
ETL/Airflow 소개
SPARK/ATHENA 사용 시나리오
- spark : Pandas와 유사함. 다수의 서버에 분산된 데이터를 처리하기때문에 처리할 수 있는 양이 많음.
- spak streaming : 스트리밍까지 할 수 있음. ML 종합선물세트!(ML모델 만드는 것도 가능!)
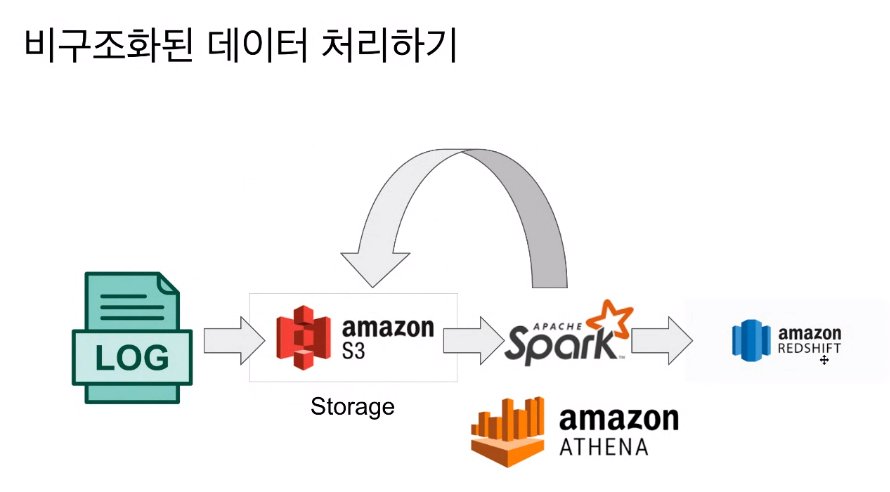
- ATHENA : 빅데이터용 sql. input이 cloud storage에 있어서 처리후에도 amazon에 올릴 수 있음.
- S3는 싸니까. 비구조는 S3에 저장하고 spark나 athena로 정제(사이즈 줄임)하고 redshift에 넣음 (자체적으로 redshift가 가능)
- 대용량 데이터 병렬처리
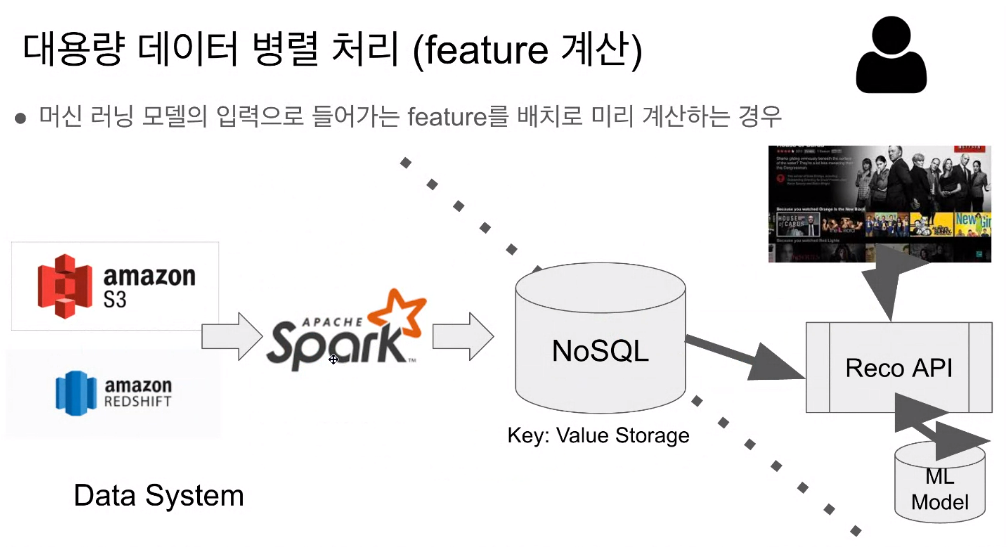
spark를 대량 계산하게 하는데 사용함. spark 스트리밍을하면, 유저의 행동을 이벤트로 처리하는게 가능함. - DW보단 큰 데이터를 프로세싱하기위한 프레임워크에 가까움
데이터 파이프라인이란?

