Segmentation
Pixelwise classification
1. Fully Convolution Network(FCN)
1) FCN?
- 대표적인 Segmentation
- feature extraction을 위해 VGG 네트워크를 백본으로 사용
- VGG네이트워크의 Fully Connected Layer(nn.Linear)를 Convolution으로 대체
- Transposed Convolution(=Deconvolution, Upsampling)으로 Pixel Wise prediction을 수행
2) Backbone 사용
- 기존 VGG를 백본 네트워크로 사용하여 pre-trained 모델을 사용할 수 있다.
- 이미 많은 image를 학습한 pre-trained 모델을 사용해 연산 감소시킬 수 있음
- VGG의 FC Layer를 Convolution으로 변경해 사용함(nn.Linear -> nn.Conv2d)
3) Convolution Layer vs Fully Connected Layer
위치 정보
- FC Layer는 input으로 사용하기 위해 flatten을 수행하는데 이때 위치 정보를 해침
- Convolution Layer는 channel wise 연산으로 위치 정보를 해치지 않은 채로 특징을 추출할 수 있음
input channel
- FC Layer는 input으로 사용되는 이미지 크기가 모두 같아야함
flatten ->nn.Linear(input_channel * width * height) - Convolution Layer는 이미지 크기에 영향을 받지 않음
nn.Conv2d(input_channel, output_channel, ...)
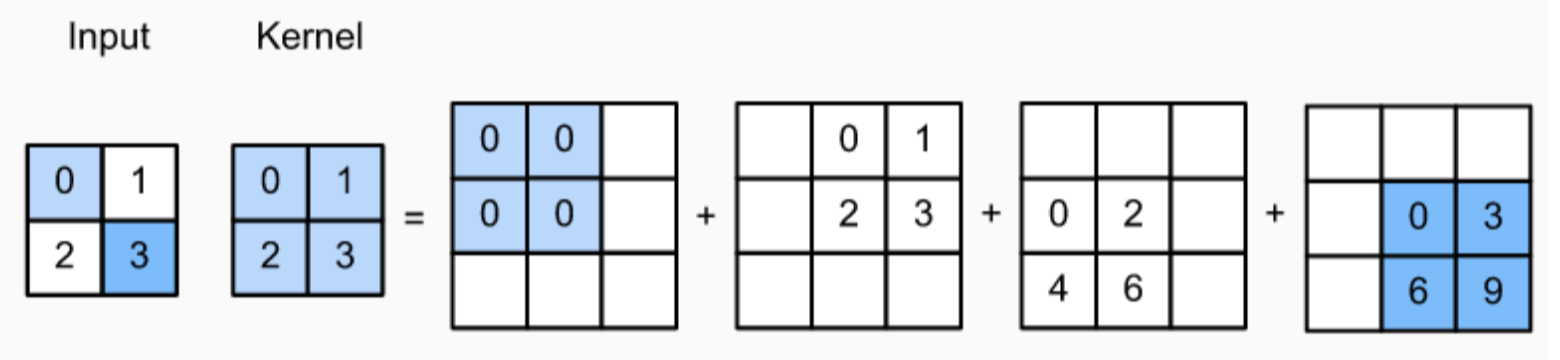
4) Transposed Convolution
- VGG backbone을 통과한 input 이미지의 크기는 5번의 max poolingdp 의해 1/32로 감소
ex) 224 -> 7 - 최종 output은 224x224 (pixel-wise predict)이어야함
- Transposed Convolution 연산으로 이미지 크기 복원
input의 width, height 보다 큰 kernel size를 사용
핵심은 Transposed Convolution 에서 사용되는 kernel도 학습이 가능한 파라미터
5) Architecture
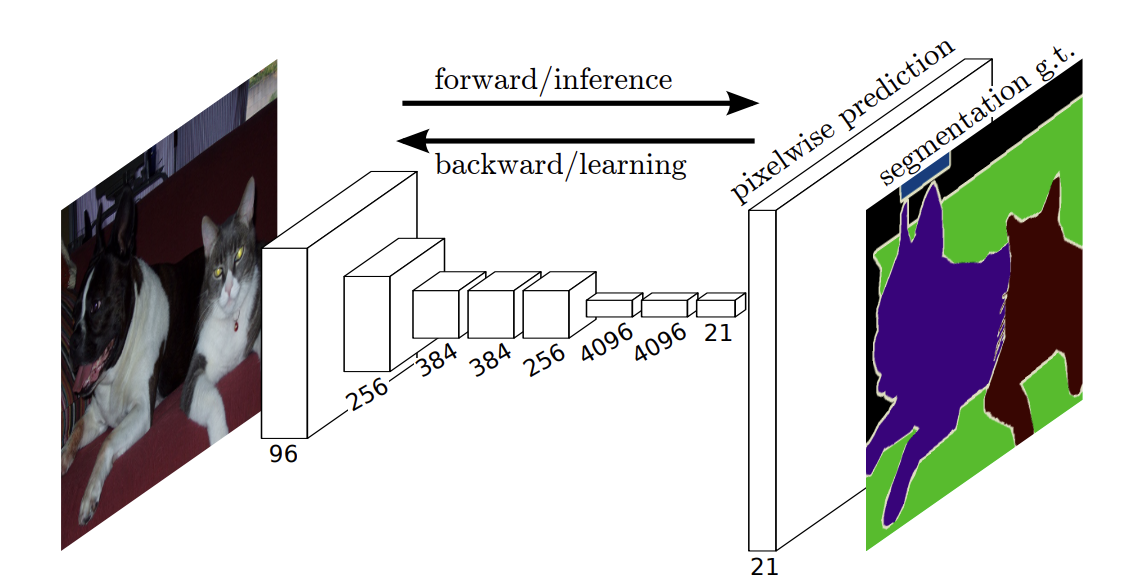
- 기존 VGG과는 다르게 Fully Connected Layer를 Convolution Layer로 변경

코드
- Conv는 Convolution layer와 ReLU함수가 묶여있음 (CBR) 3x3 convolution layer
