https://www.dataq.or.kr/www/board/view.do
[패키지 리스트 확인 명령어]
응시환경에서 아래 명령어를 이용하여 설치된 패키지를 확인할 수 있습니다.
import pkg_resources
import pandas
OutputDataSet = pandas.DataFrame(sorted([(i.key, i.version) for i in pkg_resources.working_set]))
print(OutputDataSet)
[패키지 리스트]
0 asn1crypto 0.24.0
1 beautifulsoup4 4.9.3
2 certifi 2018.1.18
3 chardet 3.0.4
4 cryptography 2.1.4
5 cycler 0.10.0
6 cython 0.29.24
7 distlib 0.3.2
8 idna 2.6
9 joblib 1.0.1
10 keyring 10.6.0
11 keyrings.alt 3.0
12 kiwisolver 1.3.1
13 lightgbm 3.3.2
14 matplotlib 3.4.2
15 numpy 1.21.1
16 pandas 1.4.2
17 pillow 8.3.1
18 pip 21.1.3
19 pycrypto 2.6.1
20 pygobject 3.26.1
21 pyparsing 2.4.7
22 python-apt 1.6.5+ubuntu0.6
23 python-dateutil 2.8.2
24 pytz 2021.1
25 pyxdg 0.25
26 requests 2.18.4
27 scikit-learn 0.24.2
28 scipy 1.7.0
29 secretstorage 2.3.1
30 selenium 3.141.0
31 setuptools 57.4.0
32 six 1.11.0
33 soupsieve 2.2.1
34 ssh-import-id 5.7
35 threadpoolctl 2.2.0
36 unattended-upgrades 0.1
37 urllib3 1.22
38 wheel 0.30.0
39 xgboost 1.4.2

- 시계열 분석에서는 주어진 자료가 정상성을 만족해야한다. 비정상시계열을 정상시계열 자료로 바꾸기 위해, 평균이 일정하지 않은 경우 현시점에서 이전 시점의 자료를 빼는 방법을 무엇이라고 하는가?
답. 차분(Difference)
- 기업의 합리적인 의사결정을 방해하는 요소로서 문제의 표현 방식에 따라 동일한 사건이나 상황임에도 불구하고 개인의 판단이나 선택이 달라질 수 있는 현상을 무엇이라고 하는가?
답. 프레이밍 효과(Framing Effect): 기업의 합리적인 의사결정을 방해하는 요소인 고정 관념, 편향된 생각
- 표본 추출 방법 중 질적인 원소들로 구성된 모집단에서 각 계층을 고루 대표할 수 있도록 표본을 추출하는 방법으로 유사한 원소끼리 몇개의 층으로 나누어 각 층에서 랜덤추출하는 방법은 무엇인가?
답. 층화 추출법(Stratified Random Sampling)
- 군집 추출법(Cluster Sampling): 모집단을 여러 군집으로 나누고, 일부 군집의 전체 또는 일부를 추출하는 방식, 내부적으로는 이질적, 외부적으로는 동질적인 방법
** 표본조사에는 확률표본추출과 비확률표본추출로 나뉘는데, 확률표본추출로는 단순 무작위 표본 추출, 체계 표본 추출, 층화 표본 추출, 군집 표본 추출이 있다. 비확률표본추출은 편의표본추출, 판단표본추출, 할당표본추출이 있다. 시험에는 확률표본추출법이 나올 가능성이 크므로 볼드 처리한 추출법에 대해 익히자.
- 군집 타당성 지표(Clustering Validity Index) 중의 하나로 군집 내의 데이터 응집도(Cohesion)와 군집간 분리도(Separation)를 계산하며 계산된 결과는 -1에서 1사이의 값을 가지고, 군집 분석이 잘 된 경우 1에 가까운 값을 가지는 지표는 무엇인가?
답. 실루엣(Silhoutte)
- 실루엣 지표는 -1과 1사이의 값을 가진다. 군집 내의 데이터의 거리가 짧을수록, 군집 간의 거리가 멀수록 값이 커진다.
1에 가까울수록 군집화가 잘 되어있고 -1에 가까울수록 군집 결과가 타당하지 않을 것으로 해석한다. 일반적으로 실루엣 지표가 0.5 이상일 경우 군집결과가 타당한 것으로 해석한다.
