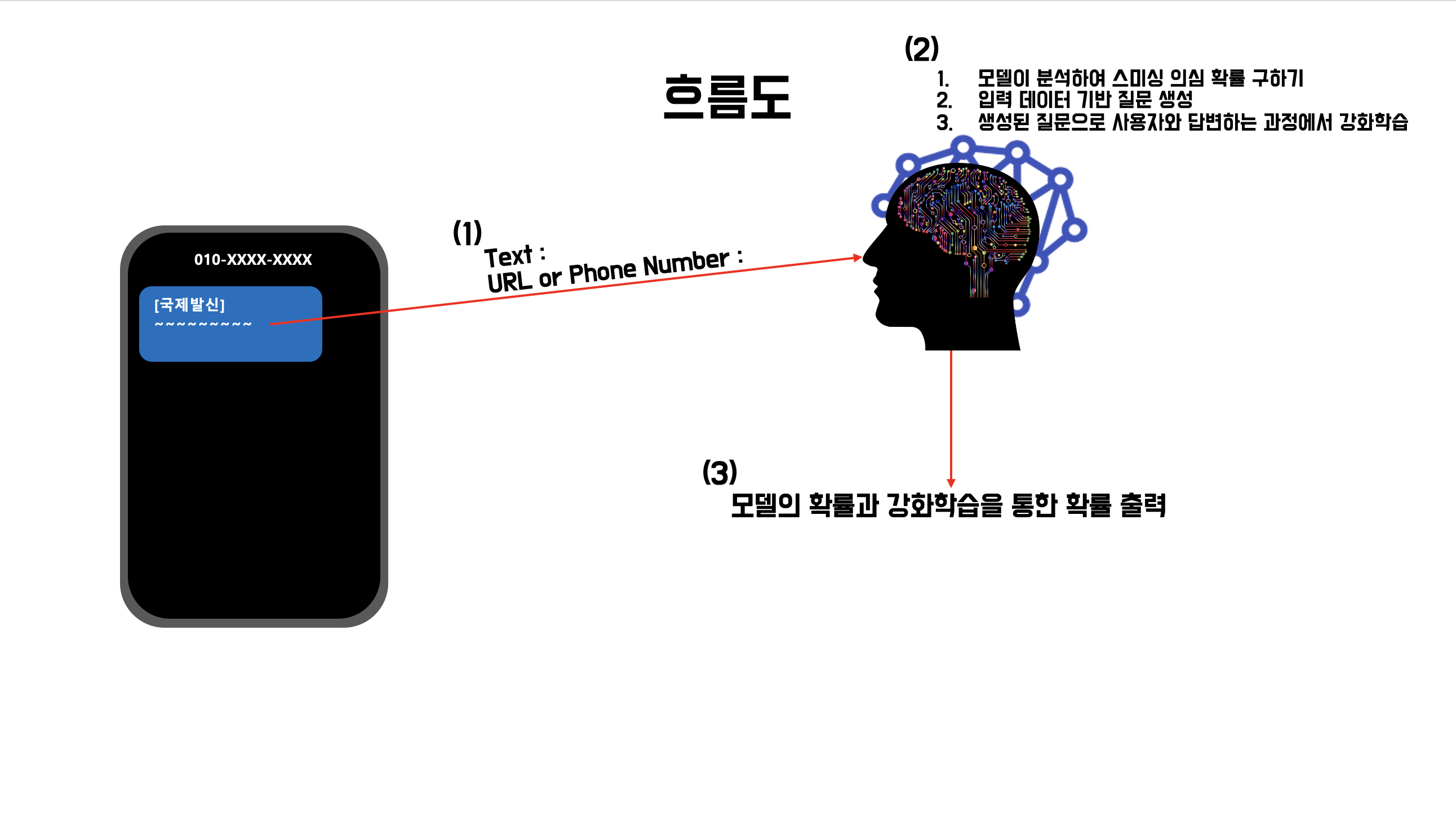
Name
: STBDS ⇒ Smishing Text Base Detection Service
Stack
: Langauge - Python
AI 학습 - 강화학습
AI 모델 - LLM(질문 생성) DistilBERT(확률 예측)
Category
: SMISHING DEFENCE AI
AI 모델
-
DistilBERT
DistilBERT는 Hugging Face에서 개발한 BERT 모델의 경량화 버전입니다.
정확히는 Knowledge Distillation이라는 기법을 이용하여, 원래의 BERT 모델보다 작고 빠르지만 거의 비슷한 성능을 유지하도록 만든 모델입니다.논문: https://arxiv.org/abs/1910.01108
목적: 속도 향상, 파라미터 수 감소, 메모리 절약 등🔧 구조 요약
항목 BERT-base DistilBERT Layers (Transformer blocks) 12 6 Hidden size 768 768 Parameters 110M 66M Training 방식 사전 학습 + 파인튜닝 Knowledge Distillation 사용 DistilBERT는 다음 요소를 제거하여 경량화함:
[token_type_ids]제거Next Sentence Prediction (NSP)제거- 레이어 개수 12 → 6개로 절반
- Softmax 출력이 teacher(BERT)의 출력을 모방하도록 학습
📘 Knowledge Distillation이란?
