
오늘은 판다스를 이용하여 데이터를 다루는 것에대하여 즉 Profiling에 대하여 블로깅할 것이다!
흔히 머신러닝이나 딥러닝, 혹은 데이터와 관련된 그어떤 일이더라도 절대불변의 진리는 있기 마련인데. 그중 가장 보편적으로 인용되는 문구는 Garbage In, Garbage Out (GIGO)라고 생각한다. 정확한 결과를 출력하기 위해서는 그 무엇보다도 중요한건 데이터의 퀄리티라고 생각한다. 그만큼이나 data는 너무나도 중요하고 그렇게 중요한 data를 Profiling 하는 것에 있어서 미숙하다면 큰 패널티로 다가올 것이라고 생각한다. 함께 알아보도록 하자!
판다스 프로파일링(Pandas-Profiling)
좋은 요리를 위해서는 조리 방법도 중요하지만, 그만큼 중요한 것은 갖고있는 재료의 상태입니다. 재료가 상하거나 문제가 있다면 좋은 요리가 나올 수 없습니다. 마찬가지로 좋은 머신 러닝 결과를 얻기 위해서는 데이터의 성격을 파악하는 과정이 선행되어야 합니다. 이 과정에서 데이터 내 값의 분포, 변수 간의 관계, Null 값과 같은 결측값(missing values) 존재 유무 등을 파악하게 되는데 이와 같이 데이터를 파악하는 과정을 EDA(Exploratory Data Analysis, 탐색적 데이터 분석)이라고 합니다.
탐색적 데이터 분석 정리글 바로가기
이번에는 방대한 양의 데이터를 가진 데이터프레임을 .profile_report()라는 단 한 줄의 명령으로 탐색하는 패키지인 판다스 프로파일링(pandas-profiling)을 소개합니다.
프롬프트에서 아래의 pip 명령을 통해 패키지를 설치합니다.
pip install -U pandas-profiling
실습 파일 불러오기
실습을 위해 아래의 링크에서 spam.csv란 파일을 다운로드 해보겠습니다.
kaggle 다운로드링크
다운로드가 완료되면, data에 spam.csv를 할당해 줍니다.
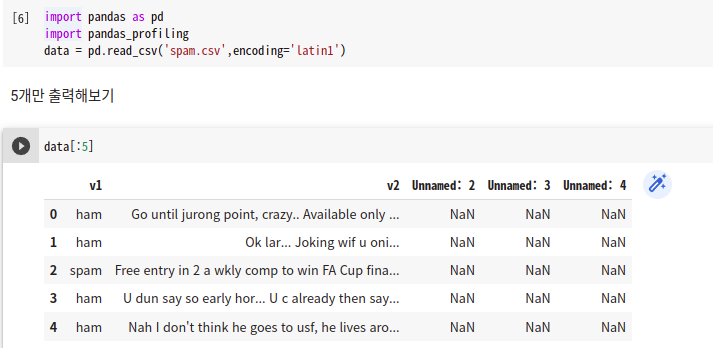
이 데이터에는 총 5개의 열이 있는데, 여기서 Unnamed라는 이름의 3개의 열은 5개의 행만 출력했음에도 벌써 Null 값이 보입니다. v1열은 해당 메일이 스팸인지 아닌지를 나타내는 레이블에 해당되는 열입니다. ham은 정상 메일을 의미하고, spam은 스팸 메일을 의미합니다. v2열은 메일의 본문을 담고있습니다.
