
Vision transformer가 급부상하고 있으나 attention 메카니즘과 ViT의 근간인 Transformer의 기초부터 잘 알고 있는지에 대한 의문이 생기게 되었다. 학부연구생 시절 Stanford 강의로 딥러닝을 공부했던 때를 때올리며 attention 메카니즘과 transformer의 기초를 탄탄히 하기 위해 Stanford CS224N의 8주차 강의인 Self-Attention and Transformers의 리뷰를 간략히 써본다!
- 강의 영상: https://www.youtube.com/watch?v=LWMzyfvuehA
- PPT: https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1234/slides/cs224n-2023-lecture08-transformers.pdf
1. Recurrent model for (most) NLP!
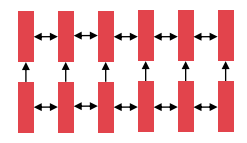
Bidirectional LSTM
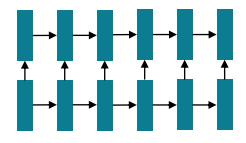
Uni-directional LSTM
- 2016년도 즈음, NLP에서 de facto standear는 Bidirectional LSTM으로 문장을 인코딩하는 것이다.
(예) Source sentence in translation - Bidirectional LSTM은 Uni-directional LSTM으로 발전했다.
- 출력 (구절, 문장, 요약 등)을 문장으로 정의하고 이를 생성하기 위해 LSTM을 사용하였다.
Uni-directional LSTM
- 더 나아가, 메모리에 유연한 접근을 위해 Attention을 사용했다고 한다.
- Attention을 사용하면 다시 특정 node에 정보를 주거나 받는 등 메모리 접근에 자유로워진다.
2. Issues with Recurrent Models
A. Linear Interaction Distance
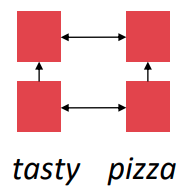
'tasty'와 'pizza'는 강한 상관관계를 가질 것이다.
- RNN은 왼쪽에서 오른쪽 (혹은 반대로) 전개된다.
- 이러한 방법을 통해 RNN은 linear locality를 인코딩한다. 즉, 인접한 단어가 다른 단어 의미에 영향을 미친다.
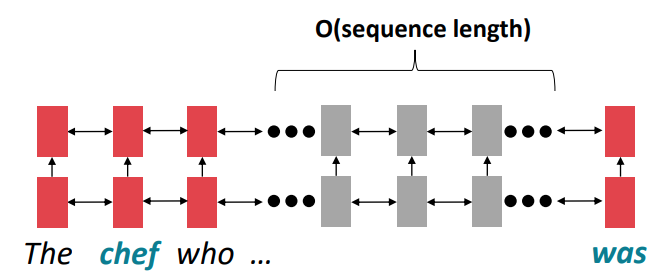
'tasty'와 'pizza'는 강한 상관관계를 가질 것이다.
- 여기서 문제는 먼 단어쌍 끼리 상호작용에 O(sequence length) step이 필요하다는 것이다.
- 위 그림에서, chef와 was의 상호작용을 위해선 중간 단계의 길이인 O(sequence length) 만큼의 스텝이 필요하다는 것이다.
- 이는 'was'에서 'chef'까지 gradient가 전파되며 정보가 손실되는 gradient problem 때문이라고 한다.
Linear intraction distance: RNN은 gradient problem 때문에 long distance dependency를 학습하기 어려움
B. Lack of Parallelizability
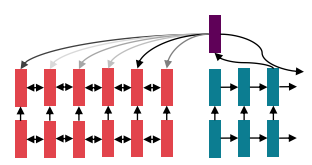
- RNN은 forwad 및 backward 과정이 O(sequence length) 만큼 지난다.
- 미래 hidden state의 계산을 위해선 과거 hidden states가 계산되어야 하는 것이다. 즉, 완전 직렬 방식
- 따라서, 연산의 비효율로 인해 큰 데이터셋에 학습이 힘들다.
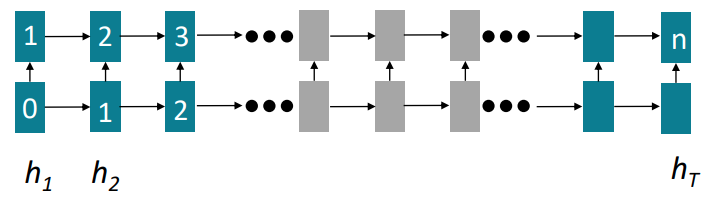
그림의 숫자는 연산 순서를 가리킨다. n번째 hidden state 계산을 위해선 0, 1, 2, ...의 선 계산이 필수적이다.
3. What about Attentions?
- Attention은 각 단어의 representation을 query로서 취급하며 어떤 set of values로부터 정보에 접근한다.
