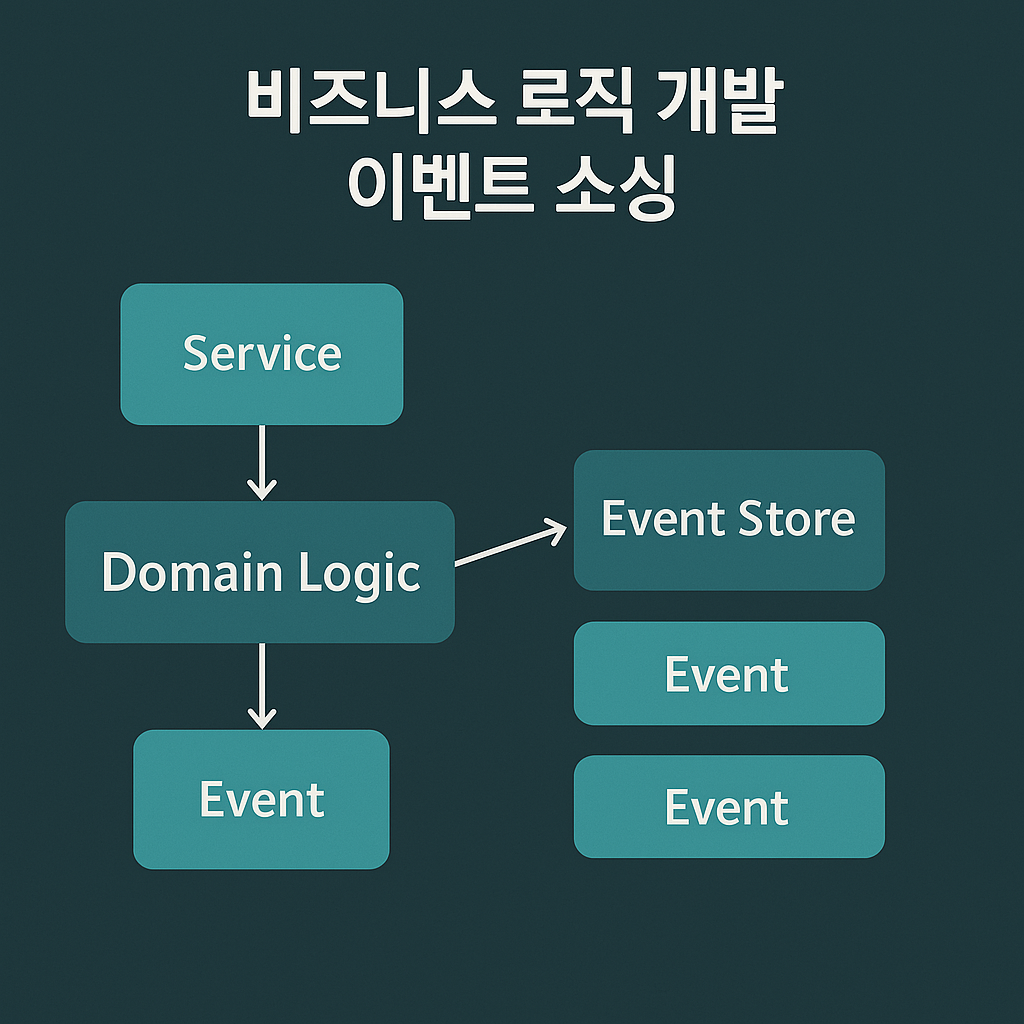
이벤트 소싱 응용 비즈니스 로직 개발
이벤트 소싱은 비즈니스 로직을 구성하고 애그리거트를 저장하는 방법이다. 이벤트는 각 애그리거트의 상태 변화를 나타내며, 애플리케이션은 이벤트를 재연하여 애그리거트의 현재 상태를 재생성 한다.
패턴: 이벤트 소싱
상태 변화를 나타내는 일련의 도메인 이벤트로 애그리거트를 저장한다.
이벤트 소싱은 애그리거트의 이력이 보존되어 감사/통제 용도로 적합하고, 도메인 이벤트의 확실한 발행이 가능한 장점이 있으나 비즈니스 로직을 작성하는 학습 시간 및 저장소 쿼리의 복잡성이 단점이다.
기존 영속화의 문제점
클래스는 DB테이블에, 클래스의 필드는 테이블의 컬럼에, 클래스 인스턴스는 테이블의 각 로우에 매핑하는 것이 기존의 영속화 방식이다. Order 클래스는 ORDER 테이블에, OrderLineItem 클래스는 ORDER_LINE_ITEM 테이블에 매핑하는 형태로 구성하였다.
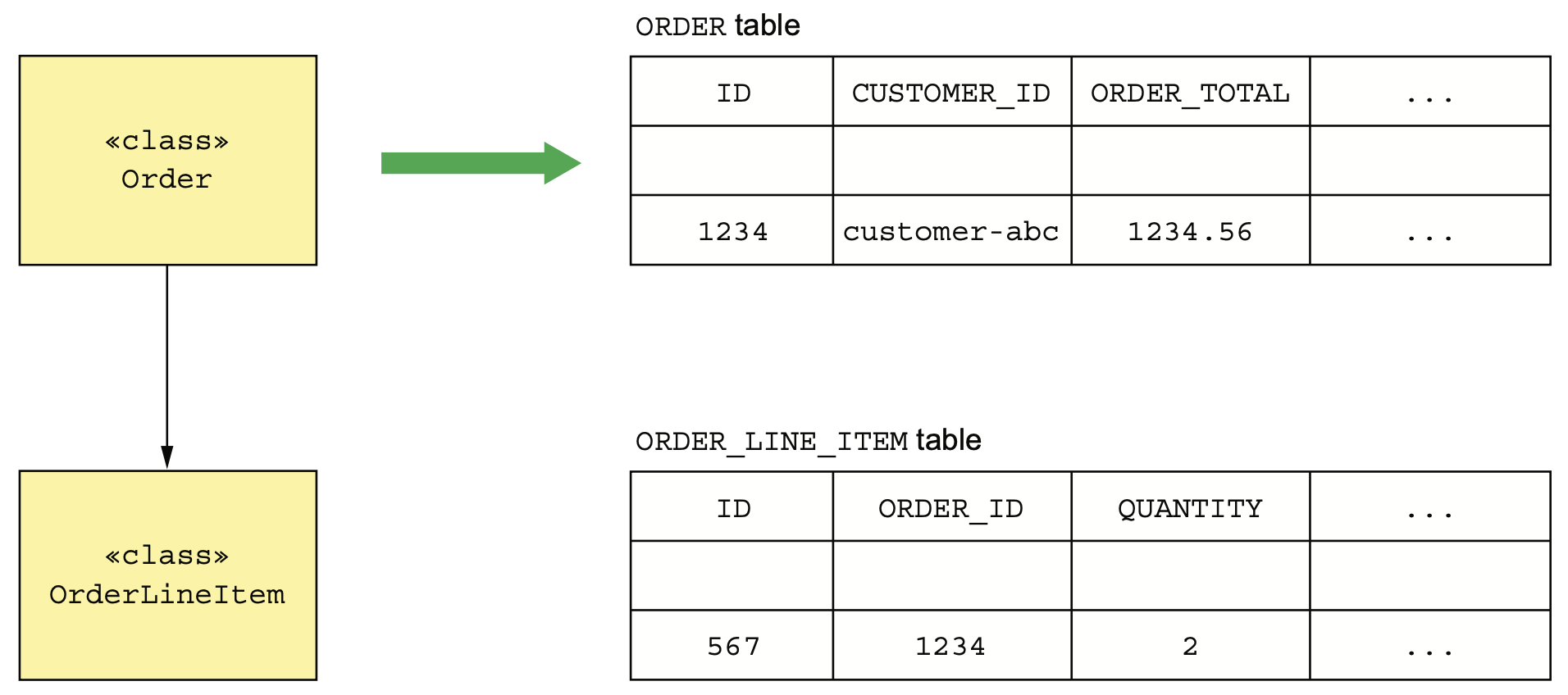
The traditional approach to persistence maps classes to tables and objects to rows in those tables.
이러한 DB 저장 방식은 모놀리식 엔터프라이즈 애플리케이션에 잘 동작 되었지만 다음의 한계가 있다.
- 객체-관계 임피던스 부정합: 테이블 형태의 관계형 스키마와 관계가 복잡한 리치 도메인 모델(rich domain model)의 그래프 구조는 근본적인 개념에서 차이가 있어 "객체-관계 매핑은 컴퓨터 과학의 월남전이다" 라고 표현될 정도로 어려운 문제이다.
- 애그리거트 이력이 없다: 현재(최종) 애그리거트의 상태만 저장하는 형태로, 애그리거트의 이력을 관리하는 것은 개발도 어렵고, 비즈니스 로직과 동기화하는 코드 중복 개발도 필요하다.
- 감사 로깅은 구현하기 힘들고 오류도 자주 발생한다: 엔터프라이즈 애플리케이션은 애그리거트의 변경에 대한 감사 로그가 필요하다. 감사 로깅은 구현하는데 시간도 걸리지만, 감사 로깅 코드 및 비즈니스 로직이 계쏙 분화하기 때문에 버그 가능성이 높다.
- 이벤트 발행 로직이 비즈니스 로직에 추가된다: 기존 영속화는 도메인 관련 이벤트 발행을 지원하지 않는다. 개발자가 이벤트 생성 로직을 추가해야 하고, 심하게는 비즈니스 로직과 동기화 되지 않을 위험도 있다.
객체-관계 임피던스 부정합(Object-Relational Impedance Mismatch)
이벤트 소싱 패턴으로 들어가기 이전에, 객체-관계 임피던스 부정합에 대한 내용을 살펴보자. 우선 객체-관계 임피던스 불일치는 관계형 데이터 저장소(RDBMS)의 데이터와 도메인 중심 객체 모델 간의 데이터 처리에서 발생하는 문제를 의미한다. 관계형 데이터베이스 관리 시스템(RDBMS)는 데이터를 전용 데이터베이스에 저장하는 표준적인 방법이지만, 객체 지향(Object-Oriented, OO) 프로그래밍은 비즈니스 중심 설계에서 기본적으로 사용되는 프로그래밍 방식으로 근본에서 차이가 발생하게 된다. 관계형 데이터베이스나 객체 지향 프로그래밍의 본질적인 문제라고 하기 보다는, 두 논리 모델 간의 개념적인 차이를 매핑하는 데 어려움이 있다. 두 논리 모델은 각기 다른 방식으로 데이터베이스 서버, 프로그래밍 언어, 디자인 패턴, 또는 기타 기술 등을 통해 구현되는데, 저장된 관계형 데이터를 객체 지향 모델에서 사용하거나 그 반대의 경우에 생성되는 문제를 의미한다. 이 문제를 해소하기 위해 객체 지향 데이터 저장소(Object-oriented data stores)를 사용할 수도 있으나 객체지향 데이터 저장소 모델은 널리 사용되지 못하고 있다.
