Segmentation
FCN의 한계와 Encoder, Decoder 구조로 극복한 모델들
1. FCN의 한계
1) 객체의 크기가 크거나 작은 경우 예측을 잘 못함

- 큰 객체의 경우 지역적인 정보만으로 예측해 전체적인 모습을 예측하지 못함
- 같은 객체여도 다르게 labeling
- 작은 Object가 무시되는 경우가 있음
2) 디테일한 모습이 사라지는 문제
- Deconvolution의 절차가 너무 간단해 경계를 학습하기에는 무리가 있음 (ex FCN-32s, 16s, 8s도 여전히 단순)
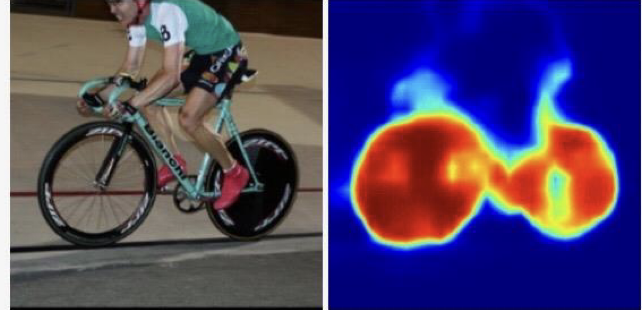
2. DeconvNet
1) DeconvNet?
- Deconder와 Encoder를 대칭으로 만든 형태
- VGG16을 사용해 13개의 층
- ReLU와 Pooling이 Convolution 사이에서 이루어짐
- Deconvolution은 Unpooling, Deconvolution, ReLU로 이루어짐
2) Encoder, Decoder

3) Unpooling vs. Deconvolution
- DeconvNet의 Decoder 부분의 1개 block은 UnPooling과 Transposed Convolution(Deconvolution)이 반복적으로 이루어진 형태
- Unpooling은 디테일한 경계를 포착하고 Deconvolution은 전반적인 모습을 포착한다.
Unpooling
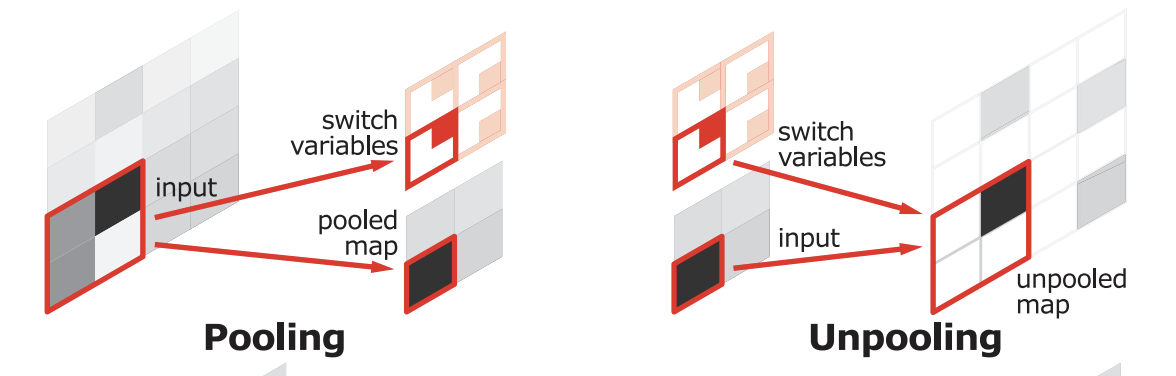
- Pooling을 통해 값을 추출(Max Pooling인 경우 가장 큰 값을 추출)
- pooled map에서는 해당 input 데이터에서 뽑힌 Pixcel의 위치 정보를 잃어버림
- Unpooling에서는 input에서 뽑힌 pixel의 위치 정보를 기억하고 해당 영역의 위치를 복원함 (나머지는 0으로 처리)
- 학습이 필요 없기 때문에 속도가 빠름
- sparse한 activation map을 가지기 때문에 (dense하지 않음) 이를 채워 줄 필요가 있는데 이 역할을 Transposed Convolution이 수행
Deconvolution (Transposed Convolution)
https://velog.io/@choihj94/Boostcampers-TIL-13#4-transposed-convolution
- Deconvolution layer를 통해서 input의 모양을 복원함
- 순차적인 층으로 다양한 수준의 모양 잡음(얕은 층: 전반적인 모습, 깊은 층: 구체적인 모습)
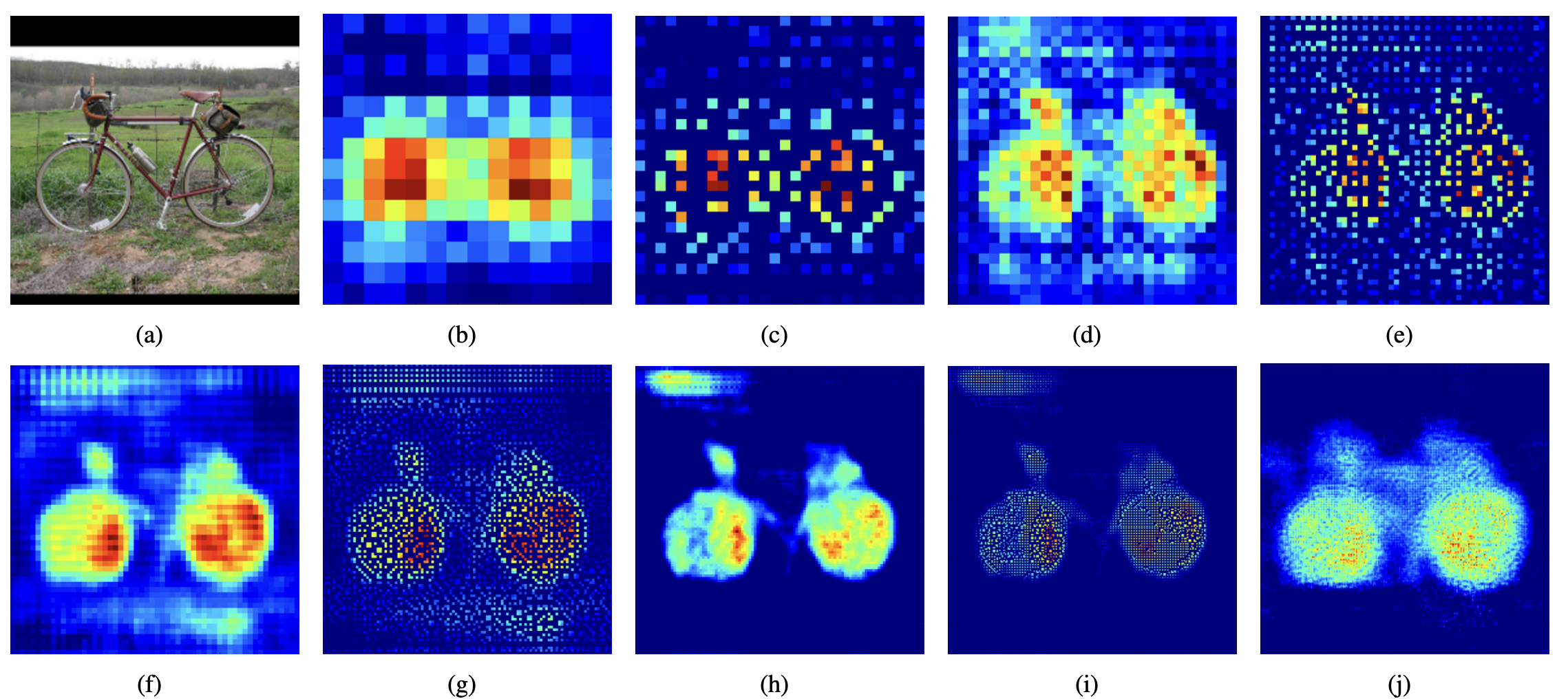
- (c), (e), (g), (i)는 Unpooling, "example-specific"(자세한 구조)
- (b), (d), (f), (h), (j)는 Deconvolution, "class-specific"(위의 구조에서 빈 부분을 채워넣음)
- 둘을 병행해서 사용해 activation map이 더 디테일해질 수 있음
4) Architecture
- Conv는 Convolution layer와 BatchNorm, ReLU함수가 묶여있음 (CBR)
