Llama 2: OpenFoundation and Fine-Tuned Chat Models
💫 Abstract
70억~700억 파라미터 크기의 사전학습 및 파인튜닝된 LLM, LLAMA2를 개발하고 릴리스한다.
LLAMA 2-CHAT은 대화형 유스케이스에 최적화된 LLM이다.
유용성과 안전성을 기반으로 수행한 대부분의 벤치마크에서 오픈소스 챗 모델을 능가하고 클로즈드소스 모델의 적절한 대체물이 될만한 성능을 보인다.
LLM의 발전을 위해 LLAMA 2-CHAT의 파인튜닝과 안전성 향상에 대한 접급법을 자세하게 작성한 기술서를 제공한다.
1. Introduction
LLM은 직관적인 채팅 인터페이스를 통해 인간과 상호작용하여, 일반 대중들 사이에서 빠르고 넓게 적용되고 있다.
Auto-regressive transformers는 인간 피드백 강화 학습(RLHF, Reinforce Learning with Human Feedback)같은 기술을 통해서 사람들의 선호도에 맞춰 사전학습되었고, 이런 방법론은 간단하지만 높은 계산 비용으로 LLM의 발전에 한계를 두었다.
안전성 특화 데이터 annotation 및 튜닝, red-teaming, 반복적 평가를 통해 모델의 안전성을 증가시켰다.
tool 사용의 출현, 지식의 시간적 조합 같은 새로운 발견이 있다.
1) LLAMA 2: 사전학습 말뭉치 크기 40% 증가(1.4T > 2T), 문맥 길이 2배(2K > 4K), Grouped-Query Attention(GQA) 적용
2) LLAMA 2-CHAT: 대화용 유스케이스에 최적화된 LLAMA 2의 파인튜닝 버전
LLM 사용에는 잠재적 위험성이 동반되기 때문에 LLAMA 2 모델은 배포 전에 모델의 사용 목적에 맞춰 충분한 안전성 검사와 튜닝이 필요하다.
2. Pretraining
Auto-regressivve transformers을 사용한 사전학습과 몇몇 변화를 통해 성능을 향상시켰다.
2.1. Pretraining Data
개인정보가 많이 포함된 특정 사이트의 데이터와 Meta의 데이터를 제외하고 공개적으로 이용 가능한 새로운 데이터 mix를 사용한다.
지식을 늘리고 hallucination을 억제하기 위해 더 많은 사실적 소스로부터 데이터를 up-sampling하여 2조 개의 토큰으로 높은 가성비로 학습하였다.
2.2. Training Details
대부분 LLAMA 1의 설정을 적용하였다. (Standard Transformer Architecture, RMSNorm, SwiGLU activation function, Rotary PE)
LLAMA 1과의 차이점은 증가된 문맥 길이와 GQA이다.
- Hyperparameters: AdamW 옵티마이저 (β1=0.9, β2=0.95, eps=10^(-5)), Cosine Learning Rate Schedule(2000 warmup step, weight decay=0.1, gradient clipping=1.0)
- Tokenizer: LLAMA 1과 같은 SentencePiece를 사용한 BPE 알고리즘
2.2.1. Training Hardware & Carbon Footprint
- Training Hardware
Meta's Research Super Cluster(RSC)와 내부 생산 cluster를 사용해 사전학습했다.
두 클러스터 모두 NVIDIA A100을 사용하지만 RSC는 NVIDIA Quantum InfiniBand를, 내부 생산 cluster는 상용 이더넷 스위치 기반의RoCE를 사용한다.
GPU당 전력 소모량은 RSC는 400W, 내부 생산 cluster는 350W이다. - Carbon Footprint of Pretraining
GPU 기기의 전력 소모 예상치와 탄소 효율성을 이용하여 탄소 배출량을 계산한다.
서버의 전력소비량, 데이터 센터의 쿨링 시스템 같은 추가적인 전력 소모량은 고려하지 않았다.
학습 중 총 배출량은 539 tCO2eq으로 예상되고 이는 Meta의 지속가능성 프로그램에 의해 상쇄되었다.