참고로 임피던스 불일치라는 용어는 전기공학에서 사용되는 임피던스 매칭(Impedance Matching)에서 차용된 것으로, 임피던스(Impedance)는 전기 회로에서 전압과 전류 사이의 저항을 나타내며, 두 분리된 회로 간에 효율적인 전력 전달을 위해서는 임피던스를 맞춰야 한다. 만약 임피던스가 일치하지 않으면, 에너지 손실이나 신호 왜곡이 발생할 수 있고, 이런 현상을 임피던스 불일치(Impedance Mismatch)라고 했다. 전산학에서는 해당 개념을 차용해서 데이터베이스와 객체 지향 모델 간의 불일치 문제를 설명하는 데 사용하며, 전기 회로에서 임피던스 불일치가 전력 전달에 문제를 일으키는 것처럼, 관계형 데이터 모델과 객체 지향 모델 간의 불일치도 데이터 매핑과 처리 과정에서 문제를 일으킨다는 유사성을 나타낸다.
객체 지향 모델
Java에서는 Order와 Item 객체 간의 관계를 다음과 같이 정의할 수 있다.
Order class
import java.util.List;
public class Order {
private int orderId;
private List<Item> items;
public Order(int orderId, List<Item> items) {
this.orderId = orderId;
this.items = items;
}
public int getOrderId() {
return orderId;
}
public List<Item> getItems() {
return items;
}
public void addItem(Item item) {
items.add(item);
}
}Item class
public class Item {
private int itemId;
private String name;
private double price;
public Item(int itemId, String name, double price) {
this.itemId = itemId;
this.name = name;
this.price = price;
}
public int getItemId() {
return itemId;
}
public String getName() {
return name;
}
public double getPrice() {
return price;
}
}위 코드에서 Order 클래스는 여러 Item 객체를 리스트 형태로 포함하고 있으며, 이는 집합(composition) 관계로, Order는 하나의 주문을 표현하고, 그 안에 여러 Item 객체가 포함될 수 있다.
RDBMS 모델
위의 객체 모델을 RDBMS(관계형 데이터베이스)에서 모델링 하려면 다음과 같이 두 개의 테이블로 변환해서 구현하는 것이 일반적인 방법이다.
Order 테이블
order_id(주문 ID)- 기타 주문 관련 필드 (예: 고객 ID, 주문 날짜 등)
Item 테이블
item_id(아이템 ID)name(아이템 이름)price(가격)order_id(주문 ID, 외래 키로 사용되어Order테이블과 관계를 표시)
객체-관계 임피던스 불일치 케이스
상속과 관계형 데이터베이스의 불일치
다음 코드는 OOP를 따른 Java 코드로 Product 라는 공통의 속성을 가지고 있으며, 서로 다른 속성을 가지는 DigitalProduct와 PhysicalProduct는 Product를 상속받은 클래스이다.
public class Product {
private int productId;
private String name;
private double price;
public Product(int productId, String name, double price) {
this.productId = productId;
this.name = name;
this.price = price;
}
// Getter methods...
}
public class DigitalProduct extends Product {
private int fileSize;
public DigitalProduct(int productId, String name, double price, int fileSize) {
super(productId, name, price);
this.fileSize = fileSize;
}
// Getter methods...
}
public class PhysicalProduct extends Product {
private double weight;
public PhysicalProduct(int productId, String name, double price, double weight) {
super(productId, name, price);
this.weight = weight;
}
// Getter methods...
}관계형 데이터베이스에서는 OOP에서의 상속을 표현하기 위한 구조가 없기 때문에 단일테이블 상속 혹은 테이블 분할 상속 등의 방법을 사용하게 된다. 단일 테이블 상속 (Single Table Inheritance)은 하나의 테이블에 모든 상속된 클래스의 속성을 저장하는 형태로 다음처럼 스키마를 구성할 수 있다.
CREATE TABLE Product (
product_id INT PRIMARY KEY,
name VARCHAR(255),
price DOUBLE,
file_size INT, -- DigitalProduct에만 사용
weight DOUBLE -- PhysicalProduct에만 사용
);단일 테이블 상속 구조를 사용하면 테이블에 상속된 모든 정보를 포함하고 있으므로 구현은 손쉽게 가능할 수 있으나, DigitalProduct에는 weight가 필요 없고, PhysicalProduct에는 file_size가 필요 없는 상황이므로 사용하지 않는 컬럼이 생성되는 문제가 있다. 반면에 테이블 분할 상속 (Class Table Inheritance)은 상속 관계에 따라 각 클래스마다 별도의 테이블을 생성하고, 조인을 사용해 연결합하는 형태로 다음처럼 테이블 스키마를 구성할 수 있다.
CREATE TABLE Product (
product_id INT PRIMARY KEY,
name VARCHAR(255),
price DOUBLE
);
CREATE TABLE DigitalProduct (
product_id INT PRIMARY KEY,
file_size INT,
FOREIGN KEY (product_id) REFERENCES Product(product_id)
);
CREATE TABLE PhysicalProduct (
product_id INT PRIMARY KEY,
weight DOUBLE,
FOREIGN KEY (product_id) REFERENCES Product(product_id)
);테이블 분할 상속을 적용하면 DigitalProduct나 PhysicalProduct를 조회할때 Product 테이블을 FK로 조인해야하므로, 쿼리가 복잡하게 되는 문제가 있다.
데이터 탐색 방법의 차이 (Navigational vs. Relational)
Java 객체 지향 모델에서는 데이터 탐색 시 객체 간의 참조를 직접 접근할 수 있다. 예를 들어, Order 객체에서 주문에 포함된 모든 아이템을 아래 코드처럼 탐색할 수 있다.
Order order = new Order(1, Arrays.asList(
new Item(101, "Book", 29.99),
new Item(102, "Pen", 2.99)));
for (Item item : order.getItems()) {
System.out.println(item.getName());
}반면에 SQL 기반의 관계형 데이터베이스에서는 다음과 같이 JOIN을 사용해 데이터를 탐색해야하므로 Java 코드에서는 객체의 참조를 따라 탐색할 수 있지만, 관계형 데이터베이스에서는 테이블 간의 관계를 JOIN을 통해 명시적으로 정의해야 하는 어려움이 있다.
SELECT i.name
FROM Item i
JOIN Order o ON i.order_id = o.order_id
WHERE o.order_id = 1;데이터 로딩 시점의 차이 (Lazy Loading vs. Eager Loading)
지연 로딩(Lazy Loading)과 즉시 로딩(Eager Loading)은 데이터를 불러오는 시점의 차이를 나타내는 문제로, 지연 로딩은 연관된 데이터가 필요한 시점에 가져오는 형태이고, 즉시 로딩은 연관된 데이터를 동시에 불러오는 형태이다. Java에서는 ORM(Object-Relational Mapping) 라이브러리(예: Hibernate)등을 활용하여 지연 로딩을 구현(Order 객체를 로드할 때 items는 읽어오지 않고, 해당 정보가 필요할때 로딩)할 수 있도록 구현이 가능하다. 그러나 SQL 쿼리에서는 즉시 로딩을 통해 JOIN을 사용해 관련된 데이터를 미리 가져오게 되어 불필요할 수 있는 데이터까지 모두 로드되어 성능 문제를 유발할 수 있는 가능성이 있다.
@Entity
public class Order {
@Id
private int orderId;
@OneToMany(fetch = FetchType.LAZY)
private List<Item> items;
}데이터 타입의 불일치
Java에서는 다양한 데이터 타입과 자료 구조(List, Set, Map 등)를 사용할 수 있으나, 관계형 데이터베이스에서는 이러한 컬렉션 타입을 직접적으로 표현할 수 없어, 별도의 테이블을 생성하거나 JSON 형식으로 데이터를 저장하는 방식 등을 사용해야 한다. 따라서 데이터 저장과 불러오는 과정에 추가적인 변환 로직을 만들어야 하고 오류의 가능성이 확대된다.
객체지향 데이터 저장소 모델 (Object-Oriented Data Storage Model)
객체지향 데이터 저장소 모델은 데이터를 객체 단위로 관리하는 모델로, 객체지향 프로그래밍(OOP)의 개념을 데이터 저장소에 적용하여, 객체지향 언어에서 사용하는 객체와 유사한 방식으로 데이터를 저장하고 관리할 수 있도록 지원한다. 데이터와 그와 관련된 행동(메서드)을 함께 저장할 수 있기 때문에, 객체 지향 애플리케이션의 설계와 구현을 더 자연스럽게 표현할 수 있는 장점이 있다.
객체지향 데이터 저장소의 개념
객체지향 데이터 저장소(Object-Oriented Database, OODB)는 객체지향 개념을 바탕으로 설계된 데이터베이스로,전통적인 관계형 데이터베이스와는 데이터 모델에 차이가 발생한다.
- 객체(object): 데이터와 관련 메서드(동작)를 함께 묶어놓은 단위
- 클래스(class): 객체의 구조를 정의하는 청사진으로, 객체의 속성(필드)과 메서드를 정의
- 상속(inheritance): 객체지향 데이터 저장소에서는 클래스 간의 상속 관계를 표현하여 클래스가 다른 클래스의 속성이나 메서드를 재사용하거나 확장을 지원
- 캡슐화(encapsulation): 데이터와 메서드를 하나의 객체로 캡슐화하여, 외부에서는 객체의 인터페이스를 통해서만 접근
- 다형성(polymorphism): 서로 다른 클래스의 객체가 동일한 인터페이스를 통해 동작할 수 있도록 하는 기능을 제공
객체지향 프로그래밍 언어(Java, C++, Python 등)에서 사용하는 동일한 개념을 지원하여 이러한 객체를 데이터베이스에 직접적으로 저장하고 관리할 수 있도록 지원한다.
객체지향 데이터 저장소의 특징
-
객체의 저장 및 관리: 객체지향 데이터 저장소는 객체를 데이터베이스에 그대로 저장할 수 있도록 설계되어 객체의 속성, 메서드, 관계 등을 데이터베이스 내에서 유지 가능하다. 또한 객체지향 프로그래밍 언어의 객체를 데이터베이스에 저장할 때, 객체의 상태(속성 값)뿐만 아니라 객체의 행동(메서드)도 함께 저장할 수 있어, 객체의 동작을 데이터 저장소에서 재사용을 지원한다.
-
데이터와 행동의 결합: 전통적인 관계형 데이터베이스에서는 데이터를 테이블 형태로 저장하며, 데이터와 그에 대한 행동(비즈니스 로직)을 분리하여 애플리케이션 레이어에서 처리해야 한다. 객체지향 데이터 저장소는 데이터와 그 데이터에 대한 행동(메서드)을 하나의 객체로 묶어서 관리하여, 객체 내부에 데이터를 조작하는 메서드가 포함될 수 있다.
