회귀분석 63~, 결정트리와 앙상블 86~100,
통계 분석 기법
상관분석
𝑥와 𝑦변수 간에 관계가 어떤 선형적인 관계를 갖고 있는지를 파악하고, 두 변수가 변하는 패턴이 얼마나 비슷한가를 확인하는 과정이 상관분석이다.
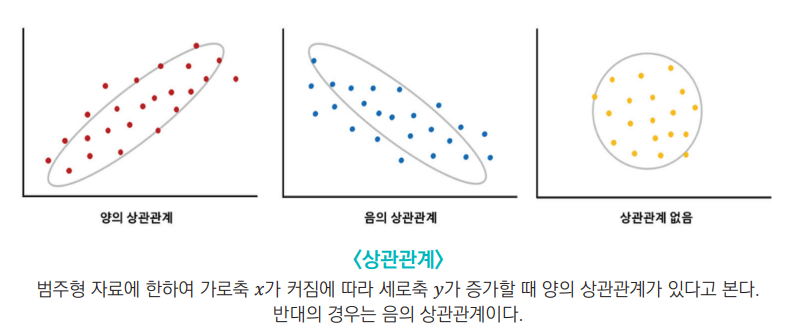
Q. 왜? 범주형 자료에 한하여라고 했을까??
수치형이어도 양아 상관이라고 해야 하는거 아닌가?
-
표준화 : 같은 데이터라도 구간의 단위에 따라서 결과가 달라 질 수 있기 때문에 구간의 범위를 통일하는 과정이 필요하다. 이를 표준화라고 한다.
-
상관계수 : 표준화 하고 얻어지는 통계량을 상관계수라고 한다. 상관계수는 독립변수 𝑥와 종속변수 𝑦간 연관성을 숫자로 나타낸다.
- 1 : 양의 상관관계가 비슷 할 수록
- -1 : 음의 상관관계가 비슷 할 수록
- 즉, -1 <= 상관계수 <= 1
-
활용
-
상관계수는 수학적인 관계를 설명하는 지표이지 인과관계를 나타내지 않는다.
ex) 아이스크림 판매량과 강력범죄율의 상관계수가 0.75라고, '아이스크림 판매가 많아질수록 강력범죄가 증가한다.'고 해설 할 수 없다.
-
상관계수는 선형의 관계를 설명할 때만 쓰인다.
비선형적 관계성이 있을경우 상관계수로 표현 할 수 없다.
-
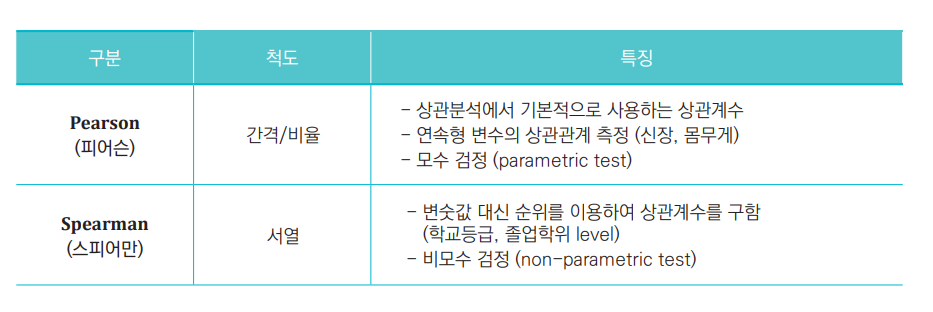
Q. 모수검정? 비모수검정...??
무슨말일까
데이터 표준화와 정규화
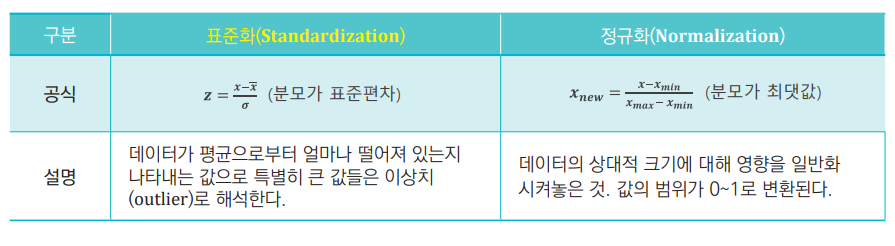
Q. 표준화가 왜 필요한자 잘 이해가 안된다.
회귀분석
예측을 목적으로 하는 통계 분석이다.
좌표상에서 데이터의 분포와 앞으로의 변화를 가장 잘 설명할 수 있는 하나의 선을 그려내는 것이 회귀분석의 궁극목적이다. 그리고 이러한 선을 추세선이라고 한다.
직선의 추세선(회귀선)
y = ax + b
직선은 이와같은 1차 방정식이다. x와 y는 현재 가지고 있는 데이터이다. 추세선을 구한다는건, 기울기(a) 와 절편(b)의 값을 찾는 것이다.
a,b 를 회귀계수라고 한다.
최소제곱법(최소자승법) (OLS)
임의의 추세선을 기준으로 분포한 x,y 죄푯값의 차이(잔차)를 제곱하여 모두 더한 값이 최소가 되는 지점들을 연결하는 방법이다. 제곱을 하는 이유는 거리(차이의 절댓값)이 필요하기 때문이다.
OLS 는 잔차의 제곱의 합이 가장 작은 직선을 찾아가게 되고, 평균으로 회귀하는 성질을 가진다.

표준오차
표준오차(SE) : 회귀선(추세선)과 데이터 간 차이의 표준값이다.
표준오차는 직선의 회귀선을 기준으로 데이터가 잘 모여있는지 퍼져있는지를 표현한다. 표준오차가 작으면 데이터가 회귀선 주변에 가깝게 분포하고, 표준오차가 크면 데이터가 멀리 펴져있다는 것을 의미한다.
표준오차가 작다 = 데이터가 회귀선 기준으로 잘 모여있다. = 회귀선이 데이터를 잘 성명해준다!!
- 표준오차가 작은것이 회귀계수의 설명력을 높이게 된다.
- 표준오차가 크면 회귀계수의 우연정도(P-value) 가 커지기 때문에 회귀선의 설명력이 떨어진다.
Q. P-value 가 우연정도였어.....??
t-value
회귀분석은 변수들간에 양,음의 상관관계가 전제가 되야 하는건데 기울기가 0이라면 의미가 없다.
그렇기 때문에 기울기가 0이 아닌지 확인을 할 필요가 있다.
추세선의 기울기를 검정하는 방법으로 t-test 를 활용한다.
T 분포.. 공부하자
회귀분석 결과
- 표준오차와 p-value 는 작을수록, t-value 는 커질수록 두 변수간의 관계가 유의미 하다는 것을 말한다.
회귀분석 순서
- 상관계수 확인하기
- pair plot 으로 데이터 분포가 선형인지 시각화하여 확인해보기