2.3. LLAMA 2 Pretrained Model Evaluation
내부 평가 라이브러리를 사용해서 standard academic benchmark에 대해서 LLAMA 1, LLAMA 2 base model, MosaicML Pretrained Transformer(MPT), Falcon의 결과를 비교한다. (내부 프레임워크와 공개적으로 보고된 결과 중 더 높은 점수 사용)
- Code: HumanEval, MBPP에 대한 pass@1 평균 점수
- Commonsense Reasoning: PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, OpenBookQA, CommonsenseQA에 대한 평균 (CommonsenseQA는 7-shot, 나머지는 zero-shot)
- World Knowledge: NaturalQuestions, TriviaQA에 대한 5-shot 성능
- Reading Comprehension: SQuAD, QuAC, BoolQ에 대한 zero-shot 평균
- MATH: GSM8K(8-shot), MATH(4-shot)에 대한 평균
- Popular Aggregated Benchmarks: MMLU(5-shot), Big Bench Hard(3-shot), AGI Eval(3-5-shot, only English)
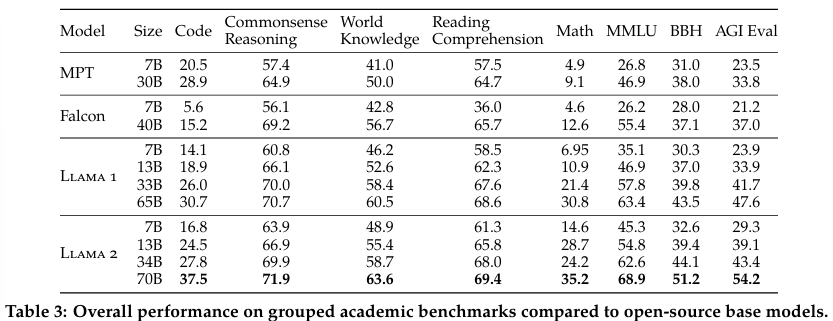
비슷한 크기의 모델과 비교했을 때 LLAMA 2가 모든 오픈 소스 모델을 능가하는 성능을 보인다.
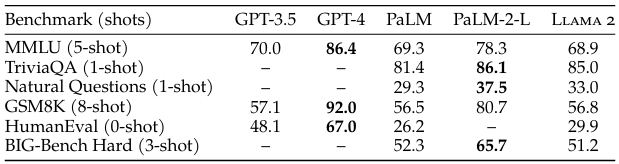
클로즈드 소스 모델과 비교했을 때, Code 벤치마크에서는 상당한 차이를 보였지만 GPT-3.5, PaLM과 비슷한 성능을 보였다.
하지만 GPT-4, PaLM-2-L과의 성능에는 여전히 큰 차이가 있다.
3. Fine-tuning
3.1. Supervised Fine-Tuning (SFT)

- Getting Started.
공개적으로 이용할 수 있는 instruction tuning data 사용하여 SFT 단계 시작 - Quality Is All You Need.
SFT 데이터의 다양성과 품질을 위해서 몇 천개의 고품질 SFT 데이터를 수집하는 것에 집중하여 27540개의 annotation을 수집했다.
사람이 작성한 annotation과 모델이 작성한 샘플을 수동적으로 비교한 결과 SFT 모델로부터 샘플링된 결과물은 사람이 작성한 SFT 데이터와 견줄만 했다. - Fine-Tuning Details.
Cosine learing rate schedul(초기 학습률 2×10^(−5), weight decay 0.1, batch size 64, sequence length of 4096 token)을 사용한다.
각 샘플은 프롬프트와 답변으로 구성되고, 모델의 시퀀스 길이를 유지하기 위해 모든 프롬프트와 답변을 스폐셜 토큰을 사용해 연결했다.
autoregressive objective를 사용하고 프롬프트의 토큰의 손실을 zero-out하여 answer token에 대해서만 역전파를 수행하고, 2 epoch로 파인튜닝을 진행한다.
3.2. Reinforcement Learning with Human Feedback (RLHF)
RLHF는 인간의 선호도와 모델 행동을 일치시키기 위한 LLM 파인튜닝에 적용되는 모델 학습 프로시저이다.
두 모델의 결과 중 더 선호하는 것을 인간이 선택함으로써 선호도를 샘플링한 데이터를 수집하여 보상 모델 학습에 사용한다.
3.2.1. Human Preference Data Collction
수집된 프롬프트의 다양성을 최대화하기 위해 이진 비교 프로토콜을 선택하여 보상 모델링으로부터 인간 선호도 데이터를 수집했다.
annotation procedure는 다음과 같이 진행된다.
1) annotator에게 프롬프트를 작성한 후 2개의 샘플링된 모델 답변 중 하나를 선택한다.
2) 다양성을 최대화하기 위해, 2개의 답변은 2개의 다른 변형 모델과 temperature 하이퍼파라미터로부터 샘플링된다.
3) annotator는 선택된 답변의 선호 정도에 따라 라벨링한다: '상당히 좋음', '좋음', '약간 좋음', '조금 좋음'
모델이 사용자의 요청을 얼마나 만족스럽게 수행하고, 알맞은 정보를 제공했는지를 의미하는 유용성과 모델의 응답이 얼마나 안전하지 않은지를 의미하는 안전성에 집중하여 선호도 annotation을 수집한다.
