1. 학습 키워드
- sql - 윈도우 함수
- 파이썬 이론 메모
- 데이터 시각화
2. 학습 내용
sql - 윈도우 함수
행과 행간의 관계를 정의하기 위해 사용함.
# 윈도우 함수 기본문법 # partition by는 사용 안할수도 있음. SELECT WINDOW_FUNCTION () OVER(PARTITION BY 컬럼 ORDER BY 컬럼) FROM 테이블명
일반적으로 단일 쿼리만 사용시 집계 함수를 사용한 다음에는 집계를 하지 않는 컬럼은 못가져온다. 그러나 윈도우 함수는 이를 가능하게함.
ex) 국가별 연봉이 가장 높은 사람의 '성별'
(순위 함수로 국가별 연봉이 높은 사람의 순위를 정하고 1위만 조건으로 뽑아서 성별 출력)
순위: RANK, DENSE_RANK, ROW_NUMBER
집계: SUM, MAX, MIN, AVG, COUNT
순서: FIRST_VALUE, LAST_VALUE, LAG, LEAD
비율: RATIO_TO_REPROT, PERCENT_RANK, CUME_DIST, NTILE
- 집계함수: GROUP BY 구문과 병행하여 사용할 수 있음
- 순위함수: GROUP BY 구문과 병행하여 사용할 수 없음
- 순서함수: GROUP BY 구문과 병행하여 사용할 수 없음
- 비율함수: GROUP BY 구문과 병행하여 사용할 수 없음
순위 함수(가장 많이 사용)
RANK() OVER(PARTITION BY 컬럼1 ORDER BY 컬럼2)
RANK(): 동일한 값은 동일한 순위. 중간 순위를 비움. (1위가 2개이면 그 다음 순위는 3위)DENSE_RANK(): 동일한 값은 동일한 순위. 중간 순위를 비우지 않음.- 🔥
ROW_NUMBER(): 모든 순위를 다 다르게함. 가장 많이 사용함.
순서 함수
LAG(컬럼1) OVER (PARTITION BY 컬럼2 ORDER BY 컬럼3)
-
FIRST_VALUE: 파티션별 가장 먼저 나온 값. 공동 등수를 인정하지 않음.
FIRST_VALUE(컬럼1) OVER(PARTITION BY 컬럼2 ORDER BY 컬럼3) -
LAST_VALUE: 파티션별 가장 나중에 나온 값. 공동 등수를 인정하지 않음.
LAST_VALUE(컬럼1) OVER(PARTITION BY 컬럼2 ORDER BY 컬럼3) -
🔥중요🔥
LAG: 이전 N번째 행을 가져옴. 별도 명시가 없으면 기본값은 1.
LAG(컬럼1, 숫자) OVER (PARTITION BY 컬럼2 ORDER BY 컬럼3)
이전값을 출력해서 얼마만에 결제했는지(=리텐션)
2번째 전 값 구하기
select *, LAG(SALARY,2) OVER (ORDER BY NAME) as PREV_SAL from basic.window1partition by가 없으므로 전체 salary 대상으로 2번째 이전 값.
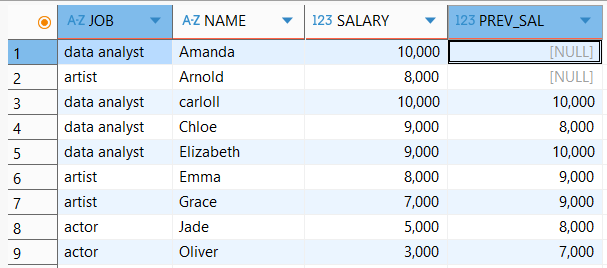
- 🔥중요🔥
LEAD: 이전 N 행의 값을 가져옴. 별도 명시가 없으면 기본값은 1. LAG와 사용법 동일함.
비율 함수
- 🔥중요🔥
PERCENT_RANK: 파티션별로 가장 먼저 나오는 값을 0, 가장 마지막에 나오는 값을 1로 정하여 행 순서별 백분율을 출력.의미: “이 행이 전체 중 어느 퍼센트 위치인가?”
