
⏳ 위대한 복습 여정의 시작

인공지능을 접한지도 벌써 1년이 넘었다,, 기획 디자인 프론트엔드 이리저리 삽질하면서 공부하다보니 딥러닝에 대해서 해도 까먹고 해도 까먹고를 반복,,, 이번에 제대로 여러번 복습을 하면서 내 선에서 핵심 중요 개념들을 톺아보는 시간을 가져보려고한다 !
복습 방법은 파이토치 wikidocs를 활용하여 공부하고, 핵심 내용만 쏙쏙 뽑아 정리해보았다.
위키독스 요즘 너무너무 애용한다 🧡 핸드폰이나 패드로 슥슥 보면서 짬짬히 정리하기도 좋고, 모르는 개념 빠르게 찾아볼 때도 너무너무 좋다,,, 나중에 나도 요기서 집필 한번 하고싶을정도 (그런날이 올까,,?)
✨ 자 그럼 지금부터 시작 !
텐서 크기
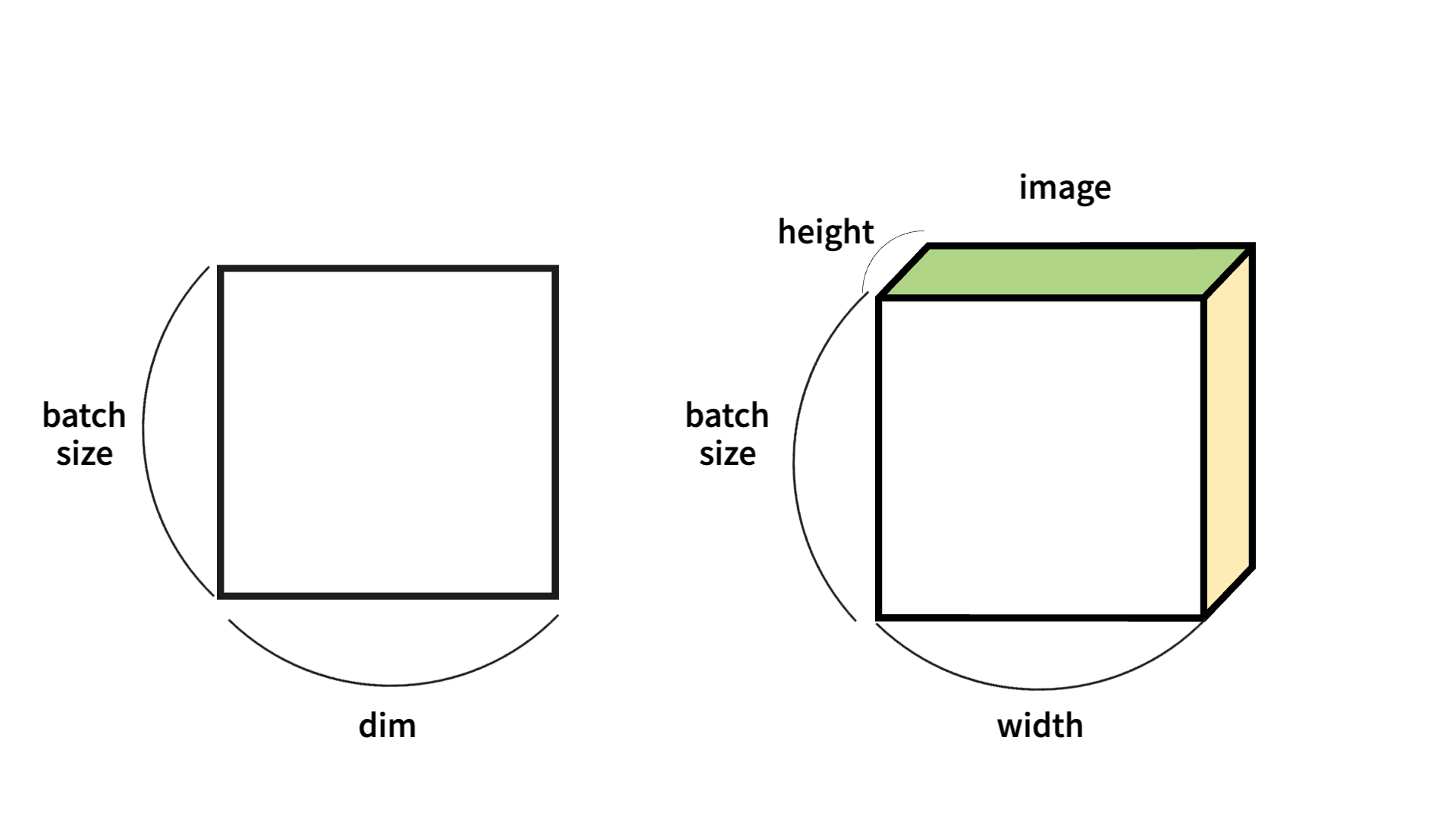
왼쪽부터 살펴보자. |t| = (Batch size, dim) 으로 전형적인 2차원 텐서이다.
