1. 목표
Pytorch로 Regression을 구현하여, 기본적인 Pytorch 사용법을 익히기
2. 코드
(1) Import
# 데이터 분석을 위한 기본적인 라이브러리
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns# torch 라이브러리
import torch
import torch.nn as nn # class model(nn.Module)(1) Dataset: row 1개당 기준으로 Column을 나눠줍니다. -> x, y | 방법 : class MyDataset(Dataset)
(2) DataLoader -> row 기준 mini-batch를 만들기 -> batch로 묶기 |(bs, 8)|, |(bs, 1)|
=> 방법 : DataLoader(train_ds) / 번외 : class Loader(DataLoader)
(2) 캘리포니아 데이터 로드
from sklearn.datasets import fetch_california_housing
ch = fetch_california_housing()
df = pd.DataFrame(ch.data, colums = ch.feature_names)
df['target'] = ch.target(3) Dataset -> DataLoader
class MyDataset(Dataset):
def __init__(self, df = df):
self.df = df
self.x = df.iloc[:, :-1].values # numpy
self.y = df.iloc[: -1:].values # numpy
# override 1
# 전체 rows 수를 반환
def __len__(self):
return self.x.shape[0] # len(self.df)
# override 2
def __getitem__(self, index):
x = self.x[index] # numpy
y = self.y[index] # numpy
return torch.tensor(x, dtype = torch.float), torch.tensor(y, dtype = torch.float)# Dataset
Pytorch의 TensorDataset은 tensor를 감싸는 Dataset
(1) 인덱싱 방식과 길이를 정의 -> tensor의 첫 차원을 따라 반복, 인덱스, 슬라이스 방법 제공
(2) Training시, 동일한 라인에서 독립 변수와 종속 변수에 쉽게 접근 가능
# __len__
파이썬 내장 함수로, 클래스에 구현하여 len()을 사용하게 해준다.
# __getitem__
파이썬 내장 함수로, 클래스에 구현하여 index 접근으로 원하는 값을 얻을 수 있다.
ds = MyDataset(df)
sample = next(iter(ds))
sample[0].shape, sample[1].shape
# 8, 1 -> row 1개 기준# next(iter())
iter(객체. 반복을 끝낼 값) : 반복 가능한 개체에서 이터레이터를 반환
next(반복 객체, 기본 값 설정) : 이터레이터에서 값을 차례대로 꺼냄
# cpu 갯수에 따라 worker 후에 설정
import os
num = os.cpu_count()def prepare_loaders(df = df, index = 15640, batch_size = 512):
# 1) Train Valids Split
train = df[:index].reset_index(drop = True)
valid = df[index:].reset_index(drop = True)
# 2) train, valid -> MyDataset(Dataset) --> train_ds, valid_ds
train_ds = MyDataset(train)
valid_ds = MyDataset(valid)
# 3) train_ds, valid_ds -> DataLoader -> train_loader, valid_loader
train_loader = DataLoader(train_ds, shuffle = True, batch_size = batch_size, num_workers = num, drop_last = True)
valid_loader = DataLoader(valid_ds, shuffle = False, batch_size = batch_size, num_workers = num, drop_last = True)
print('DataLoader Completed')
return train_loader, valid_loader
train_loader, valid_loader = prepare_loaders(df = df, index = 15640, batch_size = 512)DataLoader를 사용하여 미니 배치 형태로 쉽게 데이터 처리
DataLoader(데이터셋, 미니배치 크기, 셔플(각 에폭마다 데이터가 학습되는 순서 변경))
sample = next(iter(train_loader))
sample[0].shape, sample[1].shape
# (bs, 8), (bs, 1) -> row 1개 기준
>> torch.Size([512, 8]), torch.Size([512, 1])(4) Model