** 1과 -1 사이의 값을 가지는 것 중 대표적인 것이 피어슨 상관계수(Correlation coefficient)인데, 상관계수는 '전체 편차 내에서 예측치와 평균치 간의 차이가 차지하는 비율'로 편차 = 평균과 예측값 간의 차이 + 예측값과 실제 값의 차이 로 계산할 때 (예측값과 실제 값의 차이) / (전체 편차)의 비율을 계산해 상관관계를 계산한다. 따라서 군집 내의 응집도와 상관계수는 관계가 없음!
- 의사결정나무의 형성 과정 중 끝마디가 너무 많을 경우, 모형이 과적합(Over-fitting) 되어 현실 문제에 적용할 수 있는 적절한 규칙이 나오지 않게 되는 문제가 발생한다. 따라서 분류된 관측치의 비율 또는 MSE(Mean Squared Error)등을 고려해 적절한 수준의 ( ) 규칙을 제공해 주어야 한다.
답. 가지치기
- 정지규칙과 가지치기의 개념 차이를 알아야한다. 가지치기는 MSE(평균제곱합)이 언급됨을 알아두자.
정지규칙: 더 이상 분리가 일어나지 않고 현재의 마디가 끝마디가 되도록하는 여러가지 규칙. 정지규칙에 사용되는 지수로는 최대 나무의 깊이, 자식마디의 최소 관측치 수, 카이제곱 검정 통계량, 지니지수, 엔트로피지수 등이 언급됨을 알아두자.
** 종속변수의 형태에 따라 분류기준에 사용되는 지표가 다르다.
종속변수가 이산형일 경우: CHAID(카이제곱 통계량), CART(지니 지수), C4.5(엔트로피 지수)
종속변수가 연속형인 경우: CHAID(ANOVA-F 통계량), CART(분산감소량)
- 인공신경망에서 가중치 매개변수 기울기를 미분으로 계산하면 시간 소모가 크다. 이를 개선하여 오차를 출력층에서 입력층으로 전달하고, 연쇄법칙을 활용해 역전파를 통한 가중치와 편항을 갱신(Update)하는 것은?
답. 오차역전파(Error Back Propagation)
- 역전파 알고리즘: 인공신경망을 학습시키기 위해 사용하는 일반적일 알고리즘이다. 인공신경망을 학습시킨다는 것은 출력값과 실제값의 오차가 최소가 되는 가중치와 편향을 찾는 것을 의미한다. 오차가 본래의 진행 방향과 반대 방향으로 전파된다는 의미에서 역전파 알고리즘이라고 부른다. 역전파 알고리즘은 출력층에서 결정된 결곽값의 오차를 출력층에서 입력층으로 역으로 전파하며 오차가 최소가 되게 가중치를 갱신한다. 오차를 먼저 계산한 후 이 오차가 작아지는 방향으로 가중치를 조절하므로 입력층부터 모든 경우의 수에 대해 가중치를 계산하는 기존 방식보다 최적화 과정이 빠르고 정확하다(출처: 이지패스 2021 빅데이터분석기사 필기 3과목 빅데이터 모델링 380p).
** 경사하강법(Gradient Descent): 인공신경망에서 오차함수의 낮은 지점을 찾아가는 최적화 방법으로 낮은 쪽의 방향을 찾기 위해 오차함수를 현재 위치에서 미분한다. Step이 크면 최솟값을 지나칠 수 있고, 너무 작으면 최솟값까지 오랜 시간이 소요되므로 일반적으로 서로 다른 초기값을 주어 내려가게 한다.
- 코호넨에 의해 제시된 비지도 신경망으로 고차원의 데이터를 이해하기 쉬운 저차원의 뉴런으로 정렬하여 지도의 형태로 형상화한 군집분석방법은?