순위는 RANK 함수 기반
계산방식: (파티션 내 순위 - 1) / (파티션 내 전체 행 개수 - 1)
PERCENT_RANK() OVER (PARTITION BY 컬럼1 ORDER BY 컬럼2)
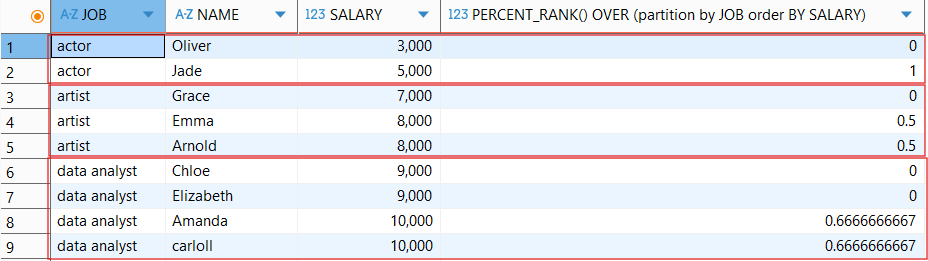
-
RATIO_TO_REPORT: 파티션 내 전체 SUM값에 대한 행별 백분율을 소수점으로 출력. MYSQL에서는 지원하지 않음. 비율의 합은 1.
RATIO_TO_REPORT(컬럼1) OVER (PARTITION BY 컬럼2 ORDER BY 컬럼3) -
CUME_DIST: 파티션별 전체건수에서 현재 행보다 작거나 같은 건수에 대한 누적백분율.
CUME_DIST() OVER (PARTITION BY 컬럼1 ORDER BY 컬럼2) -
NTILE: 파티션별 전체 건수를 계산한 값으로 N등분한 결과를 출력. 이거 대신 row_number() 사용하면 되서 잘 사용 안함.
NTILE(숫자) OVER (PARTITION BY 컬럼1 ORDER BY 컬럼2)
sql - with
: 하나의 테이블이 여러번 필요한 경우 with를 사용해서 임시 테이블을 생성함.
with를 사용하면 임시테이블을 정의할 때 테이블을 한 번 불러옴. 이후 이를 통해서 만들어진 임시테이블을 몇 번을 사용하든 테이블은 한번만 불러온 것으로 된다. 데이터 사용량을 줄일 수 있다.
with 임시테이블명 as ( select 컬럼1, 컬럼2, ... from 테이블명 ) select 컬럼 from 임시테이블명
파이썬 이론 메모
리스트 주요 메서드
insert(위치, 값): 지정 위치에 추가remove(x): 해당 요소 삭제. 중복되는 값이 있다면 가장 먼저나오는 값을 지워준다.pop(): 마지막 요소 꺼내기. 리스트에서는 꺼낸거 지워짐.sort(): 오름 차순으로 정렬. 괄호 안에 reverse=True로 지정해주면 내림차순.
딕셔너리 주요 메서드
.keys(): 키 다 가져오기.values(): 값 다 가져오기.items(): 키-값 다가져오기.get(key): 안전하게 값 가져오기. 존재하지 않는 키에 해당하는 값을 가져올 때 에러를 발생시키지 않고None을 반환함. 그냥student['없는키']를 사용하면 에러가 발생함. 이는 코드 실행의 문제를 가져옴.- .pop(key): 특정키 삭제
데이터 시각화
데이터 시각화는 의사결정을 잘할 수 있도록 도와줌.
plot() 활용해서 데이터 시각화
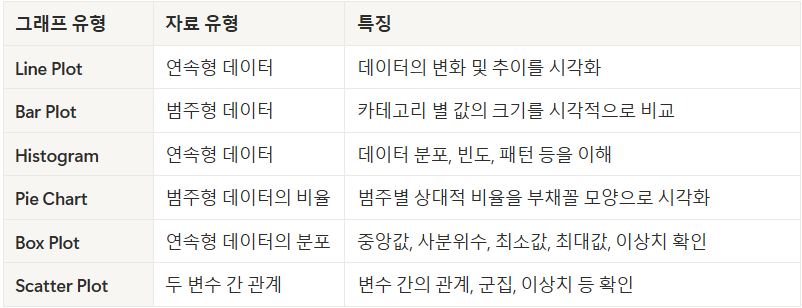
line 그래프
: 연속적인 데이터 추이를 볼 때 유용하다.
