강의내용
Advanced Object Detection
Cascade RCNN
IoU threshold가 다르게 학습되었을 때 결과가 다르다. 전작적으로 IoU threshold가 0.5로 학습된 model이 성능이 가장 좋지만 AP의 IoU가 높아질수록 input IoU threshold가 높은 모델의 성능이 더 좋아진다.
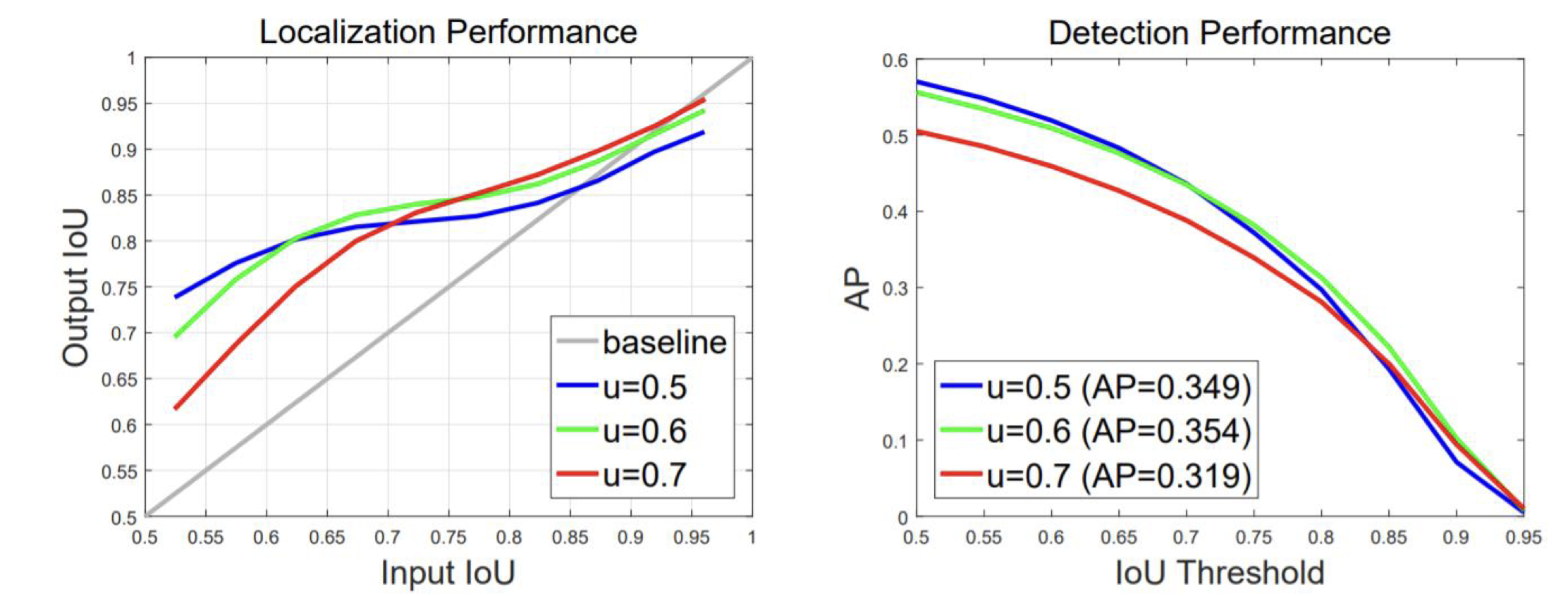
즉 학습될때 사용되는 IoU에 따라 대응되는 AP 측정 IoU 박스가 다르다. 이를 해결하기 위해 IoU를 0.5, 0.6, 0.7에서 학습할 수 있도록 제안
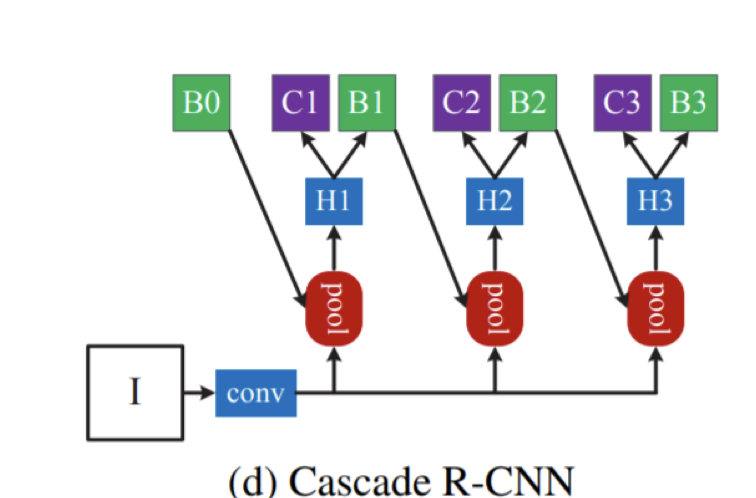
RPN으로 부터 B0를 얻고 순차적으로 B1, B2, B3를 얻으며 H1, H2, H3 별로 IoU threshold를 다르게 설정한다.
