Logical Data Modeling
이전 단계인 Conceptual Data Modeling은 유저의 요구사항을 ER Model로 표현하는 것이다. 이 단계에서는 유저의 비즈니스 요구사항을 어떻게 정확하게 뽑아내는지에 초점을 맞췄다.
이번 단계인 Logical Data Modeling에서는 데이터베이스 기술 아래에서 데이터를 어떻게 구성하는지를 목표로 둔다.
Relational data model
Relational data model은 Logical data modeling단계에서 사용하는 주된 도구 중 하나이다.
Logical database design시 목표는 이전 단계에서 진행한 산출물을 가지고 데이터베이스 기술에 사용할 수 있는 논리적으로 실행가능한 design(logical design implementable)으로 변환하는 것이다.
Relational data model은 E.F.Codd에 의해 만들어졌으며 궁금한 사람은 하단의 참고를 확인해보자.
Component
Relational data model의 구성요소는 다음과 같다.
- Data structure : 데이터는 row와 column을 가진 relation들(혹은 테이블들)로 구성된다.
- Data integrity : 데이터의 정확성과 일관성을 확실하게 해줄 수 있는 규칙 및 메커니즘을 지원한다. 이것들은 데이터가 저장이나 조작될 때, 비즈니스 규칙들과 함께 따르게 된다.
- Data manipulation : 서로 다른 relation들(혹은 테이블들)에 저장된 데이터를 추출, 조작하기 위해서 이해하기 쉽지만 강력한 operation들을 SQL에 의해 지원된다.
간단하게 설명하면 data structure는 어떻게 데이터를 구성하는지, data integrity는 어떻게 비즈니스 규칙을 따르면서 데이터의 무결성을 유지하는지, data manipulation은 어떻게 데이터를 읽고, 쓰는 것과 같은 조작을 하는지를 의미한다.
Data structure
데이터는 row와 column을 가지는 relation들(혹은 table들)로 구성된다.
- Relation : 이름을 가지는 2차원 데이터 테이블이다.
표현식은 다음과 같다.
TableName (Column1, Column2...)
Relation의 구성요소를 부르는 이름들을 다음과 같이 여러 가지 이름을 가지게 된다.
| Formal terms | Alternative1 | Alternative2 |
|---|---|---|
| Relation | Table | File |
| Tuple | Row | Record |
| Attribute | Column | Field |
- Notation : Relation의 표현식
Relation의 구조를 표현하는 방법은 2가지가 존재한다.
- 간단한 텍스트로 표현 : 위에서 언급한 table표현 방식을 이용하면 된다.
Relation Name (Identifying Attrtibute, Other Attritute List)
- 그림으로 표현 : 표로 그리는 것이다.
책을 예시로 들어보자. 다음과 같이 표현된다.
| BookID | Title | Price |
|---|---|---|
| B1 | 'Game Master' | 12000 |
| B2 | 'Database Master' | 33000 |
| B3 | 'Unity Master' | 35000 |
Relation
- 특징
- Database 내에서 relation은 unique한 이름을 갖는다.
- 모든 attribute 값들은 여러 값들로 분해되는 것이 아닌 하나의 값을 갖는다.
- 모든 row들은 unique하다. 즉, 모든 필드 내의 값들이 똑같은 row가 또 존재할 수 없다.
- Attribute들은 relation 내에서 unique한 이름을 갖는다.
- Column들의 순서는 무관하다.
- Row들의 순서는 무관하다.
- Key Fields : 2가지 목적의 특별한 field들인 key가 존재한다.
- Primary Key : Relation의 unique한 구분자(Identifier) 역할을 한다. 예를 들어, 학번, 주민번호와 같은 것이다.
- Foreign Key : 의존하고 있는 relation의 구분자(Identifier)이다.
- Key들은 하나의 field이거나 그 이상의 field일 수도 있다.
- 유저의 질문(Query)의 응답속도를 높이기 위한 index로 사용된다.

- Database : Relation들의 집합
- Database Schema : Database의 구조
Data Integrity
데이터의 정확도와 무결성을 용이하게 해준다. 3개의 Constraint가 존재한다.