# 사용환경에서 GPU를 사용할 수 있는지? 사용가능하면 GPU 안 되면 CPU
device = torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu')class Model(nn.Module):
def __init__(self, input_dim = 8, ouput_dim = 1):
super().__itit__() # error 날 수 있으니 반드시
# frame만 선언
# 1)
# input shape: vs, 8
self.fc1 = nn.Linear(8,4)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(4, 2)
self.relu =nn.ReLU()
self.last - nn.Linear(2, 1)
# 2) Sequential()
self.seq = nn.Sequential(
nn.Linear(8,4) nn.ReLU(), nn.Linear(4,2), nn.ReLU(), nn.Linear(2,1)
)
# nn.Module 상속시 반드시 override
def forward(self, x):
# x shape = |bs, 8|
x1 = self.relu(self.fc1(x))
x2 = self.relu(self.fc2(x1))
output = self.last(x2)
# torch flatten(x,1)
output1 = self.seq(x)
return output # shape : (bs, 1)model = Model(8,1).to(device)
>>>
Model(
(fc1): Linear(in_features=8, out_features=4, bias=True)
(relu): ReLU()
(fc2): Linear(in_features=4, out_features=500, bias=True)
(last): Linear(in_features=500, out_features=1, bias=True)
)(5) Lossfunction, Optimizer
loss_fn = nn.MSELoss().to(device) # Regression
# F.mse_loss()
lr = 1e-2
optimizer = torch.optim.Adam(model.parameters(), #lr = lr).to(device)# NLP - AdamW: lr = 1e-5
# CV - Adam : lr = 1e-3, 1e-4
# concept
# 1 epoch: 전체 데이터를 한 번 훑는 것 (20640)
# iteration = 전체 데이터 row 수(20640) / batch_size(=512) --> N: iteration
# train: 15640 -> train_loader: 15640/512 -> N' : model 학습 횟수(=웨이트업뎃수)
# valid_loader -> 성능평가만
# run_train 함수
for epoch in range(200):
# train_one_epoch
# train_loader -> model 학습구간
train_loss = 0
model.train()
for data in train_loader:
x = data[0].to(device) # GPU
y = data[1].to(device) # GPU
y_pred = model(x)
loss = loss_fn(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss
train_loss /= len(train_loader)
# valid_one_epoch 함수
# valid_loader -> model 성능평가구간
valid_loss = 0
model.eval()
for data in train_loader:
x = data[0].to(device) # GPU
y = data[1].to(device) # GPU
y_pred = model(x)
loss = loss_fn(y_pred, y)
valid_loss += loss
valid_loss /= len(valid_loader)
# monitoring
# lowest loss 갱신(6) train_one_epoch
def train_one_epoch(model = model, loss_fn = loss_fn, optimizer, scheduler = None, device = device):
#train_one_epooch
#train_loader -> model 학습구간
train_loss = 0
model.train() # model 학습 의지 표명
for data in train_loader:
x = data[0].to(device)
y = data[1].to(device)
y_pred = model(x)
loss = loss_fn(y_pred, y)
# 역전파
optimizer.zero_grad() # 그라디언트 초기화
loss.backward() # 역전파할 그라디언트 구하고
optimizer.step() # 웨이트 업데이트
if scheduler is not None:
scheduler.step()
train_loss += float(loss) # loss.item()
train_loss /= len(train_loader) # 1 epoch당 평균 train_loss