def CBR(in_channels, out_channels, kernel_size=3, stride=1, padding=1):
return nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding),
nn.ReLU(inplace=True))- conv1(block)은 2개의 CBR과 MaxPooling
#conv1
self.conv1_1 = CBR(3, 64, 3, 1, 1) # size 변동 없음
self.conv1_2 = CBR(64, 64, 3, 1, 1)
self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True) # 사이즈 1/2- conv2(block)
self.conv2_1 = CBR(64, 128, 3, 1, 1)
self.conv2_2 = CBR(128, 128, 3, 1, 1)
self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True) # 사이즈 1/4- conv3(block)
self.conv3_1 = CBR(128, 256, 3, 1, 1)
self.conv3_2 = CBR(256, 256, 3, 1, 1)
self.conv3_3 = CBR(256, 256, 3, 1, 1)
self.pool3 = nn.MaxPool2d(2, stride=2, ceil_mode=True) # 사이즈 1/8- conv4(block)
self.conv4_1 = CBR(256, 512, 3, 1, 1)
self.conv4_2 = CBR(512, 512, 3, 1, 1)
self.conv4_3 = CBR(512, 512, 3, 1, 1)
self.pool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True) # 사이즈 1/16- conv5(blcok)
self.conv5_1 = CBR(512, 512, 3, 1, 1)
self.conv5_2 = CBR(512, 512, 3, 1, 1)
self.conv5_3 = CBR(512, 512, 3, 1, 1)
self.pool5 = nn.MaxPool2d(2, stride=2, ceil_mode=True) # 사이즈 1/32- FC6 (원래 VGG 모델에서는 7x7 Convolution이지만 1x1로 개념 학습)
self.fc6 = CBR(512, 4096, 1, 1, 0) # Linear -> Conv
self.drop6 = nn.Dropout2d()- FC7
self.fc7 = CBR(4096, 4096, 1, 1, 0)
self.drop7 = nn.Dropout2d()- Score (pixel 단위로 prediction)