def CBR(in_channels, out_channels, kernel_size=3, stride=1, padding=1):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)- Deconvolution Network는 Transposed Convolution과 BatchNorm, ReLU로 구성(DCB)
def DCB(in_channels, out_channels, kernel_size=3, stride=1, padding=1):
return nn.Sequential(
nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride, padding),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)- conv1
self.conv1_1 = CBR(3, 64, 3, 1, 1)
self.conv1_2 = CBR(64, 64, 3, 1, 1)
self.pool1 = nn.MaxPool2d(kernel_szie=2, stride=2, ceil_mode=True, return_indices=True)
# return_indeices를 True로 설정하여 max pooling시에 어떤 위치에서 수행되었는지 반환한다.(UnPooling)- conv2
self.conv2_1 = CBR(64, 128, 3, 1, 1)
self.conv2_2 = CBR(128, 128, 3, 1, 1)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2 , ceil_mode=True, return_indices=True)- conv3
self.conv3_1 = CBR(128, 256, 3, 1, 1)
self.conv3_2 = CBR(256, 256, 3, 1, 1)
self.conv3_3 = CBR(256, 256, 3, 1, 1)
self.poo3 = nn.MaxPool2d(kernel_size=2, stride=2 , ceil_mode=True, return_indices=True)- conv4
self.conv4_1 = CBR(256, 512, 3, 1, 1)
self.conv4_2 = CBR(512, 512, 3, 1, 1)
self.conv4_3 = CBR(512, 512, 3, 1, 1)
self.poo4 = nn.MaxPool2d(kernel_size=2, stride=2 , ceil_mode=True, return_indices=True)- conv5
self.conv5_1 = CBR(512, 512, 3, 1, 1)
self.conv5_2 = CBR(512, 512, 3, 1, 1)
self.conv5_3 = CBR(512, 512, 3, 1, 1)
self.poo5 = nn.MaxPool2d(kernel_size=2, stride=2 , ceil_mode=True, return_indices=True)- 7 x 7 (fc6)
self.fc6 = CBR(512, 4096, 7, 1, 0)