import seaborn as sns
data = sns.load_dataset('flights')
data_grouped = data[['year', 'passengers']].groupby('year').sum().reset_index()
plt.plot(data_grouped['year'], data_grouped['passengers'])
plt.xlabel('year')
plt.ylabel('passengers')
plt.show()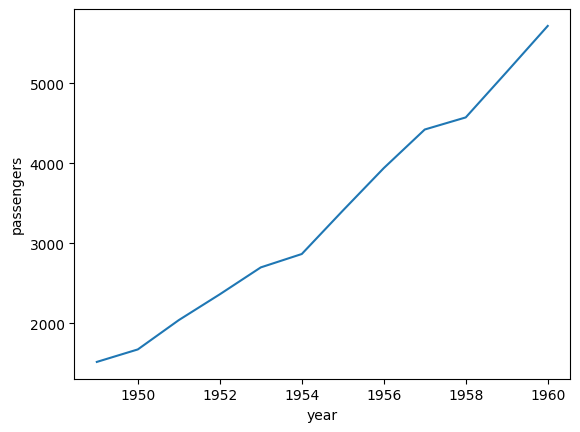
bar vs histogram
bar: 범주형 데이터의 비교
ex) plt.bar(df['도시'], df['인구'])histogram: 연속적인 데이터의 분포 확인. y축은 해당 범위에서의 빈도를 나타냄.
ex) plt.hist(df['인구'], bins=30)pie 차트(원 그래프)
import matplotlib.pyplot as plt
# 데이터 생성
sizes = [30, 20, 25, 15, 10]
labels = ['A', 'B', 'C', 'D', 'E']
# 원 그래프 그리기
plt.pie(sizes, labels=labels, autopct='%1.1f%%')
plt.title('Pie Chart')
plt.show()
box plot
: 데이터의 분포와 이상치 확인
import seaborn as sns import matplotlib.pyplot as plt iris = sns.load_dataset('iris') species = iris['species'].unique() sepal_length_list = [iris[iris['species'] == s]['sepal_length'].tolist() for s in species] plt.boxplot(sepal_length_list, labels=species) plt.xlabel('species') plt.ylabel('sepal length') plt.show()
seaborn 사용
sns.boxplot(data = iris, x='species', y='sepal_length') plt.show()
scatter
: 두 변수간의 관계를 점으로 표현해주는 그래프
plt.scatter(iris['sepal_length'], iris['sepal_width']) plt.xlabel('sepal length') plt.ylabel('sepal width') plt.show()
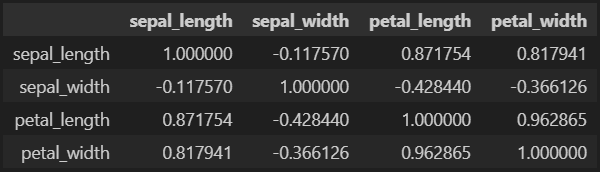
상관계수 보는 방법# numeric_only: 문자열을 제외하고 숫자 컬럼만 상관계수 구함 iris.corr(numeric_only=True)
* 피어슨 상관계수: 두 변수간의 선형적 관계를 측정하기 위한 방법. 주로 연속 변수들 간의 상관관계를 구할 때 사용함.
상관 관계가 강하다고 인과성이 있는 것은 아니다.
3. 배운점
- 리스트: 여러값을 순서대로 저장 가능하고 수정, 삭제가 가능.
- 튜플: 데이터가 수정되는 것을 방지하고 싶을 때. 리스트보다 속도가 빠르다.
- 딕셔너리: 값에 정체성을 부여할 수 있고 키로 가져올 수 있어서 순서가 필요 없다.
- 딕셔너리에서 값을 가져올 때 .get('키') 형태로 값을 가져오면 해당 키가 없는 경우에 에러를 발생하지 않고 None 값을 가져와 프로그램 실행시 중간 멈춤을 방지할 수 있다.
dic['키'] 보다 dic.get['키'] 추천 - corr() 함수를 사용할 때 numeric_only로 설정할 수 있다는 것을 알게 됨.
