데이터 분리
- 성능 확인
- 큰 데이터 : 2-way holdout
- 작은 데이터 : k-fold cross-validation
- 모델 선택
- 큰 데이터 : 3-way holdout
- 훈련데이터 : 모델을 fit 하는 데 사용
- 검증데이터 : 예측 모델을 선택하기 위해서 예측의 오류를 측정할 때 사용
- 테스트 데이터 : 일반화 오류를 평가하기 위해 선택된 모델에 한하여
- 작은 데이터 : k-fold cross-validation
- 큰 데이터 : 3-way holdout
- 모델 비교
- 큰 데이터 : Multiple independent training sets + test sets, McNemar test
- 작은 데이터 : Combined 5x2 cvFtest, nested cross-validation (이건 모시다냐🙄)
- 시계열 데이터에서는
- 과거 -> 학습데이터
- 최근 -> 검증데이터
- 미래 -> 테스트데이터
분류문제와 로지스틱 회귀
- 분류문제를 풀기 전엔 항상 타겟 범주가 어떤 비율을 가지는지 확인해야 한다.
target = '타겟컬럼명'
y_train = train[target]
y_train.value.counts(normalize=True)
#normalize=True는 비율(%), False는 개수
#시각화
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
sns.countplot(x=y_train)- 기준모델(=최빈값) 코드
major = y_train.mode()[0]
y_pred = [major] * len(y_train)-
분류모델에는 새로운 성능 지표가 사용된다.
(accuracy, precision, recall, f1, roc) -
로지스틱회귀의 계수는 직관적으로는 이해하기 어렵지만, 오즈(Odds)를 사용하면 쉽게 해석이 가능하다.
-
예를 들어,
odds = 4라는 것은성공확률 : 실패확률 = 4 : 1이라는 뜻. 즉, 분류에서는 1일 확률 : 0일 확률 -
오즈에 로그를 취하는 것을 로짓변환(Logit transformation)이라고 하는데, 이것을 통해 선형형태로 만들어 회귀계수의 해석을 용이하게 한다.
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
#성능확인
model.score(y_test, y_pred)실습
데이터셋 : titanic data
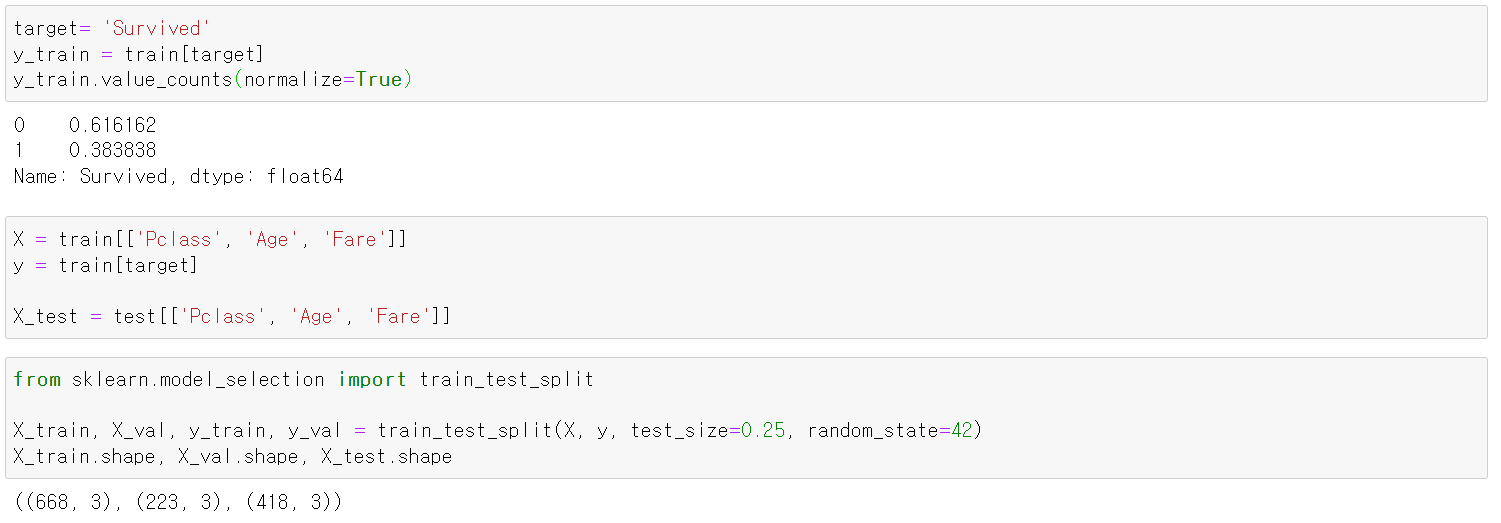
데이터 호출 후, 데이터를 살펴보니, 타겟값이 적당히 분포해있었고, 피쳐와 타겟을 분리 + 학습 검증 데이터로 분리하였다.