답. SOM(Self-Organizing Maps), 또는 자기조직화지도, 코호넨 맵: 가까운 뉴런은 더 가깝게, 먼 뉴런은 더 멀게 가중치를 조정해가며 군집을 형성하는 방법으로 인공신경망이 역전파 알고리즘을 통해 여러 단계의 피드백을 거치며 가중치를 학습하는 것과는 달리, SOM은 하나의 전방패스를 사용해 속도가 빠르고, 그에 따라 잠재적으로 실시간 학습 처리가 가능한 모델
- 비계층적 군집: K-means 군집, DBSCAN(Density Based Spatial Clustering of Application with Noise), 가우시안 혼합 모델, SOM
- 버섯을 구매한 고객이 치즈도 구매할 연관성에 대해 분석할 때 지지도, 신뢰도, 향상도는 무엇인가?
지지도: P(A 교집합 B) / P(전체 거래 수)
신뢰도: P(A 교집합 B) / P(A)
향상도: P(A 교집합 B) / P(A) * P(B)
답.
지지도 = 300 / 1200 = 0.25
신뢰도 = 0.25 / 0.33 = 0.75
향상도 = 0.25 / (0.33 * 0.66) = 1.125
- 사용자가 다차원으로 이루어진 정보에 직접 접근하여 대화식으로 정보를 분석하고 의사결정에 활용하는 시스템은 무엇인가?
답. OLAP(Online Analytical Processing)
- SCM(Supply Chain Management): 기업이 외부 공급업체 또는 제휴업체와 통합된 정보시스템으로 연계하여 시간과 비용을 최적화시키기 위한 것으로, 자재구매, 생산/재고, 유통/판매, 고객데이터로 구성되는 정보시스템
** CRM(Customer Relationship Management): 기업의 내부 데이터로써 소비자들은 자신의 고객으로 만들고, 이를 장기간 유지하고자 내부 정보를 분석하고 저장하는데 사용하는 정보시스템
- 회귀모형의 계수를 추정하는 방법으로 잔차의 제곱합을 최소화하는 계수를 찾는 방법을 무엇이라고 하는가?
답. 최소제곱법(Least Square Mathod): 최소제곱법은 값을 정확하게 측정할 수 없는 경우에 근사적으로 값을 구하는 방법으로 회귀모형의 계수를 추정할 때 사용된다.
- 아래와 같이 오분류표가 주어질 경우에 대한 재현율(Recall)을 구하는 공식을 쓰시오.
답. TP / (TP + FN) = 1 / (1 + 3)
- 혼동행렬(Confusion Matrix)를 통해 다양한 평가지표를 계산할 수 있다.
정확도(Accuracy) = (TP + TN) / (TP + TN + FP + FN)
정밀도(Precision) = TP / (TP + FP): Positive로 분류한 것 중 실제 Positive의 비율
재현율(Recall) = TP / (TP + FN): 실제 Positive 중 Positive로 분류한 비율
재현율은 민감도(Sensitivity), 참긍정률(TPR)로 불리기도 한다.
특이도(Specificity, TNR) = TN / (TN + FP): 실제 Negative 중에서 실제 Negative인 비율
거짓긍정률(FPR) = 1- TNR = FP / (TN + FP): 1 - 특이도, 실제 Negative 중에서 실제로는 Positive인 비율
F1-score = 2 (Precision Recall) / (Precision + Recall)
- 다음은 인공신경망에서 무엇에 대한 설명인가?
인공신경망 학습에서 최적의 가중치 매개변수 값을 찾기 위한 지표로 이것을 사용한다.
인공신경망의 학습은 이것이 최소가 되도록 하기 위해 가중치와 편향을 찾는 것이다.
출력한 값과 실제 값과의 오차에 대한 함수이다.
이것으로 평균제곱오차 또는 교차엔트로피 오차를 활용한다.
답. 손실함수(Loss Function)
- 텍스트 마이닝의 전처리 과정에서 어형이 번형된 단어로부터 접사등을 제거하고 그 단어의 원형 또는 어간을 분리해 내는 것을 무엇이라고 하는가?
답. 스테밍(Stemming)
- 다음은 앙상블 모형에서 무엇에 대한 설명인가?
원 데이터 집합으로부터 크기가 같은 표본을 여러번 단순 임의 복원추출하여 각 표본에 대해 분류기(Classifier)를 생성한 후 그 결과를 앙상블하는 기법이다.
반복추출 방법을 사용하므로 같은 데이터가 한 표본에 여러 번 추출되거나 데이터가 추출되지 않을 수도 있다.