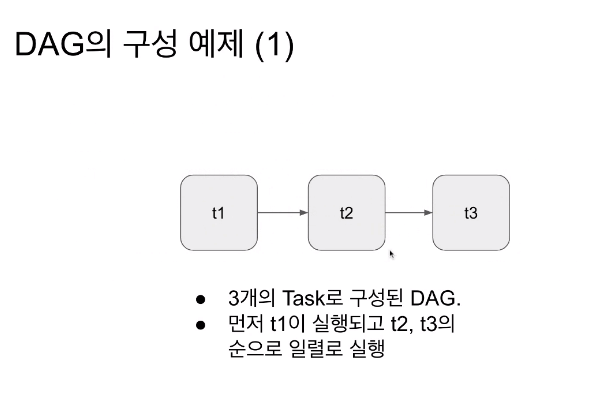
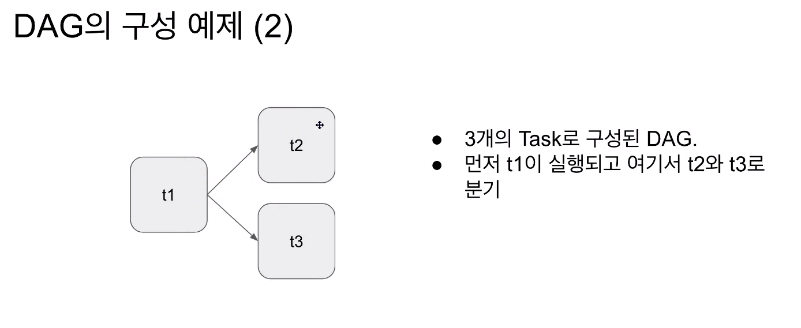
- 하나의 파이프라인은 다수의 테스크가 있고, 그 태스크를 정리하면 그래프가 나옴 -> DAG
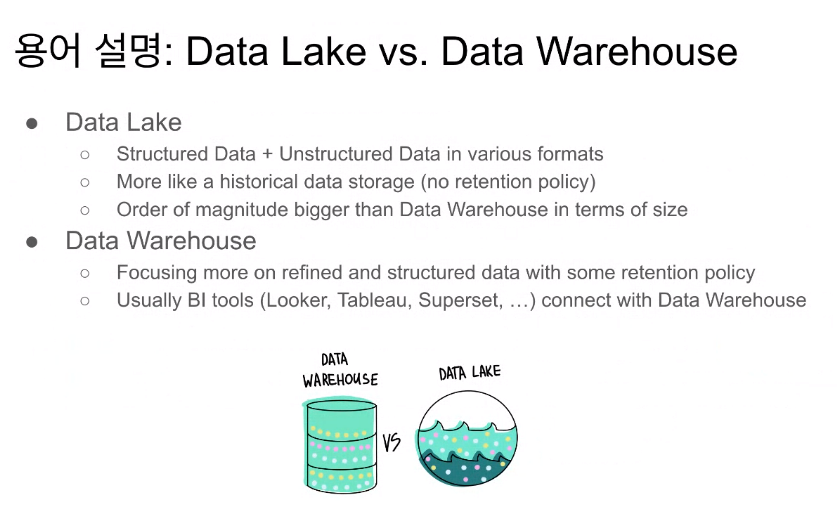
- Data Lake
- 크기가 훨씬 크니 비구조 데이터를 저장하는데 문제가 없다
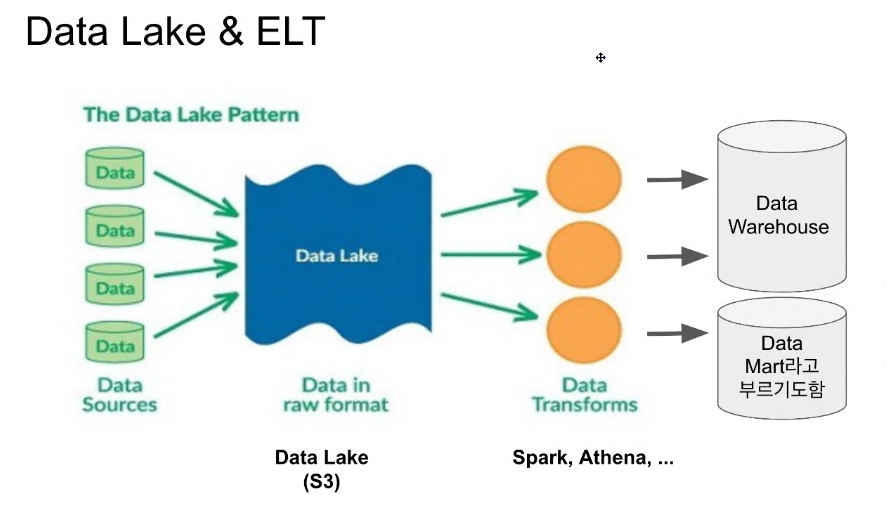
- 크기가 훨씬 크니 비구조 데이터를 저장하는데 문제가 없다
- Data Lake에 다 올리고, spark나 Athena로 조절해서 DW에 올림
정의
- 데이터를 소스로부터 목적지로 복사하는 작업
- 이 작업은 보통 코딩(파이썬 or 스칼라) 혹은 SQL로 이뤄짐
- 대부분 목적지는 DW임
- 데이터 소스의 예
- Poduction DB, ~~관련 DB -> API로 받아와서 정제 후 테이블형태로 저정
- 데이터 목적지의 예
- DW, 캐시 시스템(Redis, Mem~~~
Data Pipeline 예)