훈련 data 하나의 크기가 256, data의 개수가 3000개라고 하자.
전체 훈련 데이터의 크기는 256 * 3000 이라고 간단하게 알수있다.
여기서 batch size 가 64 추가된다면, 한번에 처리하는 2D 텐서의 크기 는 64 * 256임을 확인하자. (덩어리 단위로 처리된다는 것을 batch size 라고 생각하면 되겠다.)
오른쪽을 살펴보면 |t| = (batch size, width, height) 형태로 3차원 텐서이며, 주로 비전 분야에서 활용된다.
이미지 데이터의 경우 3D로 처리되기 때문에 , batch size는 이미지의 개수로, width, height는 이미지의 고정적인 특성으로 들어가는 것을 확인할 수 있다.
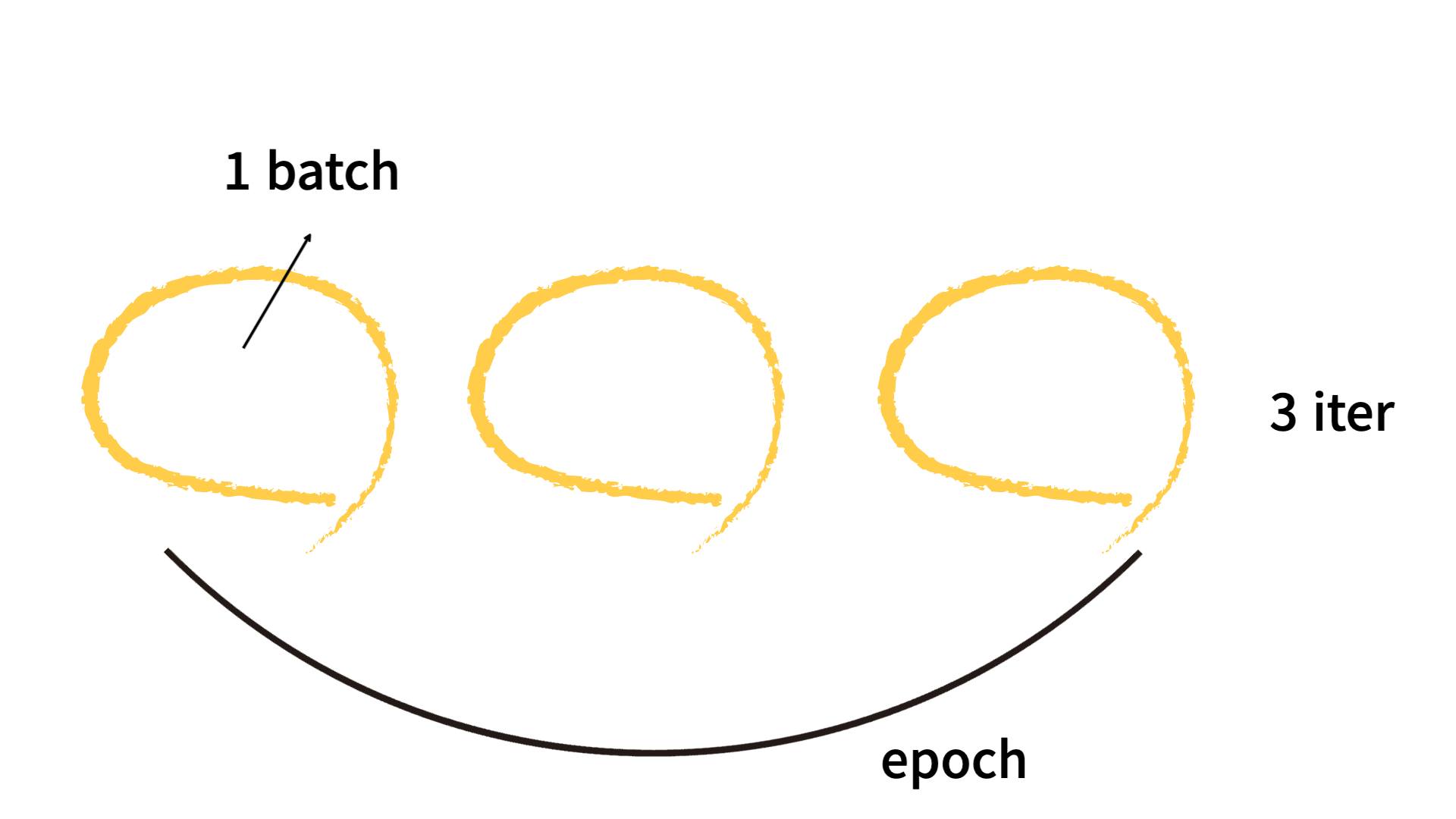
batch, epoch, iteration 의 개념은 이 이미지 하나로 각인시키자.
비용함수에 대하여
선형 회귀를 예측하기 위해 가설을 세워보자. 선형성을 띄니까 수식 하나로 정리가 가능하다.
이때 x와 곱해지는 W를 가중치(Weight) 라고 하며, b를 편향(bias) 이라고한다.
비용함수 = 손실함수 = 오차함수 라고 부른다.
비용함수를 찾는 이유는, 실제 값과 예측 값 간의 오차를 줄여주기 위함인 것은 알것이다.
평균 제곱함수는 : W, b 최적값 찾기에 적합하다.
평균 제곱오차를 W와 b 에 대한 손실 함수로 정리하면 다음과 같아진다.
