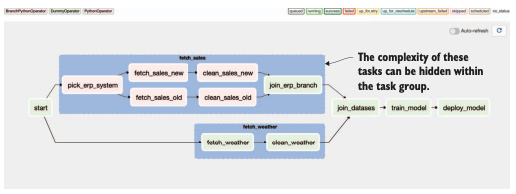
7) 대규모 수정
DAG가 실행하면 실행 인스턴스가 스케줄러 데이터베이스에 포함됩니다. 그런데 시작날짜, 스케줄 간격 등과 같은 DAG의 큰 변경이 발생하면 스케줄러가 의도한 대로 동작하지 않을 수 있습니다.
따라서, 이러한 대규모 수정이 발생하는 DAG를 복사하여 새로운 이름으로 다시 배포해야합니다.
그래서 DAG에 대한 버전관리 기능은 현재 Airflow 커뮤니티에서 강력하게 요구하고 있다고 합니다.
2) 재현 가능한 태스크 설계
DAG를 효과적으로 잘 설계하고 짜는 것도 중요하지만,
Airflow DAG를 작성하는 데 있어 큰 과제 중 하나는 태스크 재현 가능하도록 설계하는 것입니다.
재현 가능한 태스크라는 것은 언제 실행해도 동일한 결과를 산출해야한다는 것입니다.
1) 태스크 멱등성
Airflow 태스크의 특징은 항상 멱등성을 가지고 있다는 점입니다.
동일한 태스크를 여러번 실행해도 결과는 동일해야합니다.
왜냐하면, Airflow, 사용자가 태스크를 다시 실행하는 경우가 많이 때문입니다.
이렇게 다시 태스크를 실행할 떄 앞서 출력된 데이터를 덮어 쓰도록 멱등성을 강제할 수 있습니다.
이 경우에도 해당 태스크의 부작용을 신중하게 고려하여, 태스크의 멱등성을 해치는 요소가 있는지 확인해야합니다.
2) 태스크 결과는 결정적
태스크는 결정적일 때만 재현할 수 있습니다.
태스크는 주어진 입력에 대해 항상 동일한 출력을 반환해야한다는 말입니다.
데이터 세트 명시적 정렬, 렌덤 임의성을 막고자 랜덤 시드 설정 등으로 이러한 비결정적 함수의 문제를 방지할 수 있습니다.
3) 함수형 패러다임
함수형 프로그래밍은 결과를 반환하지만 어떤 부작용도 포함하면 안된다는 것을 말합니다.
부작용이라 함은 결과의 차이를 의미합니다.
즉, 멱등적이고 결정적이라고 할 수 있습니다.
이러한 제약을 적용하여 멱등성 및 결정론적 태스크의 목표를 달성하여, DAG 및 태스크를 재현 가능하게 만들 수 있습니다.
3) 효율적인 데이터 처리
대량의 데이터를 처리하기 위한 DAG는 가장 효율적인 방식으로 처리하도록 신중하게 설계해야합니다.
대용량 데이터를 효율적으로 처리하는 방법을 알아봅시다.
1) 데이터의 처리량 제한
원하는 결과를 얻는 데 필요한 최소한의 데이터로 처리를 제한하는 것입니다.
모든 데이터 소스가 필요한지 판단하여 사용되지 않는 행과 열을 삭제하여 데이터 세트의 크기를 줄입니다.
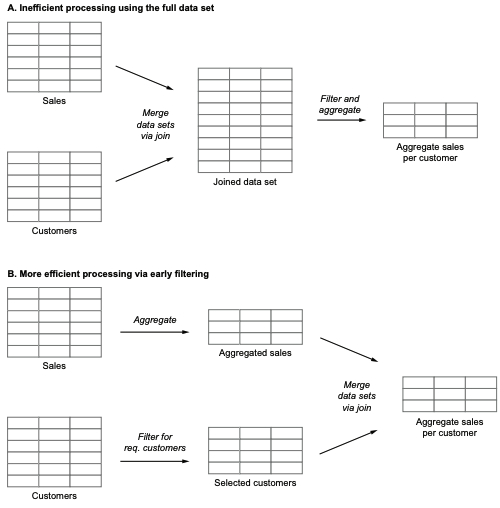
가령 특정 고객에 대한 제품의 월별 판매량을 계산하는 데이터 프로세스라면
두 데이터 세트를 조인하고 집계하는 것보다
필요한 데이터를 먼저 필터링하고 조인하여 집계한다면 계산을 더 효율적으로 만들 수 있습니다.
2) 증분 적재 및 처리
효율적인 집계 또는 필터링으로도 데이터 세트의 크기를 줄일 수 없는 경우가 많다.
데이터의 증분 처리를 적용하여 각 처리 실행 단계에서 수행해야 하는 처리량을 제한할 수 있는데 대포적으로 시계열 데이터 세트에 많이 적용한다.
증분처리의 기본 아이디어는 데이터를 시계열 기반 파티션으로 분할하고, 이러한 파티션을 각 DAG 실행에서 개별적으로 처리하는 것입니다.
각 증분 실행의 결괏값을 결과 데이터 세트에 추가하게되면, 시간이 지나고 나면 전체 데이터 세트가 만들어질 수 있습니다.
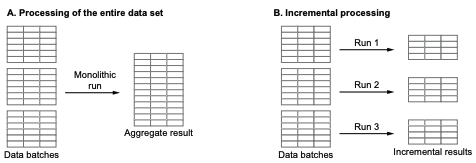
증분 처리 설계의 가장 큰 장점은 실행 중 일부 과정이 오류가 생길 경우 처음부터 다시 실행할 필요없이 실패한 부분만 다시 실행해주면 됩니다.
3) 중간 단계 데이터 캐싱
데이터 처리 워크플로에서 DAG는 여러 단계를 구성되는데, 각 단계에서는 이전 단계의 결과 데이터에 추가 작업을 수행합니다. DAG를 명확한 세부적 단계로 분할하여 실행 중에 오류가 발생하면 오류가 발생한 부분만 다시 실행할 수 있다는 장점이 있습니다.
그러나 이러한 DAG 모든 단계를 효율적으로 다시 실행할 수 있으려면 해당 단계에 필요한 데이터를 즉시 사용할 수 있는지 확인해야합니다.