리포트 생성하기
pr=data.profile_report() # 프로파일링 결과 리포트를 pr에 저장
data.profile_report() # 바로 결과 보기
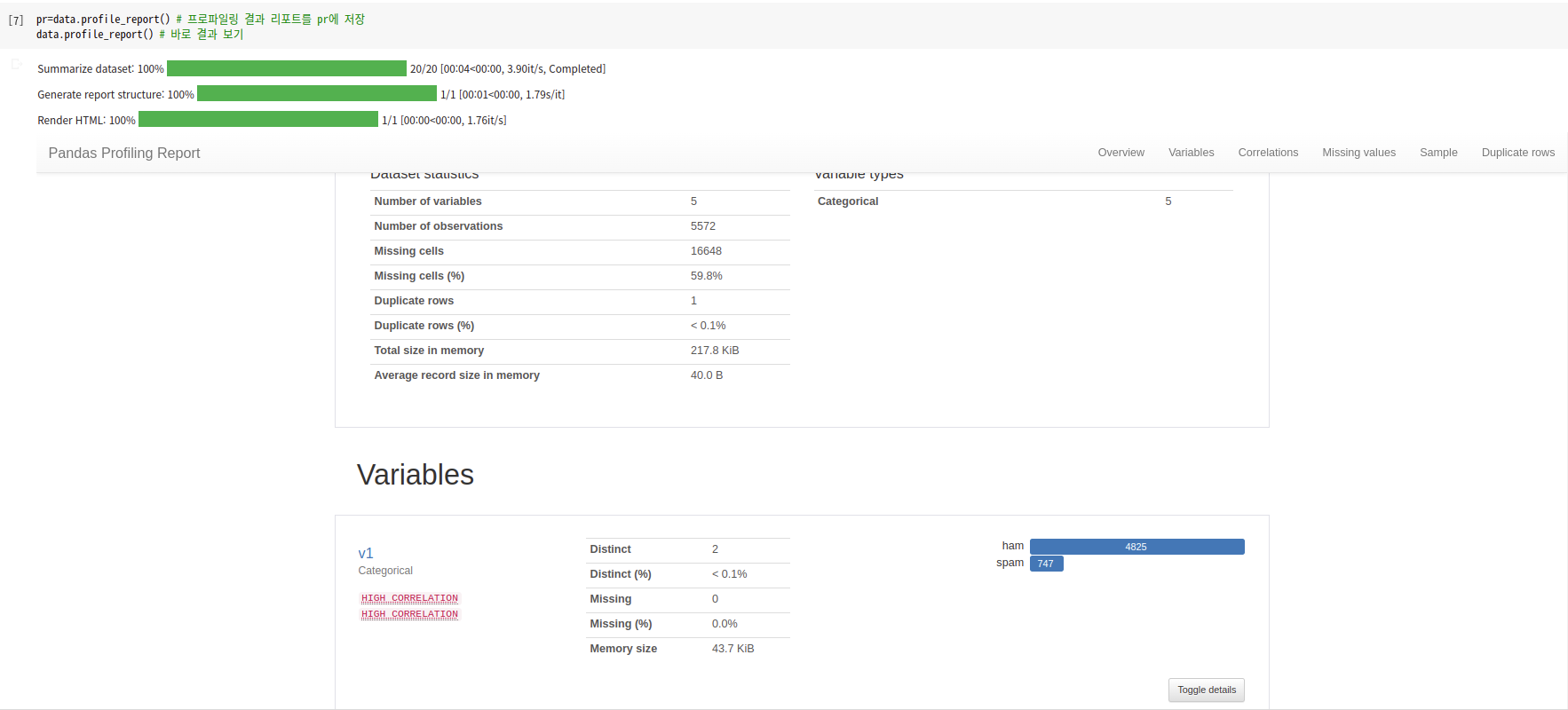
html 파일로 저장하는 것도 가능하다.
pr.to_file('./pr_report.html') # pr_report.html 파일로 저장
리포트 살펴보기
- 개요(Overview)
Overview는 데이터의 전체적인 개요를 보여줍니다. 데이터의 크기, 변수의 수, 결측값(missing value) 비율, 데이터의 종류는 어떤 것이 있는지를 볼 수 있습니다.