자, 이 식에서 알 수 있는 것은 Cost(W,b)가 최소가 되게 만드는 W,b 를 구하면 훈련 데이터를 잘 나타내는 직선을 구할 수 있다는 것이다. 해당 코드는
cost.backward()
optimizer.step() #업데이트 진행로 작성하고, 비용함수를 미분하며 gradient를 계산, W 와 b 에 대한 기울기가 계산된다. 계산하고 새로 업데이트는 optimizer를 활용하여 진행한다.
Cost식의 의미를 다시 한번 되새기면 좋겠다.
원-핫 인코딩이란?
교재에서 이 내용이 종종 빠질 때가 있는데, 필수적으로 알아야한다.
선택해야하는 선택지의 개수만큼 차원을 가지고 각 선택지의 인덱스에 해당하는 원소는 1, 나머지 원소는 0의 값을 가지도록 하는 표현 방법이다. 원-핫 인코딩으로 표현된 벡터를 원-핫 벡터라고 한다.
원-핫 인코딩이 중요한 이유는 다음과 같다.
모든 클래스 간의 관계를 균등하게 분배한다.
일반적인 분류 문제에서는 각 클래스는 순서의 의미를 갖고 있지 않으므로 각 클래스 간의 오차는 균등한 것이 옳다. 예를 들어, 그냥 단순한 과일 나열의 경우는 순서의 의미를 갖지 않아 오차가 균등하다. 하지만 가족관계, 키 순서와 같이 순서가 있는 경우, 이때는 단순 정수 인코딩이 의미가 있으나, 순서의 의미를 갖지 않는 분류 문제의 경우 정수 인코딩이 알맞지 않다.
정수 인코딩과 달리 원-핫 인코딩은 분류 문제 모든 클래스 간의 관계를 균등하게 분배한다.