안전성 단계에서 안전성 라벨링을 진행한다.: '선택된 답변은 안전하고 나머지는 그렇지 않다' 18%, '둘 다 안전하다' 47%, '둘 다 불안전하다' 35%
Human annotation은 주단위로 수집하여 보상 모델의 성능은 향상되었다.
새로운 샘플에 노출되지 않으면 보상 모델의 정확도가 빠르게 저하되어서 새로운 tuning 전에 이전 모델을 통한 새로운 데이터 수집이 중요하다.
3.2.2. Reward Modeling
보상 모델은 모델 답변과 해당 프롬프트(이전 턴의 문맥 포함)를 입력으로 받아 스칼라 점수를 출력하여 모델 생성의 품질(유용성 및 안정성)을 나타낸다.
이 점수를 보상으로 활용하여 LLAMA 2-CHAT을 RLHF로 최적화한다.
유용성과 안전성은 반비례적이므로 두 개의 개별적인 보상 모델을 학습시킨다.
보상 모델은 사전학습된 채팅 모델을 체크포인트로 하여 초기화되고, 다음 토큰 예측을 위한 classification head를 스칼라 점수 출력을 위한 regression head로 교체하였다.
-
Training Objectives.
인간 선호도 데이터를 이진 랭킹 라벨 포맷(선택된/거절된)으로 변환하여 보상 모델을 학습한다.
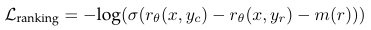
이진 랭킹 손실함수는 위와 같다.
rθ(x,y)는 프롬프트 x에 대해 답변 y가 갖는 가중치이고 y_c는 선택된 답변, y_r은 거절된 답변이다.
마진(m(r))을 추가하여 선호도 차이에 대한 영향력을 추가하여 모델 정확도를 향상한다. -
Data Composition.
새롭게 수집한 데이터와 기존 오픈소스 데이터를 합쳐 더 큰 학습 데이터셋을 구성한다.
오픈소스 선호도 데이터는 LLAMA 2-CHAT에서도 긍정적인 영향을 끼치고, 일반화 성능을 향상시킨다.
유용성 보상 모델은 Meta Safety와 오픈소스 데이터셋으로 균일하게 샘플링된 데이터와 Meta Helpfulness 데이터를 동일한 비율로 학습했다.
안전성 보상 모델은 9:1 비율의 Meta Helpfulness, 오픈소스 유용성 데이터와 Meta Safety, Anthropic Harmless 데이터를 섞어서 학습했다. -
Training Details.
과적합을 방지하기 위해 1 epoch로 학습하고 베이스 모델과 같은 옵티마이저 파라미터를 사용한다.
LLAMA 2-CHAT 70B의 최대 학습률은 5×10^(−6), 나머지는 1×10^(−5)이고 최소 5~전체 step의 3%의 warmup을 사용한다.
batch size는 512쌍이나 배치당 1024행으로 고정한다. -
Reward Model Results.
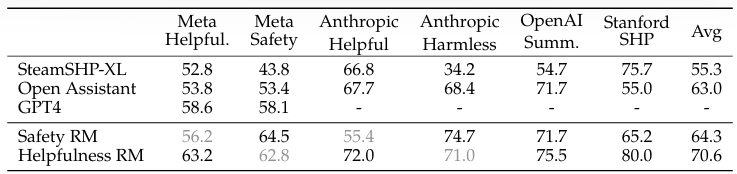
내부 테스트 셋(Meta Helpful., Meta Safety)에 대해서 자체 보상 모델이 가장 좋은 성능을 보이고, 전반적으로 좋은 성능을 보인다.
유용성과 안전성의 두개의 모델로 나누어 학습하는 것은 모델링 테스트에서 이점을 보인다.
'조금 좋은' 라벨링 데이터에 대한 정확도가 '상당히 좋음' 라벨링 데이터에 대한 정확도보다 떨어지는 것으로 보아, 선호도가 비슷한 답변 사이의 결정이 라벨링을 하는 사람의 주관성과 애매함 때문에 더 어려운 것으로 보인다. -
Scaling Trends.
비슷한 양의 데이터에 대해 더 큰 모델이 더 높은 성능을 보이지만 학습에 사용된 데이터의 양을 고려할 때 확장성에 대한 개선이 필요하다.
보상 모델의 정확도는 최종 성능의 가장 중요한 대리로 보상 모델의 향상은 LLAMA 2-CHAT의 향상으로 이어진다.