- Domain Constraint
- Entity Integrity
- Referential Integrity
Domain Constraint
Attribute의 값들이 미리 정의된 도메인으로부터 나온 것이여야 하는 제약이다. 여기서 도메인은 도메인 이름, 의미, 데이터 타입, 크기, 허용가능 값들을 포함하고 있다.
Entity Integrity
Entity Integrity를 설명하기 전에 Null에 대해 이야기를 하겠다. Null은 값이 없는 것이거나 값이 빠진 것을 의미한다. Null은 숫자 0도 아니고 빈 문자열도 아니다.
Entity Integrity는 primary key attribute가 null이면 안된다.
- Relation은 무조건 primary key를 가져야 한다.
- Relation 내의 각각의 tuple들은 primary key를 위한 값을 가지고 있어야 한다.
각각의 데이터 row들은 하나의 unique한 사실을 의미하며, primary key 없이는 그것들을 구분할 수 없다.
Referential Integrity
각각의 foreign key 값들은 다른 relation의 primary key 값과 연결되어야 하며, 혹은 foreign key가 null이어야만 한다.
ER Model → Relational Data Model
-
각각의 entity type을 relation에 연결한다. Relation은 다음의 attribute를 포함한다.
- Entity type의 모든 simple attribute.
- Entity type의 composite attribute의 모든 simple attribute.
- Identifier attribute는 primary key에 대응한다.
단, Muli-Valued attribute는 포함하지 않는다.
-
각각의 weak entity type은 relation이 된다. Primary key는 다음의 것으로 구성된다.
- Weak entity type의 partial key.
- Weak entity type의 identifying owner의 identifier attribute.
즉, primary key가 1개가 아니다.
위의 두번째 key는 foreign key가 된다. 즉, primary key 겸 foreign key다.
-
각각의 binary 타입의 1:M 관계 relationship type은 1쪽의 entity type의 primary key가 M쪽의 entity type에 foreign key로 들어간다.
-
M:M 관계의 relationship type은 양쪽 entity type의 primary key를 primary key로 가지는 매핑 테이블을 만든다.
-
1:1 관계의 relationship type은 아무 쪽에나 foreign key를 넣어도 되지만, 미래를 생각하여 total paricipation이 되는 쪽에 넣는 것이 좋다.
-
Unary relationship type은 위의 3~5단계를 적용한다.
-
N-ary(n>2)인 relationship type은 relation으로 변환한다.
- 이 relation은 relationship에 참여 중인 relation들의 primary key들을 primary key로써 포함한다.
- 이 relation은 relationship type의 attribute들을 포함한다.
- Primary key는 foreign key들의 조합이다.
-
Supertype, subtype을 연결한다.
- Supertype은 하나의 relation이 된다.
- 각각의 subtype들은 하나의 relation이 된다.
- Identifier attribute를 포함한 supertype의 attribute는 supertype relation에 포함된다.
- Subtype attribute는 각각의 subtype relation에 포함된다.
- Supertype relation의 primary key는 각각의 subtype relation의 primary key가 된다.
- Subtype relation의 primary key는 foreign key의 역할도 하며, supertype relation과 연결된다.
-
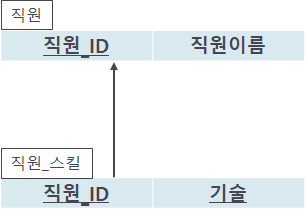
각각의 multi-valued attribute는 그것만의 relation을 만든다.
Multi-valued attribute를 위한 relation에서 primary key는 Multi-valued attribute를 가지고 있던 relation의 primary key와 각각의 값들의 조합으로 이뤄진다.
아래의 예시를 통해 확인해보자.
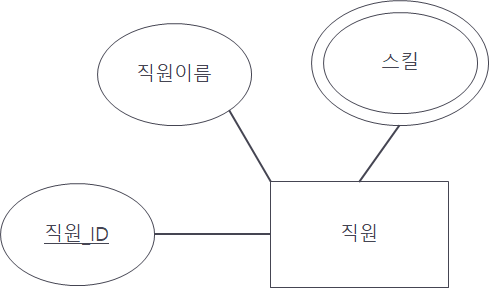
스킬이 multi-valued attribute이다. 이 경우, 스킬을 위한 relation을 만든 후, 직원_ID와 각각의 스킬로 조합되는 primary key를 가지는 relation을 만드는 것이다. 아래를 확인해보자.