self.drop6 = nn.Dropout2d(0.5)- 1 x 1 (fc7)
self.fc7 = CBR(4096, 4096, 1, 1, 0)
self.drop7 = nn.Dropout2d(0.5)- 7 x 7 (fc6-deconv)
self.fc_deconv = DCB(4096, 512, 7, 1, 0) # TransposedConv2d -> BatchNorm2d -> ReLU- unpool5
*pool1의 indices를 인자로 넣어줌
self.unpool5 = nn.MaxUnpool2d(2, stride=2) # size *2 (14*14)
self.deconv5_1 = DCB(512, 512, 3, 1, 1)
self.deconv5_2 = DCB(512, 512, 3, 1, 1)
self.deconv5_3 = DCB(512, 512, 3, 1, 1)- unpool4
self.unpool4 = nn.MaxUnpool2d(2, stride=2) # size *2 (28*28)
self.deconv4_1 = DCB(512, 512, 3, 1, 1)
self.deconv4_2 = DCB(512, 512, 3, 1, 1)
self.deconv4_3 = DCB(512, 256, 3, 1, 1)- unpool3
self.unpool3 = nn.MaxUnpool2d(2, stride=2) # size *2 (56*56)
self.deconv3_1 = DCB(256, 256, 3, 1, 1)
self.deconv3_2 = DCB(256, 256, 3, 1, 1)
self.deconv3_3 = DCB(256, 128, 3, 1, 1)- unpool2
self.unpool2 = nn.MaxUnpool2d(2, stride=2) # size *2 (112*112)
self.deconv2_1 = DCB(128, 128, 3, 1, 1)
self.deconv2_2 = DCB(128, 64, 3, 1, 1)- unpool1
self.unpool1 = nn.MaxUnpool2d(2, stride=2) # size *2 (224*224)
self.deconv1_1 = DCB(64, 64, 3, 1, 1)
self.deconv1_2 = DCB(64, 64, 3, 1, 1)- Score
self.score_fr = nn.conv2d(64, num_classes, 1, 1, 0, 1)3. SegNet
1) SegNet?
- 정확도 측면에서 성능 향상이 아닌 추론 속도 성능향상
- 자율 주행에 있어 빠르고 정확하게 구분(real-time)
- DeconvNet의 중앙에 있는 구조를 제거하여 parameter를 줄여 속도 향상
- Deconvolution을 사용하지 않고 Convolution layer사용
- Decoder Network의 마지막 blcok(unpool1)의 구조를 좀 더 단순하게 설계

4. Implementation
5. Reference
https://arxiv.org/abs/1505.04366 (Learning Deconvolution Network for Semantic Segmentation)

Boostcamper!