-
객체 간의 관계: 객체지향 데이터 저장소는 객체 간의 관계를 저장하고 관리할 수 있는 기능을 제공하여, 객체 간의 참조(reference)나 집합(composition) 관계 등을 데이터베이스에 저장할 수 있어, 관계형 데이터베이스에서의
JOIN과 같은 복잡한 관계 설정을 객체지향 데이터 저장소에서는 참조로 단순하게 처리할 수 있다. -
클래스 계층 구조와 상속 지원: 객체지향 데이터 저장소는 클래스 간의 상속 관계를 자연스럽게 저장하고 처리할 수 있어, 상위 클래스에서 정의한 속성이나 메서드를 하위 클래스에서도 재사용할 수 있다. 예를 들어,
Vehicle이라는 상위 클래스를 상속받는Car와Motorcycle이라는 하위 클래스가 있을 때, 각 객체의 공통적인 속성(speed,model등)을Vehicle에 정의하고, 하위 클래스에서 추가적인 속성이나 메서드를 정의할 수 있다.
객체지향 데이터 저장소의 장점
- 자연스러운 객체 저장: 객체지향 애플리케이션에서 사용하는 객체를 직렬화 없이 직접 데이터베이스에 저장할 수 있어 설계가 간단
- 객체 간의 참조 관리: 객체 간의 참조를 데이터베이스에 저장하여 객체의 관계를 직접적으로 유지 가능(
Order가Item을 참조하는 관계를 데이터베이스에서도 그대로 유지) - 상속 구조의 표현: 클래스 간의 상속 관계를 자연스럽게 표현할 수 있어, 데이터 모델과 비즈니스 모델 간의 불일치 이슈 해소
객체지향 데이터 저장소의 단점
- 데이터베이스 관리 도구의 부족: 관계형 데이터베이스에 비해 성숙한 관리 도구나 쿼리 최적화 도구가 부족
- 이식성 문제: 객체지향 데이터 저장소는 특정 프로그래밍 언어나 프레임워크에 종속되는 경우가 많아, 다른 환경으로의 이식이 어려움
- 대규모 데이터 처리의 한계: 관계형 데이터베이스에 비해 대규모 데이터의 처리나, 고성능 분산 처리 등의 기능에서는 한계가 있을 수 있음
ORM(Object-Relational Mapping)
ORM(Object-Relational Mapping)은 객체 지향 프로그래밍 언어의 객체를 관계형 데이터베이스의 테이블에 매핑(mapping)하여, 데이터베이스 조작을 객체 지향적인 방식으로 수행할 수 있게 해주는 기술이다. ORM을 사용하면 데이터베이스의 데이터를 직접적으로 조작하기 위한 SQL 쿼리를 작성하지 않고도, 객체지향 언어의 코드만으로 데이터베이스와 상호작용할 수 있다.
위에서 설명한대로 객체 지향 언어와 관계형 데이터베이스는 데이터와 그 구조를 다루는 방식에서 차이가 있기 때문에, 두 시스템 간의 임피던스 불일치(impedance mismatch) 문제가 발생하게 된다. 객체 지향 언어에서는 클래스와 객체를 사용하여 데이터를 다루지만, 관계형 데이터베이스에서는 테이블과 행, 열을 사용하여 데이터를 관리하기 때문에 다음 문제들이 발생할 수 있다.
- 데이터 구조 불일치: 객체 지향 언어에서는 상속과 다형성 등의 개념을 사용하지만, 관계형 데이터베이스는 이러한 개념을 미지원
- 매핑 코드의 중복: 데이터를 객체로 변환하거나 객체의 데이터를 테이블에 맞춰 변환하는 과정에서 매핑 코드가 많이 필요
- 직접 SQL 쿼리 작성의 불편함: 개발자가 SQL 쿼리를 직접 작성해야 하는 경우, 객체와 SQL 간의 매핑 로직을 수동으로 처리해야 하는 어려움
ORM은 이러한 문제를 해결하기 위해 객체와 데이터베이스 테이블 간의 매핑을 자동으로 처리해 주며, 개발자가 비즈니스 로직에 더 집중할 수 있도록 도와주는 기능이다.
엔티티(Entity)와 테이블(Table)
ORM에서 객체는 데이터베이스의 테이블과 매핑되며, 객체 지향 프로그래밍에서 사용하는 클래스가 데이터베이스의 테이블과 1:1로 매핑되고, 클래스의 인스턴스(객체)는 데이터베이스 테이블의 각 행(row)에 대응된다. 예를 들어, User 클래스를 데이터베이스의 users 테이블에 매핑할 수 있다.
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username;
private String email;
// Getters and Setters
}@Entity어노테이션은 이 클래스가 데이터베이스의 엔티티(테이블)와 매핑된다는 것을 의미@Id는id필드가 테이블의 기본 키(Primary Key)로 사용된다는 것을 의미@GeneratedValue는id값이 데이터베이스에서 자동으로 생성한다는 것을 의미
필드(Field)와 컬럼(Column)
클래스의 각 필드(멤버 변수)는 데이터베이스의 각 컬럼과 매핑되어, ORM은 필드와 컬럼 간의 매핑을 통해 객체의 필드 값을 데이터베이스의 컬럼 값과 자동으로 변환한다.
username필드는users테이블의username컬럼과 매핑email필드는users테이블의email컬럼과 매핑
연관 관계 매핑
객체 지향 프로그래밍에서는 객체 간의 관계를 1:1, 1:N, N:M으로 표현할 수 있으며, ORM을 사용하면 이러한 관계를 데이터베이스에 맞게 매핑을 지원한다.
-
1:1 관계: 하나의 객체가 다른 객체 하나와만 매핑되는 구조로, 사용자
User와 사용자 상세 정보UserProfile간의 관계가 1:1 관계이다.@OneToOne @JoinColumn(name = "profile_id") private UserProfile userProfile; -
1:N 관계: 하나의 객체가 여러 객체와 매핑될 수 있는 관계로 사용자
User와 그 사용자가 작성한Post간의 관계가 1:N 관계이다.@OneToMany(mappedBy = "user") private List<Post> posts; -
N:M 관계: 여러 객체가 여러 객체와 매핑될 수 있는 관계로 학생
Student와 수업Course간의 관계가 N:M 관계이다.@ManyToMany @JoinTable( name = "student_course", joinColumns = @JoinColumn(name = "student_id"), inverseJoinColumns = @JoinColumn(name = "course_id") ) private Set<Course> courses;
쿼리(Query)와 JPQL
ORM에서는 객체를 이용한 데이터베이스 조작을 쉽게 하기 위해, 객체 중심의 쿼리 언어를 제공하며, Java에서는 JPQL(Java Persistence Query Language)을 통해 SQL과 유사한 객체 기반 쿼리를 지원한다. JPQL에서 User 엔티티를 조회하는 JPQL 쿼리는 다음과 같다. JPQL은 데이터베이스 테이블이 아닌 엔티티와 그 필드를 기반으로 쿼리를 작성하며, entityManager를 통해 실행된다.
String jpql = "SELECT u FROM User u WHERE u.username = :username";
TypedQuery<User> query = entityManager.createQuery(jpql, User.class);
query.setParameter("username", "john_doe");
User user = query.getSingleResult();ORM의 장점
-
생산성 향상: ORM을 사용하면 SQL 쿼리를 직접 작성하지 않아도 되므로, 객체 지향 언어를 사용하는 개발자가 더 직관적으로 데이터베이스와 상호작용할 수 있고, ORM 라이브러리가 자동으로 CRUD(Create, Read, Update, Delete) 작업을 생성해 주기 때문에, 반복적인 쿼리 작성이 줄어들어 생산성이 향상될 수 있다.
-
유지보수 용이: 데이터베이스 테이블 구조가 변경되더라도 ORM 매핑 설정만 수정하면 되기 때문에, 애플리케이션 코드의 변경이 최소화될 수 있으며, 객체 지향 코드와 데이터베이스 스키마 간의 매핑을 자동으로 관리해 주기 때문에 코드 유지보수가 용이하다.
-
데이터베이스 독립성: ORM은 특정 DBMS에 종속되지 않고, 다양한 데이터베이스 시스템을 지원하므로, 개발자는 ORM을 통해 데이터베이스에 의존하지 않고, 객체 지향적인 프로그래밍에 집중할 수 있다. 예를 들어, 애플리케이션의 데이터베이스를 MySQL에서 PostgreSQL로 변경할 때, ORM을 사용하면 데이터베이스 변경의 영향을 최소화 할 수 있다.
ORM의 단점
- 성능 문제: ORM은 객체와 관계형 데이터베이스 간의 변환을 자동으로 처리하기 때문에, 이 과정에서 성능 오버헤드가 발생할 수 있다. 특히, 잘못된 연관 관계 설정이나
Eager Loading을 사용할 경우, 불필요한 데이터베이스 쿼리가 발생할 수 있으며, 성능 최적화를 위해 쿼리 동작을 세밀하게 관리해야 한다. - 복잡한 쿼리 처리의 어려움: 복잡한 SQL 쿼리를 필요로 하는 경우, ORM을 사용하는 것이 오히려 더 복잡하고 비효율적일 수 있어 ORM 대신, 네이티브 SQL 쿼리를 사용하는 것이 유리할 수 있다. 예를 들어, 복잡한 통계 데이터 조회나 특정 DBMS 기능(SQL Window 함수 등)을 활용해야 하는 경우에는 ORM으로 작성된 코드가 비효율적이거나 표현하기 어려울 수 있다.
- 초기 학습 비용: ORM은 초기 설정과 매핑 방법에 대한 학습이 필요하며, 엔티티 간의 관계 매핑이나 다양한 어노테이션의 사용법을 익히는 데 시간이 필요하다.
이벤트 소싱(Event Sourcing)
이벤트 소싱은 이벤트를 위주로 비즈니스 로직을 구현하고, 애그리거트를 DB에 일련의 이벤트로 저장하는 기법이다. 따라서 기존의 영속화 방식과 다르게, 애그리거트를 DB에 있는 이벤트 저장소에 이벤트로 저장한다. 즉, 이벤트는 계속 insert만 수행하고, 애그리거트를 로드할때 이벤트 저장소에 있는 이벤트를 재연하여 재 구성하는 형태이다.
