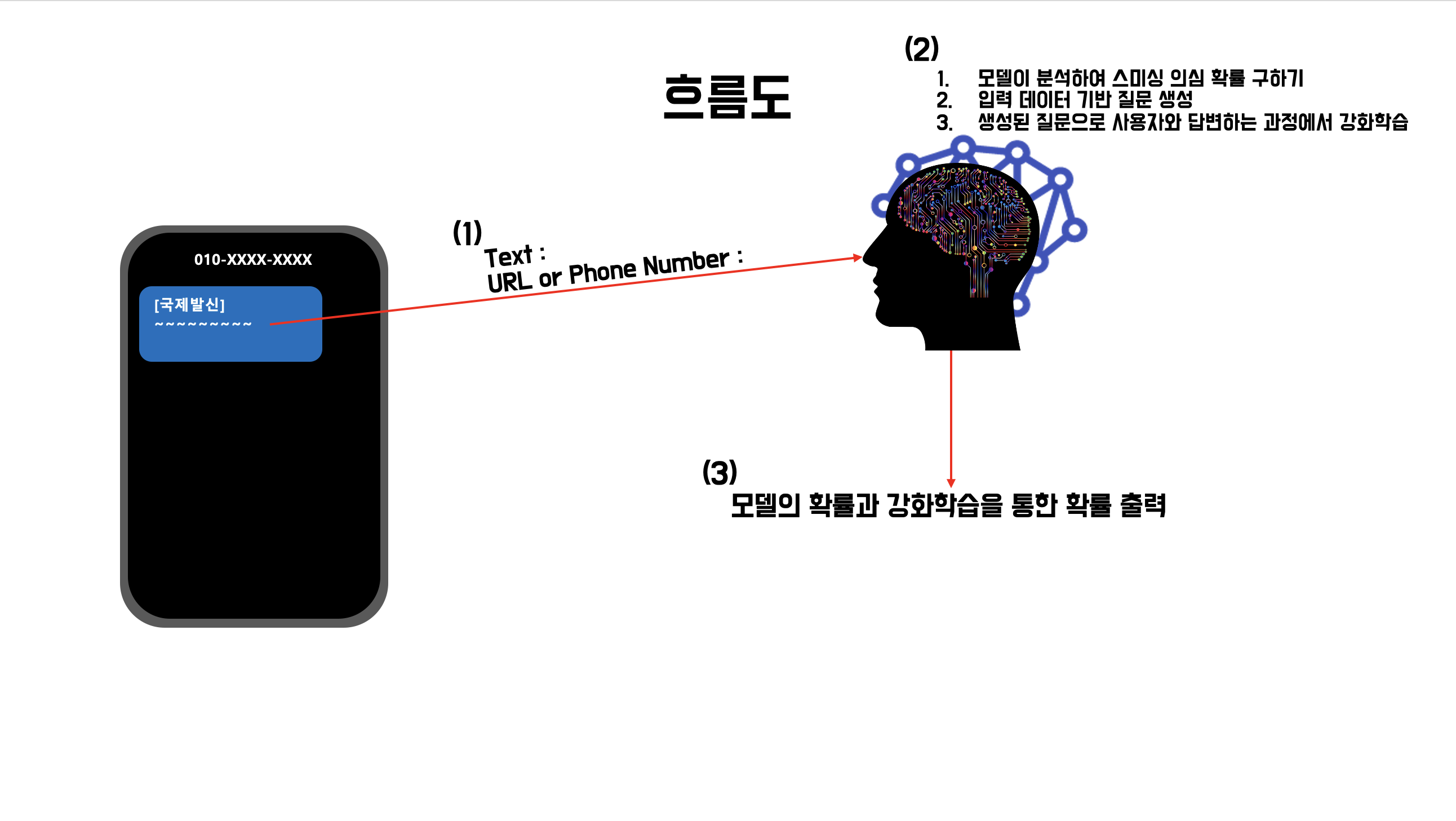
(1)
- Text
- 설명 Text 필드에는 스미싱이 의심되는 문자 메세지를 받습니다. (최종 코드는 아니기에 많이 달라질 수 있다는 점)
Text = str(input("의심 메세지 : ")) keyword = [] keyword.append(Text.split(" "))input 의심 메세지 : [국제발신] Hello my mane is KIM. Please click this link? http://guide/ output ['[국제발신]', 'Hello', 'my', 'mane', 'is', 'KIM.', 'Please', 'click', 'this', 'link?', 'http://guide/']
- 설명 Text 필드에는 스미싱이 의심되는 문자 메세지를 받습니다. (최종 코드는 아니기에 많이 달라질 수 있다는 점)
- URL or Phone Number
- 설명 이 필드는 직접적인 확률을 예측하는데 쓰이지 않고 질문 생성할 때 쓰기 위해 입력을 받는 필드 입니다. (최종 코드는 아니기에 많이 달라질 수 있다는 점)
URL_OR_PhoneNumber = str(input(" 추가 정보 (URL OR PhoneNumber) : ") DataType = "" if "://" in URL_OR_PhoneNumber: DataType = "URL" else: DataType = "PN"
- 설명 이 필드는 직접적인 확률을 예측하는데 쓰이지 않고 질문 생성할 때 쓰기 위해 입력을 받는 필드 입니다. (최종 코드는 아니기에 많이 달라질 수 있다는 점)
(2)
- 모델이 스미싱 의심 확률 구하기 이 의심 확률을 구할 때 사용할 모델은 DIstilkoBERT 모델을 사용하기로 했습니다.