답. 배깅(bagging)
- 앙상블 모형 중 데이터를 조정하는 가장 대표적인 방법에는 배깅과 부스팅이 있다.
-
배깅: 크기가 같은 표본을 여러번 단순 임의 복원추출하여 각 표본에 대해 분류기를 생성한 후 그 결과를 앙상블하는 기법이다.
-
부스팅: 배깅의 과정과 유사하나 부트스트랩 표본을 구성하는 재표본 과정에서 각 자료에 동일한 확률을 부여하는 것이 아니라, 분류가 잘못된 데이터에 더 큰 가중을 주어 표본을 추출하는 기법니다.
- R언어에서 apriori 함수를 활용해 생성한 연관규칙을 확인할 수 있는 함수는 무엇인가?
답. inspect
- 실제로 부정인 범주에서 부정으로 올바르게 예측한 비율로, TN / (TN + FP)의 계산식을 갖는 혼동행렬 지표는 무엇인가?
답. 특이도(Specificity)
-
정밀도(Precision): 긍정으로 예측(TP + FP)한 것 중 TP의 비율
-
민감도(Sensitivity): 실제 긍정(TP + FN)인 것 중 TP의 비율
-
특이도(Specificity): 실제 부정(TN + FP)인 것 중 TN의 비율
-
거짓긍정률(FPR): 1 - Specificity, 실제 부정인 것 중 FP의 비율
- 다음은 회귀분석에서 어떤 문제에 대한 설명인가?
-
독립변수들간에 높은 선형관계가 존재할 때 발생하는 문제이다.
-
회귀분석에서 결정계수값이 높아 회귀식의 설명력은 높지만, 각 독립변수의 p-value값이 커서 개별 인자들이 유의하지 않은 경우 이 문제가 발생할 수 있다.
-
분산팽창요인(VIF; Variance Inflation Factor)이 10을 넘는 경우 발생하는 문제이다.
-
상관관계가 높은 독립변수들 중 하나 혹은 일부를 제거하여 이 문제를 해결한다.
-
주성분분석(PCA) 방법을 이용하여 설명력이 높은 변수를 선택하여 이 문제를 해결한다.
답. 다중공선성
- 다중공선성이 있을 경우 문제 해결 방법:
-
상관관계가 높은 독립변수를 제거한다.
-
변수를 변형시키거나 새로운 관측치를 이용한다.
-
주성분분석(PCA)을 이용해 설명력이 높은 변수를 선택한다.
- 군집 내의 오차제곱합(MSE)에 기초해 군집을 수행하는 방법으로 군집의 병합으로 인한 오차제곱합의 증가량이 최소가 되는 방향으로 군집을 형성하는 군집 간 거리 측정 방법은 무엇인가?
답. 와드연결법(Ward Linkage Method)
- 군집간 거리측정 방법:
-
단일연결법(Single Linkage): 최단연결법, 각 군집에 속하는 임의의 개체 사이의 거리 중에서 가장 작은 값을 거리로 정의해 가장 유사성이 큰 군집을 병합해나가는 과정. 고립된 군집을 찾는데 효과적이다.
-
완전연결법(Complete Linkage): 최장연결법, 각 군집에 속하는 임의의 개체 사이의 거리 중에서 가장 큰 값을 거리로 정의해 가장 유사성이 큰 군집을 병합해 나가는 과정, 내부 응집성에 중점을 둔 방법으로 둥근 형태의 군집이 형성된다.
-
평균연결법(Average Linkage): 모든 가능한 관측치 쌍 사이의 평균 거리를 거리로 정의해 가장 유사성이 큰 군집을 병합해 나가는 방법이다. 계산량이 불필요하게 많아질 수 있으며, 단일연결법, 완전연결법보다 이상치에 덜 민감하다.
-
중심연결법(Centroid Linkage): 각 군집의 중심점 사이의 거리를 거리로 정의한 방법, 평균연결법보다 계산량이 적고, 모든 관측치 사이의 거리를 측정할 필요 없이 중심 사이의 거리를 한 번만 계산한다.