클래스 표현 방법의 무작위성을 만들어준다.
원-핫 인코딩을 통해 모든 클래스에 대해서 원-핫 벡터들은 모든 쌍에 대해서 유클리드 거리를 구해도 전부 유클리드 거리가 동일하다. 원-핫 벡터는 이처럼 각 클래스의 표현 방법이 무작위성을 가진다.(다 동등한 조건이기 때문) 하지만 원-핫 벡터의 관계의 무작위성은 때로는 단어의 유사성을 구할 수 없다는 단점으로 언급되기도 한다.
(+a) 소프트 맥스 함수
k 차원 벡터에서 i 번째 클래스가 정답일 확률를 pi라고 한다.
비용함수 - 크로스 엔트로피 함수
손실 함수 중에 까먹고 까먹는 것이 바로 cross-entropy 함수 ... 제대로 짚고 넘어가보자 !
크로스 엔트로피 손실함수는 loss값이 0과 1사이의 숫자로 측정되며, 분류 모델의 확률 분포와 예측 분포 사이의 차이를 측정한다.
대표적인 이진 분류 의 경우, Binary Cross Entropy를 사용하며, 이 바이너리 크로스엔트로피는 하나의 값만 저장한다. (둘 중 하나의 값)
위의 식으로 이진 분류에서 cross entropy를 정의하며, p는 예측 확률 , y는 지표 를 나타낸다(0또는 1).
다중 분류에서는 확장시켜서 (N개의 클래스라면)
다음과 같이 표현할 수 있다. 파이토치에서는 모듈이 지정되어있는데, F.cross_entropy 를 그냥 사용하면 된다. 이 속에는 softmax함수 까지 구현되어있다는 사실!
하이퍼파라미터와 매개변수의 차이, 알고있니?
이것도 그냥 이론만 냅다 공부하고 구현하다보면 헷갈리면 끝장나는 개념이다..
제대로 머릿속에 넣어두고 가자 !
하이퍼파라미터 : 값에 따라 모델의 성능에 영향을 주는 매개변수 (사용자가 직접 정할 수 있는 변수)
매개변수 : 가중치와 편향 같이 학습을 통해 바뀌어가지는 변수 (모델이 학습 과정에서 얻어지는 값)
그니까, 우리가 컨트롤할 수 있는 변수는 하이퍼파라미터 라는 것, 알아두고 가자!
이제는 활성화 함수 차례다 !
선형 활성화 함수는 우리가 지겹지겹하게 봤다,, y = wx + b 식에 대입해서 생각해보면 구조가 쭈루룩 나올 정도,, 그렇다면 비선형 활성화 함수 에 대해 잘 알고있니?! 😱
비선형 활성화 함수 : 단순하게 말하면 입력을 받아 수학적 변환을 수행하고, 출력을 생성하는 함수이다. 선형 함수로는, 은닉층을 여러번 추가하더라도 1회 추가하는 것과의 차이를 줄 수가없다. 수식으로 이해를 해보자면,
이 식이 있다고 하자. 여기서 은닉층을 2번 추가 한 식은
이렇게 식이 진행되는데, 여기서 w^3을 k라고 한다면 다시,,
이 전식과 다를바가 없는 식이 되므로 은닉층을 여러번 추가하더라도 1회 추가와 차이를 줄 수 없는 것이다..
수식적으로 말고도 비선형 활성함수를 사용해야 이러한 비선형성이 전체 신경망을 더 복잡한 함수로 근사하도록 해주는 역할을 하면서도, 미분 가능 하여 기울기 계산이 가능해져 보완 또한 가능해진다는 점이다.
비선형 활성 함수의 종류와, 각각의 문제점, 이점, 보완 과정은 여기로 후루룩 넘어가서 보고오길바란다.🤤
다음 파트에서는 신경망 구조에 대해서 자세~히 확인해보려구한다 😎 이거 시리즈 적으면서 복습하니까 좋네용 👍🏻 여러분들도 공부하시는 것들 모두모두 화이팅입니당ㅎㅎㅎ