self.score_fr = nn.Conv2d(4096, num_classes, 1, 1, 0)- Up Score (Deconvolution을 사용해서 Up Score)
5번의 Max Pooling으로 인해 원본 사이즈가 32배(2^5)만큼 줄어든 상태이므로 다시 32배 키우기 위해서 Transpose Convolution 사용
self.upscore32 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=64, stride=32, padding=16) # 32배 크기 키움6) FCN에서 성능을 향상 시키기 위한 방법 (FCN-16s, FCN-8s)
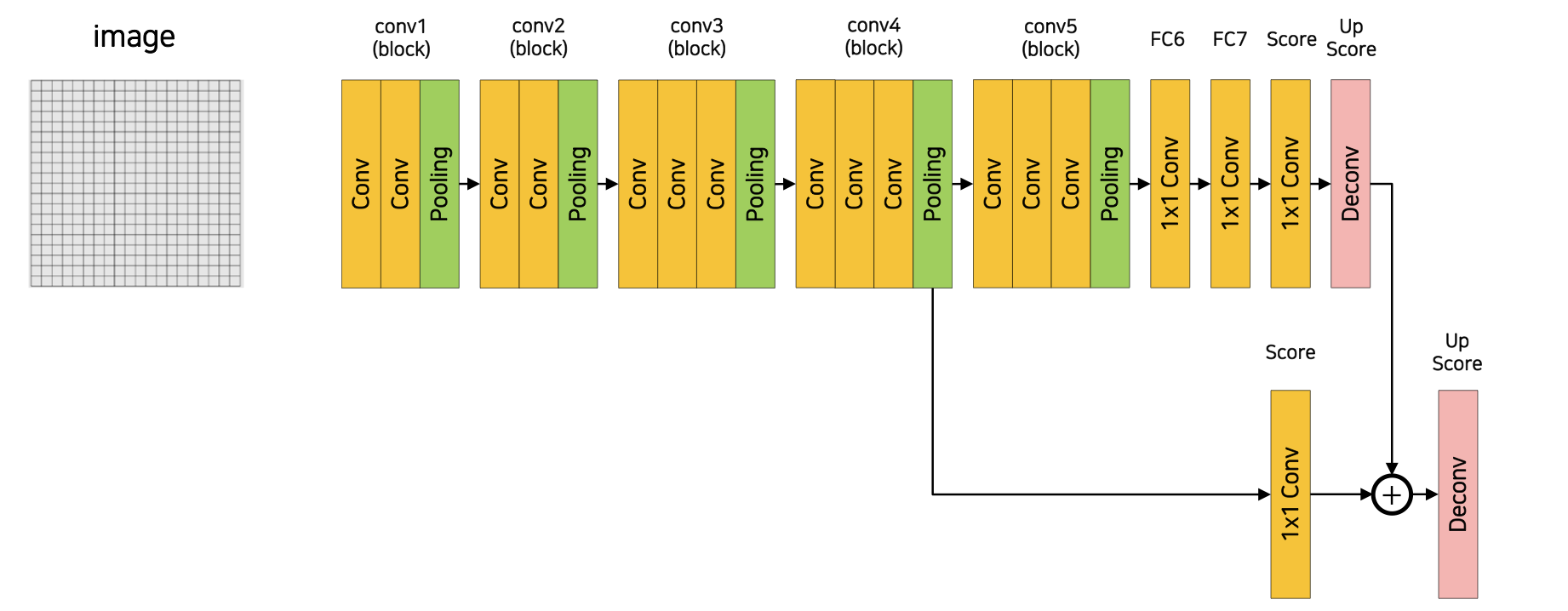
FCN-16s
-
네트워크 구조에서 block이 넘어갈 때 MaxPooling을 하면 정보를 잃을 수 밖에 없음
-
손실이 발생하기 전 매트릭스를 가져와 summation 해줌으로써 잃어버린 정보를 어느정도 복원
-
또한 Upsampled Size를 줄여주기 때문에 좀 더 효율적인 이미지 복원이 가능 ex) 32배 -> 16배
-
MaxPooling을 conv4까지 적용했을 때 크기는 1/16
-
conv4의 결과를 가져와Up Score의 결과와 summation을 해주는 skip connection 구성 -
conv4의 결과를 가져와Up Score의 결과의 channel을 맞춰주기 위해 1x1 convolution layer를 사용 -
Up score에서 32배가 아닌 16배만 크기 복원
-
처리된 두 결과를 합쳐 최종적으로 크기 복원
코드
- Score pool4
self.score_pool4_fr = nn.Conv2d(512, num_classes, kernel_size=1, stride=1, padding=0) # output channel을 Up Score와 동일하게 적용- Up Socre2
self.upscore2 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, padding=1)- Sum
def forward(self, x):
h = x
...
h = upscore2 + score_pool4c # 잃어버리기 전의 정보를 어느정도 복원- Up Score (최종 Deconv, stride 16을 사용하기 때문에 FCN-16s)
self.upscore16 = nn.ConvTranspose2d(num_classes, num_classes, kernsel_size=32, stride=16, padding=8) FCN-8s
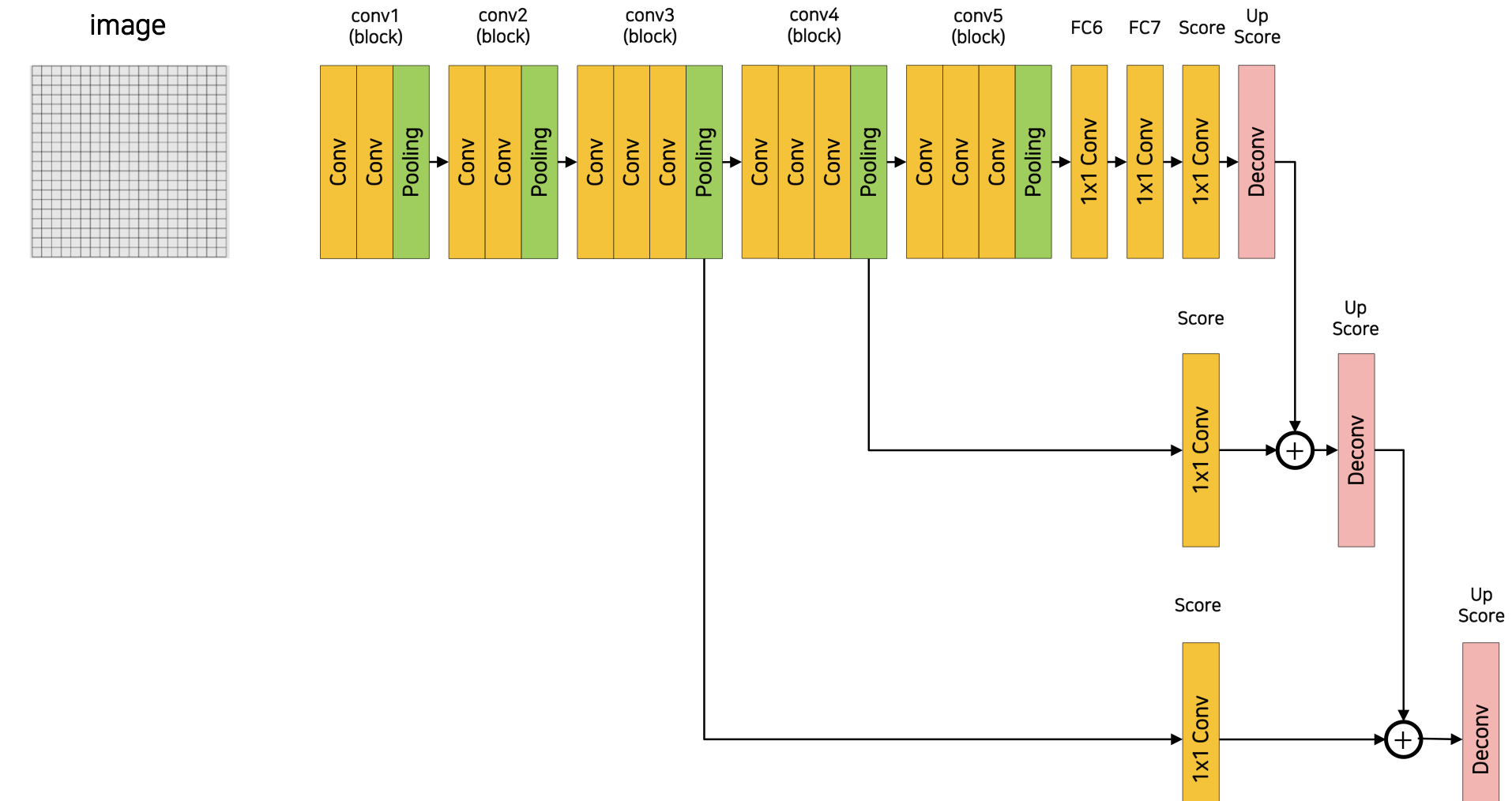
-