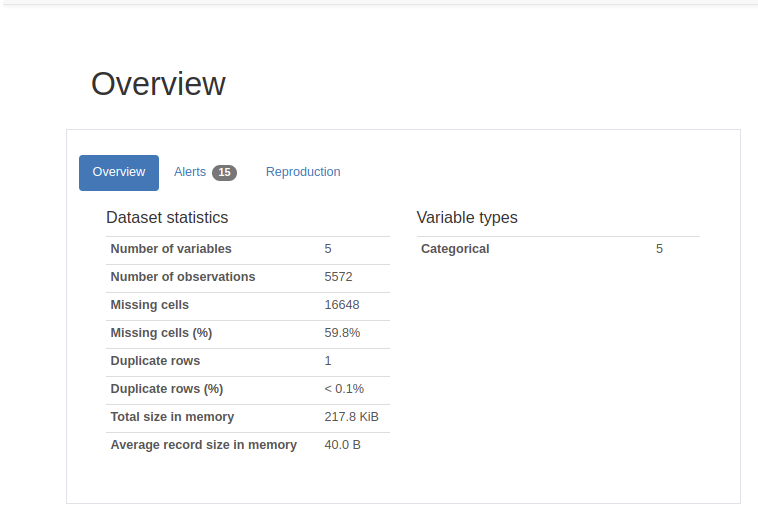
Dataset info를 보겠습니다. 해당 데이터는 총 5,572개의 샘플(행)을 가지고 있으며, 5개의 열을 가지고 있습니다. 하나의 값을 셀이라고 하였을 때, 총 5,572 × 5개의 셀이 존재하지만 그 중 16,648개(59.8%)가 결측값(missing values)으로 확인됩니다.
Warnings를 보면 사실 결측값들은 Unnamed라는 3개의 열에 존재합니다. 3개의 열 모두는 99% 이상이 결측값을 갖고 있어 데이터에서 별다른 의미를 갖지 못합니다. 앞서 메일의 본문을 의미한다고 했던 v2열은 총 5,169개의 중복되지 않은 값(distinct value)을 갖고있습니다. 총 샘플의 개수가 5,572개인것을 감안하면 403개의 메일은 중복이 존재한다는 의미입니다.
- 변수(Variables)
변수(Variables)는 데이터에 존재하는 모든 특성 변수들에 대한 결측값, 중복을 제외한 유일한 값(unique values)의 개수 등의 통계치를 보여줍니다. 또한 상위 5개의 값에 대해서는 우측에 바 그래프로 시각화한 결과를 제공합니다.

우선 Unnamed라는 이름을 가진 3개의 열에 대해서 보겠습니다. 앞서 개요에서 봤듯이 3개의 열 모두 99% 이상의 값이 결측값입니다. 예를 들어 Unnamed_2 열은 총 5,572개의 값 중에서 5,522개가 결측값입니다. 이는 총 50개의 결측값이 아닌 값이 존재함을 의미합니다. 그리고 그 중 중복을 제거한 유일한 값의 개수는 44개입니다.
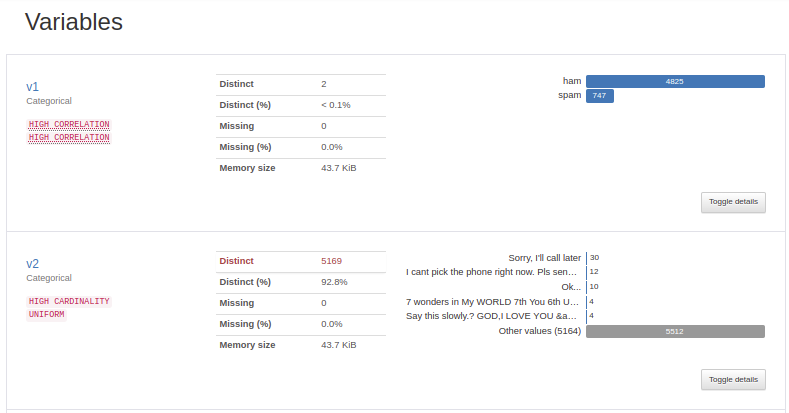
이번에는 다른 2개의 열인 v1과 v2를 보겠습니다. v2는 메일의 본문이고, v1은 해당 메일이 정상 메일(ham)인지, 스팸 메일(spam)인지 유무가 기재되어져 있습니다. v1의 경우 유일한 값의 개수(distinct count)가 2개뿐으로 5,572개의 값 중에서 우측의 바 그래프를 통해 4,825개가 ham이고 747개가 spam인 것을 알 수 있습니다. 이는 데이터에서 정상 메일 샘플이 훨씬 많다는 것을 보여줍니다. v2의 경우 5,572개의 메일 본문 중에서 중복을 제외하면 5,169개의 유일한 내용의 메일 본문을 갖고 있습니다. 그 중 중복이 가장 많은 메일은 Sorry, I'll call later라는 내용의 메일로 총 30개의 메일이 존재합니다.