-
와드연결법(Ward Linkage): 군집의 평균과 각 관측치 사이의 오차 제곱 합의 크기를 고려한 방법. 군집의 병합으로 인한 MSE 합의 증가량이 최소가 되는 방향으로 군집을 형성. 군집 내 분산을 최소로 하기 때문에 좀 더 조밀한 군집이 생성될 수 있다.
- 평균으로부터 t-Standard Deviation만큼 떨어져 있는 값들을 이상값(Outliet)으로 판단하고 t를 3으로 하는 이상값 검색 알고리즘은 무엇인가?
답. ESD(Extreme Studentized Deviation: 극단적 스튜던트화 편차)
- 연관성 분석에서 규칙이 우연에 의해 발생한 것인지를 판단하기 위해 연관 규칙 내 항목의 연관성 정도를 측정하는 척도는 무엇인가?
답. 향상도(Lift)
-
지지도: 전체 거래 중 A, B를 동시에 포함하는 비율 ( A -> B 라고 하는 규칙이 전체 거래 중 차지하는 비율을 통해 연관규칙이 얼마나 의미가 있는 규칙인지를 확인하는 척도 )
-
신뢰도: A 상품을 거래했을 때, B상품을 살 조건부 확률에 대한 척도 ( 상품 A를 구매했을 때, 상품 B를 구매할 확률이 어느정도 되는지에 대한 척도 )
-
향상도: A가 주어지지 않았을 때 B 확률 대비 A가 주어졌을 때 B의 확률 증가 비율 ( 규칙이 우연히 일어날 경우 대비 얼마나 나은 효과를 보이는지에 대한 척도 )
- ( )은/는 사용자의 의사결정에 도움을 주기 위해 기간 시스템의 데이터베이스에 축적된 데이터를 공통 형식으로 변환해서 관리하는 데이터베이스이다.
답. 데이터 웨어하우스(DW: Data Warehouse)
- 시간이 지날수록 관측치의 평균값이 지속적으로 증가하거나 감소하는 시계열 모형으로 주기나 불규칙성을 가지고 있는 시계열 데이터의 특성을 토대로 과거의 몇 개 관측치를 평균하여 전반적인 추세를 파악할 수 있는 시계열 모형은 무엇인가?
답. 이동평균모형(MA; Moving Average)
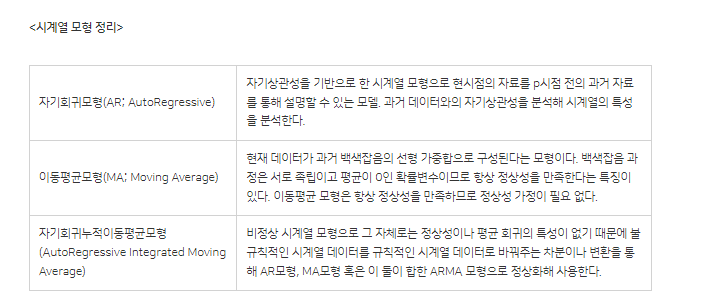
- 표준편차를 평균으로 나눈 것으로, 자료의 측정치 단위가 서로 다르거나 관찰점 수가 다른 경우 표준편차 값을 서로 비교하기 어려워지는 문제를 해결하기 위해 사용, 단위가 다른 두 집단간의 산포를 비교할 때 가장 적합한 측도는?
답. 변동계수(CV; Coefficient of Variance) 또는 상대표준편차(RSD; Relative Standard Deviation)
- GMM(Gaussian Mixture Model) 군집분석이 모수를 학습하는 방법은?
답. EM알고리즘
- 참긍정률이라고하며, 실제로 긍정인 범주에서 긍정으로 예측한 비율은?
답. 민감도(Sensitivity), 또는 Recall
- 인터넷상의 서버에서 데이터 저장, 처리, 네트워크, 콘텐츠 사용 등 서로 다른 물리적인 위치에 존재하는 컴퓨팅 자원을 가상화 기술을 통해 IT 관련 서비스를 한 번에 제공하는 혁신적인 컴퓨팅 기술을 의미하는 단어는?
답. 클라우드 컴퓨팅
- 통계의 표본 분포의 표준편차를 의미하는 단어는?