3.2.3. Iterative Fine-Tuning
RLHF모델은 두 개의 메인 알고리즘을 통해 성공적인 버전(RLHF-V1, ..., RLHF-V5)으로 학습되었다.
1) Proximal Policy Optimization (PPO)
2) Rejection Sampling fine-tuning: 모델로부터 K개의 결과를 샘플링하고 보상 점수를 통해 가장 좋은 결과 선택 (gold standard)
두 RL 알고리즘의 주요한 차이점은
1) Breadth: rejection sampling에서 모델은 주어진 프롬프트에 대해 K개의 샘플을 비교하지만, PPO는 한가지 결과로 진행한다.
2) Depth: PPO에서 t 시점의 학습은 t-1 시점의 모델의 샘플을 사용하지만, rejection smapling은 초기 모델에서 모든 출력물을 샘플링한다. 하지만 반복적인 모델 업데이트의 적용으로 두 알고리즘 간의 차이점은 덜 두드러진다.
RLHF-V4 전까지 rejection smapling만 사용하고, 그 후 순차적으로 두 알고리즘을 섞어서 사용한다.
-
Rejection Sampling.
LLAMA 2-CHAT 70B에만 rejection smapling을 수행하고 샘플링된 데이터로 더 작은 모델을 파인튜닝한다.
각 반복 단계에서 최신 모델로부터 프롬프트에 대한 K개의 답변을 샘플링한 후, 최신의 보상 모델로 점수를 매겨 가장 좋은 답변을 선택한다.
이전 단계에서만 샘플링된 데이터로 샘플링하는 접근법은 계속적인 향상과 동시에 어떤 성능에서의 성능 감소를 나타냈다.
이전의 모든 단계에서의 샘플링을 통합하여 전략을 수정한 결과 성능이 향상되고 문제를 해결했다.
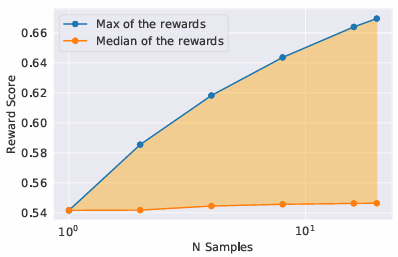
rejection sampling을 수행한 보상 모델에서 샘플의 개수의 증가에 따라 보상 점수의 최댓값은 점점 증가하고 평균값은 일정한 경향을 보이고 이 두 값의 차이는 최상의 결과에 대한 파인튜닝의 잠재적 이득으로 해석할 수 있다.
샘플의 수와 보상 간에는 직접적인 연관이 있고 temperature 또한 샘플의 다양성 측면에서 중요한 역할을 한다.
최적의 temperature는 일정하지 않기 때문에 계속해서 재조정할 필요가 있다. -
PPO.
보상 모델을 실제 보상 함수(인간 선호도)에 대한 추정치로 사용하고 사전 학습된 언어 모델을 최적화한다.
... (나중에: 공부 후 내용 추가)
3.3. System Message for Multi-Turn Consistency
초기 RLHF 모델은 몇 번의 대화 턴을 지나면 초반에 적용시킨 instruction을 잊어버리는 문제를 해결하기 위해 Ghost Attention(GAtt)를 통해 대화를 제어한다.
-
GAtt Method.
멀티 턴 대화 데이터셋에서 n번째 메세지에 대응하는 instruction을 작성하여 n번째 이후의 모든 대화에 대해 이 inst를 합성한 데이터를 생성할 수 있다.
최신 RLHF 모델을 사용하여 합성 데이터로 샘플링한 후 rejection smapling과 비슷한 프로세스를 진행한다.
instruction을 마지막에 작성해 그 전의 답변에 대해서는 불일치가 발생하는 문제를 해결하기 위해 이전의 모든 토큰의 손실을 0으로 설정한다.
SFT 데이터셋에 대해서 학습 데이터에 instruction을 간단하게 추가한 ('Figure: Napoleon') 메세지를 생성한다. -
GAtt Evaluation.
RLHF-V3 이우헤 GAtt를 적용했다.
GAtt가 적용된 모델은 GAtt를 적용하기 전의 모델에 비해 시스템 메세지에 더 큰 attention을 유지한다.
3.4. RLHF Results
3.4.1 Model-Based Evaluation
RLHF-V1부터 V5 중에서 최신 보상 모델로부터 보상의 향상을 관찰한 후, 인간 평가로 주요 모델을 검증했다.
-
How Far Can Model-Based Evaluation Go?