- 예를 들어, 하나의 문장에서 모든 단어는 이전 layer의 모든 단어에 접근하며 대부분 화살표는 무시된다. (중요도 판단 측면에서 낮은 스코어를 말하는 듯 하다)
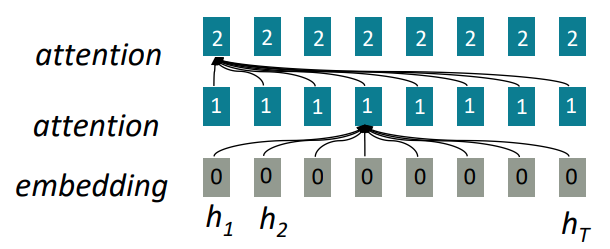
여기서, 비병렬화 연산 (unparallelizable operation)의 수가 시퀀스의 길이에 따라 증가하지 않는다.
Attention은 Linear interaction distance 및 unparallelizability를 해결할 수 있다!
- Linear interaction distance: 모든 단어가 이전 레이어의 모든 단어에 '일단' 접근은 하므로 long distance dependency 문제를 상대적으로 완화한다.
- Unparallelizability: 더 이상 연산이 시퀀스 길이에 비례하지 않는다.
4. Attention as a soft, averaging lookup table
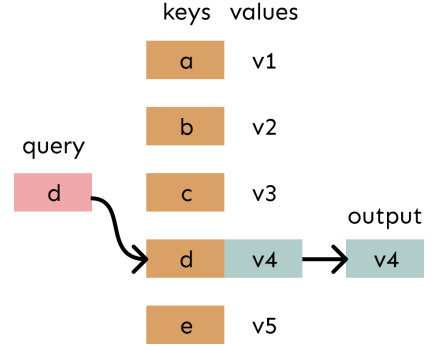
여기서, 우리는 Attention을 key-value를 저장하는 lookup table로 간주할 수 있다.
Lookup table은 value에 해당하는 key의 table이며 Query가 key들 중 하나와 부합하다면 그 key의 value를 반환한다.
Attention은, query가 key에 0과 1 사이 가중치에 따라 softly match 한다.
Value는 가중치와 weighted-sum 될 것이다. 여기서 weight는 query와 key 간 similarity에 softmax를 취한 값이다.
5. Self-Attention: keys, queries, values from the same sequence.
동일 문장 내에서 query, key, value를 계산하여 진행되는 self-attention에 대해서 알아보자.
을 vocabulary 의 단어들의 순열이라고 하자.
각 마다, 의 word embedding을 만들 수 있으며 는 embedding matrix이다. 여기서 는 vocabulary size라고 한다.
Self-attention의 과정은 다음과 같다.
1) Weight matrices , 그리고 로 word embedding을 변환한다.
2) Keys와 Queries를 사용하여 Pairwise similarity를 계산한 뒤, softmax로 normalize 한다.
3) 각 단어의 출력을 value와의 weighted sum으로 계산
6. Barriers and Solutions for Self-Attention as a building block
Self-Attention을 Neural network의 학습 가능한 building block으로 구성할 때 challenge와 solution을 다룬다.
1) 내재된 순서가 없다. → Position representation vector
예를 들어. "Zuko made his uncle"과 "His uncle made Zuko"의 두 문장의 self-attention의 결과는 동일할 것이며 이는 의도된 바가 아니기에 바람직하지 못하다!
이런 순서에 독립적인 self-attention 방식은 단순한 집합을 다룰 때는 의미가 있을 수 있다고 한다.
즉, Queries, keys, values에서 문장의 순서를 인코딩할 필요가 있다
각 sequence index를 vector로 표현한다고 했을 때,
Self-attention block에 이 정보를 통합하기 위해서 단순히 입력에 더해주면 된다고 한다!
- 깊은 self-attention network에서 이는 첫 번째 layer에서 수행한다.
- Concatenation을 할 수도 있지만 대부분 addition을 사용한다고 한다.
A. Sinusoidal position representation
- 가변 주기의 sinusoidal 함수를 position representation에 사용하는 방법
- 장점
- Preriodicity는 '절대적인 위치'가 그렇게 중요하지 않을 수도 있다는 것을 시사한다: 즉, 반복적이거나 주기적으로 변하는 현상에서는 각 요소의 절대적인 위치보다 그들의 상대적인 패턴이나 규칙성이 더 중요한 역할을 할 수 있다는 뜻입니다.
- 더 긴 sequence에 대해서도 적용이 가능하다 (강의에선 extrapolate라는 단어를 썼네요)
- 단점
- 학습 가능하지 않다. Extrapolation이 잘 동작하진 않는다 (?..)
B. Position representation vectors learned from scratch
Sinusoidal position representation 대신 position 정보를 학습 가능한 파라미터로 사용하는 것이다.
행렬 을 학습한다. 여기서 는 행렬의 column이 될 것! 은 단어의 개수이다.
-
장점
- Flexibility: 각 위치는 데이터에 fit하게 학습된다
-
단점
- 개의 단어를 초과하면 extrapolate 불가능
-
대부분에 시스템에서 사용된다고 한다
C. 기타 다른 flexible position representation
- Relative linear position attention
- Dependency syntax-based position
(30분 28초부터 계속)