Knowledge Distillation은 큰 모델(Teacher)의 지식을 작은 모델(Student)에 전달하는 방법입니다.
DistilBERT는 학습할 때 다음 3가지 손실 함수(loss)를 혼합하여 사용합니다:- Soft label loss: BERT의 출력 softmax 값을 모방 (Kullback-Leibler divergence)
- MLM loss: Masked Language Modeling 손실
- Cosine embedding loss: Hidden state 간의 코사인 유사도 차이 최소화
✅ 장점
- 빠르다: 추론 속도 BERT 대비 60% 향상
- 가볍다: 파라미터 수 약 40% 감소
- 거의 같은 성능: GLUE benchmark 기준 BERT 대비 97% 성능 유지
- 모바일이나 임베디드 디바이스에 적합
❌ 단점
- 매우 복잡한 문장 해석 능력은 BERT보다는 약간 떨어질 수 있음
- 일부 도메인 특화 작업에서는 미세한 성능 손실 존재
- 원래 BERT가 가진 NSP 등 기능 제거됨
🧪 사용 예시 (Hugging Face Transformers)
from transformers import DistilBertTokenizer, DistilBertForSequenceClassification from transformers import pipeline # 분류 파이프라인 classifier = pipeline("sentiment-analysis", model="distilbert-base-uncased") result = classifier("I love using DistilBERT!") print(result)📚 참고 자료
- https://arxiv.org/abs/1910.01108
- Hugging Face DistilBERT 모델 페이지
- Knowledge Distillation 소개 (Google Research Blog)
🧠 BERT란?
BERT는 Transformer 기반의 양방향(Bidirectional) 사전 학습 언어 모델로, 문맥을 이해하는 데 탁월한 성능을 보입니다.
- 논문: https://arxiv.org/abs/1810.04805
- 개발: Google AI
- 목표: 문맥을 더 깊이 있게 이해하는 사전학습 언어 모델
🔧 핵심 아이디어 요약
1. 양방향 문맥(Bidirectional Context) 학습
기존 모델(RNN, GPT 등)은 왼쪽 → 오른쪽 또는 오른쪽 → 왼쪽으로 문장을 처리했지만,
BERT는 양방향으로 문맥을 동시에 학습합니다.
예:문장: "나는 [MASK]를 좋아해" → 왼쪽 문맥 "나는" + 오른쪽 문맥 "를 좋아해" → "축구" 추론 가능2. 사전학습 (Pre-training) + 미세조정 (Fine-tuning)
- Pre-training: 대규모 텍스트 코퍼스(예: Wikipedia)로 일반적인 언어 이해를 학습
- Fine-tuning: 특정 작업(예: 감정 분석, QA, NER 등)에 맞게 추가 학습
🏗️ BERT의 구조
항목 BERT Base BERT Large Layers (Transformer blocks) 12 24 Hidden size 768 1024 Attention heads 12 16 Parameters 110M 340M BERT는 Transformer의 Encoder 부분만 사용합니다.
🧪 Pre-training 방식
BERT는 두 가지 사전 학습 태스크를 사용합니다.