답. 표준오차
- 기업 또는 기관의 전사 차원에서 식별된 다양한 분석과제를 대상으로 제한된 예산과 자원을 효과적으로 수행하기 위해 우선순위를 평가하고 평가 결과에 따른 단계별 군현 로드맵을 수립하는 실행 계획
답. 분석마스터 플랜
- 스트리밍 데이터 흐름을 비동기 방식으로 처리하는 분산형 로그 수집 기술
답. 플럼
- 정상성을 만족하는 요인으로 평균값과 분산값은 시간 t에 상관없이 일정해야하며, 공분산은 시간에 의존하지 않고 오직 ( )에만 의존한다.
답. 시차
- 빅데이터 저장 기술로, RDBMS와 다른 DBMS를 지칭하기 위한 용어로, 고정된 테이블 스키마가 필요하지 않으며, JOIN 연산을 사용할 수 없는 수평적 확장이 가능한 DBMS는?
답. NoSQL
- 긍정으로 예측한 범주 중 실제로 긍정인 비율
답. 정밀도(Precision)
- 모델의 파라미터값을 측정하기 위해 알고리즘 구현 과정에서 사용, 주로 알고리즘 사용자에 의해 결정, 경험에 의해 결정 가능한 값이며, 모델 성능 향상을 위해 조절해주는 값은?
답. 하이퍼파라미터
- 분해시계열 분석에서 고정된 주기를 가지고 자료가 변화하는 요인은?
답. 계절요인
- 잔차가 정규분포를 잘 따르고 있는지를 확인하는 그래프를 나타내는 용어로 잔차들이 그래프 선상에 있어야 이상적임을 나타낸다.
답. Q-Q plot
- 구글에서 대용량 데이터 처리를 분산 병렬 컴퓨팅에서 처리하기 위한 목적으로 제작, 발표한 소프트웨어 프레임워크이며 대용량 데이터를 신뢰도가 낮은 컴퓨터로 구성된 클러스터 환경에서 병렬 처리를 지원하기 위해서 개발된 것은?
답. 맵 리듀스
- 네트워크를 통해 센서 데이터 및 오디오, 비디오 등의 미디어 데이터를 실시간으로 수집하는 기술은?
답. 스트리밍
- 크로스칼의 스트레스 값을 통해 검증하며 개체들 사이의 유사성/비유사성을 측정하여 2차원 또는 3차원 공간상에 표현해 개체들 사이의 집단화를 시각적으로 표현하는 분석방법은?
답. 다차원척도법(MDS; Multi Dimensional Scaling)
-
주성분분석(PCA; Principle Component Anaysis): 고차원의 데이터를 직교변환을 사용해 저차원의 데이터로 환원하는 기법, 상관관계가 있는 변수들을 결합해 분산을 극대화하는 데이터를 만드는 방법
-
요인분석(FA; Factor Analysis): 고차원의 변수들 중 잠재된 몇 개의 변수를 찾아내는 것
- 원격지 시스템 간에 파일을 공유하기 위한 서버-클라이언트 모델로 TCP/IP 기반으로 파일을 송수신하는 응용계층 통신 프로토콜
답. FTP
- 인공신경망에서 목푯값이 다범주일 때 사용하는 함수로 입력받는 값을 출력으로 0~1사이의 값으로 모두 정규화하여 출력값의 총합이 항상 1이 되는 특성을 가진 활성화함수는?
답. 소프트맥스 함수
<인공신경망 활성함수 정리>
- Step함수: 가장 기본적인 활성함수로 그래프가 계산모양으로 생겼으며, 임곗값을 기준으로 출력값이 0 혹은 1로 표현된다.
- Sigmoid함수: 로지스틱 함수라고도 불리며, 특정 임곗값을 기준으로 출력값이 급격하게 변하는 Step함수와는 달리 완만한 곡선 형태로 0과 1사이의 값을 출력한다.
- Sign함수: 함수의 값이 중간에 바뀌는 불연속함수로, 입력값이 음수이면 -1, 양수이면 1을 출력한다.
- tanh함수: 확장된 Sigmoid함수로 함수의 중심값이 0.5인 sigmoid함수와 달리 중심값이 0이다. -1과 1사이의 값을 출력하며 sigmoid보다 학습속도가 빠르다.