return train_loss(7) valid one epoch
# valid이니 학습을 반드시 시키지 않겠다는 필수 의지 표명2
@torch.no_grad()
def valid_one_eopch(model = model, loss_fn = loss_fn, device = device):
#valid_one_epoch
#valid_loader -> model 성능평가구간
valid_loss = 0
model.eval() # model 학습 안 시키겠다 -> 성능평가
# 학습을 반드시 시키지 않겠다는 필수 의지 표명1
with torch.no_grad()
for data in train_loader:
x = data[0].to(device)
y = data[1].to(device)
y_pred = model(x)
loss = loss_fn(y_pred, y)
valid_loss += float(loss) # loss.item()
valid_loss /= len(valid_loader) # 1 에폭당 평균 valid_loss(8) Run Train
import copydef run_train(model = model, train_loader = train_loader, valid_loader = valid_loader,
loss_fn = loss_fn, optimizer = optimizer, device = device, scheduler = None):
train_hs, valid_hs = [], [] # 시각화를 위한 history 저장
lowest_loss, lowest_epoch = np.inf, np.inf
best_model = None
result = dict()
n_epochs = 300
print_iter = 20
early_stop = 30
for epoch in range(n_epochs):
train_loss = train_one_epoch(model = model, loss_fn = loss_fn, optimizer = optimizer, scheduler = None, device = device)
valid_loss = valid_one_epoch(model = model, loss_fn, device = device)
# 줍줍
train_hs.append(train_loss)
valid_hs.append(valid_loss)
# monitoring
if (epoch + 1) % print_iter = 0:
pirnt('Epoch[%d}, TL:%.3e, VL:%.3e, LowestLoss:%.3e' %(epoch + 1, train_loss, valid_loss, lowest_loss))
# Lowest Loss를 갱신 -> valid_loss 기준
if valid_loss < lowest_loss:
lowest_loss = valid_loss:
lowest_epoch = epoch
# 1) model save
best_model = copy.deepcopy(model.state_dict())
# 2) torch.save
torch.save(model.state_dict(), './model.pth') # model.bin
else:
if early_stop > 0 and early_stop + lowest_epoch < epoch + 1:
print('진전이 없음')
break
print()
print("The best Validation Loss=%.3e at %d Epoch" % (lowest_loss, lowest_epoch))
# load model 1)
model.load_state_dict(best_model)
# torch load 2)
model.load_state_dict(torch.load("./model.pth"))
result["Train Loss"] = train_hs
result["Valid Loss"] = valid_hs
return model, resultmodel, result = run_train(model = model, train_loader = train_loader, valid_loader = valid_loader,
loss_fn = loss_fn, optimizer = optimizer, device = device, scheduler = None)(9) Visualization
## Train/Valid History
plot_from = 0
plt.figure(figsize=(20, 10))
plt.title("Train/Valid Loss History", fontsize = 20)
plt.plot(
range(0, len(result['Train Loss'][plot_from:])),
result['Train Loss'][plot_from:],
label = 'Train Loss'
)
plt.plot(
range(0, len(result['Valid Loss'][plot_from:])),
result['Valid Loss'][plot_from:],
label = 'Valid Loss'
)
plt.legend()
plt.yscale('log')
plt.grid(True)
plt.show()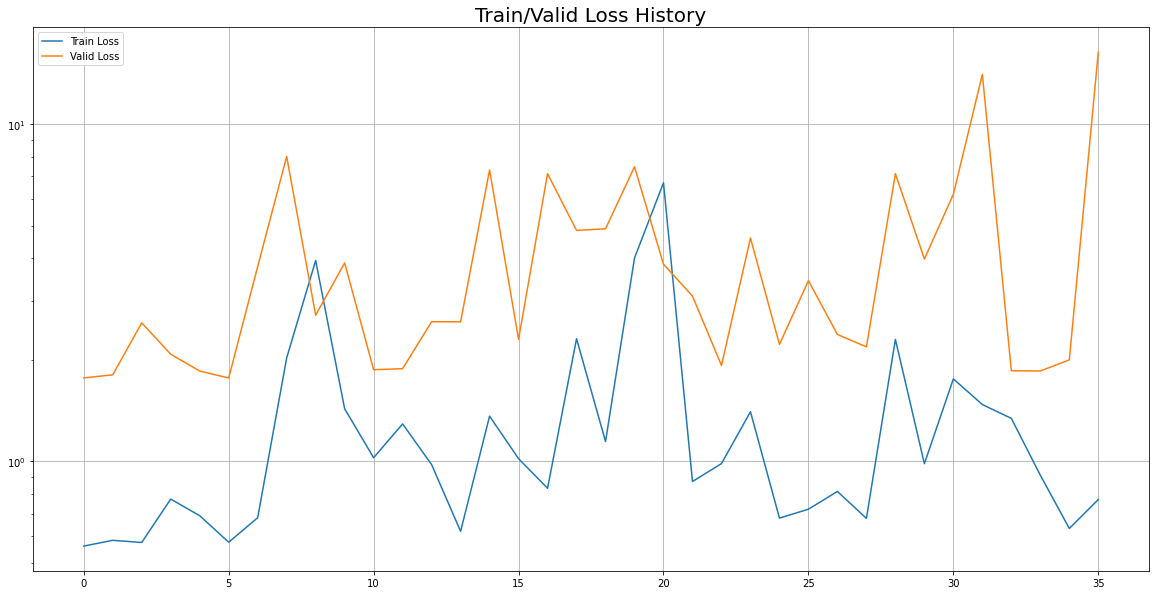

개발꿈나무