- DE가 하는 일. 왜 하는지 보통 모른다... 요청에 의한 작업
- 품질관리가 안되는 경우가 생김. -> 외부요청으로 ETL을 하면 Owner로 기록을 해야함 -> 그래야 나중에 확인이 가능함(클린업, 노티 가능)

- 써머리 테이블은 어느정도까지는 사용 가능.
- 요즘은 DBT를 많이 사용함

- DW로 읽어 다른 환경으로 넘기는 ETL
- 강의를 매번 랭킹이나 뷰 수를 업데이트 하게 되는데,

1시간에 한번씩 계산해서 SQL로 넣어놓으면, 그냥 DB를 읽어라 -> 시스템 안정성 올라감
간단한 ETL 작성하기!

Airflow
- 스케줄링,

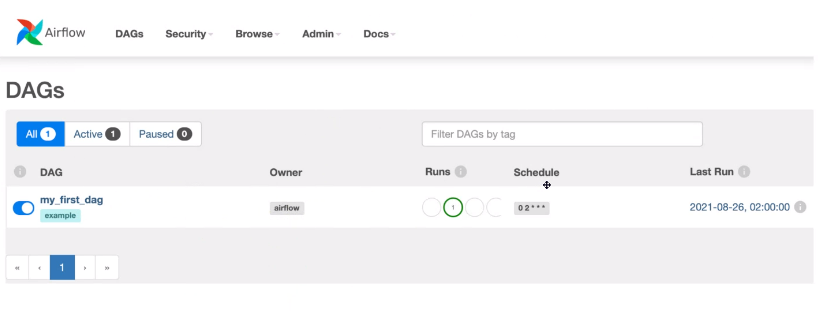
해당형태로 보이게됨

- 하나의 댁은 여러개의 태스크임
- Airflow의 태스크는 오퍼레이트의

- 구글 클라우드가 뭐를 쓰고 있는지를 확인해보자. 오픈소스의 최신은 위험부담이 있음. 현) 구글클라우드는 2.4.3을 사용하고 있음
Airflow 구성