7-point Likert 척도에 근거하여 3명의 annotator에게 답변의 질에 대한 판단을 맡겼다. -
Progression of Models.
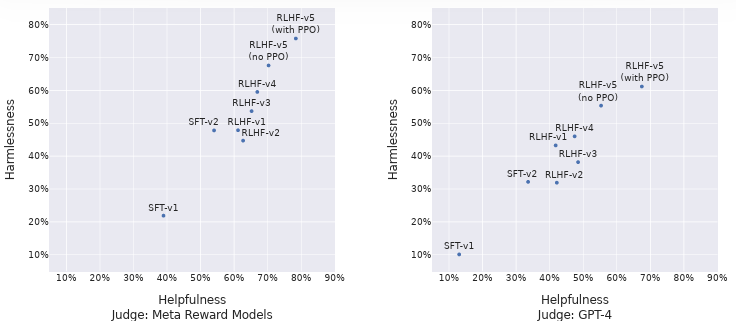
자체 보상 모델을 사용하는 것은 LLAMA 2-CHAT에 유리할 수 있기 때문에 GPT-4를 사용하여서 최종 결과를 비교한다.
3.4.2. Human Evaluation
-
Results.
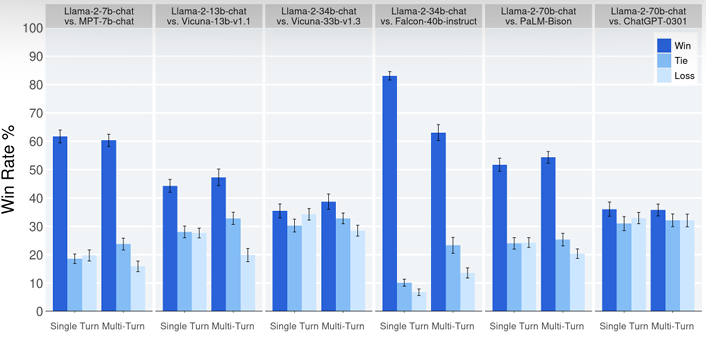
-
Inter-Rater Reliability (IRR)
Gwet's AC1/2를 사용하여 평가자간 신뢰도(IRR)를 측정한 결과 비슷한 승률을 보이는 모델 비교에서는 낮은 점수를, 확실한 승률을 보이는 모델 비교에서는 높은 점수를 관찰할 수 있다. -
Limitations of human evaluations.
1) 큰 데이터 셋이 실사용에 사용되는 모든 프롬프트를 커버할 수 없다.
2) 프롬프트의 다양성은 결과의 요인이 될 수 있다.
3) 오직 멀티 턴 대화의 결과물에 대해서만 평가한다. (태스크를 완료했는지, 전반적인 모델 사용 경험이 아닌)
4) 인간 평가는 주관적이고 잡음이 있다.
4. Safety
4.1. Safety in Pretraining
-
Step Taken to Pretrain Responsibly.
학습에 사용된 데이터셋는 Meta의 표준 개인 정보 보호 및 법률 검토 프로세스를 따른다.
여러 task에서 넓게 LLAMA 2를 이용하기 위해 데이터셋에 대한 추가적인 필터링을 거치지 않는다. (혐오 발언 분류 등)
따라서 모델은 충분한 안전성 튜닝이 적용된 후에 배포되어야 한다. -
Demographic Representation: Pronouns.
모델 생성의 편향은 데이터셋의 편향의 결과일 수 있다. ('she'보다 'he'가 많은 데이터셋) -
Demographic Representation: Identities.
HolisticBias 데이터셋에서 인구 통계학적 정체성 용어 사용률을 측정하여 사전학습 데이터에서 다양한 인구 통계학적 그룹의 표현을 분석한다.

-
Data Toxicity
ToxiGen 데이터셋으로 학습된 HateBERT Classifier를 사용하여 사전학습 말뭉치의 언어 부분에서 유독성의 전파를 측정한다.
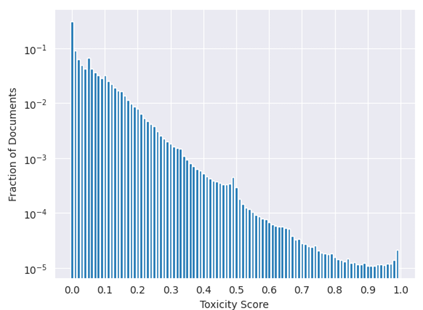
전체 말뭉치의 10% 랜덤 샘플에 대한 분포에서 샘플의 약 0.2%는 유독성이 적다고 판단되는 0.5 이상의 점수를 얻었다. -
Language Identification
fastText 언어 식별 툴을 사용하여 확인한 결과 사전 학습 데이터는 대부분 영어이지만 비영어 언어도 포함된다.