또한 v1과 v2 모두 결측값(missing values)은 존재하지 않는데, 이는 결과적으로 데이터 전처리를 수행할 때, Unnamed라는 3개의 열을 제거하고 나서는 별도의 결측값 전처리는 필요가 없음을 의미합니다.
- 상세사항 확인하기(Toggle details)
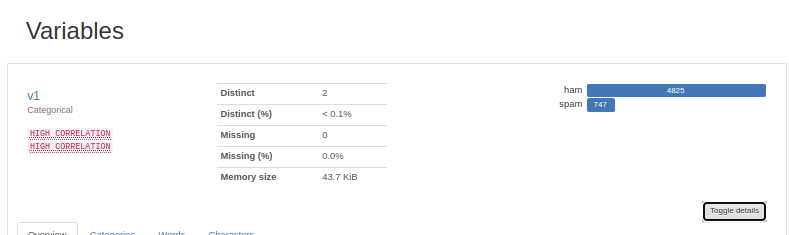
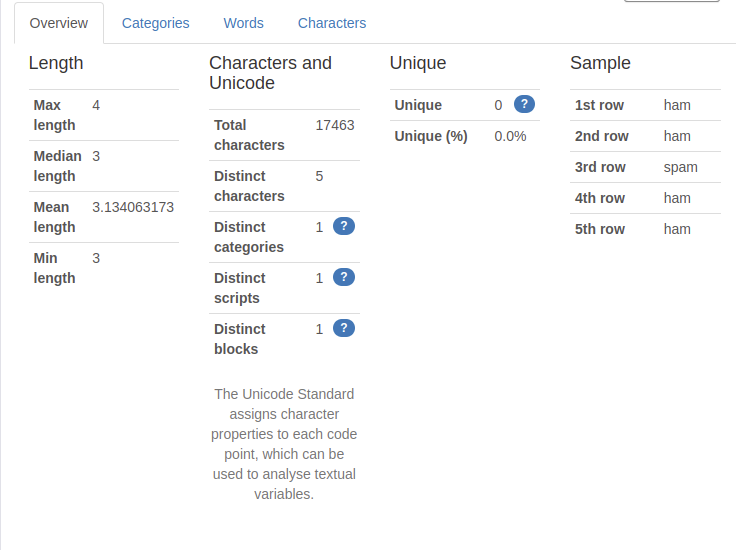
우선 v1의 상세사항 확인하기(Toggle details)를 누른 결과는 위와 같습니다. 첫번째 탭인 빈도값(common values)에서는 앞서 바 그래프로 확인했던 각 값의 분포를 좀 더 상세하게 보여줍니다. v1의 경우, ham이 총 4,825개로 이는 전체 값 중 86.6%에 해당되며, spam은 747개로 전체 값 중에서는 13.4%에 해당됩니다.