아무래도 한국어로 많이 오기 때문에 존재하나 찾아봤더니 모델이 있어서 BERT의 경량화 모델이면서 한국어로 분석이 가능한 모델인 DIstilkoBERT 모델을 선정하게 되었습니다.
솔직히 말하면 이게 도저히 공부를 할 시간이 없어서 현재로선 GPT에 의존해서 코드를 생성한거라 뭐라 설명을 못하겠습니다. [Using Stack] : Pytorch, Distilkobert Modelfrom transformers import BertTokenizer, BertForSequenceClassification import torch import torch.nn.functional as F # 모델과 토크나이저 불러오기 model_name = "monologg/distilkobert" tokenizer = BertTokenizer.from_pretrained(model_name) model = BertForSequenceClassification.from_pretrained(model_name, num_labels=2) # GPU 사용 가능 시 설정 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model.to(device) model.eval() # 예측할 문장 text = str(input("의심 메세지 : ")) # 토큰화 inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=128) inputs = {k: v.to(device) for k, v in inputs.items()} # 추론 with torch.no_grad(): outputs = model(**inputs) logits = outputs.logits probs = F.softmax(logits, dim=1) # 스미싱 확률 출력 smishing_prob = probs[0][1].item() * 100 print(f"스미싱 의심 확률: {smishing_prob:.2f}%") - 입력 데이터 기반 질문 생성 GPT API를 사용하게 되면 Token에 따라 비용이 발생해서.. 어쩔 수 없이 T5 모델을 사용하기로 결정했습니다.
T5-small 모델도 고려해봤지만 한국어로 하면 성능이 떨어져 보통은 영어 텍스트 → 영어 질문이 생성으로 사용합니다…from transformers import T5Tokenizer, T5ForConditionalGeneration import re # ✅ T5 모델 및 토크나이저 불러오기 model_name = "KETI-AIR/ke-t5-base" # 한국어 T5 모델 tokenizer = T5Tokenizer.from_pretrained(model_name) model = T5ForConditionalGeneration.from_pretrained(model_name) model.eval() # ✅ URL 마스킹 함수 def mask_url(text): return re.sub(r'https?://\S+|www\.\S+', '[URL]', text) # ✅ 질문 생성 함수 def generate_question(input_text, max_length=64): prompt = f"질문 생성: {input_text}" # 모델이 학습된 prefix (필요시 조정) inputs = tokenizer.encode(prompt, return_tensors="pt", truncation=True) outputs = model.generate( inputs, max_length=max_length, num_beams=5, early_stopping=True ) return tokenizer.decode(outputs[0], skip_special_tokens=True) # ✅ 사용자 입력 받기 raw_text = input("의심 메시지를 입력하세요: ") # ✅ URL 마스킹 적용 clean_text = mask_url(raw_text) # ✅ 질문 생성 question = generate_question(clean_text) # ✅ 출력 print(f"\n📌 입력 메시지: {raw_text}") print(f"📌 URL 마스킹 후: {clean_text}") print(f"📌 생성된 질문: {question}") - 생성된 질문으로 사용자와 답변하면서 강화학습 반영 위에서 T5 모델로 생성된 질문에 답변을 하면 그 답변을 분석하여 중요도를 분석하게 됩니다.