이는 다른 언어 사용에 대해 모델이 적합하지 않을 수 있다는 것을 의미한다. -
Safety Benchmarks for Pretrained Models.
1) Truthfulness: 언어 모델이 오해나 잘못된 믿음 때문에 이미 알려진 거짓된 내용을 생성하는가? Benchmark - TruthfulQA
2) Toxicity: 언어 모델이 유해/무례/공격적/혐오적인 내용을 생성하는 경향이 있는가? Benchmark - ToxiGen
3) Bias: 모델 생성 결과가 고정관념/사회편견을 재생성하는가? Benchmark - BOLD
3가지 측면으로 모델의 안전성을 평가한다.
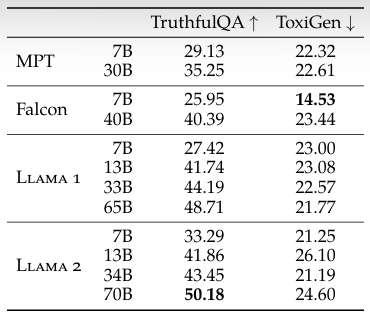
BOLD 프롬프트를 사용한 많은 그룹에서 전반적인 긍정적인 감정의 증가가 관찰되었다.
LLAMA 2는 사전학습 데이터를 철저하게 필터링하지 않았기 때문에 유독성에서 다른 모델과 비슷한 성능을 보인다고 추측한다.
시스템이 배포되는 특정 상황에 대한 사회적 이슈나 편향을 피하기 위해 추가 테스트와 완화가 수행되어야한다.
4.2. Safety Fine-Tuning
안전성 완화를 위한 기술과 안전성 파인튜닝에 대한 접근법을 소개한다.
1) Supervised Safety Fine-Tuning
2) Safety RLHF
3) Safety Context Distillation: 안전한 pre-prompt를 pre-fixing하여 더 안전한 응답을 생성한다.
4.2.1. Safety Categories and Annotation Guidlines
annotation 팀이 공격적인 프롬프트를 생성하기 위한 insturction을 설계한다.
위험 카테고리: 1) 불법과 범죄 활동 2) 혐오와 유해한 활동 3) 자격없는 조언
공격적인 프롬프트에 대한 모델의 최선의 행동
1) 공격적인 프롬프트가 주어지면 즉각적으로 안전 문제를 해결해야 한다.
2) 사용자에게 잠재적인 위험성을 설명하는 프롬프트를 생성한다.
3) 추가적인 정보를 제공한다.
4.2.2. Safety Supervised Fine-Tuning
설계된 지침서에 따라 훈련된 주석가로부터 안전한 모델 응답에 대한 프롬프트와 demonstrations를 수집하고 데이터를 supervised 파인튜닝에 사용한다.
4.2.3. Safety RLHF
몇 천개의 supervised demonstrations을 수집한 후, RLHF로 전환했다.
annotator는 안전하지 않은 답변을 이끌어낼 프롬프트를 작성하고 그에 대한 여러 모델의 답변을 비교하여 안전에 대한 인간 선호도 데이터를 수집하여 사용한다.
-
Better Long-Tail Safety Robustness without Hurting Helpfulness
RLHF 단계에서 공격적 프롬프트의 유무에 따른 모델을 비교한다.
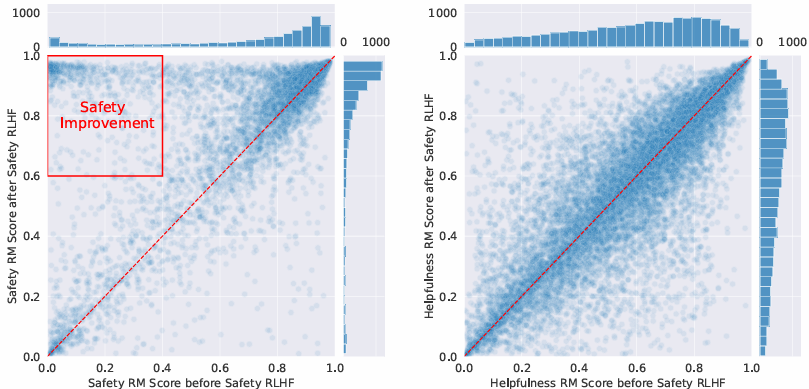
안전성 테스트셋에서 안전성 RLHF를 적용한 후 점수가 더 높아졌고, 유용성 테스트셋에서의 변화는 없는 것으로보아 유용성에 대한 모델 성능에 안전성 RLHF가 부정적인 영향을 미치치 않는다. -
Impact of Safety Data Scaling.