선형모델
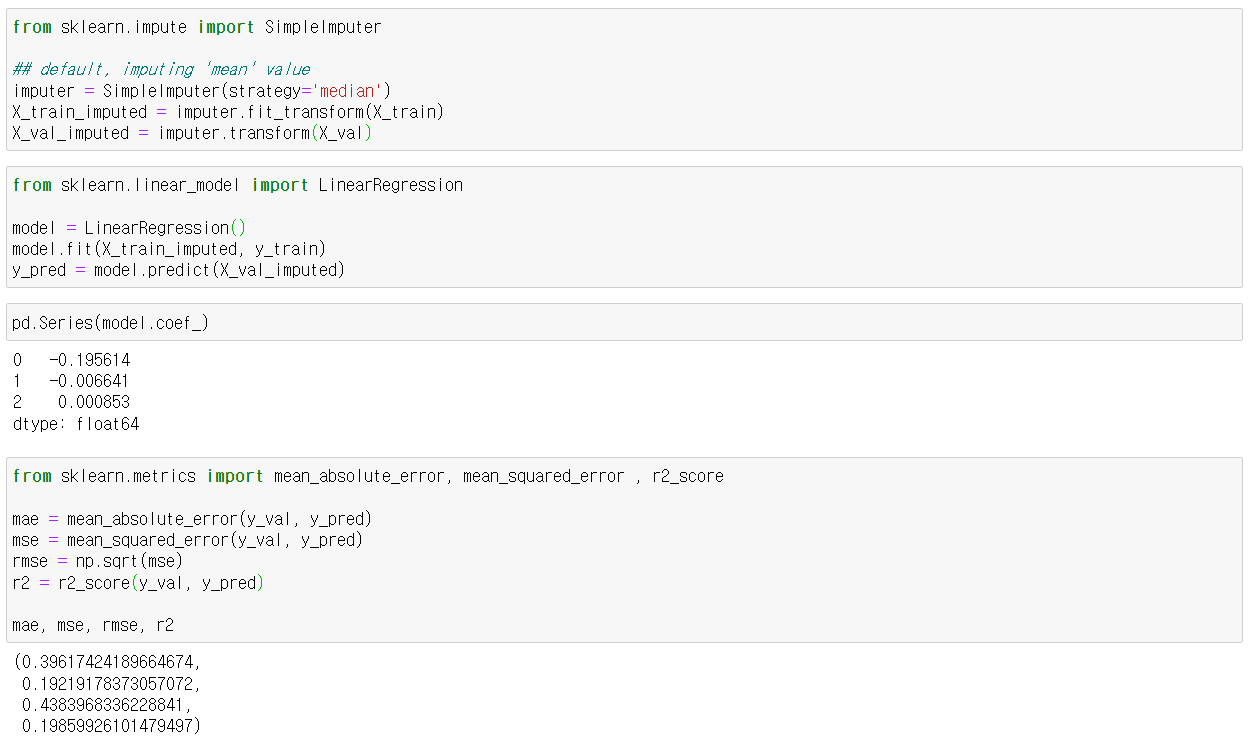
임퓨팅 해주고 선형모델 돌려주니 class의 영향이 가장 컸고(계수가 가장 컸고), mae는 0.4, mse는 0.2, r2은 0.2 정도의 그저그런 성능이 나왔다.

class의 영향도를 보고자 다른 조건은 동일하게 주고 클래스만 변화를 주었을 때, 생존 확률이 뚝뚝 떨어졌다.