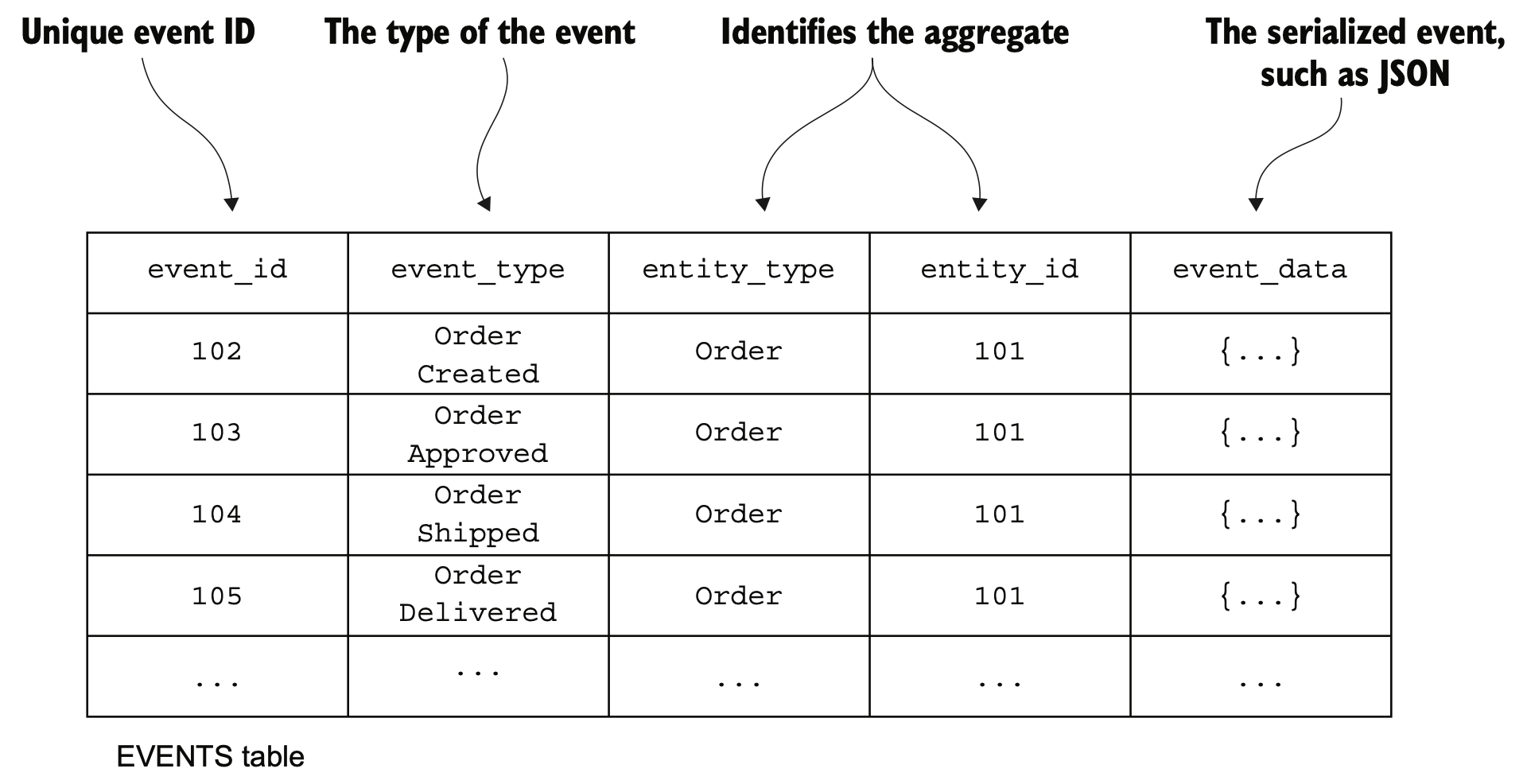
Event sourcing persists each aggregate as a sequence of events. A RDBMS-based application can, for example, store the events in an EVENTS table.
이벤트 소싱의 예시
출처:https://learn.microsoft.com/ko-kr/azure/architecture/patterns/event-sourcing
컨퍼런스 관리 시스템은 완료된 컨퍼런스 예약 수를 추적해야 합니다. 이를 통해 잠재적 참석자는 예약을 시도하면서 남은 자리가 있는지 확인할 수 있습니다. 다음과 같이 총 회의 예약 수를 둘 이상의 방법으로 저장할 수 있습니다.
예약 정보를 보유하는 데이터베이스에 총 예약 수에 대한 정보를 별도의 엔터티로 저장할 수 있습니다. 예약이 완료되거나 취소되면 시스템이 이 개수를 적절하게 증분하거나 감소할 수 있습니다. 이 접근 방법은 이론상 간단하지만, 짧은 기간 동안 많은 참석자가 좌석을 예약하려고 시도할 경우 확장성 문제가 발생할 수 있습니다. 예를 들어 예약 기간 마감 전날 등에 발생합니다.
시스템이 예약 및 취소 정보를 이벤트 저장소에 보류된 이벤트로 저장할 수 있습니다. 그런 다음 이 이벤트를 재생하여 사용 가능한 좌석 수를 계산할 수 있습니다. 이 접근 방법은 이벤트를 변경할 수 없기 때문에 더 확장성이 있습니다. 시스템이 이벤트 저장소에서 데이터를 읽거나 이벤트 저장소에 데이터를 추가할 수 있기만 하면 됩니다. 예약 및 취소에 대한 이벤트 정보는 수정되지 않습니다.
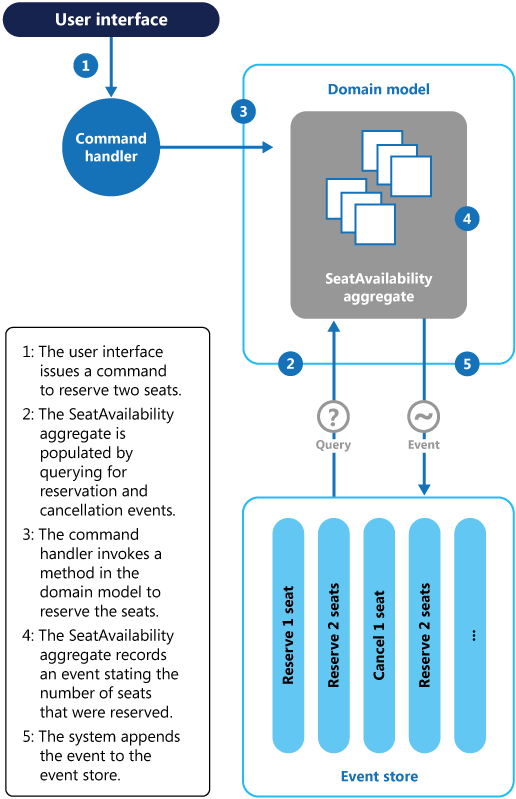
다음 다이어그램은 이벤트 소싱을 사용하여 회의 관리 시스템의 좌석 예약 하위 시스템을 구현할 수 있는 방법을 보여 줍니다.
이벤트 소싱을 사용하여 회의 관리 시스템에서 좌석 예약 정보 캡처
두 개의 좌석을 예약하기 위한 작업 시퀀스는 다음과 같습니다.
- 사용자 인터페이스가 두 명의 참석자를 위한 좌석을 예약하는 명령을 실행합니다. 명령은 별도의 명령 처리기에 의해 처리됩니다. 사용자 인터페이스에서 분리되고 명령으로 게시된 요청을 처리하는 논리 부분입니다.
- 예약 및 취소를 설명하는 이벤트를 쿼리하여 회의에 대한 모든 예약 정보를 포함하는 집계가 생성됩니다. 이 집계는
SeatAvailability라고 하며, 집계의 데이터를 쿼리하고 수정하기 위한 메서드를 노출하는 도메인 모델에 포함됩니다. 고려할 몇 가지 최적화는 스냅샷 사용(집계의 현재 상태를 얻기 위해 전체 이벤트 목록을 쿼리 및 재생할 필요가 없음) 및 메모리에 캐시된 집계 사본 유지 관리입니다.- 명령 처리기는 도메인 모델에서 노출된 메서드를 호출하여 예약을 수행합니다.
SeatAvailability집계는 예약된 좌석 수를 포함하는 이벤트를 기록합니다. 다음에 집계가 이벤트를 적용하면 모든 예약이 남아 있는 좌석 수를 계산하는 데 사용됩니다.- 시스템이 이벤트 저장소의 이벤트 목록에 새 이벤트를 추가합니다.
사용자가 좌석을 취소하는 경우 명령 처리기가 좌석 취소 이벤트를 생성하고 이벤트 저장소에 추가하는 명령을 사용한다는 점을 제외하고 시스템이 유사한 프로세스를 따릅니다.
이벤트 저장소를 사용하면 확장성의 범위가 더 넓어질 뿐 아니라 컨퍼런스 예약 및 취소의 전체 기록 또는 감사 추적도 제공됩니다. 이벤트 저장소의 이벤트는 정확한 레코드입니다. 시스템이 쉽게 이벤트를 재생하고 상태를 특정 시점으로 복원할 수 있으므로 다른 방법으로 집계를 유지할 필요가 없습니다.
애그리거트를 로드하기 위한 재 구성 방식은 다음 3단계로 구성된다.
- 애그리거트의 이벤트를 로드
- 기본 생성자를 호출하여 애그리거트 인스턴스를 생성
- 이벤트를 하나씩 순회하여
apply()를 호출
Eventuate Client 프레임워크 등을 구성하여 애그리거트의 상태를 재구성할 수 있게 한다. 이벤트를 가져와 재연하는 방식으로 in-memory의 상태를 다시 만들어내는 것은 한편으로는 비효율적으로 볼 수 있으나, 상태를 영속적으로 관리해야 하는 경우가 아닌, 클래스 인스턴스가 사용되고, 폐기되는데 짧은 라이프사이클을 가지고 있다면 가능성이 있는 방법 이며, 중간 중간 snapshot을 찍어서 애그리거트를 관리하는 형태로 구현하면 누적된 이벤트를 모두 처리하지 않고도 상태를 되돌릴 수 있다.
이벤트 특성
출처: MSDN
이벤트 소싱을 이해하려면 이벤트의 필수적인 특성을 포착하는 기본적인 이벤트 정의가 중요합니다.
- 사건은 과거에 발생합니다. 예를 들어, "연사가 예약되었습니다.", "좌석이 예약되었습니다.", "현금이 지급되었습니다." 과거 시제를 사용하여 이러한 사건을 설명하는 방식에 주목하세요.
- 이벤트는 변경할 수 없습니다. 이벤트는 과거에 발생하기 때문에 변경하거나 취소할 수 없습니다. 그러나 후속 이벤트는 이전 이벤트의 효과를 변경하거나 무효화할 수 있습니다. 예를 들어, "예약이 취소되었습니다"는 이전 예약 이벤트의 결과를 변경하는 이벤트입니다.
- 이벤트는 일방적 메시지입니다. 이벤트에는 이벤트를 게시하는 단일 소스(게시자)가 있습니다. 한 명 이상의 수신자(구독자)가 이벤트를 받을 수 있습니다.
- 일반적으로 이벤트에는 이벤트에 대한 추가 정보를 제공하는 매개변수가 포함됩니다. 예를 들어, "Seat E23은 Alice가 예약했습니다."
- 이벤트 소싱의 맥락에서 이벤트는 비즈니스 의도를 설명해야 합니다. 예를 들어, "Seat E23 was reserved by Alice"는 비즈니스 용어로 무슨 일이 일어났는지 설명하며 "예약 테이블에서 키 E23이 있는 행의 이름 필드가 값 Alice로 업데이트되었습니다."보다 더 설명적입니다.