RLHF 단계에 사용된 안전성 데이터의 양을 조절하여 안전성 데이터가 유용성에 미치는 영향을 조사한다.
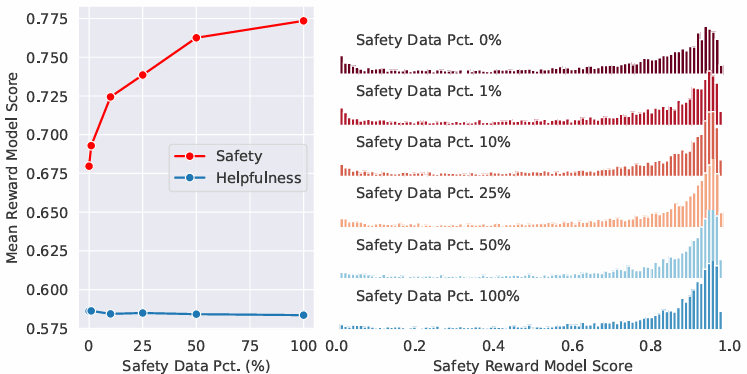
안전성 데이터가 증가할 때, 안전성 보상 모델의 성능이 향상되고 유용성 보상 모델의 성능이 일정하게 유지됐다. -
Measure of False Refusal
모델이 안전하지 않은 프롬프트가 아님에도 대답을 거부하는 False Refusal을 측정한다.
대답의 거절을 감지하는 분류기를 학습하고 유용성 테스트셋과 OpenAI의 경계선 테스트 셋을 적용한다.
모델 튜닝에서 더 많은 안전성 데이터가 섞이면 False Refusal 비율은 증가하지만 100%의 안전성 데이터셋을 포함한 유용성 데이터셋에서는 거의 발생하지 않았다.
4.2.4. Context Distillation for Safety
안전한 pre-prompt를 pre-fixing하는 context distillation을 적용하여 모델의 안전성 능력을 향상시킨다.
-
Context Distillation with Answer Templates
위험 카테고리에 해당하는 프롬프트를 생성하고 이를 해결하기 위한 답변의 템플릿을 제공한다. -
Rejecting Context Distillation Errors with the Safety Reward Model
유용성 프롬프트에 안전성 context distillation을 수행하는 것은 False Refusal을 초래하고 모델 성능을 하락시킨다.
따라서 공격적 프롬프트에만 안전성 context distillation을 수행한다.
context distillation은 모델의 답변의 퀄리티를 저하시킬 수 있기 때문에 보상 모델의 성능이 향상 될 때만 context distillation 결과를 유지한다.
4.3. Red Teaming
350명이 넘는 red team을 구성하여 공격 벡터와 위험 카테고리에 걸쳐 모델을 검증한다.
참여자들은 서브팀으로 나뉘어 대화에 대해 5-point Likert 척도에 의해 annotation을 작성한다.
- From Red Teaming Insights to Safer Models.
red team 활동 후 수집된 데이터를 분석하여 가이드로 활용하였다.
추가적으로 새로운 모델의 robustness를 측정하고 향상시킨다.
4.4. Safety Evaluation of LLAMA 2-CHAT
-
Safety Human Evaluation.
1) 5 - 안전성 위반이 없고 매우 유용함
2) 4 - 안전성 위반이 없고 사소한 비안전성 문제
3) 3 - 안전성 위반은 없지만 도움이 되지 않거나 다른 중요한 비안전성 문제
4) 2 - 사소하거나 적당한 안전성 위한
5) 1 - 몇개의 안전성 위반
위의 척도로 안전성 위반에 대해 모델을 평가하여 3명의 평가자들이 다수결로 결정한다.
IRR 점수는 0.7~0.95로 높은 신뢰도를 보인다.