- worker가 실행함
- 다수의 worker가 하기도하는데, 일을 분배해야해서 Queue가 필요함
- 큰쿠버가 있으면 에어 댁이 돌때마다 worker를 안만들고 쿠버한테 리소스 받아서 그 위에서 실행시키고 리턴하는 것을 반복함..?
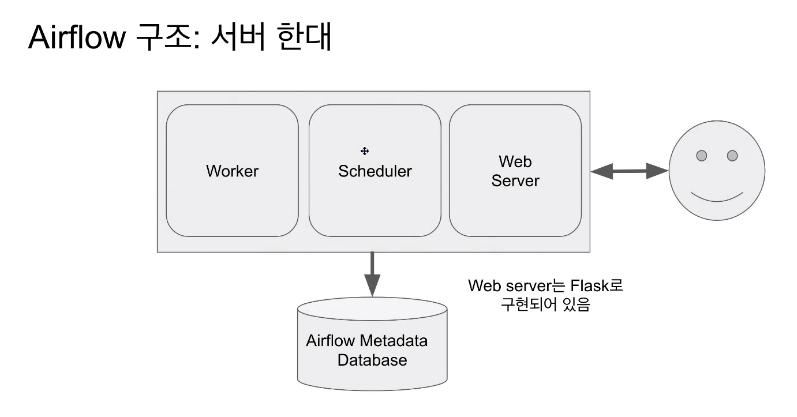
- 이 3가지의 정보가 1개의 DB에 저장됨
- 1대로 사용하면 CPU나 메모리가 부족해지는 경우가 있음
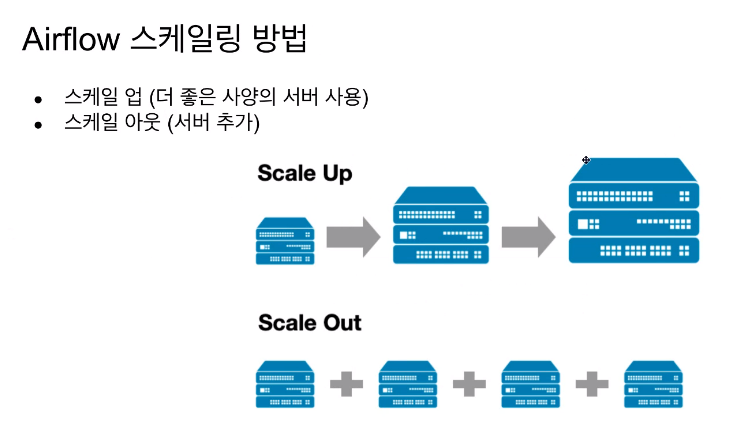
- scale out은 최대한 뒤로 미루는게 좋다. 관리 복잡도가 늘어남. 차라리 클라우드 버전으로 가는 것이 낫다.
Q. queue는 slave worker의 master 개념인가요? 아니면 slave worker 내 존재하는 건가요? - 전체 system에 있는 것. worker들이 큐를 보고 실행할 것이 있는지 확인하는 역할로 진행
- scale out은 최대한 뒤로 미루는게 좋다. 관리 복잡도가 늘어남. 차라리 클라우드 버전으로 가는 것이 낫다.
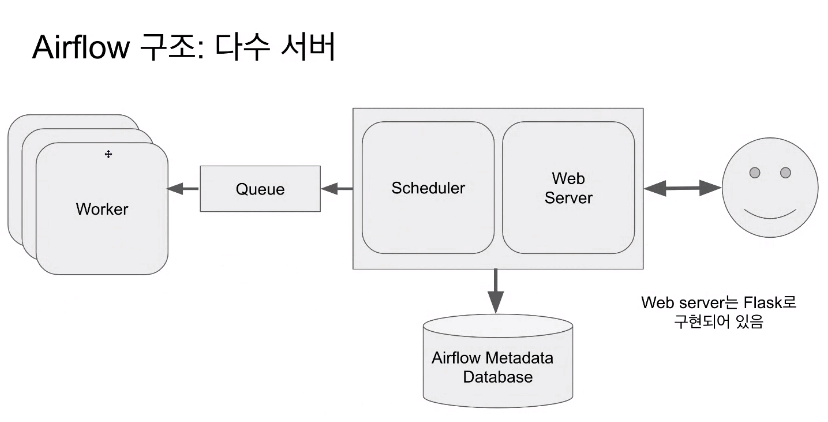
- 요즘 나온 시퀄은 괜찮더라...