로지스틱 모델
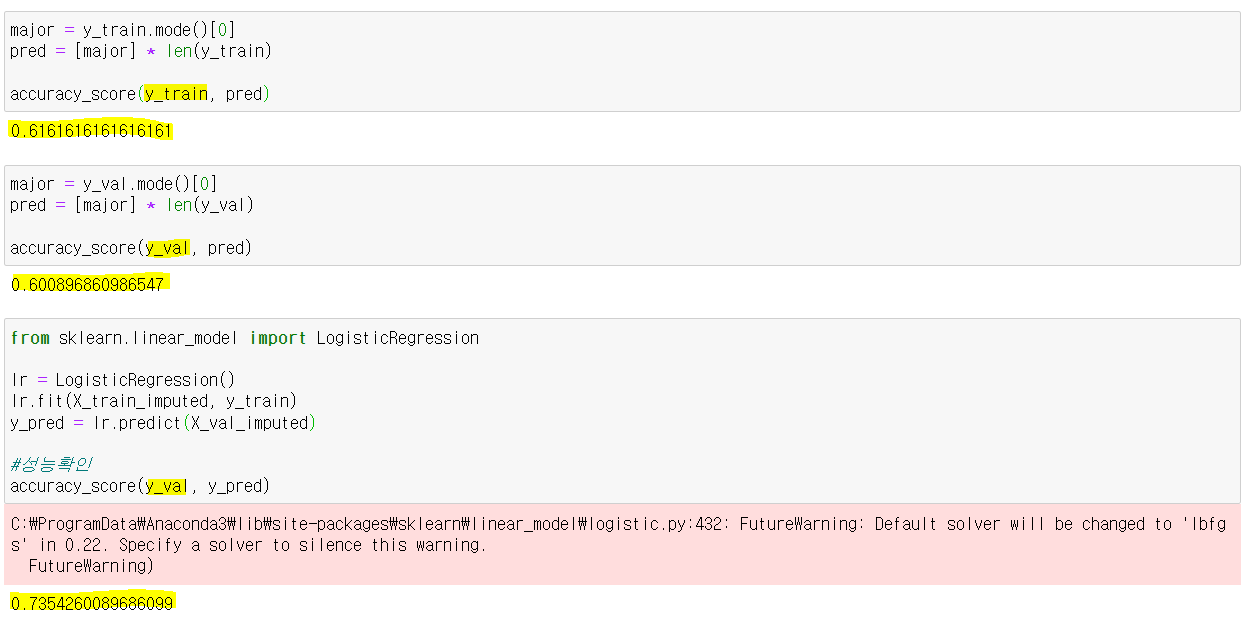
학습데이터의 기준모델 성능 = 0.61
검증데이터의 기준모델 성능 = 0.60
검증데이터의 로지스틱 모델 학습 후 성능 = 0.73 (로지스틱 만만세다🤲)
파이프라인으로 encoder, imputer, model 했을 때가 성능이 가장 좋았다.
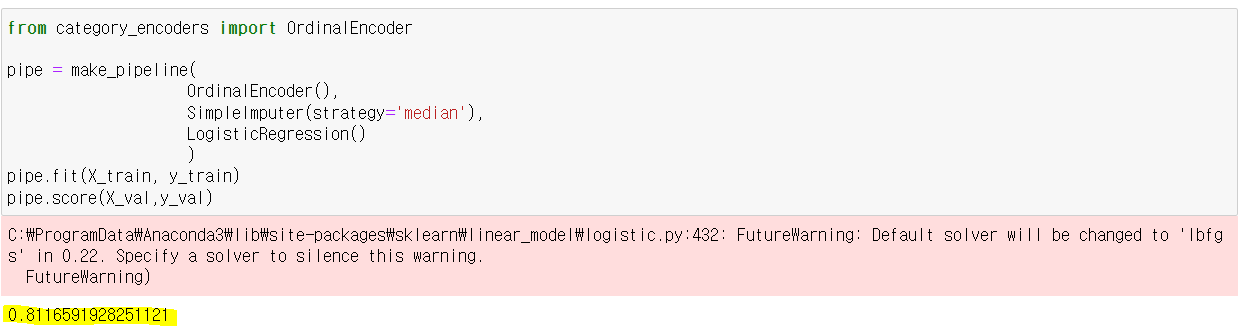

완료주의