- ReLU함수: 입력값이 0보다 작으면 0, 0보다 크면 입력값을 그대로 출력하는 함수. sigmoid, tanh보다 연산이 빠르다는 장점이 있지만 0보다 작은 값에 대해서는 기울기가 0이므로 뉴런이 작동하지 않을 수 있다는 단점이 있다.
- Softmax함수: 목푯값이 다범주일 때 사용하는 함수. 입력받은 값을 정규화해 0과 1 사이의 값으로 출력하낟. 분류모델에서 확률값이 출력되며, 가장 높은 확률을 가지는 범주를 선택한다. Softmax 함수를 적용하 노드의 출력값은 항상 1이다.
- 정지규칙과 가지치기로 모델을 학습하며 다수의 독립변수 둥에서 종속변수에 큰 영향을 미치는 변수를 탐색하는 가장 기본적인 모델은?
답. 의사결정나무
- 일련의 개체 또는 사건들 간의 규칙을 발견하기 위해 사용되는 대표적인 정형 데이터 마이닝 기법은?
답. 연관분석
- 다중공선성을 측정하는 지표로 알려져 있으며, 독립변수간 상관관계가 있는지 정량적으로 나타내는 용어는?
답. 분산팽창요인(VIF; Variance Inflation Factor)
- 인터넷상에서 제공되는 다양한 웹사이트로부터 소셜네트워크 정보, 뉴스, 게시판 등의 웹문서 및 콘텐츠 수집 기술
답. 크롤링
- 데이터에 포함된 개인 식별 정보를 삭제하거나 알아볼 수 없는 형태로 변환하는 것을 의미하는 단어는?
답. 익명화
<개인정보 비식별화 기술 정리>
-
가명처리
-
총계처리
*데이터 삭제
-
데이터 범주화
-
데이터 마스킹
<프라이버시 보호모델>
-
K-익명성: 특정인임을 추론할 수 있는지를 검토, 일정 확률 수준 이상 비식별되게 함
-
L-다양성: 특정인 추론이 안된다고 해도 민감한 정보의 다양성을 높여 추론 가능성을 낮추는 기법
-
T-근접성: L-다양성뿐만 아니라 민감한 정보의 분포를 낮추어 추론 가능성을 더욱 낮추는 기법
- 회귀모형 변수 선택시 도움이 되지 않는 변수들을 하나씩 제거하는 방법은?
답. 후진제거법
- 데이터마이닝의 절차 중 데이터의 정제, 통합, 선택, 변환의 과정을 거친 구조화된 단계로서 더이상 추가적 절차 없이 데이터마이닝 알고리즘 실험에서 활용가능한 상태를 나타내는 말은?
답. corpus
- 귀무가설이 참인데 잘못하여 이를 기각하게 되는 오류는?
답. 제1종 오류(알파오류)
- M*N 차원의 행렬데이터에서 특이값을 추출하고 이를 통해 주어진 데이터 세트를 효과적으로 축약할 수 있는 차원 축소기법은?
답. 특이값 분해(SVD; Singular Value Decomposition)

- 불순도의 측도로 출력범주가 범주형일 경우 지니지수를 이용, 연속형인 경우 분산을 이용한 이진분리를 이용하는 의사결정나무 알고리즘은?
답. CART
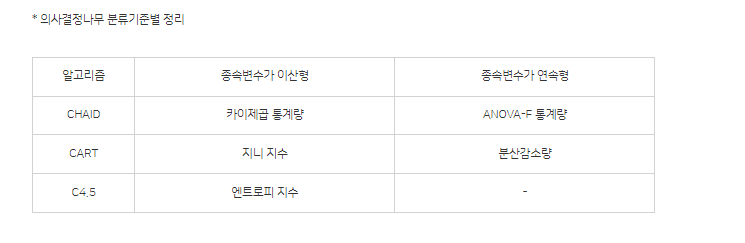
- 회귀모형의 평가방법 중 하나로 회귀제곱합을 총제곱합의 값으로 나눈 것은?
답. 결정계수(R^2)
- 센서로부터 수집 및 생성된 데이터를 네트워크를 통해 수집 및 활용하는 기술은?
답. 센싱
- 사용자의 요구에 따라 정보를 처리해주고 데이터베이스를 관리해주는 소프트웨어는?
