이번 시간에는 어떻게 컴퓨터가 수치 데이터를 나타내고 저장하는지 알아본다.
참과 거짓은 이진수 0과 1로 나타낼 수 있다. 이진수에서 0과 1을 비트라고 부른다.
8비트를 다룬다면 0-255 사이의 숫자를 표현할 수 있다.
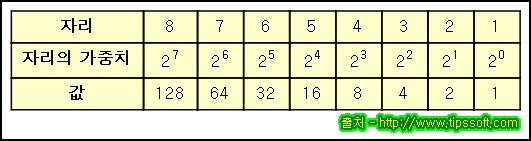
32비트나 64비트, 라는 컴퓨터 용어에 대해 들어봤을 것이다. 이건 32나 64비트의 덩어리로 작동한다는 뜻이다. 이건 아주 많은 숫자를 다룰 수 있따. 32비트로 다룰 수 있는 가장 큰 숫자는 43억 미만이다. 이것이 우리가 인스타그램 사진을 매우 부드럽고, 선명하게 볼 수 있는 이유다.
32bit는 32개의 0과 1로 이루어진다. 문제는 모든 수가 양수가 아니라는 것이다. 음수는 어떻게 다룰 것인가? 대부분 컴퓨터는 부호의 첫번재 비트를 음과 양을 나타내는 데 사용한다. 맨 첫자리가 1이라면 음. 0이라면 양. 그리고 남은 31bit는 숫자를 나타낸다. 이걸로 +-20억 범위의 수를 쓸 수 있다. 꽤 넓은 범위지만 충분하지 않다. 64bit가 필요한 이유다. 64bit로 나타낼 수 있는 가장 큰 숫자는 대략 920경이다.
컴퓨터에서 중요한 것 중 하나는, 주소Adress다. 컴퓨터는 위치를 표시할 수 있어야만 한다. 주소라는 저장공간에 데이터를 보관하고 검색하기 위해서다. 컴퓨터가 메모리가 기가,테라바이트 하며 수 조 바이트로 커지면서 64bit 메모리 주소 또한 필요했다. 컴퓨터는 정수가 아닌 다른 수도 다룰 수 있어야만 한다. 이를테면 12.6같은 실수도 다뤄야 한다.
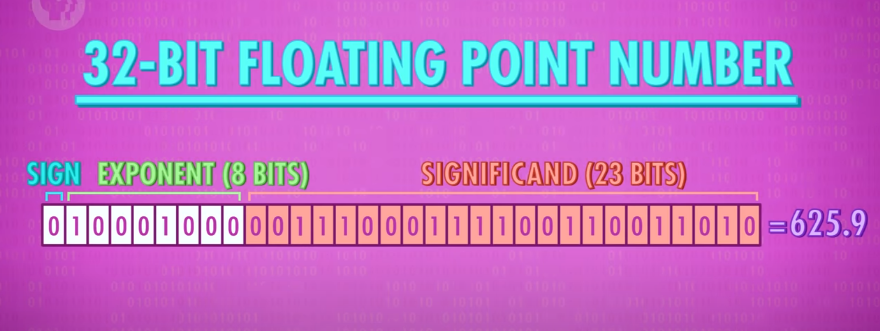
부동 소수점을 나타내기 위한 여러 방법이 개발 되었다. 가장 일반적인 것은 IEEE754 표준이다. 이 표준은 소수를 과학적인 표기법으로 저장한다.
예를 들어 625.9는
0.6259 * 10^3으로 적는다
여기에 두 가지 중요한 수가 있다. 6259는 유효숫자Significand라고 부른다. 10^3에서 3은 흔히 지수Exponent라고 부른다. 32비트 부동 소수점 표기법에서 첫 번째 비트는 양, 음 부호를 나타내는 데 사용한다. 그 다음 8bit는 지수exponent를 저장하는 데 쓰고, 나머지 23bit는 유효숫자를 나타내는 데 사용한다.
숫자는 이렇다 쳐도 문자는 어떻게 할까. 컴퓨터는 문자를 저장하는 특별한 저장공간을 가지지 않는다. 단순히 숫자를 사용한다. 프란시스 베이컨Francis Bacon은 1600년대에 26개의 알파벳을 암호화하는 데에 5bit의 연속된 순서를 사용했다. 이 5bit는 32가지 값을 저장할 수 있었기에 26개의 문자를 나타내는 것에는 적합했다. 하지만 구두점, 숫자, 대소문자를 나타내기엔 역부족이었다.