1. Masked Language Modeling (MLM)- 입력 문장에서 무작위로 15%의 단어를
[MASK]로 가리고, 이를 예측입력: 나는 [MASK]를 좋아한다 → 출력: 축구
2. Next Sentence Prediction (NSP)
- 문장 A, 문장 B를 주고, B가 A 다음 문장인지 맞추는 이진 분류
입력: [CLS] 나는 학교에 갔다. [SEP] 수업을 들었다. [SEP] → label: IsNext
✅ 장점
- 문맥 이해 능력 탁월 (양방향 학습 덕분)
- Transfer Learning 가능 (사전학습 → 다양한 작업에 재사용)
- 다양한 NLP 작업에서 SOTA 달성
❌ 단점
- 매우 크고 무거움 (실시간 응답에는 느림)
- 학습 비용이 매우 큼 (TPU, GPU 필수)
- 추론 속도 느림 → DistilBERT 같은 경량화 모델 필요
💡 BERT 사용 예시 (Hugging Face Transformers)
from transformers import BertTokenizer, BertForMaskedLM import torch tokenizer = BertTokenizer.from_pretrained("bert-base-uncased") model = BertForMaskedLM.from_pretrained("bert-base-uncased") text = "I love [MASK] models." inputs = tokenizer(text, return_tensors="pt") outputs = model(**inputs) predicted_index = torch.argmax(outputs.logits[0, 2]).item() predicted_token = tokenizer.convert_ids_to_tokens(predicted_index) print(predicted_token) # 예: "language"🌐 실제 활용 분야
- 감정 분석 (Sentiment Analysis)
- 질문 응답 시스템 (Question Answering)
- 개체명 인식 (NER)
- 문서 분류, 요약
- 검색 질의 개선 (Google 검색에도 사용됨)
📚 참고 자료
- 논문: https://arxiv.org/abs/1810.04805
- 코드: Hugging Face BERT Model
- 튜토리얼: Google BERT 설명 블로그
🧠 DIstillBERT 한국어 모델
🇰🇷 대표적인 DistilBERT 한국어 모델
1. monologg/distilkobert
- 설명: SKT에서 만든 KoBERT를 기반으로 Hugging Face 사용자
monologg가 Knowledge Distillation을 적용하여 만든 경량화 KoBERT - Hugging Face 링크: https://huggingface.co/monologg/distilkobert
- 기반 모델: SKT KoBERT
- 특징:
- 한국어에 특화된 토크나이저 (
Mecab,SentencePiece등) - 파라미터 수 감소로 추론 속도 개선
- 한국어에 특화된 토크나이저 (
2. distil-kobert-nsmc (Fine-tuned)
- 설명:
monologg/distilkobert를 감정 분석(Naver 영화 리뷰 - NSMC) 태스크에 fine-tuning한 버전 - Hugging Face 링크: https://huggingface.co/beomi/distil-koELECTRA-base-nsmc
3. ELECTRA 기반 경량화 모델 (참고용)
- KoELECTRA의 Distilled 버전도 많이 활용됩니다. BERT 계열이지만 구조는 다름.
- 예:
monologg/koelectra-small-discriminator
🧪 사용 예시 (Python 코드)
from transformers import BertTokenizer, BertForSequenceClassification from transformers import pipeline # 모델과 토크나이저 로드 model_name = "monologg/distilkobert" tokenizer = BertTokenizer.from_pretrained(model_name) model = BertForSequenceClassification.from_pretrained(model_name) # 파이프라인 활용 (예: 감정 분석) nlp = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer) result = nlp("이 영화 정말 재미있었어요!") print(result)🎯 DistilKoBERT를 사용하면 좋은 이유
항목 KoBERT DistilKoBERT 속도 느림 ✅ 빠름 (30~50% 향상) 크기 큼 ✅ 작음 정확도 높음 거의 동일 (~98%) 사용처 서버 ✅ 모바일, 임베디드도 가능 🔗 참고 자료
- DistilKoBERT 모델 페이지: https://huggingface.co/monologg/distilkobert
- Distillation 소개: Google Blog - Distillation
- NSMC 감정 분석 데이터셋: ‣
-
LLM
💡여기서 말하는 LLM은 데이터를 분석하고 분석한 내용을 기반으로 문맥을 이해하여 몇 가지 체크할 질문을 생성하는 모델을 LLM이라고 하겠습니다.
GPT API를 사용하면 좋지만 Money가 문제죠..
그래서 다른 방법을 써보기로 했습니다.✅ GPT의 질문 생성 능력 = “자연어 생성(NLG) 능력”
GPT는 "문장을 이해하고 → 다음 문장을 생성하는" 과정을 반복하는 거대한 트랜스포머 기반 언어 모델입니다.
이걸 직접 만들기 위해서는 다음 조건이 필요합니다:✅ 1. 모델 선택: 어떤 구조를 써야 하나?
모델 이름 구조 특징 GPT (Transformer Decoder) Decoder-only 문장 생성에 최적 BART Encoder + Decoder 문장 요약, 생성 등 모두에 강함 T5 Text-to-Text 어떤 NLP 작업도 텍스트 입력-출력으로 처리 ➡️ 직접 질문 생성기를 만들고 싶다면
T5또는BART가 GPT보다 좋습니다.
이들은 이미 사전 학습된 모델로 제공되며, 파인튜닝(fine-tuning)으로 질문 생성에 맞게 조정할 수 있습니다.✅ 2. 데이터셋: 학습시킬 질문-답변 예제 필요
질문 생성 모델을 학습하려면 다음과 같은 페어 데이터가 필요합니다:입력 (문장) 출력 (질문) 택배가 반송되어 클릭하라는 메시지를 받았습니다 이 링크를 클릭하셨나요? 다음 주소에서 로그인하라고 하네요 해당 사이트에 로그인 시도하셨나요? ➡️ 보통 QA pair dataset이나 conversational dataset을 가공해 사용합니다.