구성(composition)에서는 전체 값의 최대 길이, 최소 길이, 평균 길이와 값의 구성에 대해서 볼 수 있습니다. v1의 모든 값들은 spam 또는 ham이라는 1개 단어만 존재하지만, 여기서의 길이는 단어 단위로 측정한 길이가 아니라 문자열 길이므로 spam의 길이인 4가 최대 길이(max length)가 되고, ham의 길이인 3이 최소 길이(min length)가 됩니다. 4,825개의 4의 길이를 가진 값과 747개의 값의 3의 길이를 평균 길이는 3.134063173이 됩니다. 또한 v1열의 모든 값들은 숫자, 공백, 특수 문자 등이 없이 알파벳만으로 구성되므로 Contains chars에서만 True가 됩니다
이번에는 v2의 상세사항 확인하기를 눌러보겠습니다.
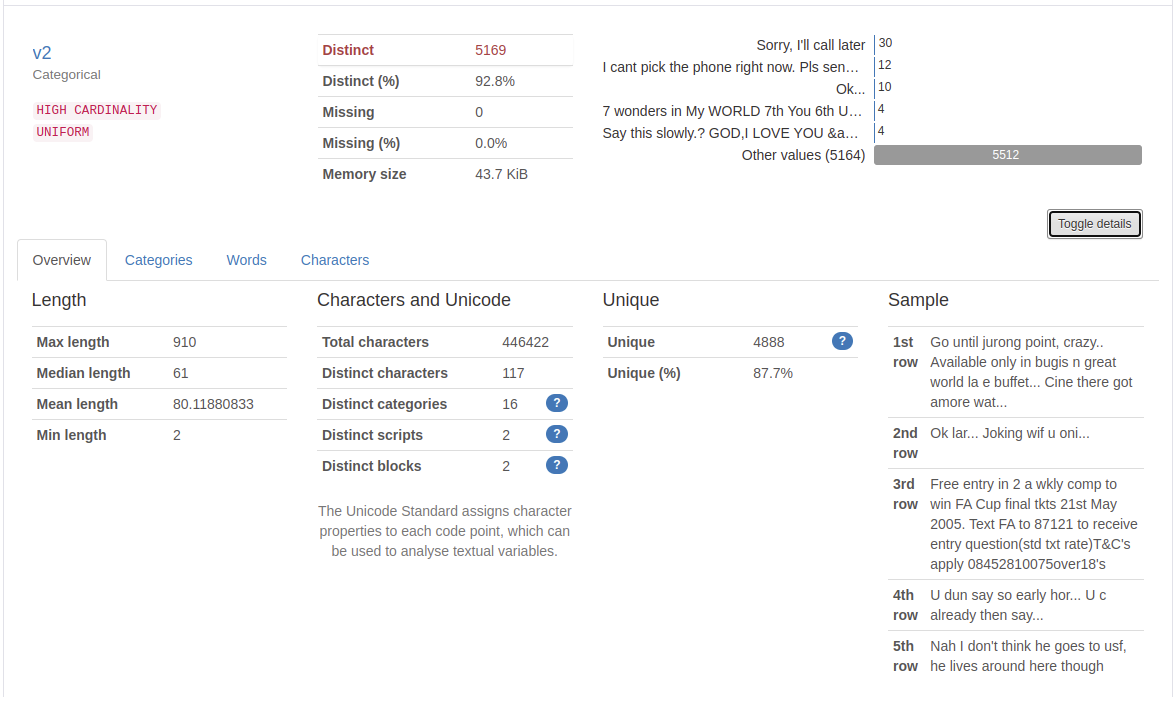
중복이 존재하는 상위 10개 메일의 내용을 확인할 수 있습니다.
또한, 값의 최대 길이는 910, 최소 길이는 2, 평균 길이는 80.11880833임을 알 수 있습니다. 그리고 메일 본문에서는 글자, 숫자, 공백, 특수문자 등이 모두 포함되어져 있으므로 모든 Contains에 True를 보여줍니다.
위 데이터에 대해서는 더 이상 불필요한 정보들이므로 이하 설명은 생략하겠지만, pandas-profiling은 위에서 열거한 기능들 외에도 수치형 데이터를 위한 상관계수(correlations), 결측값에 대한 히트맵(headmap), 수지도(dendrogram) 등의 기능을 지원합니다.