이벤트, 그리고 상태 변화
도메인 이벤트는 애그리거트의 변경을 구독자에게 알리는 방법으로, 이벤트는 애그리거트ID 같은 필수 데이터만 넣거나, 혹은 이벤트강화(5장 참고)를 위해 구독자에게 필요한 추가 데이터를 포함하여 전송이 가능했다. 또한 도메인 이벤트는 구독자가 관심이 있는 변경(즉, 구독자가 이벤트 발생을 파악해야 하는 변경 건)에 대해서만 이벤트를 발생시킬 수 있었다. 그러나 이벤트 소싱에서는 생성을 비롯한 모든 상태 변화에 대하여 이벤트를 발생시키는 것이 필요하다는 차이점이 있고, 더욱이 이벤트 소싱에서의 이벤트는 애그리거트가 상태를 전이하기 위해 필요한 모든 데이터를 포함해서 발행해야 한다. 즉 주문 변경 이벤트를 가정하면, 주문 품목의 변경에 따른 OrderLineItem의 추가/삭제 내역도 같이 보내야 한다.
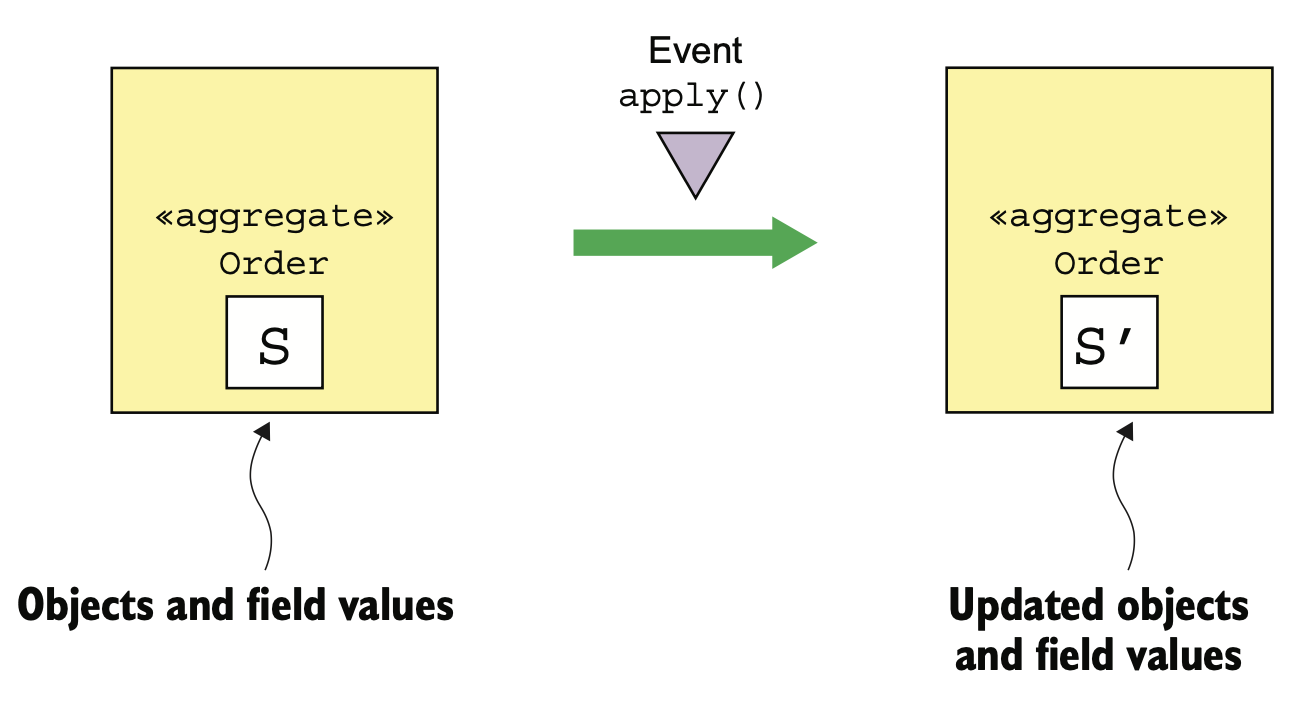
Applying event E when the Order is in state S must change the Order state to S'. The event must contain the data necessary to perform the state change.
위 그림에서 aggregate Order는 apply(E) 메소드를 호출하여 상태를 S에서 S' 으로 변경한다. 따라서 apply(E)를 처리하면서 변경될 상태 및 관련하여 필요한 정보는 event E에 포함되어 있어야 정상적인 처리가 가능하게 된다. 예를 들어 OrderCreatedEvent는 apply()가 처리하기 위한 주문 품목(OrderLineItem)이나, 지불 정보(PaymentInfo), 배달 정보(DeliveryInfo) 등을 생성하기 위한 데이터를 포함하고 있어야 한다. 이는 애그리거트를 이벤트로 저장하기 때문에 발생하는 필요사항이다.
애그리거트 메서드의 관심사는 오직 이벤트
이벤트 소싱 구조로 전환 하려면 기존의 커맨드를 처리하는 메소드에서 상태까지 변경하고 있던 비즈니스 로직을 재구성해서 커맨드를 처리하는 메서드와 애그리거트를 업데이트 하는 메소드로 분리해야 한다. 커맨드를 처리하는 메소드는 비즈니스 로직을 처리한 후에 상태 업데이트를 하지 않고, 변경 내역을 기반으로 상태 변경에 사용할 이벤트 목록을 반환하고, 애그리거트는 해당 이벤트를 처리하여 애그리거트를 업데이트 하는 형태로 리팩토링해야 한다.
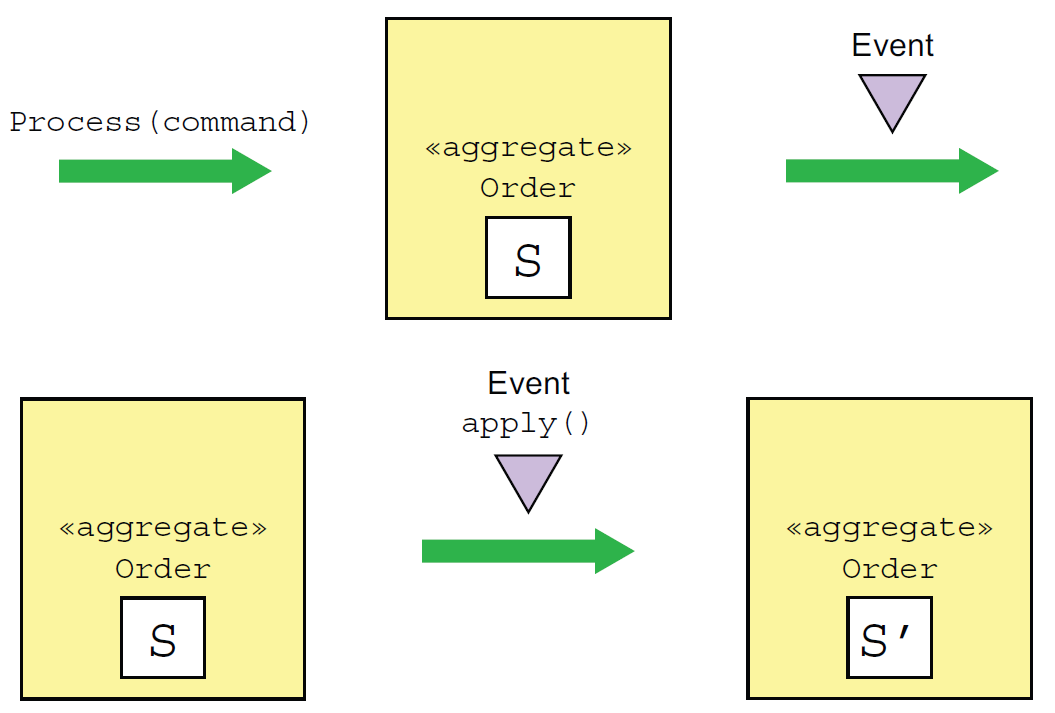
Processing a command generates events without changing the state of the aggregate. An aggregate is updated by applying an event.
이벤트 소싱 구조로 전환을 위해 기존에 커맨드를 받아 애그리거트를 업데이트 하던 revise() 메소드는 process() 메소드와 apply() 메소드로 분리해서 구현한다.
process(): 커맨드를 처리하고, 변경되어야 할 이벤트를 반환하거나 예외 처리(주문수량 불일치 등)apply():process()에서 반환환 결과를 가지고 애그리거트의 상태를 변경
이벤트 소싱 패턴을 적용하려면 애그리거트는 다음 형태로 구성되어야 한다.
애그리거트 생성
- 기본 생성자로 애그리거트 루트를 초기화
process()를 호출하여 새 이벤트를 발생- 생성된 새 이벤트를 하나씩 순회하면서
apply()를 호출하여 애그리거트를 업데이트 - 이벤트 저장소에 새 이벤트를 저장
애그리거트 업데이트
- 이벤트 저장소에서 애그리거트 이벤트를 로드
- 기본 생성자로 애그리거트 루트를 초기화
- 가져온 이벤트를 하나씩 순회하며 애그리거트 루트의
apply()호출 process()를 호출하여 새 이벤트를 발생- 새 이벤트를 순회하면서
apply()를 호출하여 애그리거트를 업데이트 - 이벤트 저장소에 새 이벤트를 저장
이벤트 소싱 패턴을 적용하기 위해 Order 클래스의 애그리거트 필드와 클래스 인스턴스 초기화 메서드 (애그리거트 생성)의 소스 코드 예제는 다음과 같다. Order 클래스의 필드는 앞에서 살펴 보았던 JPA 패턴과 비슷하나, 애그리거트에 애그리거트의 ID를 보관하지 않는다는 차이점이 있다. 또한 메소드는 기존에 createOrder(), revise() 처럼 애그리거트를 생성하거나 수정하는 메서드가 process()와 apply()로 되체되었다. process()는 CreateOrderCommand를 받아 OrderCreatedEvent를 발생시키고 apply()는 OrderCreatedEvent를 받아 Order의 각 필드를 초기화하는 형태로 동작한다.
public class Order {
private OrderState state;
private Long consumerId;
private Long restaurantId;
private OrderLineItems orderLineItems;
private DeliveryInformation deliveryInformation;
private PaymentInformation paymentInformation;
private Money orderMinimum;
public Order() {
}
public List<Event> process(CreateOrderCommand command) { // 커맨드 검증 후 OrderCreatedEvent 반환하는 메소드
... 커맨드 검증 ...
return events(new OrderCreatedEvent(command.getOrderDetails()));
}
public void apply(OrderCreatedEvent event) { // Order 필드를 초기화해서 OrderCreatedEvent 적용
OrderDetails orderDetails = event.getOrderDetails();
this.orderLineItems = new OrderLineItems(orderDetails.getLineItems());
this.orderMinimum = orderDetails.getOrderMinimum();
this.state = CREATE_PENDING;
}Order 클래스의 비즈니스 로직 중 조금 더 복잡한 주문 변경 메소드의 구현을 살펴보자. JPA에서 구현된 revise(), comfirmRevision(), rejectRevision()의 메소드는 이벤트 소싱 패턴을 적용하면 앞에서 살펴본 것 처럼 process(), apply()로 변경된다. 결국 revise() 메소드는 process(ReviseOrder)와 apply(OrderRevisionProposed) 메소드로 대체되었고, confirmRevision() 메소드는 process(ConfirmReviseOrder)와 apply(OrderRevised) 메소드로 대체되었다.