답. DBMS
- 비선형관계의 상관정도나 이산형 변수에 관한 상관정도를 표현하는 상관계수는?
답. 스피어만 상관계수
<피어슨 상관계수 vs 스피어만 상관계수>
-
피어슨: 모수검정, 연속형 변수, 예) 경영학 점수(연속형)와 통계학 점수 사이에 연관성이 있는가?
-
스피어만: 비모수검정, 이산형/순서형 변수, 예) 경영학 과목 석차(순서형)와 통계학 과목 석차 사이에 연관성이 있는가?
- 데이터 클래스 불균형을 해결하기 위한 방법으로 다수 클래스를 샘플링하고, 소수 클래스를 보간해 새로운 소수 인스턴스를 합성해내는 방법이다. 과대표집과 과소표집을 보완해주는 샘플링 방법은?
답. SMOTE(Synthetic Minority OverSampling Technique)
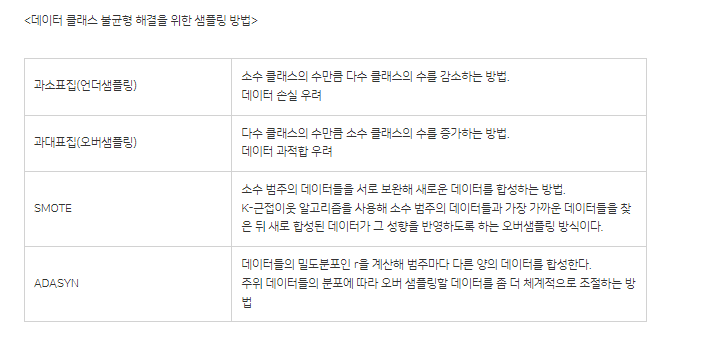
- 단순분류, 확인 목적으로 숫자를 부여, 숫자 자체로서 가지는 의미 없는 변수를 나타내는 용어는?
답. 명목변수
- 커넥터를 사용해 관계형데이터베이스(RDBMS)와 하둡(Hadoop) 간 데이터를 전송하는 기술
답. 스쿱
- 대규모 분산 시스템 모니터링을 위해 에이전트(Agent)와 컬렉터(Collector) 구성을 통해 데이터를 수집하고, 수집된 데이터를 하둡 파일 시스템에 저장하는 기능을 제공하는 데이터 수집기술
답. 척와
- 저장단위: 키로바이트 < 메가바이트 < 기가바이트 < 테라바이트 < 페타바이트 < 엑사바이트 < 제타바이트 < OO바이트 (각 1,024배씩 증가). OO에 들어갈 단어는?
답. 요타
- 배깅의 개념과 속성의 임의선택을 결합한 앙상블 기법, 예측변수들을 임의로 추출하고 추출된 변수 내에서 최적의 분할을 만들어나가는 방법을 사용하는 방식의 모델을?
답. 랜덤포레스트
- 서로 다른 분류에 속한 데이터 간에 간격이 최대가 되는 선을 찾아 이를 초평면이라는 기준으로 하고 데이터를 분류하는 모델은?
답. SVM(Support Vector Machine)
- 여러 개의 모형을 결합해 개별 모형보다 좋은 예측성능을 얻는 분석 기법을 표현한 말은?
답. 앙상블
- 다수의 서버로부터 실시간으로 스트리밍되는 로그 데이터를 수집하여 분산 시스템에 데이터를 저장하는 대용량 실기간 로그 수집 기술
답. 스크라이브(scribe)
- 시계열에 영향을 주는 일반적인 요인을 시계열에서 분리해 분석하는 방법, 회귀분석적인 방법을 주로 사용하는 것을 의미하는 것은?
답. 분해시계열
- 시계열모형 중 과거시점의 관측자료와 과거시점의 백색잡음의 선형결합으로 현시점의 자료를 표현하는 모형은?
답. 이동평균모형
[출처] 빅데이터분석기사 실기 단답형 정리 2 (21.06.11)|작성자 yoon
manim.com/dataset/03_dataq/typetwo.html
https://www.kaggle.com/general/286991
https://m.blog.naver.com/da0097/222582321859https://www.data