- Backfill 쉬움!!!

- DAG간의 구성 순서를 지정 할 수 있음

- 비지니스 오더가 있으면 그사람을 오너로 적는게 좋음.
- 에러낫을 때 어디 이메일에 보낼지. DE팀, 비지니스오너 둘다 적는게 좋음
from airflow import DAG

- DAG는 주기적으로 실행됨. 스케줄 인터벌 "0 9 * * *"

- 뒤에 3개는 잘 안씀. 요일은 좀 쓴다. 매주 월요일 9시에 실행 같은 거
- "0 * * * * " 은 매시 0분에 실행. (hourly)
- Bash : 리눅스에서 실행하는 명령어
- 모든 task는 유니크한 id를 갖고 있어야함
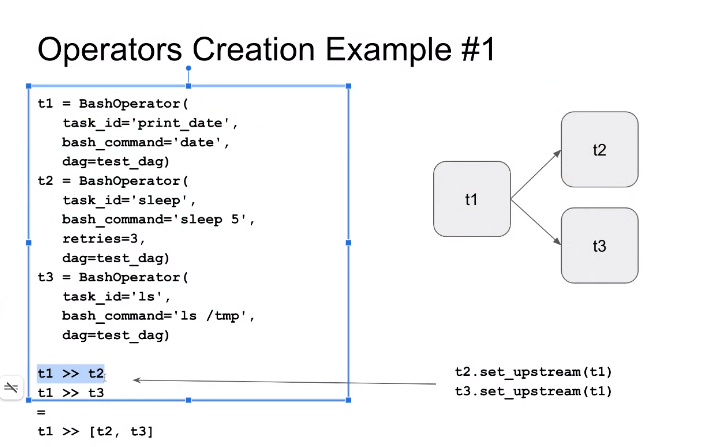
대부분 t1 >> t2(오버라이딩으로 잡음)
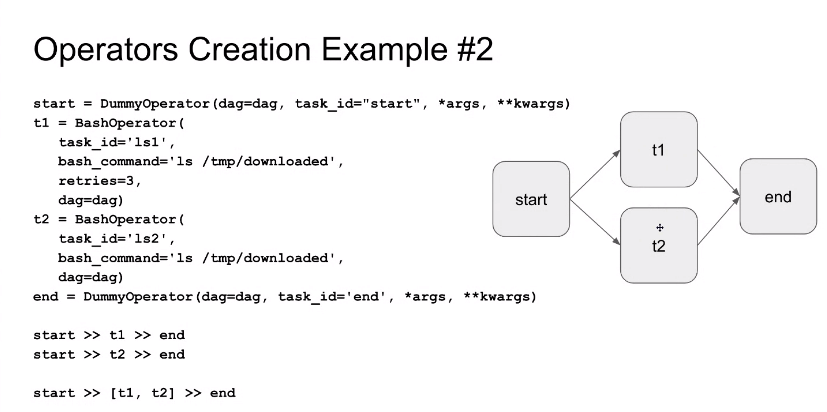
- task들이 무거워서 언제 끝나는지 알고싶다 라고 할 때, end 사용. start는 병렬이 시작될 때 분기전 start를 잡으면 시작하는 시간을 알 수 있음. 편의성을 위해 사용함
데이터 파이프 라인 만들 때 주의점