public List<Event> process(ReviseOrder command) { // 변경 가능한 Order인지, 변경 주문 수량이 최소 주문량 이상인지 확인
OrderRevision orderRevision = command.getOrderRevision();
switch (state) {
case APPROVED:
LineItemQuantityChange change =
orderLineItems.lineItemQuantityChange(orderRevision);
if (change.newOrderTotal.isGreaterThanOrEqual(orderMinimum)) {
throw new OrderMinimumNotMetException();
}
return singletonList(new OrderRevisionProposed(orderRevision,
change.currentOrderTotal, change.newOrderTotal));
default:
throw new UnsupportedStateTransitionException(state);
}
}
public void apply(OrderRevisionProposed event) {
this.state = REVISION_PENDING;
}
public List<Event> process(ConfirmReviseOrder command) {
OrderRevision orderRevision = command.getOrderRevision();
switch (state) {
case REVISION_PENDING:
LineItemQuantityChange licd =
orderLineItems.lineItemQuantityChange(orderRevision);
return singletonList(new OrderRevised(orderRevision,
licd.currentOrderTotal, licd.newOrderTotal));
default:
throw new UnsupportedStateTransitionException(state);
}
}
public void apply(OrderRevised event) {
OrderRevision orderRevision = event.getOrderRevision();
if (!orderRevision.getRevisedLineItemQuantities().isEmpty()) {
orderLineItems.updateLineItems(orderRevision);
}
this.state = APPROVED;
}낙관적 잠금
여러 요청이 동시에 동일한 애그리거트를 변경하고자 하는 경우를 대비하기 위해 낙관적 잠금(optimistic locking)을 사용할 수 있었다. 애그리거트 루트에 version 컬럼을 관리하면서 애그리거트가 업데이트 될때마다 버전을 1씩 증가시키고, 각각의 프로세스에서는 자신이 트랜잭션에 들어갔을때 버전과 종료핼때의 버전 값의 차이를 보고 다른 부분이 있으면 업데이트를 실패하는 형태로 동작하게 된다. 즉, 동시에 두개의 트랜잭션이 진행된다면 값을 읽을때와 쓸때 애그리거트 루트의 version 필드의 값이 동일하면 커밋을 성공하게 되고, version 필드의 값이 읽었을때와 쓸때 다르다면 트랜잭션을 실패하게 하는 것이다.
UPDATE AGGREGATE ROOT_TABLE
SET VERSION = VERSION + 1 ...
WHERE VERSION = <원본 버전>이벤트 저장소도 낙관적 잠금 패턴을 활용하여 동시 업데이트를 처리할 수 있다. 이벤트에 포함된 버전 정보를 각 애그리거트 인스턴스에 관리하고, 어플리케이션이 이벤트를 삽입할 때 이벤트 저장소가 버전의 변경 여부를 검사하는 형태로, 이벤트 번호를 버전 번호로 사용하거나, 혹은 이벤트 저장소가 명시적으로 버전 번호를 관리하는 형태도 가능하다.
이벤트 발행
이벤트 소싱은 애그리거트를 이벤트로 저장하는 형태로, 이벤트의 저장은 우너자적으로 처리되어야 한다. 이렇게 저장된 이벤트를 모든 컨슈머에게 안정적으로 전달하는 방법이 필요하며 EVENTS 테이블에 이벤트를 영구히 저장하는 것이 필요하다.
이벤트 발행: 폴링
이베트 소싱에서 각 애그리거트에 발생된 이벤트를 EVENTS 테이블에 저장한다고 가정하면, 이벤트 발행기는 DB에 이벤트가 발행하였는지 확인을 위해 EVENTS 테이블을 지속 polling 하다가 새 이벤트라 발생하면 메시지 브로커에 해당 이벤트를 발행한다. 다만 여기서 해결해야 할 문제는 기존에 처리한 이벤트와 새로운 이벤트를 구분하는 것이다. 만약 EVENT_ID라는 필드가 순차적으로 증가하는 것이 보장된다면, 이벤트 발행기는 자신이 마지막으로 성공적으로 처리한 EVENT_ID를 기록하고, 해당 값보다 큰 이벤트만 처리하는 형태로 가능할 수 있다. 그러나 여기서 중요한 문제가 발생되는데, 트랜잭션이 이벤트를 발생시키는 순서와 다르게 커밋될 수도 있다는 점이다. 그렇게 되면 이벤트 발생기가 이벤트를 건너뛰는 문제가 발생할 수 있다.
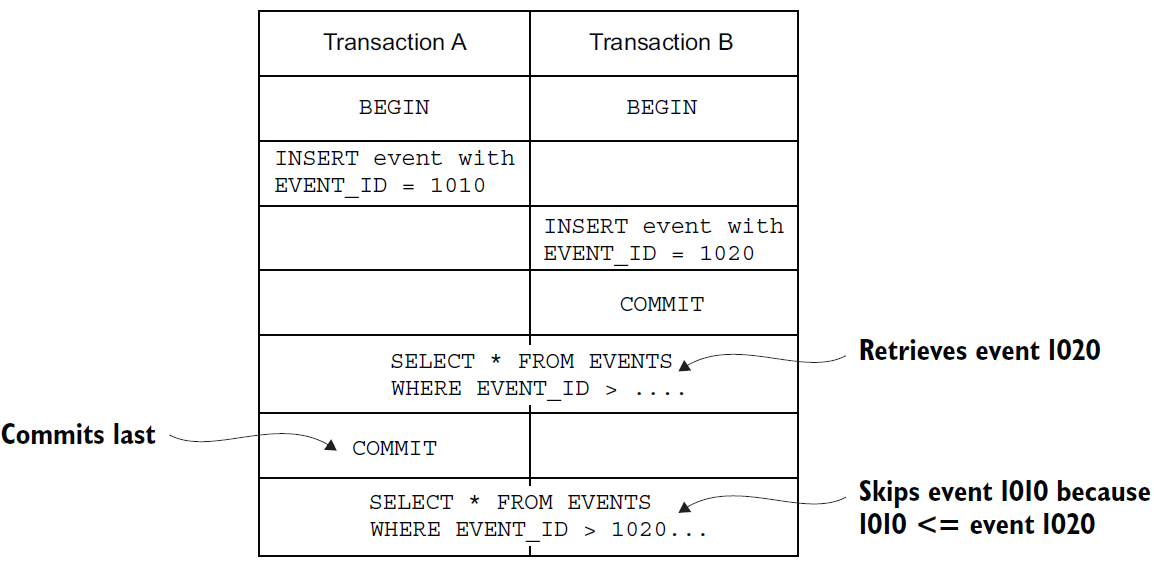
A scenario where an event is skipped because its transaction A commits after transaction B. Polling sees eventId=1020 and then later skips eventId=1010.
위 그림의 예제를 보면, 트랜잭션 A가 EVENT_ID = 1010 이벤트를 삽입하고, 트랜잭션 B가 EVENT_ID = 1020 이벤트를 삽입한 후 커밋을 처리하면, 이벤트 발행기가 EVENT 테이블을 쿼리하면 1020 이벤트가 조회되게 된다. 트랜잭션 A가 커밋된 후 1010이 조회가 가능하게 된다 하더라도, 이벤트 발행기는 1010을 무시하게 된다. 이러한 문제를 해결하기 위해서 EVENT 테이블에 이벤트 발행 여부를 추적할 수 있는 컬럼(PUBLISHED)을 추가한다. 이벤트 발행기는
SELECT * FROM EVENTS WHERE PUBLISHED = 0 ORDER BY EVENT_ID ASC 쿼리로 발행되지 않은 이벤트를 검색하고, 오더 순서에 따라 메시지 브로커에 이벤트를 발행한다. 이후 이벤트가 정상적으로 발행되었다면 UPDATE EVENTS SET PUBLISHED = 1 WHERE EVENT_ID = ? 형태의 업데이트를 처리하여 해당 이벤트가 발행된 것으로 표시할 수 있다.
이벤트 발행: 로그 테일링
트랜잭션 로그 테일링을 통한 이벤트 발행하는 방법이 있다. 메시지 릴레이를 통해 DB 트랜잭션 로그(커밋 로그)를 tailing하는 방법으로, 애플리케이션에서 커밋된 EVENTS 테이블의 업데이트를 각 DB의 트랜잭션 로그 항목(log entry)으로 남기면, 트랜잭션 로그 마이너(transaction log miner)가 해당 트랜잭션 로그를 읽어 변경 분을 하나씩 메시지로 메시지 브로커에 발행하는 절차로 수행될 수 있다. 교재에서는 저자가 만든 이벤추에이트 로컬(Eventuate Local)을 통해 설명하고 있다.
스냅샷
애그리거트의 상태 전이가 많다면 최종 상태를 재연하기 위해서 많은 처리가 필요하다. 특히 수명이 긴 애그리거트는 이벤트 수가 엄청 늘어날 수 있다. 따라서 애그리거트의 상태를 스냅샷을 만들어 보관하고, 해당 스냅샷 이후부터 재연을 수행하여 애그리거트의 상태를 복원하는 방법을 사용할 수 있다.
Using a snapshot improves performance by eliminating the need to load all events. An application only needs to load the snapshot and the events that occur after it.
위 그림은 N번의 이벤트가 발생된 상태에서 스냅샷 버전을 찍어 N으로 표기한 상태를 나타낸다. 서비스는 가장 마지막 스냅샷(N버전)을 읽어오고, N+1 에서부터 발생한 나머지 이벤트(본 예제에서는 N+1과 N+2 2개)만 가져와서 애그리거트 상태를 되살릴 수 있다. 즉 스냅샷 N 이전에 발생되었던 N개는 이벤트 저장소에서 가져올 필요가 없어지므로 DB 조회 부하 및 재연에 따른 성능 등의 문제를 해소할 수 있게 된다.