지금은 질문을 1개만 가지고 하겠지만 나중에는 여러개의 질문을 생성해 답변의 각각의 점수에 대한 평군을 사용해보겠습니다.의심 메시지 + URL ↓ [ T5 모델 ] 질문 자동 생성 ↓ 질문 출력 → 사용자 답변 입력 ↓ [ 답변 평가 모델 또는 규칙 기반 시스템 ] ↓ 분석력 점수 추출 (예: 0~1) ↓ [ 향후 강화학습 ] - 점수를 보상으로 활용 - GPT 또는 정책 모델 업데이트 가능from transformers import T5Tokenizer, T5ForConditionalGeneration import re # 1. 모델 로딩 model_name = "KETI-AIR/ke-t5-base" tokenizer = T5Tokenizer.from_pretrained(model_name) model = T5ForConditionalGeneration.from_pretrained(model_name) model.eval() # 2. URL 마스킹 def mask_url(text): return re.sub(r'https?://\S+|www\.\S+', '[URL]', text) # 3. 질문 생성 def generate_question(text): prompt = f"질문 생성: {text}" inputs = tokenizer.encode(prompt, return_tensors="pt", truncation=True) outputs = model.generate(inputs, max_length=64, num_beams=5, early_stopping=True) return tokenizer.decode(outputs[0], skip_special_tokens=True) # 4. 사용자 답변 평가 함수 (규칙 기반 예시) def evaluate_answer(answer): # 분석력 기준 예시: '피싱', '위험', '로그인', '개인정보' 등 포함 여부 keywords = ['피싱', '위험', '로그인', '개인정보', '금융', '사기', '계좌'] score = sum(1 for kw in keywords if kw in answer.lower()) normalized_score = score / len(keywords) return round(normalized_score, 2) # === 실행 === # 입력 메시지 받기 raw_text = input("📩 의심 메시지를 입력하세요: ") clean_text = mask_url(raw_text) # 질문 생성 question = generate_question(clean_text) print(f"\n🤖 생성된 질문: {question}") # 사용자 답변 받기 user_answer = input("🧠 당신의 답변: ") # 답변 평가 score = evaluate_answer(user_answer) print(f"\n📊 분석력 점수 (0~1): {score}")
(3)
- 모델의 확률과 강화학습을 통한 확률 출력 터미널에서 보여주는 것보다 명색에 프로젝트인데 간단하게 웹을 만들어서 보여줘야 될거 갔아서 Streamlit을 사용하여 만들어보겠습니다.
import streamlit as st from transformers import BertTokenizer, BertForSequenceClassification, T5Tokenizer, T5ForConditionalGeneration import torch import torch.nn.functional as F import re # 모델 로딩 @st.cache_resource def load_models(): bert_model = BertForSequenceClassification.from_pretrained("monologg/distilkobert", num_labels=2) bert_tokenizer = BertTokenizer.from_pretrained("monologg/distilkobert") t5_model = T5ForConditionalGeneration.from_pretrained("KETI-AIR/ke-t5-base") t5_tokenizer = T5Tokenizer.from_pretrained("KETI-AIR/ke-t5-base") return bert_model.eval(), bert_tokenizer, t5_model.eval(), t5_tokenizer bert_model, bert_tokenizer, t5_model, t5_tokenizer = load_models() # 입력 받기 text = st.text_area("📨 스미싱 의심 메시지 입력") if text: # BERT 확률 계산 inputs = bert_tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=128) with torch.no_grad(): outputs = bert_model(**inputs) probs = F.softmax(outputs.logits, dim=1) smishing_prob = probs[0][1].item() st.markdown(f"🔍 **AI 예측 스미싱 확률**: `{smishing_prob*100:.2f}%`") # URL 마스킹 def mask_url(t): return re.sub(r'https?://\S+|www\.\S+', '[URL]', t) clean_text = mask_url(text) # 질문 생성 questions = [] for i in range(5): # 최대 5개 질문 생성 prompt = f"질문 생성: {clean_text}" inputs = t5_tokenizer(prompt, return_tensors="pt") outputs = t5_model.generate(inputs['input_ids'], max_length=64, num_beams=5, early_stopping=True) question = t5_tokenizer.decode(outputs[0], skip_special_tokens=True) questions.append(question) # 사용자 답변 및 점수 입력 user_scores = [] st.markdown("## 📋 사용자 분석 질문") for i, q in enumerate(questions): st.markdown(f"**Q{i+1}. {q}**") answer = st.text_input(f"✍️ A{i+1}:", key=f"answer_{i}") score = st.slider(f"🧠 이 답변의 분석력 점수 (-0.5 ~ +0.5)", min_value=-0.5, max_value=0.5, step=0.1, key=f"score_{i}") user_scores.append(score) # 확률 보정 def adjust_probability(base_prob, scores): return min(max(base_prob + sum(scores), 0.0), 1.0) final_prob = adjust_probability(smishing_prob, user_scores) st.markdown(f"🎯 **사용자 분석 반영 확률**: `{final_prob*100:.2f}%`")

SoC:) SoC:)