각 단계 데이터를 저장하면 각 태스크를 다른 태스크와 독립적으로 쉽게 다시 실행할 수 있습니다.
중간 단계의 데이터 캐싱을 하기에 대규모 데이터 세트가 여러 중간 버전이 있는 경우에는 과도한 스토리지가 필요합니다. 👉 제한된 기간의 중간 단계 데이터 세트만 유지하는 절충안 👉 개별 태스크 재실행 시 특정 기간으로 제한된다.
👉 가장 원시 버전의 데이터를 항상 사용 가능하도록 보관하는 것이 좋다고 합니다.
원시 데이터 사본을 별도로 보관하면 필요할 때마다 항상 다시 처리할 수 있습니다.
4) 로컬 파일 시스템에 데이터 저장 방지
Airflow 작업 내에서 데이터를 처리할 때, 중간 단계 데이터 로컬 파일 시스템에 저장해야 하는 경우가 있습니다. 특히 Airflow 워커 내에서 지역적으로 실행되는 오퍼레이터를 사용할 때 발생하는 데, 로컬 파일 시스템에 쉽게 엑세스할 수 있기 때문입니다.
로컬 시스템 파일 저장은 다운스트림 태스크가 파일에 접근하지 못할 수 있다는 단점이 있습니다.
Airflow가 다중 태스크를 병렬로 처리 다중 워커에 테스크를 실행하기 떄문에 워커는 다른 워커의 파일 시스템에 접근할 수 없으므로 데이터를 읽어올 수 없는 겁니다.
이러한 문제를 방지하고자 모든 Airflow 워커에서 동일한 방식으로 액세스할 수 있는 공유 저장소를 사용합니다. 동일한 파일 URl과 자격 증명으로 액세스할 수 있는 공유 클라우드 스토리지 버킷에 저장하는 것입니다.
5) 외부 시스템으로 작업 이전
Airflow는 실제 데이터 처리를 위해 Airflow 워커를 사용하는 것보다 오케스트레이션 도구로 사용할 때 더 효율적입니다. 앞 장에서도 배웠지만 데이터 세트가 커질 수록 그렇습니다.
따라서, 태스크 유형의 작업에 가장 적합한 외부 시스템으로 계산 및 쿼리를 이전함으로써, 소규모 Airflow 클러스터에서도 훨씬 더 높은 성능을 얻을 수 있습니다.
가령, 데이터베이스에서 데이터를 쿼리하는 것은 데이터베이스 시스템에서 수행하게하고
빅데이터 애플리케이션의 경우, 외부 Spark 클러스터에서 계산을 실행하도록하면 Airflow를 더 효율적으로 사용할 수 있습니다.
중요한 점은 Airflow는 주로 오케스트레이션 도구로 설계되었고, 이러한 방식으로 사용하면 최상의 결과를 얻을 수 있다는 것입니다.
4) 자원관리
대용량 데이터를 작업 시 데이터 처리에 사용되는 Airflow 클러스터나 다른 시스템의 한도를 넘는 경우가 많습니다.
1) pool을 이용한 동시성 관리
많은 태스크를 병렬로 실행할 때 여러 태스크가 동일한 자원에 접근해야하는 상황이 발생할 수 있습니다. 이러한 동시성을 처리하도록 설계되지 않은 경우 해당 자원의 한도를 초과하게됩니다.
Airflow는 리소스 풀을 사용하여 주어진 리소스에 엑세스할 수 있는 테스크 수를 제어할 수 있습니다. 리소스 풀의 각 풀은 해당 리소스에 대한 액세스 권한을 부여하는 고정된 수의 슬롯을 가지고 있습니다. 따라서 리소스를 사용해야하는 개별 태스크는 리소스 풀에 할당되어 해당 풀에서 슬롯을 확보해야 함을 효과적으로 Airflow 스케줄러에게 요청할 수 있습니다.
이는 Airflow UI에서 새로운 리소스 풀의 이름과 설명, 풀에 원하는 슬롯의 개수 지정가능 합니다.
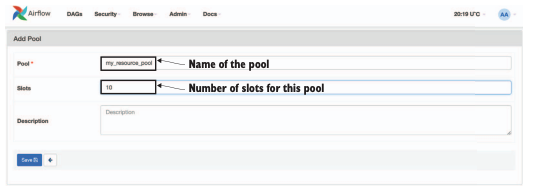