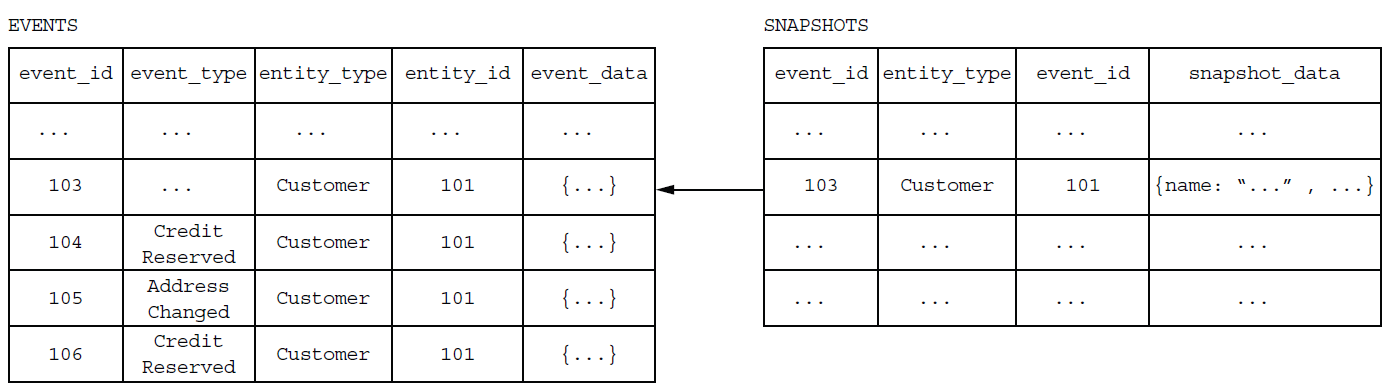
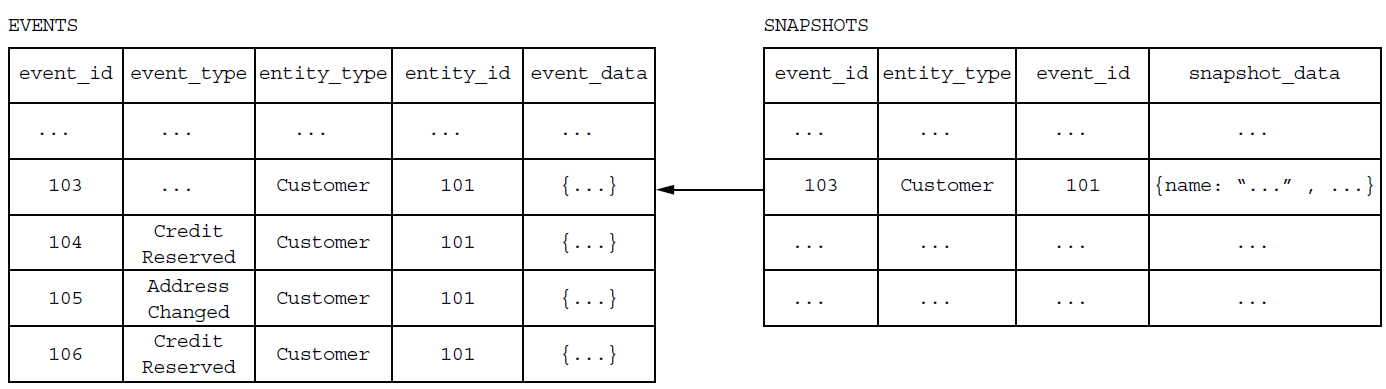
The Customer Service recreates the Customer by deserializing the snapshot’s JSON and then loading and applying events #104 through #106.
스냅샷에서 애그리거트 상태를 복원하기 위해서는, 마지막 스냅샷을 읽어서 해당 스냅샷 기준으로 애그리거트 인스턴스를 생성한 후 잔여 이벤트를 하나씩 순회하며 적용한다.
멱등한 메시지 처리
메시지 구독자는 애그리거트가 발행한 도메인 이벤트나 커맨드 메시지를 소비할때 멱등성을 지원하도록 개발해야 한다. 이벤트 소싱에서 발생되는 애그리거트의 변경 이벤트를 받으면, 수신한 이벤트는 EVENTS 테이블에 삽입하면서 동일한 트랜잭션으로 처리한 메시지의 ID를 PROCESSED_MESSAGES 테이블에 기록하면 기 처리된 메시지를 구분할 수 있게 된다. 그러나 사용하는 DBMS가 RDBMS가 아니라 ACID 트랜잭션을 지원하지 않을 수 있으므로 다른 방법을 고려해야 한다. 메시지 컨슈머가 메시지 처리 도중 생성된 메시지 ID를 저장하고, 해당 메시지 ID가 애그리거트의 이벤트에 있는지 확인하면 중복 메시지 여부를 알 수 있지만, 메시지 처리 결과 아무 이벤트도 생성되지 않을 수도 있다. 만약 이벤트가 생성되지 않는 경우라면 메시지의 처리 기록 또한 없게 되므로, 이후에 같은 메시지를 재전달/재처리하게 되면 다음과 유사한 오류가 발생될 수 있다.
- 메시지 A는 처리되나, 애그리거트는 업데이트 되지 않는다.
- 메시지 B가 처리되고 메시지 컨슈머는 애그리거트를 업데이트한다.
- 메시지 A가 재전달되고 처리 기록이 없기 때문에 메시지 컨슈머는 애그리거트를 업데이트 한다.
- 메시지 B는 다시 처리되고....
이러한 문제를 해결하는 방법은 항상 이벤트를 발행하는 것으로, 애그리거트가 이벤트를 발생시키지 않아도 되는 상황이라 핟라도, 메시지 ID를 기록할 목적으로 의사 이벤트(pseudo-event)를 저장하고, 이러한 이벤트는 이벤트 컨슈머가 무시하도록 개발하는 것이 필요하다.
도메인 이벤트의 진화
이벤트 소싱은 개념적으로 이벤트를 영구 저장하는 것은 양날의 검이 될 수있다. 정확성을 담보할 수 있는 변경 감사 로그를 제공하고, 어플리케이션이 애그리거트의 상태를 과거로부터 단계적으로 재구성할 수 있는 반면에, 이벤트의 구조는 어플리케이션의 진화에 따라 계속 변화할 수 있기 때문에 새로운 문제가 야기된다.
어플리케이션은 반드시 여러 버전의 이벤트를 처리할 수 있어야 한다. 예를 들어 Order 애그리거트를 불러오는 서비스는 물론 이벤트 구독기도 여러 버전의 이벤트를 구성해야 할 수 있다.
이벤트 스키마
이벤트 소싱에 기반한 애플리케이션의 스키마는 개념상 다음 세 가지로 구성된다.
- 하나 이상의 애그리거트
- 각 애그리거트가 발생시키는 이벤트의 정의
- 이벤트 구조의 정의
어플리케이션의 서비스 도메인 모델이 발전하면서 아래와 같은 변화는 지속 발생되게 된다. 하위 호환성을 보장하기 위해서는 필드 추가 등은 용이하게 가능하나 그렇지 않으면 어려운 문제가 발생할 수 있다.
| 수준 | 변경 | 하위 호환성 |
|---|---|---|
| 스키마 | 새 애그리거트 타입 정의 | 예 |
| 애그리거트 삭제 | 기존 애그리거트 삭제 | 아니요 |
| 애그리거트 개명 | 애그리거트 타입명 변경 | 아니요 |
| 애그리거트 | 새 이벤트 타입 추가 | 예 |
| 이벤트 삭제 | 이벤트 타입 삭제 | 아니요 |
| 이벤트 개명 | 이벤트 타입명 변경 | 아니요 |
| 이벤트 | 새 필드 추가 | 예 |
| 필드 삭제 | 필드 삭제 | 아니요 |
| 필드 개명 | 필드명 변경 | 아니요 |
| 필드 타입 변경 | 필드 타입 변경 | 아니요 |
업캐스팅
DB 스키마 변경은 보통 마이그레이션을 이용하여 처리하고 있다. 즉, 새 스키마에 기존 데이터를 옮기는 SQL 스크립트 등을 실행해서 주로 한번에 전환 처리를 수행한다. 이러한 스키마 마이그레이션은 버전 관리 시스템에 저장하고 별도의 툴(flyway 등)을 써서 처리하며, 일반적으로 시스템의 다운 타임을 야기할 수 있다.
이벤트 소싱 애플리케이션도 하위 호환이 안 되는 변경을 비슷한 방법으로 처리할 수 있지만, 마이그레이션 보다는 이벤트 소싱 프레임워크에서 이벤트를 로드할 때 바꾸는 형태로 전환을 수행한다. 이를 위해 업캐스터(upcaster)라고 하는 컴포넌트가 개별 이벤트를 구 버전에서 신 버전으로 업데이트하므로 애플리케이션 코드는 현재 이벤트 스키마를 처리하는 것으로 충분하게 된다.
이벤트 소싱의 장/단점
지금까지 이벤트 소싱을 살펴보았고, 이제 이벤트 소싱을 적용했을때 고려해야 하는 장단점을 살펴본다.
장점
- 도메인 이벤트를 확실하게 발행하도록 하며, 애그리거트 상태가 변경될 때마다 이벤트를 발행하여 감사 로그 등도 손쉽게 구현 가능하다.
- 애그리거트 이력 보존을 지원하므로 애그리거트 과거 상태를 임시 쿼리로 쉽게 조회할 수 있다. 예를 들어 어떤 고객이 과거 특정 시점에 신용 한도가 얼마였는지 사후에도 쉽게 복원이 가능하다.
- O/R 임피던스 불일치 문제를 거의 방지할 수 있도록 한다. 이벤트를 취합하는 대신 저장하는데, 이벤트는 보통 쉽게 직렬화할 수 있는 단순한 구조(서비스는 과거 상태를 죽 나열해서 복잡한 애그리거트 스냅샷을 만들 수 있음)이므로 애그리거트와 애그리거트를 직렬화한 표현형 사이를 한 수준 더 간접화(indirection)하여 문제를 회피할 수 있다.
- 개발자에게 타임머신 제공은 어플리케이션이 동작 중 발생한 모든 이벤트를 기록하여 남기기 때문에 과거에 문제를 빠르게 분석하고, 대응할 수 있도록 지원한다.
이벤트 소싱의 단점
- 개발자 학습 시간: 개발자가 새로운 프로그래밍 모델을 배우려면 시간이 걸리며, 비즈니스 로직을 재작성이 필요하다.
- 메시징 기반 애플리케이션의 복잡함: 메시지 브로커가 적어도 1회 이상 전달하는 특성을 활용하기 때문에 이벤트 핸들러는 멱등성 확보를 위해 중복 이벤트를 걸러내는 기능 등을 추가로 개발해야 한다. 그러나 프레임워크에서 이벤트별 incremental id를 부여함으로써 중복 이벤트를 필터링 하는 등의 방법을 사용할 수 있다.
- 이벤트를 발전시키기 어려움: 이벤트 스키마가 발전되면서, 영구 저장되는 애그리거트는 각 스키마 버전별로 이벤트를 폴드해야 한다. 즉, 스키마 버전에 따른 분기 처리가 필요하게 된다. 다만 앞에서 살펴본대로 이벤트 저장소에서 가져올 때 최신 버전으로 업그레이드 하는 업캐스팅을 사용하면 애그리거트에 있는 이벤트를 업그레이드하는 코드를 따로 분리하여 애그리거트는 최신 버전의 이벤트만 적용하도록 할 수 있다.