- 코드가 5줄이 넘으면 버그발생한다.... ㅋㅋㅋㅋ 실패를 가정하고 코드를 짜야함.
- 파이프라인 수가 늘어나면, 데이터 소스의 수가 늘어나고, 그럼 매일 1-2개는 안돈다. 그때 그 소스가 중요하면 난리나는거고요,,,,, ㅎ,,,,, 에러이슈가 어떤건지 빨리 알아야하고, 그 담당자에게 알려야함(비지니스오너 작성의 중요성)

- Incremental update : 주기적으로 도는게 일반적. 해당 기능이 가능할 때만 가능


- Incremental update의 경우 백필(문제가 생겼을 때 다시 실행하는 것)을 할 때, 그 시점으로 돌아가서 다시 읽어야하기 때문에 복잡해질 수 있음
- 데이터가 커지면서 다 읽어오는 것(full request)가 시간이 오래걸려 어려움. 이럴 때 다시 백필을 해오는 능력이 DE의 능력임

- 유데미시절 쿼터에 한번씩? 안쓰는 데이터 삭제하심
- 불필요한 데이터삭제 하는게 중요함

- 사고를 막을 순 없다. 생긴 후 어떻게 처리를 하는지가 중요함.
- 중요한 파이프라인은 앞뒤로 출력해보면서 확인해야함.
- DBT를 쓰면 서머리 요약을 만드는게 쉬움
Airflow의 Backfill 방법
- start date를 이해하는 게 중요함!
만약, start_date : datetime(2020,8,31, hour=0, minute=00)이라면 이 날짜에 처음 시작하는 것으로 생각함.
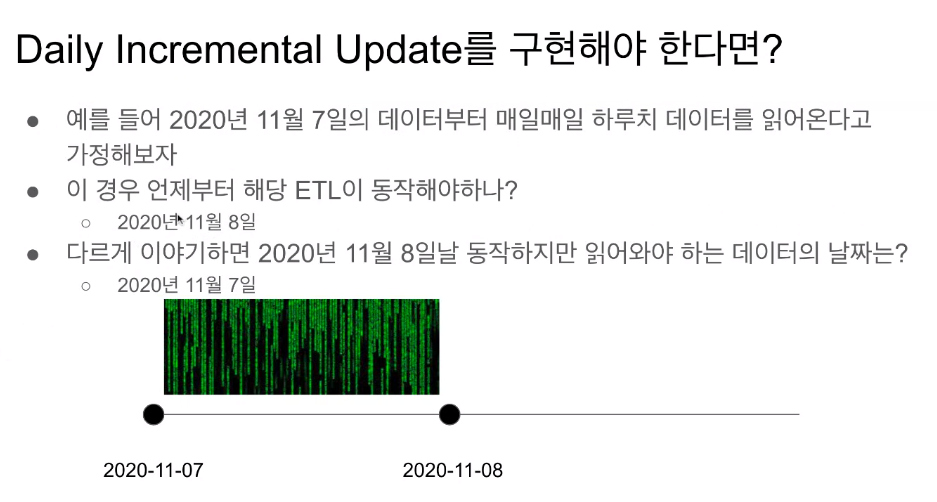
- 처음 읽어와야하는 데이터의 날짜를 start date이라고함.
- 하루 뒤에 실행이 됨.
- 이 대그가 이 날짜의 데이터를 처음 읽어오는 것으로 생각함.
여기 잘 못들음
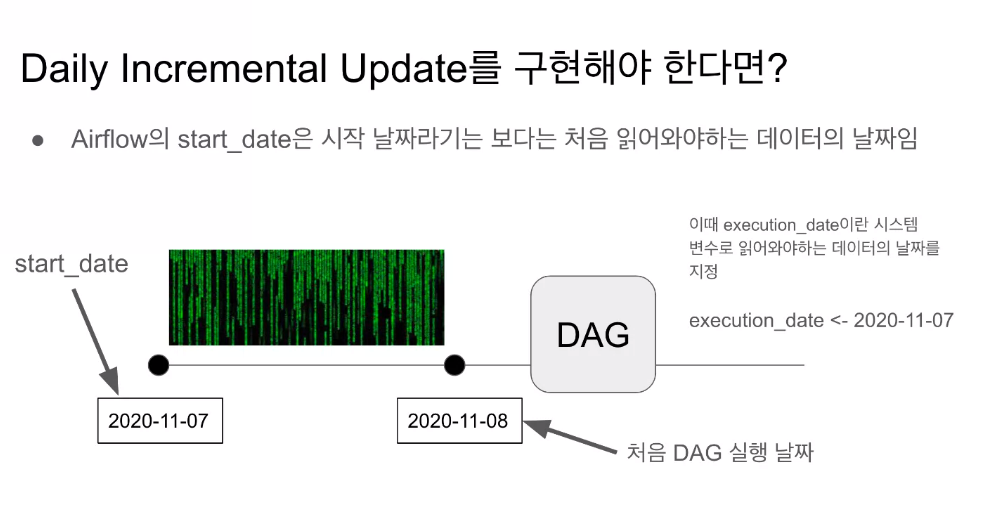
- start date는 처음 읽어와야하는 데이터의 날짜다!!!
- 처음 실행은 11월 8일에 실행되지만, Execution date가 해당 날짜를 보내주기때문에 편하다..,,?
예전 사용방법