DCN (Deformable Convolution Networks)
일반적인 convolution neural networks는 filter 모양이 정사각형으로 고정되어 있는데 이는 Geometric transformation에서 한계를 지닌다.
이를 해결하기 위해 기존에는 Geometric augmentation을 적용하거나 Geometric invariant feature engineering을 적용하였다.
하지만 이러한 해결법도 결국 사람이 만들어 내는 augmentation이기 때문에 여전히 한계가 있다.
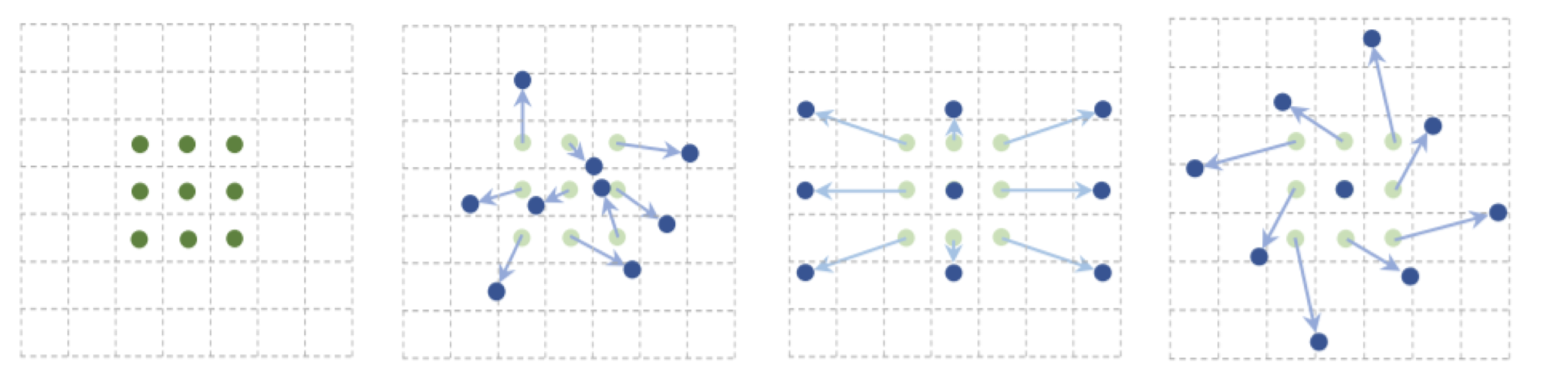
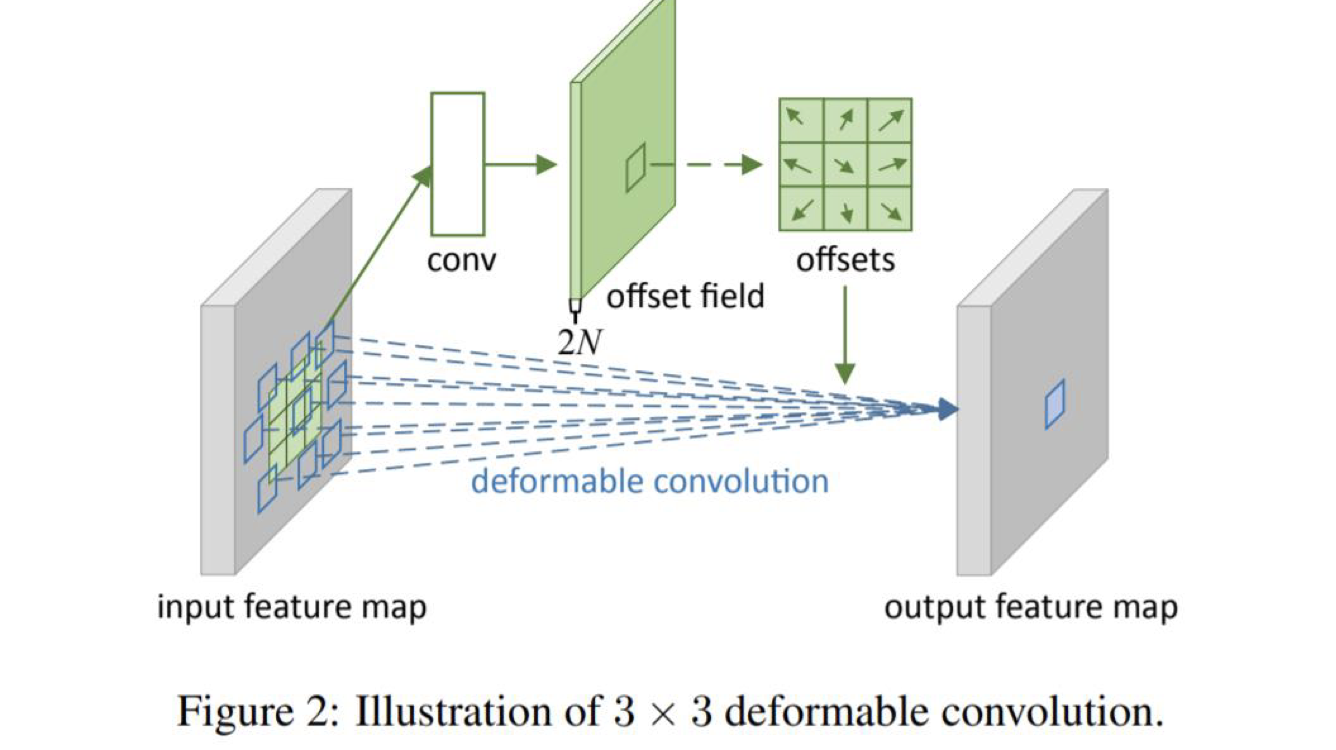
filter 에대한 연산에 offset을 추가하여 연산해 geometric 문제를 해결한다. 그 결과 객체가 있을법한 위치에서 CNN을 수행하게 되고 성능 향상을 이끌 수 있다.
Transformer
NLP에서 사용하는 Transformer 모델을 사용한다. 이미지 분류에 Transformer를 적용한 Vision Transformer(ViT)가 있지만 ViT는 Backbone으로 사용하지 못한다.
- 많은 양의 Data를 학습해야 성능이 나옴
- cost가 큼
Swin Transformer는 CNN과 유사한 구조로 설계하고 Window라는 개념을 도입하여 cost를 감소시켜 Backbon 모델로 사용이 가능하다.
- 2번의 Attention block 통과
- Multi-Head Attention이 아닌 Window-MultiHead Attention, Shifted Window-MultiHead Attention 사용
- 적은 Data에도 학습이 잘됨
- Window를 사용하여 cost 대폭 감소
YOLO v4
2-Stage Detector의 발전으로 정확도는 향상되었지만 실시간 task에는 부적합, 하나의 GPU에서 훈련할 수 있고 BOF, BOS 방법들을 적용
- BOF(Bag of Freebies): inference 비용을 늘리지 않고 정확도만 향상