- 데이터 삭제의 어려움: 이베트를 영구 저장하는 것을 기본으로 하는 이벤트 소싱에서는 이벤트에 삭제 플래그를 업데이트 하는 형식으로 soft delete를 수행하면, 해당 이벤트를 구독한 구독자 역시 유사/동일하게 작업을 한다. 그러나 GDPR 등의 규제 이슈로 인해 데이터를 영구 삭제해야 하는 경우에는 soft delete로는 규제 대응이 어렵다. 따라서 사용자별 암호화 키를 임의 발급하고, 암호화 키 테이블에 해당 정보를 저장한 뒤, soft delete가 발생되면 해당 암호화 키를 삭제하는 형태로 우회 적용이 가능할 수 있다. 그럼에도 불구하고 완전 삭제와 다른 형태이므로 가명화(pseudonymization) 기법을 사용하여 이메일/전화번호 등을 UUID 토큰으로 매핑시켜 관리하는 형태가 가능하다.
- 이벤트 저장소 쿼리의 어려움: 예를 들어 신용 한도가 소진된 고객을 찾는다고 가정하면 이벤트 테이블에는 신용 한도를 가리키는 별도의 컬럼을 관리하지 않기 때문에
SELECT * FROM CUSTOMER WHERE CREDIT_LIMIT = 0같은 쿼리를 사용할 수 없다. 따라서 처음에 신용 한도를 설정한 이후 업데이트한 이벤트를 폴드해서 신용 한도를 계산할 수 밖에 없는데, SELECT 문이 중첩된 매우 복잡하고 비효율적인 쿼리를 사용하게 되며, 심지어 NoSQL 이벤트 저장소는 대부분 기본키 검색만 지원하므로 CQRS 방식으로 쿼리를 지원해야 한다.
상태에 대해 이벤트를 폴딩(folding)한다는 것은 다음을 의미합니다: 초기 상태와 첫 번째 이벤트에 대해 Apply 함수가 호출되어 새로운 상태를 계산하고, 이 새로운 상태는 다음 이벤트와 함께 Apply의 다음 호출에 전달됩니다. 이 과정은 이벤트가 모두 소진될 때까지 반복되며, 최종적으로 상태의 마지막 버전을 반환합니다. (번역: claude.ai)
Folding events over the state means that the Apply function is called on the initial state and the first event to calculate a new state, which is in turn passed to the next invocation of Apply with the next event. This process is repeated until we run out of events and return the final version of the state.

Fold of events illustrated - 출처: https://dev.to/jakub_zalas/functional-event-sourcing-1ea5
이벤트 저장소의 구현
이벤트 저장소는 ACID를 지원하는 RDBMS를 사용하여 이벤트를 저장하고, 어플리케이션은 애그리거트 이벤트를 기본키로 insert 하면 메시지 브로커(Kafka 등)에서 이벤트를 보내고, 받아서 처리하는 형태로 구현할 수 있다. 예제의 이벤트 저장소는 EVENTS, ENTITIES, SNAPSHOTS의 3개 테이블을 사용하여, find(), create(), update()의 3개의 작업으로 구성된다.
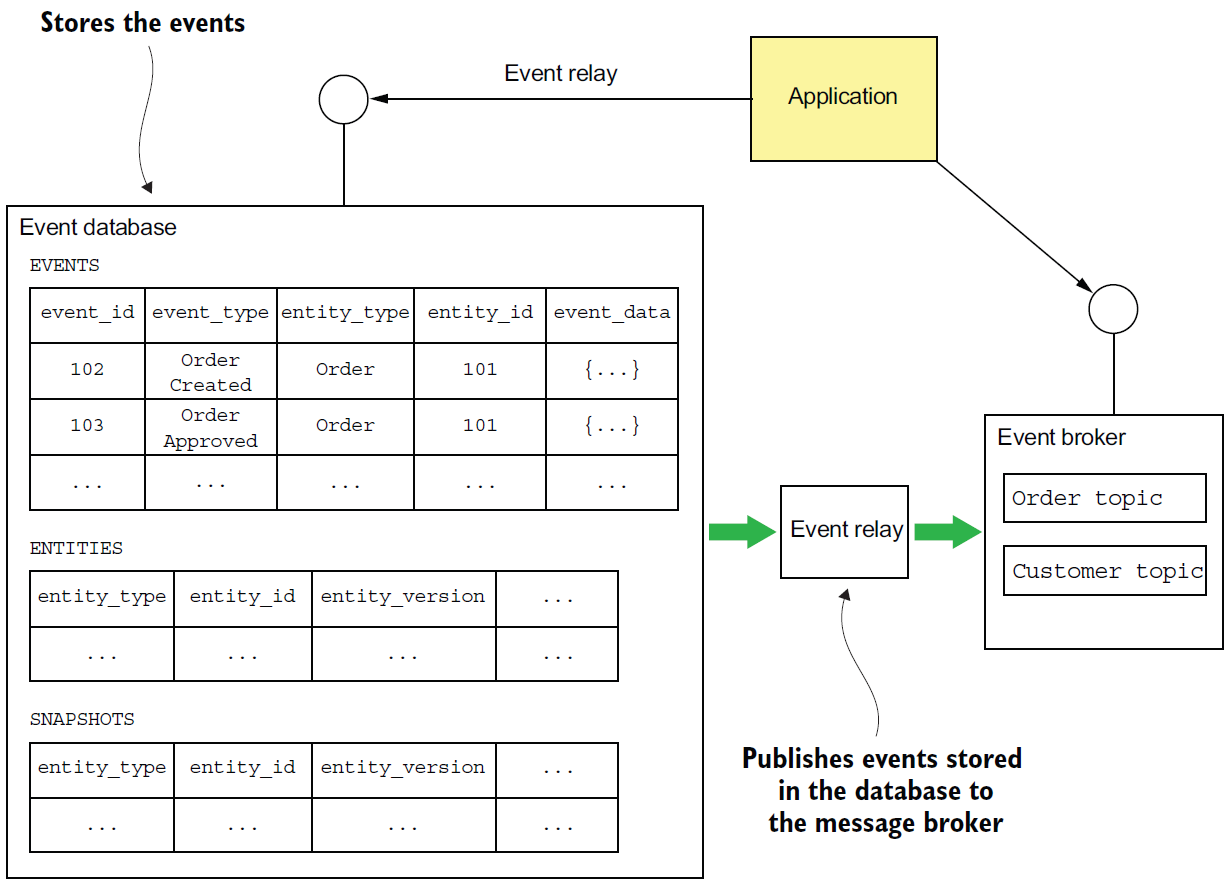
The architecture of Eventuate Local. It consists of an event database (such as MySQL) that stores the events, an event broker (like Apache Kafka) that delivers events to subscribers, and an event relay that publishes events stored in the event database to the event broker.
테이블 스키마
EVENTS 테이블
핵심이 되는 테이블인 EVENTS 테이블은 이벤트에 대한 정보를 저장하는 테이블이다. triggering_event는 중복 이벤트/메시지를 발견하는 용도의 컬럼으로 이벤트를 생성한 메시지/이벤트의 ID를 저장한다.
create table events(
event_id varchar(1000) PRIMARY KEY,
event_type varchar(1000) NOT NULL,
event_data varchar(1000) NOT NULL,
entity_type varchar(1000) NOT NULL,
entity_id varchar(1000) NOT NULL,
triggering_event varchar(1000)
);ENTITIES 테이블
ENTITIES 테이블은 엔터티별 현재 버전을 저장하고, 낙관적 잠금을 구현하는 용도로 사용한다. 엔터티가 생성되면 이 테이블에 한 행이 삽입되고, 엔터티가 업데이트 될때마다 entity_version 컬럼도 같이 업데이트한다.
create table entities(
entity_type varchar(1000),
entity_id varchar(1000),
entity_version varchar(1000) NOT NULL,
PRIMARY KEY(entity_type, entity_id)
);SNAPSHOTS 테이블
SNAPTSHOTS 테이블은 각 엔터티 별 snapshot을 저장하는 테이블로, snapshot_json 컬럼은 엔터티를 직렬화한 표현형이고, snapshot_type은 그 타입을 가리키며, entity_version은 스냅샷을 만들때의 엔터티의 버전을 나타낸다.
create table snapshots(
entity_type varchar(1000),
entity_id varchar(1000),
entity_version varchar(1000) NOT NULL,
snapshot_type varchar(1000) NOT NULL,
snapshot_json varchar(1000) NOT NULL,
triggering_event varchar(1000)
PRIMARY KEY(entity_type, entity_id, entity_version)
);구현 기능
find():SNAPSHOTS테이블에서 가장 최근 스냅샷을 조회한 후, 스냅샷이 존재하면EVENTS테이블을 뒤져event_id가 스냅샷의entity_version보다 크거나 같은 이벤트를 모두 찾고, 스냅샷이 존재하지 않으면 주어진 엔티티의 이벤트를 모두 조회하여 엔터티를 재 구성하는데 필요한 정보를 확보한다. 또한ENTITIES테이블에서 엔티티 현재 버전을 가져온다.create():ENTITIES테이블에 새로운 행을 삽입하면서EVENTS테이블에 새로운 이벤트를 삽입한다.update():EVENTS테이블에 이벤트를 삽입하고UPDATE문으로ENTITIES테이블에 있는entity_version을 업데이트해서 낙관적 잠금을 처리한다.
이벤트 순서 보장
소비자는 Apache Kafka 등을 메시지 브로커로 사용하면서 애그리거트 종류마다 할당된 토픽을 이용하여 이벤트를 소비하며 토픽을 활용하면 메시지 순서를 유지한 채 수평 확장이 가능하다. 또한 애그리거트 ID를 파티션 키로 사용하여 이벤트 순서가 보장되도록 수평 확장을 지원할 수 있다.
로컬 이벤트 릴레이
이벤트 릴레이는 이벤트 DB에 삽입된 이벤트를 이벤트 브로커로 전파하는 역할을 수행한다. 트랜잭션 로그 테일링을 이용할 수 있으며, 주기적으로 DB를 폴링해서 처리할 수도 있다. 예를 들어 마스터/슬레이브 복제 프로토콜을 사용하는 MySQL을 사용한다면, 이벤트 릴레이는 자신이 슬레이브인 것 처럼 MySQL 서버에 접속하여 binlog(MySQL의 업데이트 기록)을 읽어서 처리한다. 만약 EVENTS 테이블에 새로운 이벤트가 삽입되면 해당 이벤트를 가져다가 아파치 카프카 토픽으로 발행하며, 다른 종류의 변경은 이벤트 릴레이가 무시할 수있다.
추천 링크
- https://www.eventstore.com/event-sourcing
- https://dev.to/jakub_zalas/functional-domain-model-o3j
- https://www.youtube.com/watch?v=TDhknOIYvw4
- https://www.baeldung.com/cs/saga-pattern-microservices
- https://docs.google.com/presentation/d/12GONAxf0VJT08QVN38M7Ahn970ITtpPSZBFkEF0WvC0/edit#slide=id.g45ffbc1ece_2_0