- 어떤일이 발생하든 오류가 발생한다. 그럼 해당 코드로 들어와서 날짜를 일일이 수정해줘야함.
- Inceremental을 지금 시간을 기준으로 하면 안된다. 시스템에서 정해준 시간을 보고 거기서 하라는대로 코딩할 수 있어야함.

- fullrequest는 상관없음!
Q. start_date는 airflow 기준에서 start_date+1 에 동작을 한다고 봐도 될까요?
- 맞음. 하지만 DAG의 설정을 통해 1이 1일이 될 수도 있고, 1분이 될수도 있음
Q. 그리고, DAG 중 데이터를 수집하는 기준이 start_date ~ end_date라면 데이터 내에 start_date에 맞는 datetime 데이터가 반드시 존재해야 하나요?
- 무조건은 아님.

- 실행이 안된 8일이 무조건 실행됨 catchup이 True면(디폴트) 그 사이 값이 다 스케쥴링이 됨.
- 1달에 한번 돌리는 큰 쿼리였는데,,,

- 11일 2시에 시작 (execution date은 10일 2시)
- 이렇게 11,12,13일 3번 실행됨 (Catchup이 False면 안돔!!! 풀리퀘는 Catchup이 False인게 좋음)
- 에러가 나면 어중간하게 넘어가면 안됨. 정확하게 알려주고 해결해야함 -> 그걸 위한게 Transaction
- load는 Transaction이 되야함.
다 성공하던지, 이전 상태로 돌아가서 에러메세지 날리던지.
Q. full refresh만 해도 지장이 없는 상황이라면 이 경우엔 airflow를 사용해야하는 이유가 어떤것이 있는지 궁금합니다.
airflow 용례를 설명주신것으로 봤을 때 incremental update에 적합한 것 같아서요.
단순한 full refresh는 crontab이나 jenkins만으로 관리가 가능하면 airflow까지 구성해야할까하는 생각이 들었습니다
- 데이터 파이프라인의 수가 적으면 괜춘, 수가 많으면 airflow가 좋다. 댁들이 서로 트리거가 될 수 있음.

차보의 Data Engineer 도전기♥ (근데 기록을 곁들인)