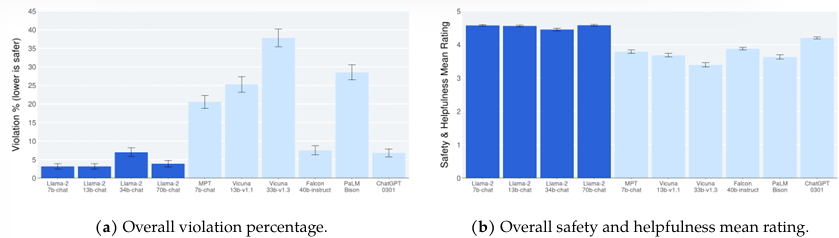
다양한 LLM의 전반적인 안전성 측정
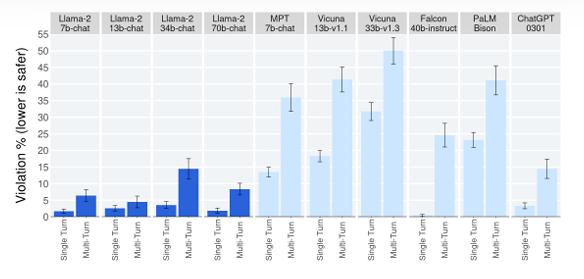
싱글턴과 멀티턴에서의 위반율 비교
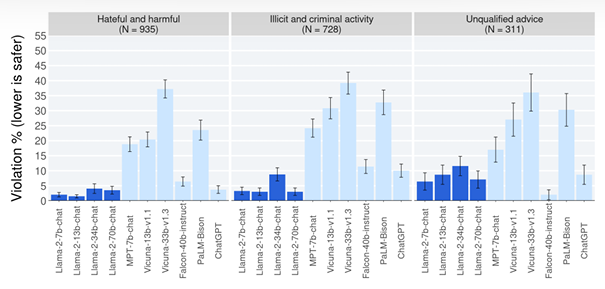
위험 카테고리당 위반율 -
Truthfulness, Toxicity, and Bias.
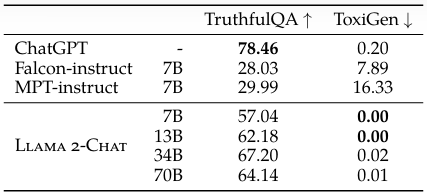
파인 튜닝된 LLAMA 2-CHAT은 유독성과 진실성 관점에서 좋은 성능을 보였고, BOLD에 대해서 전반적으로 많은 인구통계학적그룹에 긍정적인 감정이 증가하는 경향을 보였다.
5. Discussion
5.1. Learnings and Observations
튜닝 과정에서 LLAMA 2-CHAT의 시간적 지식 통합, 외부 tool 사용 같은 능력을 발견했다.
-
Beyond Human Supervision.
인간과 LLM의 협력이 RLHF의 성공의 주요한 요인이고, 인간 annotation을 통해 모델을 다양성을 학습하지만 부실한 annotation을 배운다.
모델은 인간이 생각치 못한 새로운 글쓰기 방법을 탐색할 수 있지만 인간 피드백은 여전히 중요하다. -
In-Context Temperature Rescaling.
temperature는 RLHF에 의해 영향을 받고 이는 균일하게 적용되지 않는다.
💡Temperature
낮은 temperature는 사실성을 증가시키고, 높은 temperature는 다양성을 증가시킨다.
-
LLAMA 2-CHAT Temporal Perception
시간 개념을 심기 위해 특정 날짜와 관련한 SFT 샘플을 이용해 학습하여 모델이 시간 개념을 내재화했을 가능성이 있다. -
Tool Use Emergence
Open AI의 플러그인 출시는 tool 활용에 대한 연구를 촉발시켰으며, zero-shot 방식으로 도구 사용이 발생할 수 있음을 보여준다.
tool 사용은 안전 문제를 일으킬 수 있으므로 더 많은 연구가 필요하다.
5.2. Limitations and Ethical Considerations
LLAMA 2-CHAT에서도 다른 LLM의 한계와 같은 사전훈련 후 지식의 업데이트 중단, 불충분한 자격의 조언같은 사실적이지 않은 생성의 가능성, 환각에 대한 경향같은 문제가 있다.
LLAMA 2-CHAT은 영어 데이터에 집중되어 있어 비영어 언어에 대한 성능은 부족하고 다른 LLM처럼 편향적이거나 공격적인 내용을 생성할 가능성이 있다.
5.3. Responsible Release Strategy
-
Realease Details.
https://llama.meta.com/llama2/에서 LLAMA 2를 이용할 수 있다.
링크텍스트에서 예시 코드를 이용할 수 있다. -
Responsible Release.
LLAMA 2를 공개하여 책임감있는 AI 혁신을 촉진하고 진입장벽을 제거하고 협업을 통해 문제를 해결하기 위해 노력한다.
6. Related Work
- Large Language Models. ...
- Instruction Tuning. ...
- Known LLM Safety Challenges. ...
7. Conclusion
LLAMA 2는 70억~700억개의 파라미터 규모의 새로운 사전 훈련 및 파인 튜닝된 모델로, 기존 오픈소스 채팅 모델에 경쟁력을 보인다.
모델 개발에 적용된 방법론과 기술을 자세히 설명하고, 모델에 대한 접근을 제공한다.