출처 : wikipedia
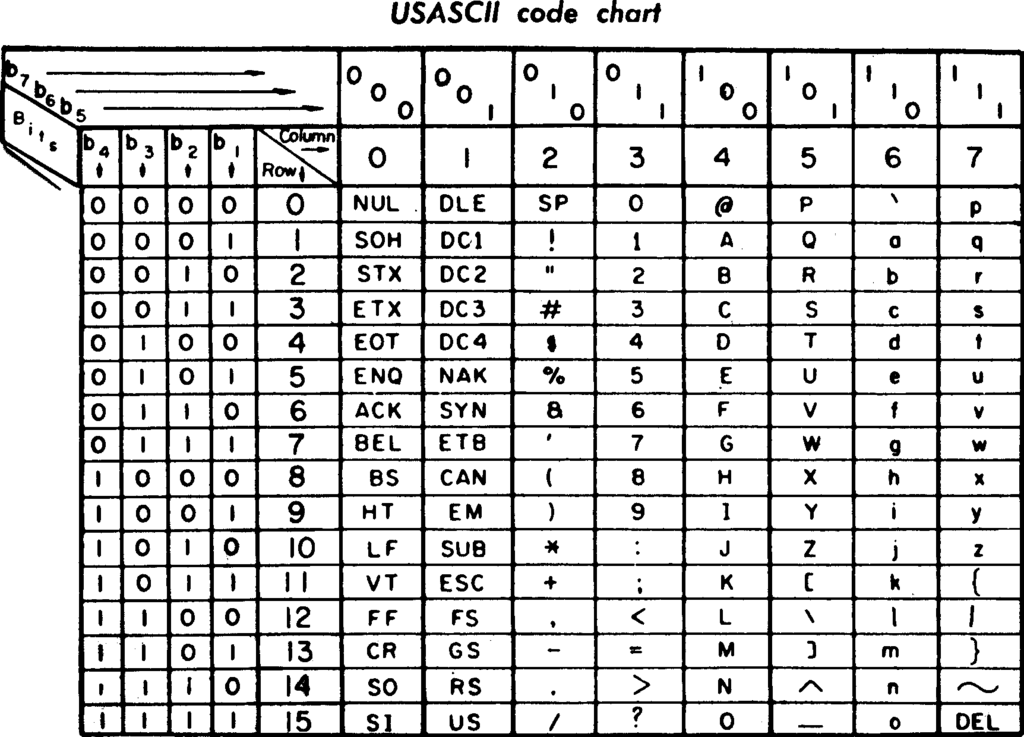
ASCII(아스키 코드:정보 교환을 위한 미국 표준 코드)
1963년 발명된 아스키는 7bit 코드였다. 128개의 다른 값을 저장할 수 있었다. 이 확장된 범위를 사용하면서 대문자와 소문자, 0부터 9까지의 숫자 @기호나 구두점과 같은 것들도 인코딩할 수 있게 된다. 예를 들면, 'a'는 97이라는 숫자에 해당한다. 그에 비해 'A'는 65에 해당한다. ':'은 58 ')'은 41이다. 아스키는 줄바꿈 문자를 사용해서 다음 행으로 줄바꿈 해야 하는 위치를 컴퓨터에게 알려줬다. ASCII는 초기 표준이었으므로 널리 사용 되었다. 다른 회사에서 만든 여러 컴퓨터와 데이터를 교환하는 데 중요하게 사용했다. 보편적으로 정보를 교환할 수 있는 이 능력을 '상호 운용성'이라고 한다.
아스키의 문제점은 영어를 위해서 설계되었다는 점이다. ASCII는 7BIT였다. 1BYTE 중 남은 1BIT를 이용해 국제 문자로 사용하지 않았던 코드가 대중화 된다. 미국에서 이런 여분의 숫자를 추가적인 기호를 인코딩하는데 사용했다. 반면 러시아 컴퓨터는 키릴 문자를 인코딩하는 데 여분의 BIT를 사용했고 그리스는 그리스 문자를 인코딩하고 그런 식이었다.
이 방식의 가장 큰 문제점은 러시아어로 쓰인 이메일을 미국 컴퓨터로 열면 문자가 깨진다는 것이었다. 아시아에서 컴퓨터가 떠오르면서 상황은 완전히 박살났다. 이 언어들은 8BIT안에 모든 문자를 인코딩할 수 없었다. 다양한 나라에서 인코딩 구조를 개발했지만, 국제적으로 호환되지는 않았다.
이런 배경에서 유니코드UNICODE가 탄생했다. 1992년 제정된 이 프로젝트는 마침내 하나의 보편적인 인코딩 구조를 만들었다. 유니코드의 가장 일반적인 버전은 16비트 공간을 사용해서 백만 개가 넘는 코드를 넣을 수 있다. 여태 사용한 모든 언어에 있는 각각의 글자를 지정하기에 충분한 크기다. 수학적 기호나 이모티콘을 포함할 수도 있었다.

놀라운 것은 이 표면적인 것들이 길고 긴 연속의 비트열로 이어진다는 사실이다. 메세지, 유튜브, 모든 웹페이지 심지어 운영체제까지도 0과 1의 연속일 뿐이다.
다음 시간엔 어떻게 컴퓨터가 이진 시스템을 조작하기 시작했는지에 대해 얘기한다.
