선형회귀
항등함수
리니어
이진분류
출력 1개 확률값
분류는 확률값
회귀는 연속값
클래스 개수
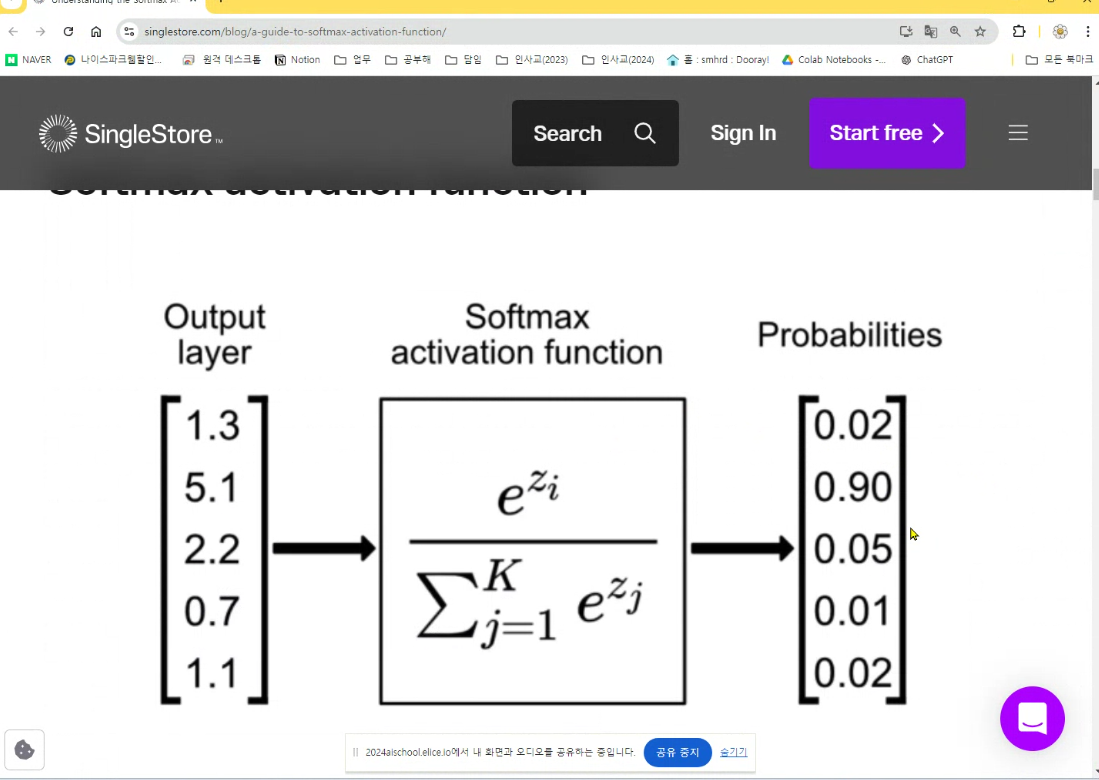
softmax
합이 1인 확률값
[딥러닝 개념정리]
- 딥러닝이란?
기계가 인간의 뉴런, 신경망을 모방하여 데이터를 학습 및 예측하는 기술- 퍼셉트론(perceptron)?