FCN-16s 의 결과에 conv3의 결과 (1/8 크기)를 summation
-
최종 Deconvolution에서 사용하는 stride가 8
-
Score pool3
마찬가지로 FCN-16s의 결과와 channel 숫자를 맞춰주기 위한 1x1 Convolution layer
self.score_pool3_fr = nn.Conv2d(256, num_classes, kernel_size=1, stride=1, padding=0)- Up Score2
원본 이미지 대비 1/8 크기인 conv3의 결과와 FCN-16s의 크기를 맞춰줌
self.upscore2_pool4 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, padding=1) # size * 2- Sum 2
def forward(self, x):
h = self.conv3_1(h)
h = self.conv3_2(h)
h = self.conv3_3(h)
pool3 = h #1/8
...
h = upscore_pool4c + score_pool3c- Up Score3
최종적으로 1/8 크기의 이미지를 8배 키우기 위해 Transposed Convolution layer 사용
self.upscore8 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=16, stride=8, padding=4)7) FCN-32s, FCN-16s, FCN-8s
- 32-> 16 -> 8로 갈수록 평가지표인 mIOU 상승
- 좀더 디테일한 부분까지 관찰 가능한 모델 완성
8) 핵심 정리
- FCN은 VGG같은 Backbone network를 사용하여 pre-trained 모델을 사용할 수 있다.
- Fully connected layer를 Convolution Layer로 교체하여 임의의 이미지 크기를 input할 수 있다.
- 기존 이미지 분류를 위한 output이 아닌 Transposed Convolution을 사용해 원본 이미지 크기로 복원시켜 pixelwise prediction이 가능하다.
2. Implementation
3. Reference
https://towardsdatascience.com/transposed-convolution-demystified-84ca81b4baba (Transposed Convolution)
https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Long_Fully_Convolutional_Networks_2015_CVPR_paper.pdf (Fully Convolutional Networks for Semantic Segmentation)