2) SLA 및 경고
데이터의 예상치 못한 문제나 제한된 리소스 등의 문제로 태스크나 DAG의 실행이 평소보다 오래 걸릴 수 있습니다.
SLA 매커니즘을 사용하여 태스크의 동작을 모니터링할 수 있습니다.
태스크 또는 DAG가 지정된 SLA 제한 시간보다 실행하는 데 오래 걸리는 경우 Airflow가 경고를 표시하게 됩니다.
DAG 정의에서 SLA를 지정할 수 있는데, sla 인수를 DAG의 default_args에 전달합니다.

태스크의 실행 결과를 검사하여 태스크의 시작 또는 종료시간이 SLA를 초과하면 SLA 누락 결고를 생성하여 사용자에게 알리고 이는 UI(Browse > SLA misses)에서도 확인할 수 있습니다.
또한, DAG에 정의된 이메일 주소에도 경고 메일이 전송되어 사용자에게 경고할 수 있습니다.
sla_miss_callback 매개변수를 사용하여, 핸들러 함수를 DAG에 전달하여 SLA 누락에 대한 사용자 핸들러 정의할 수 있습니다.

DAG 수준의 SLA 이외에도 태스크의 오퍼레이터에게 sla 인수를 전달하여 태스크 수준 SLA를 지정할 수 있습니다.

해당 태스크에 대해서만 SLA에 적용되게 되는 것입니다.
👉 Airflow는 SLA를 적용할 때 태스크의 종료시간과 DAG의 시작 시간을 계속 비교합니다. Airflow SLA가 항상 개별 태스크가 아닌 DAG의 시작 시간을 기준으로 정의되기 때문입니다.
💡 요약
1. DAG 코드 가독성을 높이는 방법
2. Factory 함수를 사용하여 반복되는 DAG 또는 태스크 효율적으로 생성
3. 멱등성, 결정론적 작업, 재현 가능한 태스크와 DAG 구축하기
4. 데이터 처리 방법을 효과적으로 하는 방법
5. 리소스 풀을 사용하여 Airflow 리소스 관리하기
6. 장기 실행 작업/DAG는 SLA를 사용하여 감지하고 플래그 지정하기