대표적으로:
- SQuAD
- https://quac.ai/
- MS MARCO
✅ 3. 학습 방식: 파인튜닝 or 프롬프트 기반 활용
- 🔧 파인튜닝 (Fine-tuning):
- 직접 질문 데이터를 수천~수만 개 모아 모델에 학습
- 예: T5-small을 2,000개 데이터로 fine-tune
- 🧠 프롬프트 기반 (prompt tuning):
- 이미 훈련된 모델을 이용해서
"문장: {문장 내용} → 질문:"형태로 입력 - GPT, BART 등에서 매우 잘 작동함
- 이미 훈련된 모델을 이용해서
✅ 4. 자원: 학습에 필요한 환경
모델 메모리 연산 시간 추천 T5-small 약 2GB VRAM 빠름 노트북 OK BART-base 약 4-6GB 중간 GPU 권장 GPT-style (GPT-2 이상) 10GB 이상 느림 고성능 GPU 필요 ✅ 현실적 대안: 미리 학습된 T5/BART 활용
직접 GPT를 만들기보다, 아래 방법을 추천드립니다:✅ 방법 1. Hugging Face에서 T5/BART 불러와서 사용
from transformers import pipeline generator = pipeline("text2text-generation", model="t5-small") input_text = "generate question: 택배 반송 메시지를 받았습니다. 링크가 포함되어 있습니다." result = generator(input_text) print(result)✅ 방법 2. FastAPI + 이 모델로 REST API 만들기
→ SaaS 형태 질문 생성기로 사용 가능✅ 정리: GPT 질문 생성기를 직접 만들 수 있는가?
항목 가능 여부 설명 완전히 처음부터 GPT 구조 만들기 ✅ 가능하나 매우 어렵고 리소스 큼 미리 훈련된 모델로 질문 생성기 구현 ✅ 매우 현실적이고 강력한 방법 GPT API 없이 완전 독립형 질문 생성기 만들기 ✅ T5, BART 등으로 충분히 가능 🧠 T5 모델
🎯 목적
- 스미싱 의심 문장을 입력하면
👉 해당 문장에 대한 Yes/No 형태의 질문을 자동으로 생성합니다.
✅ 전제 조건
- Python 설치됨
transformers라이브러리 설치됨 (pip install transformers)
🧠 예시 입력 & 출력
입력 문장:"택배가 반송되어 확인하려면 링크를 클릭하라고 합니다"생성 질문 (예):
"해당 링크를 클릭하셨나요?"✅ T5 기반 질문 생성기 코드
from transformers import T5Tokenizer, T5ForConditionalGeneration # 모델 및 토크나이저 불러오기 (HuggingFace에서 T5-small 사용) tokenizer = T5Tokenizer.from_pretrained("t5-small") model = T5ForConditionalGeneration.from_pretrained("t5-small") def generate_question(input_text): # 입력 문장을 질문 생성 프롬프트로 변환 prompt = f"generate question: {input_text}" # 입력 인코딩 input_ids = tokenizer.encode(prompt, return_tensors="pt") # 질문 생성 output_ids = model.generate(input_ids, max_length=50, num_beams=4, early_stopping=True) # 출력 디코딩 question = tokenizer.decode(output_ids[0], skip_special_tokens=True) return question # 사용 예시 test_text = "택배가 반송되었고, 링크를 클릭하라고 나왔어요." generated_question = generate_question(test_text) print("📥 입력:", test_text) print("❓ 생성된 질문:", generated_question)✅ 실행 결과 예시
📥 입력: 택배가 반송되었고, 링크를 클릭하라고 나왔어요. ❓ 생성된 질문: Did you click the link in the message?✅ 한글 질문 생성이 안된다면?
T5-small은 영어 기반 모델이기 때문에,
한글 질문을 원한다면 다음 두 가지 옵션이 있습니다:✅ 옵션 1:
KcT5,KoT5,KoBART사용from transformers import PreTrainedTokenizerFast, T5ForConditionalGeneration tokenizer = PreTrainedTokenizerFast.from_pretrained("digit82/kc-t5-base") # 한글 전용 tokenizer model = T5ForConditionalGeneration.from_pretrained("digit82/kc-t5-base") def generate_korean_question(input_text): prompt = f"질문 생성: {input_text}" input_ids = tokenizer.encode(prompt, return_tensors="pt") output_ids = model.generate(input_ids, max_length=50, num_beams=4, early_stopping=True) return tokenizer.decode(output_ids[0], skip_special_tokens=True)➡️ 이걸 쓰면
한글로 자연스러운 질문 생성이 가능합니다.✅ 다음 단계로 할 수 있는 것들
할 일 설명 ✅ 사용자 응답 (Yes/No) 입력 점수화 로직 추가 가능 ✅ 여러 개 질문 생성 num_return_sequences=3설정✅ API로 배포 FastAPI 등으로 REST API 만들기 ✅ 훈련 데이터로 Fine-tuning 질문 스타일을 사용자 맞춤으로 바꾸기