딥러닝 모델을 구성하는 기본 단위
(퍼셉트론 = 선형모델 + 활성화함수)- 모델링 순서
- 신경망 구조 설계
- 뼈대 생성 (Sequential())
- 입력층 (InputLayer(shape = (, ))) 입력특성의 형태를 지정
- 중간층, 은닉층 (Dense(units = ?, activation = ? ))
- 출력층 (Dense(units = ? , activation = ?))출력하고자하는 데이터의 형태를 지정
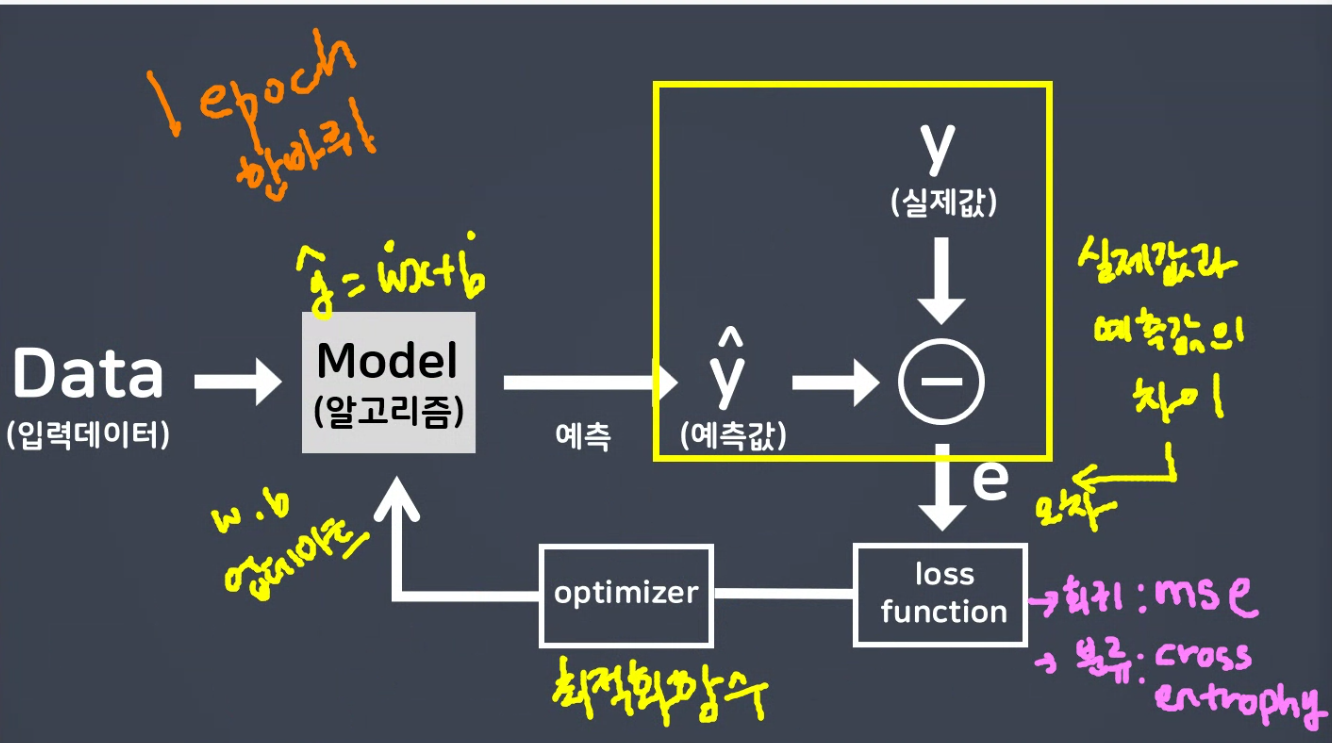
- 학습방법 및 평가방법 설정 (compile(loss, optimizer, metrics))
- 오차 손실, 최적화, 평가
- 모델학습 (model.fit(X_train, y_train, validation_split = ?, epochs = 반복횟수))
- 모델 예측 및 평가 (model.evaluate(X_test, y_test))
[활성화함수 activation -> 중간층, 출력층 (활용도가 다름)]
- 중간층 : 활성화/비활성화
(역치_활성화하기위해 필요한 최소 자극)
- 초기: stepfunction(계단함수) -> sigmoid(시그모이드) - 출력층 : 출력하고자하는 데이터의 형태를 지정
- 회귀 : linear(항등함수, y = x) 선형모델이 예측한 결과를 그대로 출력 -> default 값 별도로 작성하지 않아도 무방- 이진분류(클래스개수) : sigmoid(시그모이드) 선형모델이 예측한 연속한데이터를 0 과 1 사이의 확률값으로 변경해주기 위함이다.
- 다중분류 : softmax(소프트맥스) 클래스 개수만큼의 결과값을 전체 합이 1인 결과로 변경
[출력하고자하는 데이터의 개수에 따라 units의 개수]
- 회귀: units = 1
- 이진분류 : units = 1, 1개의 확률값(인지 아닌지에 대한 판별)
- 다중분류: units = 클래스의 개수
[학습방법 및 평가방법 설정 -> compile]
- loss(손실함수, 비용함수)
- 회귀: MSE (평균제곱오차)
- 이진분류: binary_crossentropy
- 다중분류: categorical_crossentropy -> 문제발생 -> 모델의 출력결과와 정답데이터의 형태가 달라 오류 발생 -> sparse_categorical_crossentropy
- optimizer(최적화함수)
- metrics (평가지표)
- 회귀: mse(평균제곱오차)
- 분류: accuracy(정확도)
I

성장하는 하루가 되자