- BOS(Bag of Spectials): inference 비용을 높이지만 정확도가 크게 향상
기존 YOLOv3 모델의 BOF, BOS 측면에서 여러가지 실험함
결과물
- Cascade RCNN 모델을 사용하고 Backbone model로 Swin Transformer를 사용해 높은 Score 달성 (Public LB: 0.567)
- Cascade RCNN 모델을 사용하고 Backbone model로 Swin Transformer를 사용해 2개의 모델 생성, ImageNet을 학습한 Swin Transformer의 pretrained weight 값을 사용 (base, small) 2개의 모델을 Ensemble (Public LB: 0.601)
- 2-Stage 모델과 1-Stage 모델 (YOLOv5)을 Ensemble하여 높은 Score 달성(Public LB: 0.644)
피어세션
실험 결과를 공유하고 점수가 잘 나온 baseline을 정한 뒤 여러가지 실험을 분배하여 대회 종료 전까지 적용
- Multiscale Model (image resolution): 1024, 512, 256 등 다양한 크기로 학습한 모델 Ensemble
- Data Augmentation: Color, CutMix, MixUp 등 다양한 Augmentation을 적용한 모델 생성 후 Ensemble
학습회고
분명 이번 p-stage에서는 일찍 baseline을 정해 팀원들과 여러가지 실험을 해보고 싶었지만 잘 이루어졌다. 점수 향상에 욕심을 부려 혼자서 많은 모델을 만들어보고 제대로 기록하지도 않아 정리가 되어있지 않았다. 지금이라도 제출했던 모델들을 표로 만들어서 정리하고 있지만 기억나지 않는 모델도 많다.
다행이 지금이라도 baseline을 결정해서 팀원들에게 공유하고 여러 실험을 할 수 있도록 역할을 분배하였다. 남은 기간동안 무분별하게 만들었던 모델들을 잘 정리하고 점수 갱신보다는 사용했던 모델들의 paper, 앙상블 기법, 학습 정리에 좀 더 시간을 투자해야겠다.
